机器学习 第五课 逻辑回归
- 概述
- 逻辑回归应用领域
- 逻辑回归 vs 线性回归
- 基本定义
- 输出类型
- 函数关系
- 误差计算
- 使用场景
- 数据分布
- 逻辑回归的数学原理
- Sigmoid 函数
- 多数几率
- 似然函数
- 逻辑回归损失函数
- 正则化
- L1 正则化
- L2 正则化
- L1 vs L2 实例
- 标准化
- 为什么要标准化?
- 如何进行标准化?
- 梯度下降
- 工作原理
- 梯度下降的公式
- 梯度下降的变种
- 学习率
- 前向传播 vs 反向传播
- 前向传播
- 反向传播
- 手把手计算回归
- 前向传播
- 反向传播
- 参数更新
- 实战
- 逻辑回归预测乳腺癌
- 逻辑回归 鸢尾花
- 手搓逻辑回归
概述
逻辑回归 (Logistic Regression) 尽管名字中带有 “回归” 两个字, 但主要是用来解决分类问题, 尤其是二分类问题. 逻辑回归的核心思想是: 通过将线性回归的输出传递给一个激活函数 (Activation Function) 比如 Sigmoid 函数) 将连续值转化为 0 到 1 之间的概率值, 在根据阈值 (Threshold) 对概率进行分类.

逻辑回归应用领域
逻辑回归 (Logistic Regression) 在许多领域有着广泛的应用, 包括但不限于:
- 医学: 用于疾病预测
- 金融: 信用评分, 评估某人违约的风险
- 营销: 预测客户是否购买某个产品, 或是否点击某个广告
- 社交网络: 预测用户相位, 例如是否接收好友请求或是否为垃圾信息
随着我们对数据的理解不断加深, 尤其是在设计分类任务时, 逻辑回归往往是我们首先尝试的算法. 相较于其他算法, 逻辑回归有着非常高的计算效率, 且背后的数学原理简单明了.
逻辑回归 vs 线性回归
在机器学习中, 线性回归 (Linear Regression) 和逻辑回归是最基础的算法. 尽管两个算法的名字十分相似, 但是工作原理和用途上有着很大的差异. 为了更深入的理解两者之间的差异, 我们从下面几个维度来展开讨论.
基本定义
- 线性回归 (Linear Regression): 线性回归用于估计一个或多个自变量与因变量的线性关系, 用于回归任务
- 逻辑回归 (Logistic Regression): 逻辑回归估算事件发生的概率, 用于分类任务
输出类型
- 线性回归 (Linear Regression): 线性回归输出的是连续值, 范围是 − ∞ ∼ + ∞ -\infty\sim +\infty −∞∼+∞
- 逻辑回归 (Logistic Regression): 逻辑回归输出的是概率值, 范围是 0-1
函数关系
- 线性回归 (Linear Regression): 线性回归关系是线性的, 使用恒等链接函数
- 逻辑回归 (Logistic Regression): 逻辑回归关系是 S 形的 (Sigmoid) 函数
误差计算
- 线性回归 (Linear Regression): 线性回归使用均方误差 (MSE) 来计算模型误差
- 逻辑回归 (Logistic Regression): 逻辑回归使用对数损失函数 (Logarithmic Loss Function) 来计算模型误差
使用场景
- 线性回归 (Linear Regression): 线性回归的目标是预测一个连续的值, 例如房价, 温度等
- 逻辑回归 (Logistic Regression): 逻辑回归的目标是分类, 特别是二分类, 例如垃圾邮件检测, 疾病诊断等
数据分布
- 线性回归 (Linear Regression): 要求自变量和因变量具有线性关系, 且误差应呈现正态分布 (Normal Distribution). 此外书籍中不能存在重共线性, 异方差性和自相关
- 逻辑回归 (Logistic Regression): 不需要因变量和自变量之间存在线性关系, 每个自变量与 log(odds) 之间存在线性关系. 此外, 逻辑回归还假设观察值之间是独立的
逻辑回归的数学原理
在我们深入研究逻辑回归 (Logistic Regression) 之前, 理解其背后的数学原理至关重要. 通过理解原理, 我们可以更好的理解算法, 还可以帮助我们在实际应用中做出明智的决策.
Sigmoid 函数
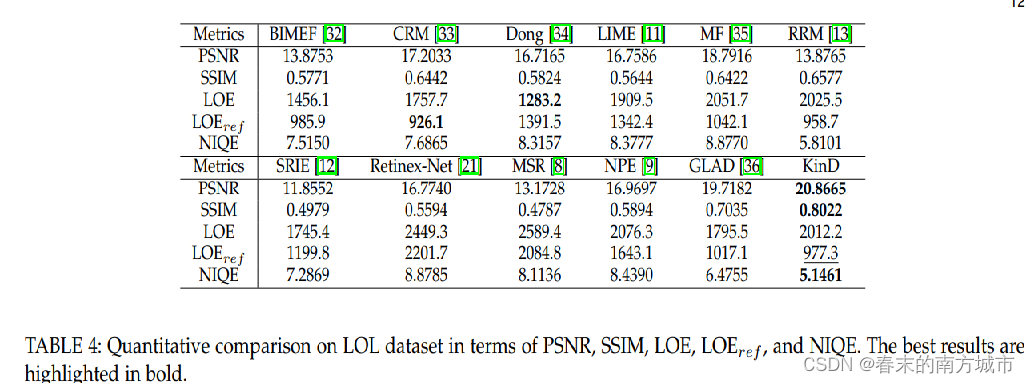
逻辑回归的核心是 Sigmoid 函数, 也称为 Logistic 函数. 通过 Sigmoid 函数, 我们可以将任何实数映射到 0-1 之间.
sigmoid 公式:
S ( z ) = 1 1 + e − z S(z) = \frac{1}{1 + e^{-z}} S(z)=1+e−z1
- z 为输入的线性组合
z 的公式:
z = w 0 + w 1 x 1 + w 2 x 2 + w 3 x 3 + . . . + w n x n z = w_0 + w_1x_1 + w_2x_2 + w_3x_3 + ... + w_nx_n z=w0+w1x1+w2x2+w3x3+...+wnxn
- 当 z 趋于正无穷时, S(z) 趋近于 1
- 当 z 趋于负无穷时, S(z) 趋近于 0
- 当 z=0 时, S(z) = 0.5
Sigmoid 的 S 形曲线非常适用于二分类问题, 因为 Sigmoid 可以产生的输出看做是属于某个类别的概率.
