前言
在现代的企业应用开发中,数据库是不可或缺的一部分。而对于大部分的应用程序来说,与数据库的交互涉及到频繁的连接、查询和事务操作。为了提高应用程序的性能和可扩展性,使用连接池来管理数据库连接是一个不错的选择。而 Spring 框架提供了对数据源(连接池)的整合和管理的支持,使得我们能够更加方便地使用和配置数据库连接池。
本文将介绍如何在 Spring 中整合和配置数据源(连接池),以及一些常用的连接池选项和最佳实践。通过本文的指导,您将能够正确配置和使用连接池,提高应用程序的性能和可靠性。
一、开始学习
本文将介绍两种配置方式,一个是 xml 配置,一个是 Java 配置类配置。
1、xml 配置
在Spring框架中,我们可以使用XML配置文件来整合Druid数据源连接池。Druid是一个高性能、可扩展的数据库连接池,具有强大的监控和统计功能。那我们就来开始学习吧。
2、新建项目,结构如下
3、导入相关依赖
<dependencies><!-- https://mvnrepository.com/artifact/com.alibaba/druid --><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.15</version></dependency><!-- spring 的核心依赖 --><!-- https://mvnrepository.com/artifact/org.springframework/spring-context --><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.3.23</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-jdbc</artifactId><version>5.3.23</version></dependency><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.4.5</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.33</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.30</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13.2</version><scope>test</scope></dependency></dependencies>
