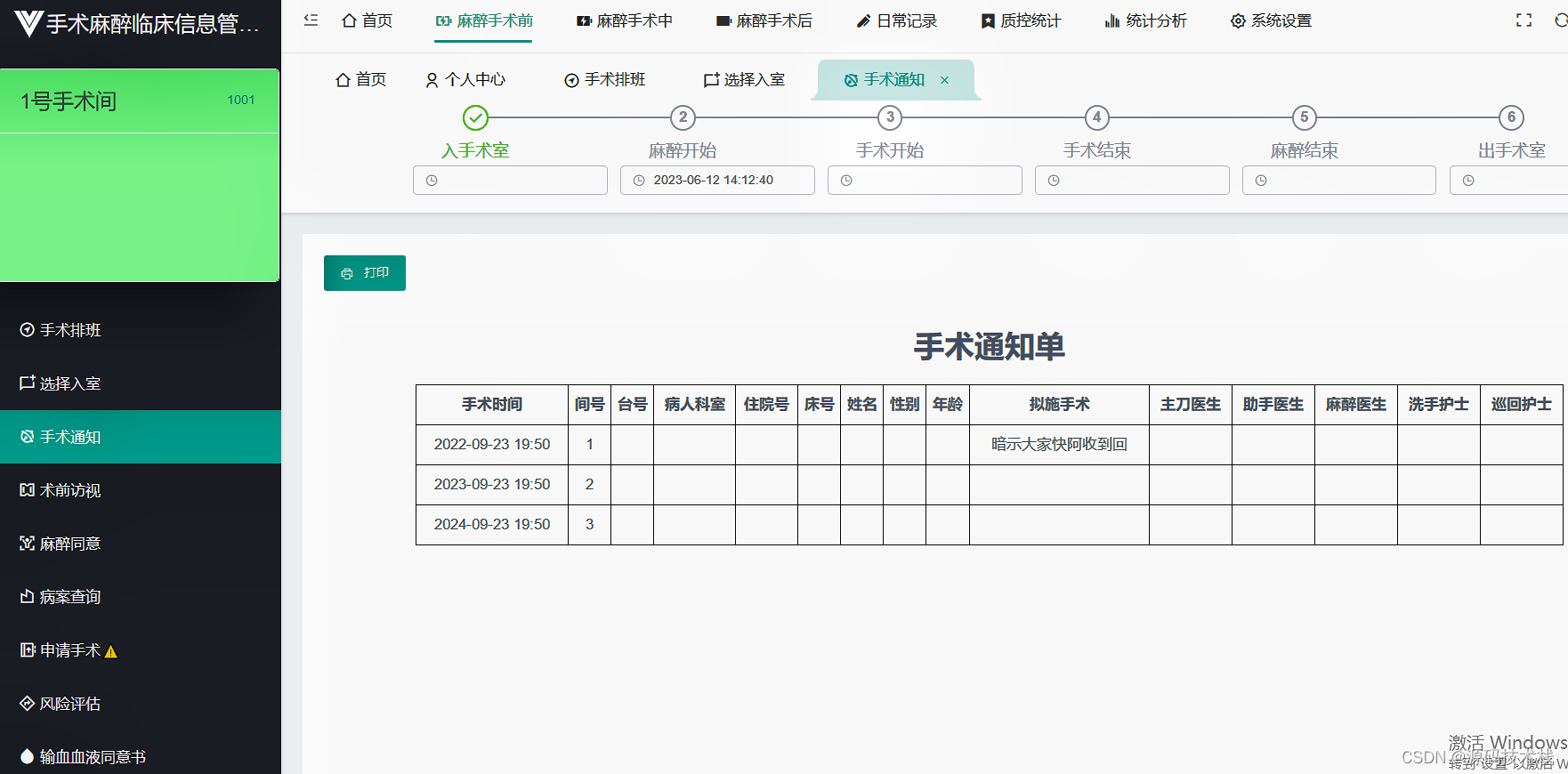
方式二:SQL方式操作
1.实例化SparkContext和SparkSession对象
2.创建case class Emp样例类,用于定义数据的结构信息
3.通过SparkContext对象读取文件,生成RDD[String]
4.将RDD[String]转换成RDD[Emp]
5.引入spark隐式转换函数(必须引入)
6.将RDD[Emp]转换成DataFrame
7.将DataFrame注册成一张视图或者临时表
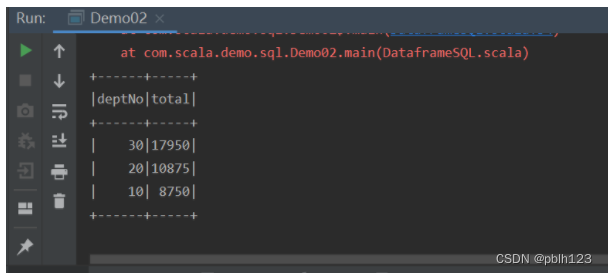
8.通过调用SparkSession对象的sql函数,编写sql语句
9.停止资源
10.具体代码如下:
package com.scala.demo.sqlimport org.apache.spark.rdd.RDDimport org.apache.spark.sql.{Row, SparkSession}import org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType}// 0. 数据分析// 7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30// 1. 定义Emp样例类case class Emp(empNo:Int,empName:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptNo:Int)object Demo02 {def main(args: Array[String]): Unit = {// 2. 读取数据将其映射成Row对象val sc = new SparkContext(newSparkConf().setMaster("local[2]").setAppName("Demo02"))sc.setLogLevel("WARN")val mapRdd = sc.textFile("file:///D:\\temp\\emp.csv").map(_.split(","))val rowRDD:RDD[Emp] = mapRdd.map(line => Emp(line(0).toInt, line(1), line(2),line(3), line(4), line(5).toInt, line(6), line(7).toInt))// 3。创建dataframeval spark = SparkSession.builder().getOrCreate()// 引入spark隐式转换函数import spark.implicits._// 将RDD转成Dataframeval dataFrame = rowRDD.toDF// 4.2 sql语句操作// 1、将dataframe注册成一张临时表dataFrame.createOrReplaceTempView("emp")// 2. 编写sql语句进行操作spark.sql("select deptNo,sum(sal) as total from emp group by deptNo order by total desc").show()// 关闭资源spark.stop()sc.stop()}}