Sigmoid 函数在 Python 中的实现:
import numpy as npdef sigmoid(z):return 1 / (1 + np.exp(-z))
多数几率
逻辑回归涉及到一个重要的概念, 对数几率 (Log-Odds). 对数几率是事件发生概率与事件不发生概率之间的对数比率.
l o g i t ( p ) = l o g ( p 1 − p ) logit(p) = log(\frac{p}{1-p}) logit(p)=log(1−pp)
其中, p 是事件发生的概率 (Probability). 我们的目标是建立解释变量和对数几率之间的关系.
似然函数
为了估计逻辑回归模型中的参数, 我们需要使用似然函数 (Likelihood Function). 给定一组参数, 依然函数描述了数据观测到的概率.
似然函数与概率:
- 似然: 给定某一观测到数据集, 我们试图估计某一参数 (如硬币出现正面的概率) 的可能性.
- 概率: 给定某一参数值 (例如一个硬币出现正反面的概率), 我们计算特定情况下观察到某一数据集的概率. 举个栗子: 抛硬币, 正反面出现的概率为 0.5, 我们可以计算连续抛投 5 词都是正面的概论, 即 P ( 5 正面 ∣ p ) = ( 0.5 ) 5 = 0.03125 P(5 正面 | p) = (0.5)^5 = 0.03125 P(5正面∣p)=(0.5)5=0.03125
- 似然 vs 概率:
- 函数角度: 似然是关于参数的函数, 给定观测到的数据; 概率是关于数据的函数, 给定固定的参数值
- 归一化: 似然的总和并不一定为 1, 不是一个真正的概率分布; 概率所有可能的事件总和总是等于 1
- 观点: 似然描述了给定已经发生的某事件下, 不同情景 (模型参数) 的可能; 概率描述了未来发生某件事情的可能性
似然函数公式:
L ( θ ∣ x ) = P ( X = x ∣ θ ) L(\theta|x) = P(X=x|\theta) L(θ∣x)=P(X=x∣θ)
- θ \theta θ: 模型参数
- X X X: 随机变量
- x x x: 观察到的数据
- P ( X = x ∣ θ ) P(X=x|\theta) P(X=x∣θ): 在给定参数 θ \theta θ下观测到数据 x x x的概率
最大似然估计, 似然函数在统计学中一个主要应用是最大似然估计 (MLE). 目标是找到能使似然函数最大化的参数值. 公式:
θ ˆ = a r g m a x L ( θ ∣ x ) \^\theta = arg\; max\; L(\theta|x) θˆ=argmaxL(θ∣x)
- θ ˆ \^\theta θˆ为模型参数的最佳估计值
为什么要使用似然函数:
- 似然函数为我们提供了一个框架来评估模型参数的不同可能值对观察数据的拟合程度. 最大似然函数估计为我们提供了一个一致性和渐进无偏的估计方法, 即样本量越大, MLE 会月接近真实参数值
逻辑回归损失函数
逻辑回归 (Logistic Regression) 用于解决二分类 (Binary Classification) 问题, 主要用于目标是预测给定输入的输出类别为 1 (True) 的概率. 为了衡量模型的预测值 ( y ˆ \^y yˆ Predict) 与实际类别标签之间的差异, 我们需要一个损失函数. 逻辑回归蚕蛹的损失函数通常被称为对数损失 (Log Loss) 或交叉熵损失 (Cross Entropy Loss).
对数损失函数:
J ( w , b ) = − y l o g ( y ˆ ) − ( 1 − y ) l o g ( 1 − y ˆ ) J(w, b) = -ylog(\^y)- (1-y)log(1-\^y) J(w,b)=−ylog(yˆ)−(1−y)log(1−yˆ)
- y: 是类别标签 (0 或 1)
- y ˆ \^y yˆ: 是模型预测值
对数损失函数考虑了模型预测值的概率和实际类别之间的所有可能的差异:
- 当实际类别等于 1 时 (y=1): 损失函数就是 − l o g ( y ˆ ) -log(\^y) −log(yˆ). 如果 y ˆ \^y yˆ 越接近 1, 那么损失值将越接近 0. 反之 y ˆ \^y yˆ 越接近 0, 损失值将越大
- 当实际类别等于 1 时 (y=0): 损失函数就是 − l o g ( 1 − y ˆ ) -log(1-\^y) −log(1−yˆ). 如果 y ˆ \^y yˆ 越接近 0, 那么损失值将越接近 0. 反之 y ˆ \^y yˆ 越接近 1, 损失值将越大
注: 交叉熵损失和对数损失在二分类问题下是等价的.
正则化
正则化 (Regularization) 是机器学习中一个的一个重点. 正则化通过在模型损失函数中添加一定的 “惩罚” 项, 来限制模型的复杂度以提高模型的泛化能力 (Generalization Ability) 和避免过拟合 (Overfitting). 在逻辑回归中, 我们常常会用到 L1 和 L2 正则化来实现.
L1 正则化
L1 正则化 (Lasso 正则化):
J L 1 = J + λ ∑ i = 1 n ∣ w i ∣ J_{L1} = J + \lambda \sum\limits_{i=1}^{n}|w_i| JL1=J+λi=1∑n∣wi∣
- J J J: 原始的损失函数
- w i w_i wi: 模型参数
- λ \lambda λ: 正则化参数
L1 正则化倾向于产生一些权重为 0 的特征 (Feature), 这意味着模型中某些特征可能完全被忽略, 从而实现了特征选择.
L2 正则化
L2 正则化 (Ridge 正则化):
J L 1 = J + λ ∑ i = 1 n w i 2 J_{L1} = J + \lambda \sum\limits_{i=1}^{n}w_i^2 JL1=J+λi=1∑nwi2
- J J J: 原始的损失函数
- w i w_i wi: 模型参数
- λ \lambda λ: 正则化参数
与 L1 正则化不同, L2 正则化不会使权重完全为 0, 但它会尽量使它们小, 这有助于防止任何单一特征对预测结果产生过大的影响, 从而使模型更加稳健.