com.alibaba:druid:1.2.15:Druid是一个高性能的数据库连接池,这个依赖提供了Druid的相关类和功能。
org.springframework:spring-context:5.3.23:Spring框架的核心依赖,提供了Spring IoC和AOP等基础功能。
org.springframework:spring-jdbc:5.3.23:在Spring框架中使用JDBC时所需的依赖。
ch.qos.logback:logback-classic:1.4.5:logback是一个灵活的日志框架,logback-classic是logback最常用的实现之一,提供了SLF4J API和log4j API的实现。
mysql:mysql-connector-java:8.0.33:MySQL数据库的Java驱动程序。
org.projectlombok:lombok:1.18.30:Lombok是一个开源的Java库,通过注解来简化Java代码。
junit:junit:4.13.2:JUnit是一个流行的Java单元测试框架,提供了断言、异常处理、参数化测试等功能。
这些依赖项组成了一个Java应用程序所需的基本组件,包括数据库连接、IoC和AOP容器、日志记录、Java Lombok库和单元测试框架等。每个依赖项都提供了不同的功能和实现,可以帮助我们更快、更简单地开发Java应用程序。
4、在 resources 包下新建一个 beans.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"><!-- 整合 druid 数据源连接池,其中将 DruidDataSource 核心类纳入spring 容器中管理,并指定相关的初始化方法以及销毁方法--><bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"><!-- 注入相关的连接属性 --><property name="driverClassName" value="com.mysql.cj.jdbc.Driver"/><property name="url" value="jdbc:mysql://localhost:3306/psm"/><property name="username" value="root"/><property name="password" value="123456"/><!