选择合适的正则化:
- 选择 L1 或 L2 正则化 (或者它们的组合, Elastic Net) 取决于我们需要解决什么问题. 如果只有几个特征是重要的, 那么 L1 正则化可能更合适, 因为它会导致稀疏的模型. 而如果所有特征都有意义, 但我们希望模型不要过于以来任何单一特征, 那么 L2 正则可能是更好的选择.
L1 vs L2 实例
假设我们有一个拥有 10 个特征的数据集, 但是其中只有 3 个是真正有意义的, 及特征中含有许多冗余特征. 在这种情况下, 我们就需要用到 L1 正则化, 因为 L1 正则化可以帮我们将那些不重要的特征的权重将为 0.
先讲一下 sklearn 生成模拟数据的格式:
sklearn.datasets.make_classification(n_samples=100, n_features=20, *, n_informative=2, n_redundant=2, n_repeated=0, n_classes=2, n_clusters_per_class=2, weights=None, flip_y=0.01, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None)
参数:
- n_samples: 生成的数据数量
- n_features: 数据的特征个数
- n_informative: 信息特征的个数 (最重要的特征)
- n_redundant: 冗余特征的个数
- random_state: 随机状态 (随机数种子)
例子:
"""
@Module Name: 逻辑回归 正则化.py
@Author: CSDN@我是小白呀
@Date: October 18, 2023Description:
逻辑回归 正则化
"""
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import log_loss, accuracy_score# 生成模拟数据, 长度1000, 特征10, 其中有用特征3, 冗余特征7
X, y = make_classification(n_samples=1000, n_features=10, n_informative=3, n_redundant=7, random_state=8)# 输出数据维度
print("特征维度:", X.shape) # (1000, 10)
print("标签维度:", y.shape) # (1000, )# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)# 使用L1正则化
l1_model = LogisticRegression(penalty='l1', solver='liblinear')
l1_model.fit(X_train, y_train)# 使用L2正则化
l2_model = LogisticRegression(penalty='l2', solver='liblinear')
l2_model.fit(X_train, y_train)# 对比权重
print("L1正则化的特征权重:\n{}".format(l1_model.coef_))
print("L2正则化的特征权重:\n{}".format(l2_model.coef_))# 对比模型效果
l1_pred = l1_model.predict(X_test)
l2_pred = l2_model.predict(X_test)print("L1 逻辑回归误差:", log_loss(y_test, l1_pred))
print("L2 逻辑回归误差:", log_loss(y_test, l2_pred))
print("L1 逻辑回归 acc:", accuracy_score(y_test, l1_pred))
print("L2 逻辑回归 acc:", accuracy_score(y_test, l2_pred))
输出结果:
特征维度: (1000, 10)
标签维度: (1000,)
L1正则化的特征权重:
[[ 0. 0. 0. -0.66172034 0. 0.0. -0.75254448 -0.27951727 0.41781586]]
L2正则化的特征权重:
[[-0.14042143 -0.21016038 0.12523401 -0.43610954 0.05762657 0.08849344-0.19145278 -0.51859205 -0.42032689 0.5046308 ]]
L1 逻辑回归误差: 9.901243835463227
L2 逻辑回归误差: 10.016373090112928
L1 逻辑回归 acc: 0.7133333333333334
L2 逻辑回归 acc: 0.71
标准化
标准化 (Standardization) 常用与预处理数据, 特别是在使用需要考虑特征尺度的机器学习算法, 例如: 支持向量机, 逻辑回归, K-近邻.
为什么要标准化?
机器学习算法对特征的尺度和分布较为敏感. 当特征的尺度 (范围) 相差很大时, 那些范围较大的特可能会主导算法的行为, 导致模型性能不佳.
如何进行标准化?
标准化的主要思想是对特征数据进行缩放, 使其均值为 0, 标准差为 1.
标准化公式:
z = x − μ σ z = \frac{x - \mu}{\sigma} z=σx−μ
- z z z: 原始特征值
- μ \mu μ: 特征均值
- σ \sigma σ: 特征标准差
sklearn 中进行标准化:
from sklearn.preprocessing import StandardScaler# 原始数据
data = [[0, 1], [2, 3], [4, 5]]
print(data)# 标准化
scaler = StandardScaler()
scaler.fit(data)
data = scaler.transform(data)
print(data)
输出结果:
[[0, 1], [2, 3], [4, 5]]
[[-1.22474487 -1.22474487][ 0. 0. ][ 1.22474487 1.22474487]]
逻辑回归预测乳腺癌, 不进行标准化:
Classification Report:precision recall f1-score support0 0.92 0.96 0.94 471 0.97 0.94 0.95 67accuracy 0.95 114macro avg 0.94 0.95 0.95 114
weighted avg 0.95 0.95 0.95 114
进行标准化:
Classification Report:precision recall f1-score support0 0.96 0.96 0.96 471 0.97 0.97 0.97 67accuracy 0.96 114macro avg 0.96 0.96 0.96 114
weighted avg 0.96 0.96 0.96 114
梯度下降
梯度下降 (Gradient Descent) 是一个用于优化函数的迭代方法. 在机器学习 (Machine Learning) 和深度学习 (Deep Learning) 中, 我们常用梯度下降来最小化 (最大化) 损失函数, 进而找到模型的最优参数.
工作原理
梯度下降的核心思想很简单: 找到损失函数的斜率 (梯度), 然后沿着斜率的反方向更新模型的参数, 逐步减小损失.
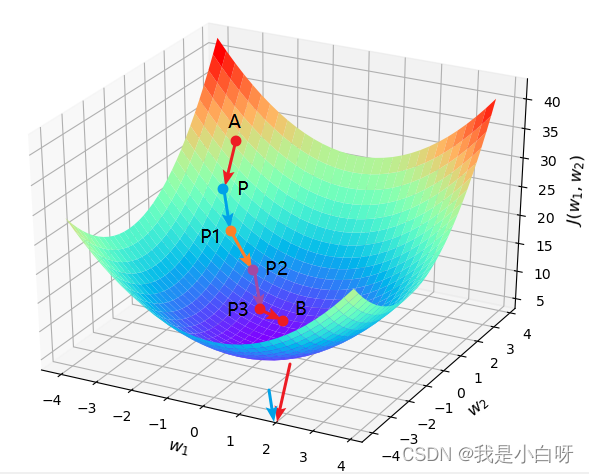
梯度下降的公式
公式:
w n e x t = w − l r × ∂ l o s s ∂ w w_{next} = w - lr\times \frac{\partial loss}{\partial w} wnext=w−lr×∂w∂loss
- w n e x t w_{next} wnext: 是梯度下降过程中的下一个权重
- lr: Learning Rate 学习率
- ∂ l o s s ∂ w \frac{\partial loss}{\partial w} ∂w∂loss: 误差函数的导数
下面我们来推导一下:
我们已知: M S E = 1 n ∑ i = 1 n ( y i − y ˆ i ) 2 y = w 0 + w 1 x 1 MSE = \frac{1}{n}\sum\limits_{i=1}^{n}(y_i - \^y_i)^2\\y = w_0 + w_1x_1 MSE=n1i=1∑n(yi−yˆi)2y=w0+w1x1
在梯度下降中, 我们的目标是调整模型参数 (权重和偏置, w 和 b 或 w0) 以最小化损失函数, 所以我们需要对模型参数 (w 和 w0) 求偏导:
w1 (权重) 求导:
∂ M S E ∂ w 1 = 1 n ∑ i = 1 n ( w 0 + w 1 x 1 ) 2 d w = 2 n ∑ i = 1 n x ( w 0 + w 1 x 1 ) \frac{\partial MSE}{\partial w_1} = \frac{1}{n}\sum\limits_{i=1}^{n}(w_0 + w_1x_1)^2dw \\=\frac{2}{n}\sum\limits_{i=1}^{n}x(w_0 + w_1x_1) ∂w1∂MSE=n1i=1∑n(w0+w1x1)2dw=n2i=1∑nx(w0+w1x1)
w0 (偏置) 求导:
∂ M S E ∂ w 0 = 1 n ∑ i = 1 n ( w 0 + w 1 x 1 ) 2 d w = 2 n ∑ i = 1 n ( w 0 + w 1 x 1 ) \frac{\partial MSE}{\partial w_0} = \frac{1}{n}\sum\limits_{i=1}^{n}(w_0 + w_1x_1)^2dw \\=\frac{2}{n}\sum\limits_{i=1}^{n}(w_0 + w_1x_1) ∂w0∂MSE=n1i=1∑n(w0+w1x1)2dw=n2i=1∑n(w0+w1x1)
如果有 w2, w3 以此类推, 这边我就不写了.
计算新的权重, 将上面的导数代入梯度下降公式, 我们可以得到:
w 1 n e x t = w 1 − l r × ∂ l o s s ∂ w 1 = w 1 − l r × 2 n ∑ i = 1 n x ( w 0 + w 1 x 1 ) w_{1next} = w_1 - lr\times \frac{\partial loss}{\partial w_1} \\=w_1 - lr\times\frac{2}{n}\sum\limits_{i=1}^{n}x(w_0 + w_1x_1) w1next=w1−lr×∂w1∂loss=w1−lr×n2i=1∑nx(w0+w1x1)
同理:
w 0 n e x t = w 0 − l r × ∂ l o s s ∂ w 0 = w 1 − l r × 2 n ∑ i = 1 n ( w 0 + w 1 x 1 ) w_{0next} = w_0 - lr\times \frac{\partial loss}{\partial w_0} \\=w_1 - lr\times\frac{2}{n}\sum\limits_{i=1}^{n}(w_0 + w_1x_1) w0next=w0−lr×∂w0∂loss=w1−lr×n2i=1∑n(w0+w1x1)
在代码中:
# 计算w的导, w的导 = 2x(wx+b-y)w_gradient += (2 / N) * x * ((w_current * x + b_current) - y)# 计算b的导, b的导 = 2(wx+b-y)
b_gradient += (2 / N) * ((w_current * x + b_current) - y)
梯度下降的变种
- 批量梯度下降 (BGD, Batch Gradient Descent): 每次使用这个训练集来计算梯度
- 随机梯度下降 (SGD, Stochastic Gradient Descent): 每次只使用一个样本来计算梯度
- 小批量梯度下降 (Mini-Batch Gradient Descent): 使用一个小批量的样本来计算梯度
学习率
寻找山谷的最低点, 也就是我们的目标函数终点 (什么样的参数能使得目标函数达到极值点)
下山分几步走呢?
- 找到当前最合适的方向
- 走一小步
- 按照方向与步伐去更新我们的参数
学习率 (learning_rate): 对结果影响较大, 越小越好.
数据批次 (batch_size): 优先考虑内存和效率, 批次大小是次要的.