-- 注入连接池的相关配置属性 --><!-- 最大连接池数量 --><property name="maxActive" value="200"/><!-- 预先初始化 5 个连接放入连接池 --><property name="initialSize" value="5"/><!-- 最小空闲连接数 --><property name="minIdle" value="5"/><!-- 获取连接的最大等待时间,单位:毫秒 --><property name="maxWait" value="2000"/><!-- 连接保持空闲而不被驱逐出连接池的最小时间,单位:毫秒 --><property name="minEvictableIdleTimeMillis" value="300000"/><!-- 检测连接的间隔时间,单位:毫秒 --><property name="timeBetweenEvictionRunsMillis" value="60000"/><!-- 检测连接是否有效 --><property name="testWhileIdle" value="true"/><!-- 放回连接池时是否检查连接的有效性 --><property name="testOnReturn" value="false"/><!-- 定义一条伪 SQL,用于检查连接时是否可用 --><property name="validationQuery" value="select 1"/><!-- 是否缓存 PreparedStatements,MySQL 建议关闭 --><property name="poolPreparedStatements" value="false"/></bean></beans>这是一个使用Spring框架整合Druid数据源连接池的配置文件。以下是配置文件的主要内容:
使用
<bean>标签定义了一个名为"dataSource"的Bean,并指定了它的类为com.alibaba.druid.pool.DruidDataSource。该Bean在初始化时会调用init-method属性指定的方法进行初始化,在销毁时调用destroy-method属性指定的方法进行资源释放。使用