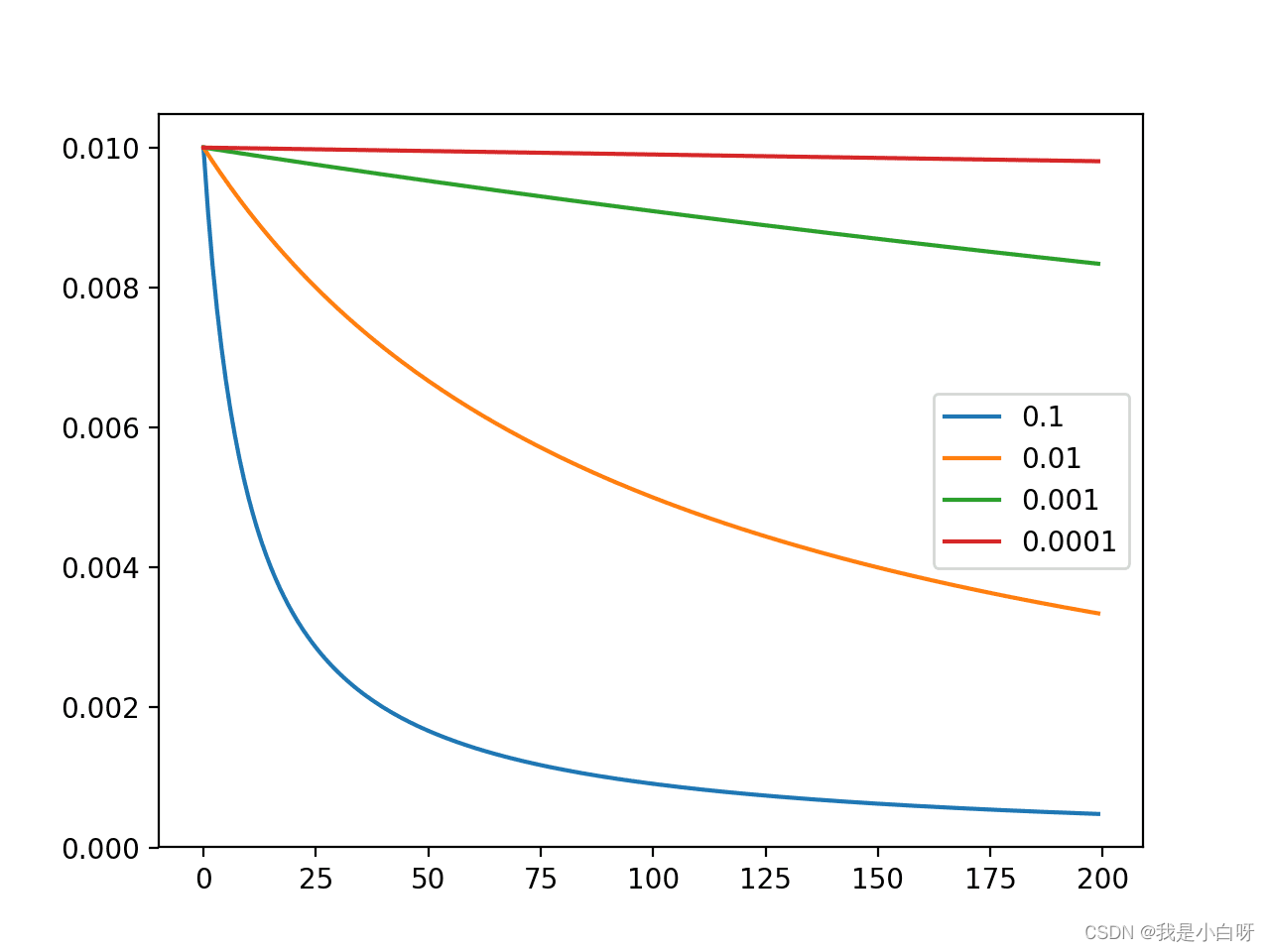
选择适当的学习率非常重要:
- 太小的学习率: 收敛速度慢
- 太大的学习率: 会错过最小值, 或梯度爆炸
常见的操作有:
- 学习率衰减或学习率退火 (Learning Rate Decay 或 Cosine Annealing), 即学习率随着迭代次数逐渐减小
前向传播 vs 反向传播
前向传播 (Forward Propagation) 和反向传播是深度学习 (Deep Learning) 中训练神经网络 (Neural Network) 的一个概念. 但是今天我乐意, 所以就来给大家讲一讲, 不喜欢欢迎来打我.
逻辑回归 (Logistic Regression) 可以被视为一个单层神经网络, 所以前向传播和反向传播的概念也适用.
前向传播
前向传播 (Forward Propagation) 是指从输入层传递到输出层的信息流. 在这个过程中我们计算每一层的输出值知道最后的预测值.
对于逻辑回归 (Logistic Regression) 而言, 逻辑回归的单层神经网络的前向传播可以描述为以下几步:
- 计算线性部分: 给定输入特征 X X X 和权重 w w w (以及偏置 b b b), 我们计算 z = w X + b z = wX + b z=wX+b
- 激活函数: 将上一步的结果 z z z 传递给 Sigmoid 激活函数, 得到预测值 y ˆ = σ ( z ) \^y = \sigma(z) yˆ=σ(z)
反向传播
反向传播 (Backward Propagation) 是通过计算损失函数对于每个参数梯度来更新模型的参数. 这些梯度可以告诉我们如何调整参数以最小化损失.
对于逻辑回归, 反向传播的过程可以描述为以下几步:
- 计算误差: 计算 y − y ˆ y - \^y y−yˆ, 即真实值和预测值之间的差
- 计算梯度: 计算损失函数 L L L 相对于权重 w w w 和偏置 b b b 的梯度. 具体来说, 就是求对于权重 w w w 和偏置 b b b 的偏导. 计算梯度 (Gradient) 的目的是找到一个方向, 沿着方向调整参数使得损失减少
- 更新参数: 使用上一步计算所得的梯度来更新权重和偏置. 我们使用学习率 (Learning Rate) 来控制更新的步长
在神经网络中, 这个过程更加复杂, 因为我们需要从输出层开始, 一层一层的回到输入层, 计算每一层的梯度. 但基本思想是一样的, 即计算损失梯度, 并使用这些梯度来更新网络中的权重和偏置. 前向传播为我们提供了模型的预测值, 反向传播为我们提供了更新模型参数的方法, 从而改进模型的预测能力.
手把手计算回归
使用简单的线性回归模型 y = w x + b y=wx+b y=wx+b来拟合给定的数据.