<property>标签注入了相关的连接属性,包括驱动类名、数据库URL、用户名和密码。使用
<property>标签注入了连接池的配置属性,包括最大连接池数量、预先初始化连接数、最小空闲连接数、获取连接的最大等待时间等。其他属性包括连接保持空闲时间、检测连接的间隔时间、是否检测连接的有效性等。
最后使用
<property>标签设置了一个伪SQL语句,用于检查连接是否可用。
通过这个配置文件,我们可以将Druid数据源连接池纳入Spring容器管理,并通过IoC方式注入到其他需要使用数据库连接的组件中。这样可以更方便地管理和使用数据库连接,并提供了一些连接池的相关配置选项。
5、测试
@Slf4j
public class Main {public static void main(String[] args) throws SQLException {ApplicationContext context = new ClassPathXmlApplicationContext("beans.xml");// 从容器中获取数据源(连接池)DruidDataSource ds = (DruidDataSource) context.getBean(DataSource.class);log.info("初始化连接数:" + ds.getInitialSize());log.info("最小空闲连接数:" + ds.getMinIdle());log.info("最大连接数:" + ds.getMaxActive());// 从数据源中获取链接Connection conn = ds.getConnection();log.info("连接对象:" + conn);}}
在
main函数中,通过ClassPathXmlApplicationContext类加载了名为"beans.xml"的Spring配置文件并创建了ApplicationContext对象。通过
getBean方法从容器中获取了名为"dataSource"的Bean,并将其强制转换成DruidDataSource类型。通过
DruidDataSource对象的一些公共方法获取了连接池的一些配置参数,包括初始化连接数、最小空闲连接数、最大连接数等,并将它们输出到控制台上。通过