数据:
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
模型初始参数:
- w = 0
- b = 0
目标: 最小化均方误差 (MSE)
1 n ∑ i = 1 n ( y − ( w x + b ) ) \frac{1}{n}\sum\limits_{i=1}^{n}(y - (wx + b)) n1i=1∑n(y−(wx+b))
前向传播
前向传播计算:
对于 x 1 = 1 x_1 = 1 x1=1, 预测结果为:
y ˆ 1 = w × x 1 + b = 0 × 1 + 0 = 0 \^y_1 = w \times x_1 + b = 0 \times 1 + 0 = 0 yˆ1=w×x1+b=0×1+0=0
真实值 y 1 = 2 y_1 = 2 y1=2, 所以误差为 e 1 = y 1 − y ˆ 1 = 2 e_1 = y_1 - \^y_1 = 2 e1=y1−yˆ1=2
以此类推:
- 对于 x 1 = 1 x_1 = 1 x1=1:
- y ˆ 1 = w × x 1 + b = 0 \^y_1 = w \times x_1 + b = 0 yˆ1=w×x1+b=0
- e 1 = y 1 − y ˆ 1 = 2 e_1 = y_1 - \^y_1 = 2 e1=y1−yˆ1=2
- 对于 x 2 = 2 x_2 = 2 x2=2:
- y ˆ 2 = w × x 2 + b = 0 \^y_2 = w \times x_2 + b = 0 yˆ2=w×x2+b=0
- e 2 = y 2 − y ˆ 2 = 4 e_2 = y_2 - \^y_2 = 4 e2=y2−yˆ2=4
- 对于 x 3 = 3 x_3 = 3 x3=3:
- y ˆ 3 = w × x 3 + b = 0 \^y_3 = w \times x_3 + b = 0 yˆ3=w×x3+b=0
- e 3 = y 3 − y ˆ 3 = 6 e_3 = y_3 - \^y_3 = 6 e3=y3−yˆ3=6
- 对于 x 4 = 4 x_4 = 4 x4=4:
- y ˆ 4 = w × x 4 + b = 0 \^y_4 = w \times x_4 + b = 0 yˆ4=w×x4+b=0
- e 4 = y 4 − y ˆ 4 = 8 e_4 = y_4 - \^y_4 = 8 e4=y4−yˆ4=8
- 对于 x 5 = 5 x_5 = 5 x5=5:
- y ˆ 5 = w × x 5 + b = 0 \^y_5 = w \times x_5 + b = 0 yˆ5=w×x5+b=0
- e 5 = y 5 − y ˆ 5 = 10 e_5 = y_5 - \^y_5 = 10 e5=y5−yˆ5=10
反向传播
MSE 的偏导为:
∂ M S E ∂ w = − 2 n ∑ i = 1 n x ( y − ( w x + b ) ) \frac{\partial MSE}{\partial w} = -\frac{2}{n}\sum\limits_{i=1}^{n}x(y - (wx + b)) ∂w∂MSE=−n2i=1∑nx(y−(wx+b))
∂ M S E ∂ b = − 2 n ∑ i = 1 n ( y − ( w x + b ) ) \frac{\partial MSE}{\partial b} =- \frac{2}{n}\sum\limits_{i=1}^{n}(y - (wx + b)) ∂b∂MSE=−n2i=1∑n(y−(wx+b))
代入 x 1 = 1 x_1 = 1 x1=1 和 y 1 = 2 y_1 = 2 y1=2:
∂ M S E ∂ w = − 2 × 1 × 2 = − 4 \frac{\partial MSE}{\partial w} = -2 \times1 \times2 = -4 ∂w∂MSE=−2×1×2=−4
∂ M S E ∂ b = = − 2 × 2 = − 4 \frac{\partial MSE}{\partial b} = = -2 \times2 = -4 ∂b∂MSE==−2×2=−4
这是一个数据的梯度, 对于整个数据, 我们需要依次计算 x 1 x_1 x1 到 x 5 x_5 x5, 然后求平均:
∂ M S E ∂ w = − 2 5 × [ ( 1 × 2 ) + ( 2 × 4 ) + ( 3 × 6 ) + ( 4 × 8 ) + ( 5 × 10 ) ] = − 2 5 × 110 = − 44 \frac{\partial MSE}{\partial w} \\= \frac{-2}{5} \times[(1 \times 2) + (2 \times 4) + (3 \times 6) + (4 \times 8) + (5 \times 10)] \\= \frac{-2}{5} \times 110 \\= -44 ∂w∂MSE=5−2×[(1×2)+(2×4)+(3×6)+(4×8)+(5×10)]=5−2×110=−44
∂ M S E ∂ b = − 2 5 × ( 2 + 4 + 6 + 8 + 10 ) = − 2 5 × 30 = − 12 \frac{\partial MSE}{\partial b} \\= \frac{-2}{5} \times(2+4+6+8+10) \\= \frac{-2}{5} \times 30 \\= -12 ∂b∂MSE=5−2×(2+4+6+8+10)=5−2×30=−12
参数更新
参数更新公式:
w n e w = w o l d − L e a r n i n g R a t e × ∂ l o s s ∂ w w_{new} = w_{old} - LearningRate\times \frac{\partial loss}{\partial w} wnew=wold−LearningRate×∂w∂loss
b n e w = b o l d − L e a r n i n g R a t e × ∂ l o s s ∂ b b_{new} = b_{old} - LearningRate\times \frac{\partial loss}{\partial b} bnew=bold−LearningRate×∂b∂loss
代入 ∂ M S E ∂ w = − 44 \frac{\partial MSE}{\partial w} = -44 ∂w∂MSE=−44 和 ∂ M S E ∂ b = − 12 \frac{\partial MSE}{\partial b} = -12 ∂b∂MSE=−12:
w n e w = 0 − 0.01 × ∂ l o s s ∂ w = 0 − 0.01 × − 44 = 0.44 w_{new} = 0 - 0.01 \times \frac{\partial loss}{\partial w} = 0 - 0.01 \times -44 = 0.44 wnew=0−0.01×∂w∂loss=0−0.01×−44=0.44
b n e w = 0 − 0.01 × ∂ l o s s ∂ b = 0 − 0.01 × − 12 = 0.12 b_{new} = 0 - 0.01 \times \frac{\partial loss}{\partial b} = 0 - 0.01 \times -12 = 0.12 bnew=0−0.01×∂b∂loss=0−0.01×−12=0.12
这样我们就完成了一次迭代. 为了得到更准确的权重, 我们需要迭代多次对模型进行收敛. 经过多次得带, 我们会发现 w w w 趋近于 2, b b b 趋近于 0.