DruidDataSource对象的getConnection方法获取了一个数据库连接,并将其输出到控制台上。
通过这个示例代码,我们可以看到如何使用Spring框架整合Druid数据源连接池,并通过IoC方式将其纳入到Spring容器中进行统一管理。同时也可以看到如何使用DruidDataSource对象获取连接池的一些配置信息以及获取数据库连接的方法。
运行结果

二、使用 Java 配置类来整合数据源(连接池)(使用 @Value注解)
1、在 resources 包下新建一个 druid.properties 资源文件
driver = com.mysql.cj.jdbc.Driver
url = jdbc:mysql://localhost:3306/psm?useUnicode=true&characterEncoding=utf-8&useSSL=false&timeZone=Asia/Shanghai
name= root
password = 123456
maxActive = 200
initialSize = 5
minIdle = 5
maxWait = 2000
minEvictableIdleTimeMillis = 300000
timeBetweenEvictionRunsMillis = 60000
testWhileIdle = true
testOnReturn = false
validationQuery = select 1
poolPreparedStatements = false这些属性是用于配置Druid连接池的相关参数,具体含义如下:
driver:数据库驱动类的全限定名,这里指定使用MySQL数据库的驱动。url:数据库连接的URL地址,指向本地MySQL数据库。设置了useUnicode=true和characterEncoding=utf-8,表示使用UTF-8字符集编码。name:连接数据库所需的用户名,这里设置为"root"。注意:这里本来是 username ,为什么要改成 name 呢?因为写 username 的话会识别成本机的用户名,所以这里要改成 name.password:连接数据库所需的密码,这里设置为"123456"。maxActive:连接池中同时可从数据源获取的最大活跃连接数,这里设置为200,即同时最多容纳200个连接。initialSize:初始化时创建的连接数,这里设置为5。minIdle:连接池中保持的最小空闲连接数,这里设置为5。maxWait:当连接池没有可用连接时,等待获取连接的最大时间(单位:毫秒),这里设置为2000毫秒。minEvictableIdleTimeMillis:连接在池中最小空闲时间(单位:毫秒),这里设置为300000毫秒(即5分钟)。timeBetweenEvictionRunsMillis:间隔多久进行一次空闲连接的检测(单位:毫秒),这里设置为60000毫秒(即1分钟)。testWhileIdle:在连接空闲时,是否执行validationQuery检测连接是否有效,这里设置为true。testOnReturn:在归还连接到连接池时,是否执行validationQuery检测连接是否有效,这里设置为false。validationQuery:用于检测连接是否有效的SQL查询语句,这里设置为"select 1"。poolPreparedStatements:是否缓存PreparedStatement(预编译的SQL语句),这里设置为false。
通过配置这些属性,可以更好地管理和优化Druid连接池的使用。可以指定数据库连接的URL、用户名和密码,设置连接池的大小、最大活跃连接数、空闲连接数等参数,以及进行连接的有效性校验和空闲连接的检测等。
注意:这些属性不能写错,写错了就不会生效了,会报错。
2、在 config 包下新建一个 AppConfig 配置类 (使用 @Value注解)
@Configuration
@PropertySource("classpath:druid.properties")
public class AppConfig {@Value("${driver}")private String driverClassName;@Value("${url}")private String url;@Value("${name}")private String name;@Value("${password}")private String password;@Value("${maxActive}")private Integer maxActive;@Value("${initialSize}")private Integer initialSize;@Value("${minIdle}")private Integer minIdle;@Value("${maxWait}")private