第 1 次迭代后: w=0.44, b=0.12
第 2 次迭代后: w=0.776, b=0.2112
第 3 次迭代后: w=1.032608, b=0.280416
第 4 次迭代后: w=1.22860928, b=0.3328512
第 5 次迭代后: w=1.3783441663999998, b=0.3724776192
第 6 次迭代后: w=1.4927597926399998, b=0.402327416832
第 7 次迭代后: w=1.5802129932492799, b=0.42471528093696004
第 8 次迭代后: w=1.6470832178782207, b=0.44140819572326406
第 9 次迭代后: w=1.6982404182016162, b=0.45375503873610556
第 10 次迭代后: w=1.7374022238730944, b=0.4627855128692865
第 11 次迭代后: w=1.7674066038488565, b=0.4692856691795151
第 12 次迭代后: w=1.7904200108513373, b=0.4738555595649934
第 13 次迭代后: w=1.8080962748901435, b=0.4769532477226133
第 14 次迭代后: w=1.8216978995509552, b=0.47892840627475247
第 15 次迭代后: w=1.83218865727326, b=0.4800479641762001
第 16 次迭代后: w=1.8403042748225709, b=0.48051568545628054
第 17 次迭代后: w=1.8466063932342285, b=0.4804871152578007
第 18 次迭代后: w=1.8515237598072303, b=0.48008098935859095
第 19 次迭代后: w=1.8553836732881241, b=0.47938794398298534
第 20 次迭代后: w=1.8584359885257578, b=0.4784771647060382
第 21 次迭代后: w=1.8608714411677287, b=0.47740146210037193
第 22 次迭代后: w=1.862835636384806, b=0.47620114638830074
第 23 次迭代后: w=1.8644397275968507, b=0.47490698527744635
第 24 次迭代后: w=1.8657685684088967, b=0.4735424619160864
第 25 次迭代后: w=1.8668869356439743, b=0.4721254985732309
第 26 次迭代后: w=1.8678442798879062, b=0.4706697724631278
第 27 次迭代后: w=1.8686783519647792, b=0.46918572022059085
第 28 次迭代后: w=1.8694179713192922, b=0.4676813046982923
第 29 次迭代后: w=1.8700851393471505, b=0.4661626003251689
第 30 次迭代后: w=1.8706966526712672, b=0.4646342399578365
实战
逻辑回归预测乳腺癌
"""
@Module Name: 逻辑回归 乳腺癌.py
@Author: CSDN@我是小白呀
@Date: October 19, 2023Description:
逻辑回归 乳腺癌
"""
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report# 加载数据
data = load_breast_cancer()
X = data.data
y = data.target# 调试输出数据基本信息
print("输出特征:", X[:5])
print("输出标签:", y[:5])# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)# 标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 训练
clf = LogisticRegression(random_state=42)
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 模型评估
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
report = classification_report(y_test, y_pred)print("acc:", accuracy)
print("\n混淆矩阵:\n", conf_matrix)
print("\nClassification Report:\n", report)
输出结果:
输出特征: [[1.799e+01 1.038e+01 1.228e+02 1.001e+03 1.184e-01 2.776e-01 3.001e-011.471e-01 2.419e-01 7.871e-02 1.095e+00 9.053e-01 8.589e+00 1.534e+026.399e-03 4.904e-02 5.373e-02 1.587e-02 3.003e-02 6.193e-03 2.538e+011.733e+01 1.846e+02 2.019e+03 1.622e-01 6.656e-01 7.119e-01 2.654e-014.601e-01 1.189e-01][2.057e+01 1.777e+01 1.329e+02 1.326e+03 8.474e-02 7.864e-02 8.690e-027.017e-02 1.812e-01 5.667e-02 5.435e-01 7.339e-01 3.398e+00 7.408e+015.225e-03 1.308e-02 1.860e-02 1.340e-02 1.389e-02 3.532e-03 2.499e+012.341e+01 1.588e+02 1.956e+03 1.238e-01 1.866e-01 2.416e-01 1.860e-012.750e-01 8.902e-02][1.969e+01 2.125e+01 1.300e+02 1.203e+03 1.096e-01 1.599e-01 1.974e-011.279e-01 2.069e-01 5.999e-02 7.456e-01 7.869e-01 4.585e+00 9.403e+016.150e-03 4.006e-02 3.832e-02 2.058e-02 2.250e-02 4.571e-03 2.357e+012.553e+01 1.525e+02 1.709e+03 1.444e-01 4.245e-01 4.504e-01 2.430e-013.613e-01 8.758e-02][1.142e+01 2.038e+01 7.758e+01 3.861e+02 1.425e-01 2.839e-01 2.414e-011.052e-01 2.597e-01 9.744e-02 4.956e-01 1.156e+00 3.445e+00 2.723e+019.110e-03 7.458e-02 5.661e-02 1.867e-02 5.963e-02 9.208e-03 1.491e+012.650e+01 9.887e+01 5.677e+02 2.098e-01 8.663e-01 6.869e-01 2.575e-016.638e-01 1.730e-01][2.029e+01 1.434e+01 1.351e+02 1.297e+03 1.003e-01 1.328e-01 1.980e-011.043e-01 1.809e-01 5.883e-02 7.572e-01 7.813e-01 5.438e+00 9.444e+011.149e-02 2.461e-02 5.688e-02 1.885e-02 1.756e-02 5.115e-03 2.254e+011.667e+01 1.522e+02 1.575e+03 1.374e-01 2.050e-01 4.000e-01 1.625e-012.364e-01 7.678e-02]]
输出标签: [0 0 0 0 0]
acc: 0.9649122807017544混淆矩阵:[[45 2][ 2 65]]Classification Report:precision recall f1-score support0 0.96 0.96 0.96 471 0.97 0.97 0.97 67accuracy 0.96 114macro avg 0.96 0.96 0.96 114
weighted avg 0.96 0.96 0.96 114
逻辑回归 鸢尾花
"""
@Module Name: 逻辑回归 鸢尾花.py
@Author: CSDN@我是小白呀
@Date: October 19, 2023Description:
逻辑回归 鸢尾花
"""
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report# 加载数据
data = load_iris()
X = data.data
y = data.target# 调试输出数据基本信息
print("输出特征:", X[:5])
print("输出标签:", y[:5])# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)# 标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 训练
clf = LogisticRegression(random_state=42)
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 模型评估
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
report = classification_report(y_test, y_pred)print("acc:", accuracy)
print("\n混淆矩阵:\n", conf_matrix)
print("\nClassification Report:\n", report)
输出结果:
输出特征: [[5.1 3.5 1.4 0.2][4.9 3. 1.4 0.2][4.7 3.2 1.3 0.2][4.6 3.1 1.5 0.2][5. 3.6 1.4 0.2]]
输出标签: [0 0 0 0 0]
acc: 1.0混淆矩阵:[[11 0 0][ 0 13 0][ 0 0 6]]Classification Report:precision recall f1-score support0 1.00 1.00 1.00 111 1.00 1.00 1.00 132 1.00 1.00 1.00 6accuracy 1.00 30macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
手搓逻辑回归
"""
@Module Name: 手把手教你实现逻辑回归.py
@Author: CSDN@我是小白呀
@Date: October 19, 2023Description:
手把手教你实现逻辑回归
"""
class LogisticRegression:def __init__(self, learning_rate=0.01, num_iterations=1000):"""初始化参数:param learning_rate: 学习率:param num_iterations: 迭代次数"""self.learning_rate = learning_rateself.num_iterations = num_iterationsself.weights = Noneself.bias = 0def _sigmoid(self, z):"""sigmoid 激活函数:param z: 值:return: 0-1概率"""return 1 / (1 + self._exp(-z))def _exp(self, value):# 实现指数函数, 为了防止溢出if value.any() < -100:return 0.0else:return 2.718281828459045 ** valuedef fit(self, X, y):"""训练模型:param X: 特征:param y: 标签:return:"""num_samples, num_features = X.shapeself.weights = [0] * num_featuresfor _ in range(self.num_iterations):model_output = self._predict(X)# 计算梯度d_weights = (1 / num_samples) * (X.T.dot(model_output - y))d_bias = (1 / num_samples) * sum(model_output - y)# 更新权重和偏置self.weights -= self.learning_rate * d_weightsself.bias -= self.learning_rate * d_biasdef predict(self, X):"""预测:param X: 特征:return: 预测值"""linear_model_output = X.dot(self.weights) + self.biasreturn [1 if i > 0.5 else 0 for i in self._sigmoid(linear_model_output)]def _predict(self, X):linear_model_output = X.dot(self.weights) + self.biasreturn self._sigmoid(linear_model_output)if __name__ == '__main__':from sklearn.datasets import load_breast_cancerfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.metrics import accuracy_score, confusion_matrix, classification_report# 加载数据data = load_breast_cancer()X = data.datay = data.target# 调试输出数据基本信息print("输出特征:", X[:5])print("输出标签:", y[:5])# 分割数据集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)# 标准化scaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)# 训练clf = LogisticRegression()clf.fit(X_train, y_train)# 预测y_pred = clf.predict(X_test)# 模型评估accuracy = accuracy_score(y_test, y_pred)conf_matrix = confusion_matrix(y_test, y_pred)report = classification_report(y_test, y_pred)print("acc:", accuracy)print("\n混淆矩阵:\n", conf_matrix)print("\nClassification Report:\n", report)
输出结果:
输出特征: [[1.799e+01 1.038e+01 1.228e+02 1.001e+03 1.184e-01 2.776e-01 3.001e-011.471e-01 2.419e-01 7.871e-02 1.095e+00 9.053e-01 8.589e+00 1.534e+026.399e-03 4.904e-02 5.373e-02 1.587e-02 3.003e-02 6.193e-03 2.538e+011.733e+01 1.846e+02 2.019e+03 1.622e-01 6.656e-01 7.119e-01 2.654e-014.601e-01 1.189e-01][2.057e+01 1.777e+01 1.329e+02 1.326e+03 8.474e-02 7.864e-02 8.690e-027.017e-02 1.812e-01 5.667e-02 5.435e-01 7.339e-01 3.398e+00 7.408e+015.225e-03 1.308e-02 1.860e-02 1.340e-02 1.389e-02 3.532e-03 2.499e+012.341e+01 1.588e+02 1.956e+03 1.238e-01 1.866e-01 2.416e-01 1.860e-012.750e-01 8.902e-02][1.969e+01 2.125e+01 1.300e+02 1.203e+03 1.096e-01 1.599e-01 1.974e-011.279e-01 2.069e-01 5.999e-02 7.456e-01 7.869e-01 4.585e+00 9.403e+016.150e-03 4.006e-02 3.832e-02 2.058e-02 2.250e-02 4.571e-03 2.357e+012.553e+01 1.525e+02 1.709e+03 1.444e-01 4.245e-01 4.504e-01 2.430e-013.613e-01 8.758e-02][1.142e+01 2.038e+01 7.758e+01 3.861e+02 1.425e-01 2.839e-01 2.414e-011.052e-01 2.597e-01 9.744e-02 4.956e-01 1.156e+00 3.445e+00 2.723e+019.110e-03 7.458e-02 5.661e-02 1.867e-02 5.963e-02 9.208e-03 1.491e+012.650e+01 9.887e+01 5.677e+02 2.098e-01 8.663e-01 6.869e-01 2.575e-016.638e-01 1.730e-01][2.029e+01 1.434e+01 1.351e+02 1.297e+03 1.003e-01 1.328e-01 1.980e-011.043e-01 1.809e-01 5.883e-02 7.572e-01 7.813e-01 5.438e+00 9.444e+011.149e-02 2.461e-02 5.688e-02 1.885e-02 1.756e-02 5.115e-03 2.254e+011.667e+01 1.522e+02 1.575e+03 1.374e-01 2.050e-01 4.000e-01 1.625e-012.364e-01 7.678e-02]]
输出标签: [0 0 0 0 0]
acc: 0.9649122807017544混淆矩阵:[[45 2][ 2 65]]Classification Report:precision recall f1-score support0 0.96 0.96 0.96 471 0.97 0.97 0.97 67accuracy 0.96 114macro avg 0.96 0.96 0.96 114
weighted avg 0.96 0.96 0.96 114



![2023年中国精准护肤发展现状及趋势分析:未来皮肤实现定制化诊断成趋势[图]](https://img-blog.csdnimg.cn/img_convert/a09834b0e39b31014cadeb180cdc69fd.png)







![2023年中国粘度指数改进剂行业需求现状及前景分析[图]](https://img-blog.csdnimg.cn/img_convert/793e6aed00a3b74dd57974b0e85a5ece.png)