Integer maxWait;@Value("${minEvictableIdleTimeMillis}")private Integer minEvictableIdleTimeMillis;@Value("${timeBetweenEvictionRunsMillis}")private Integer timeBetweenEvictionRunsMillis;@Value("${testWhileIdle}")private Boolean testWhileIdle;@Value("${testOnReturn}")private Boolean testOnReturn;@Value("${validationQuery}")private String validationQuery;@Value("${poolPreparedStatements}")private Boolean poolPreparedStatements;@Bean(initMethod = "init", destroyMethod = "close")public DruidDataSource dateSource() throws Exception {// 创建数据源对象DruidDataSource ds = new DruidDataSource();// 设置连接属性ds.setDriverClassName(driverClassName);ds.setUrl(url);ds.setUsername(name);ds.setPassword(password);// 设置连接池属性ds.setMaxActive(maxActive);ds.setInitialSize(initialSize);ds.setMinIdle(minIdle);ds.setMaxWait(maxWait);ds.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis);ds.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis);ds.setTestWhileIdle(testWhileIdle);ds.setTestOnReturn(testOnReturn);ds.setValidationQuery(validationQuery);ds.setPoolPreparedStatements(poolPreparedStatements);return ds;}}
这段代码是一个配置类,用于配置Druid数据源的相关属性。通过
@Value注解,从配置文件中读取相应的属性值,并将其注入到对应的成员变量中。在这段代码中,
@Value("${name}")表示从配置文件中读取名为name的属性值,并将其赋值给name变量。其他属性同理。然后通过
@Bean注解,将DruidDataSource对象作为一个Bean注册到Spring容器中,并在initMethod和destroyMethod中指定该对象的初始化方法和销毁方法。最后,在
dateSource方法中,创建一个DruidDataSource对象,设置连接属性和连接池属性,然后返回该对象。
3、测试
@Slf4j
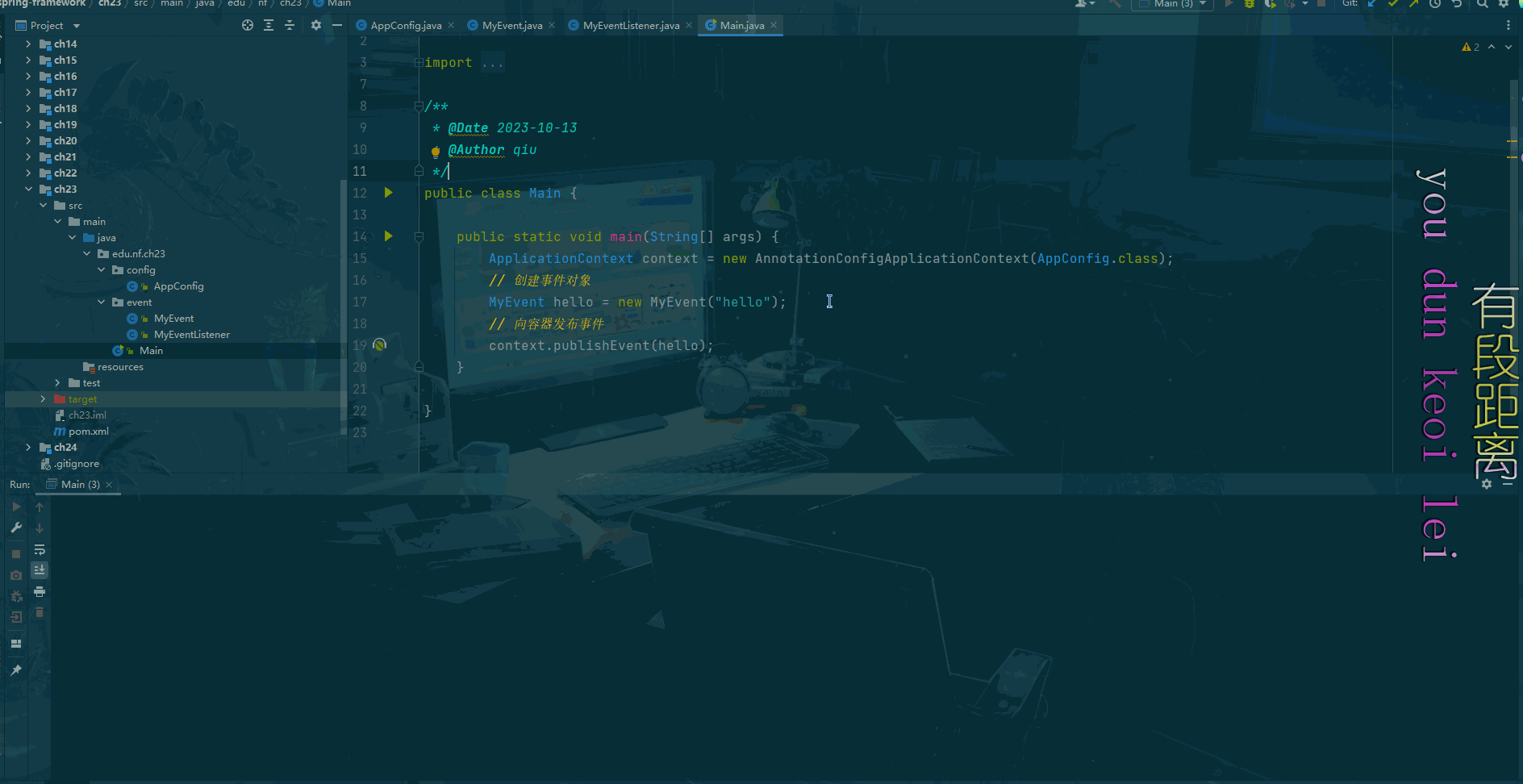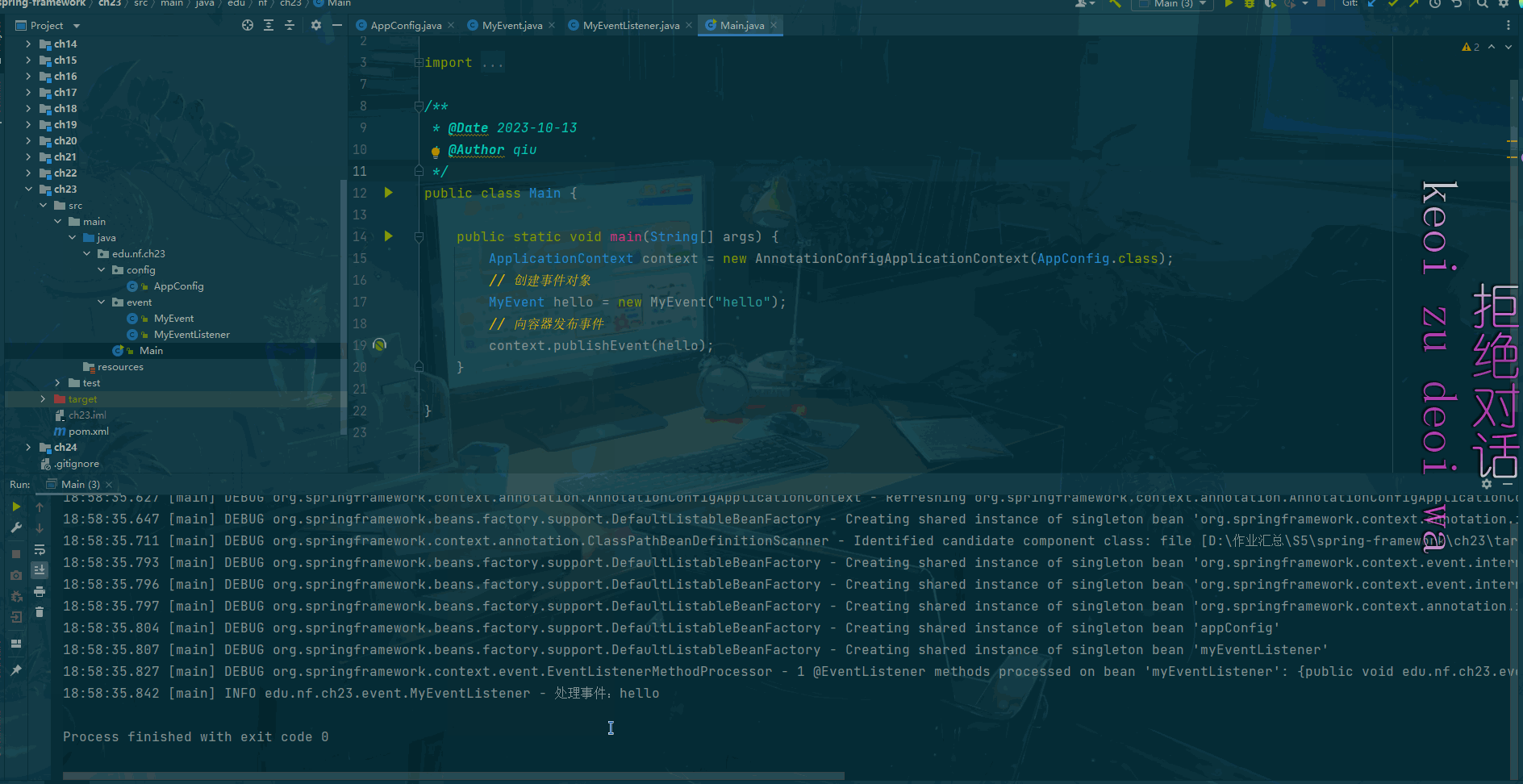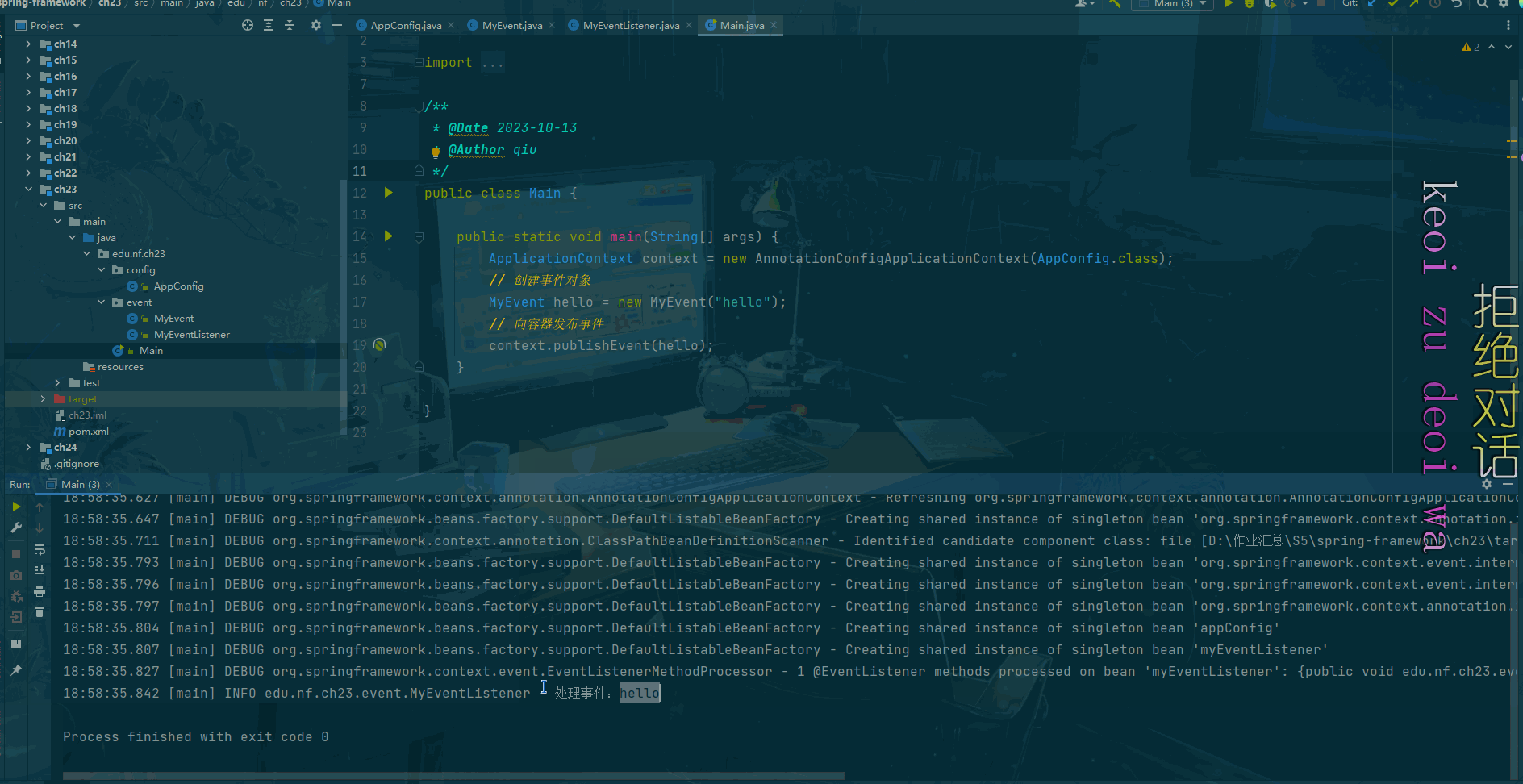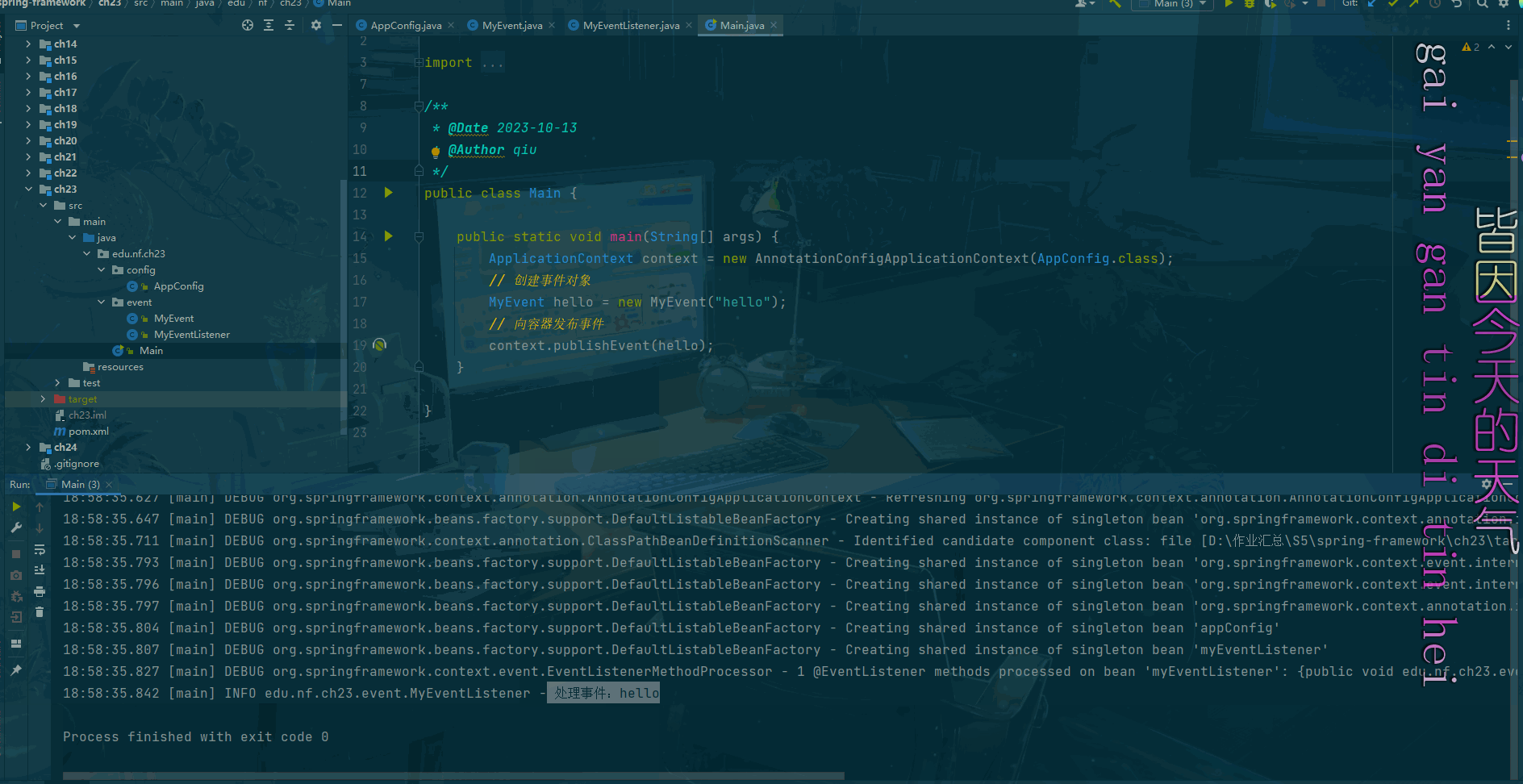
public class Main {public static void main(String[] args) throws SQLException {ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);// 从容器中获取数据源(连接池)DruidDataSource ds = (DruidDataSource) context.getBean(DataSource.class);log.info("初始化连接数:" + ds.getInitialSize());log.info("最小空闲连接数:" + ds.getMinIdle());log.info("最大连接数:" + ds.getMaxActive());// 从数据源中获取链接Connection conn = ds.getConnection();log.info("连接对象:" + conn);}}运行结果
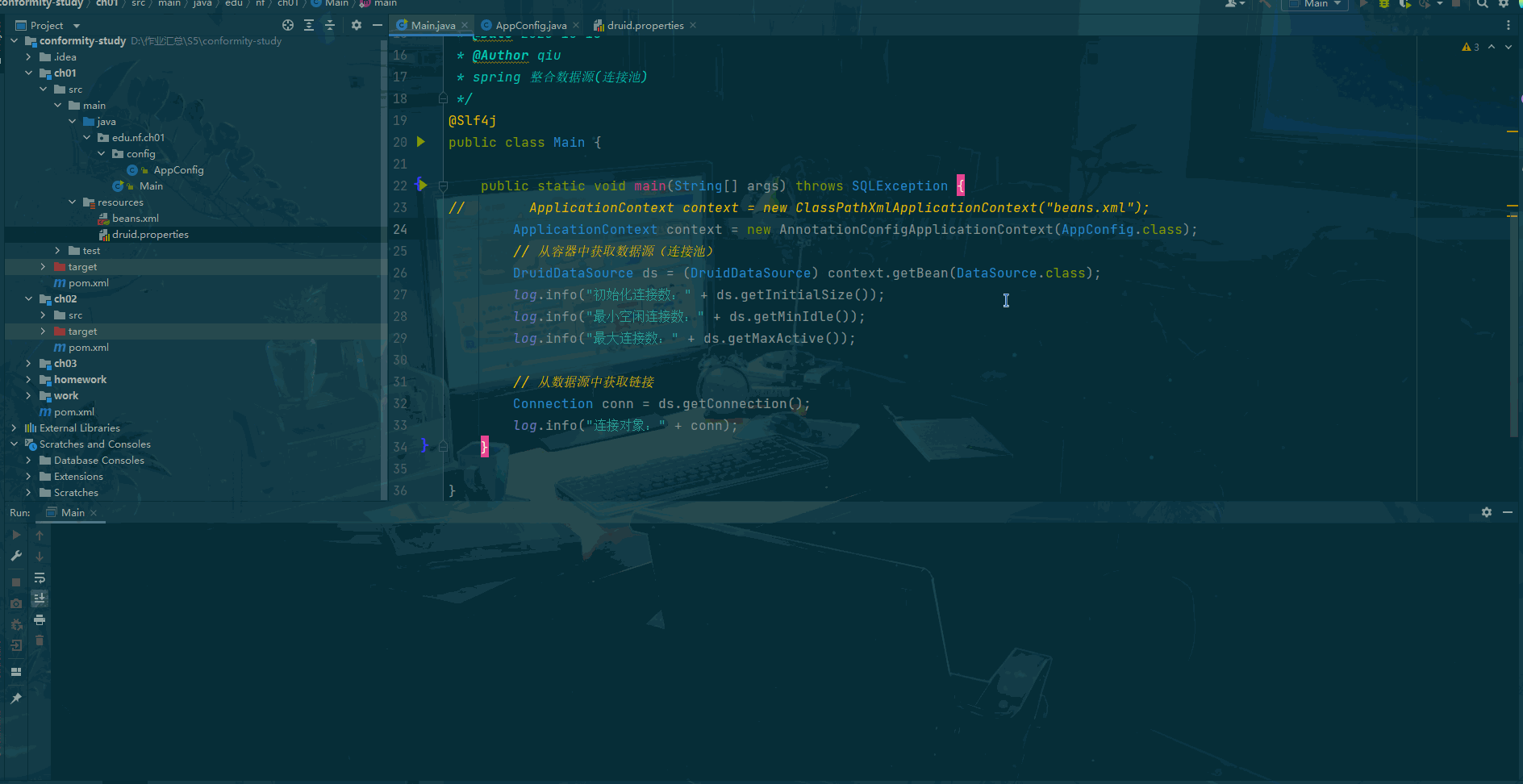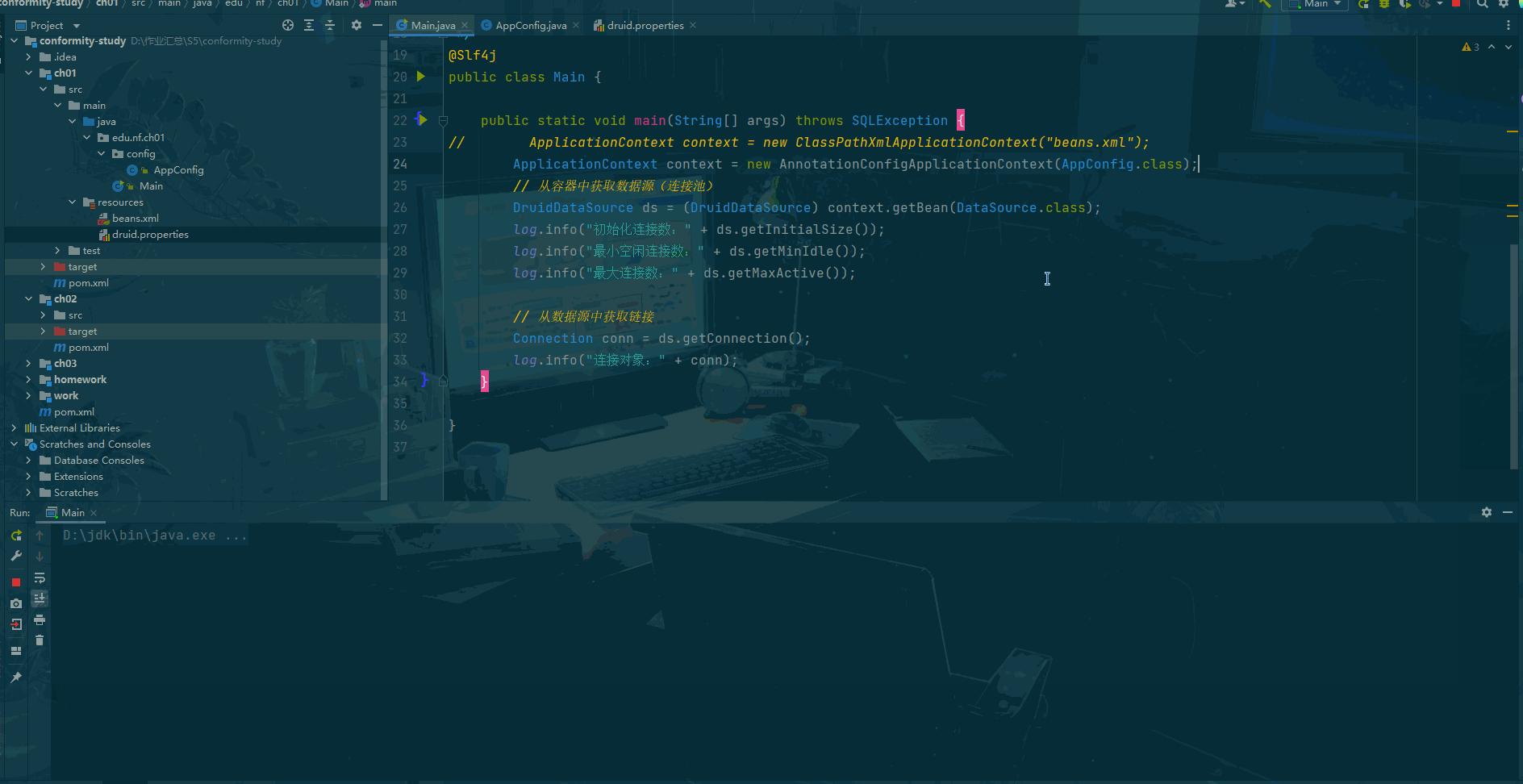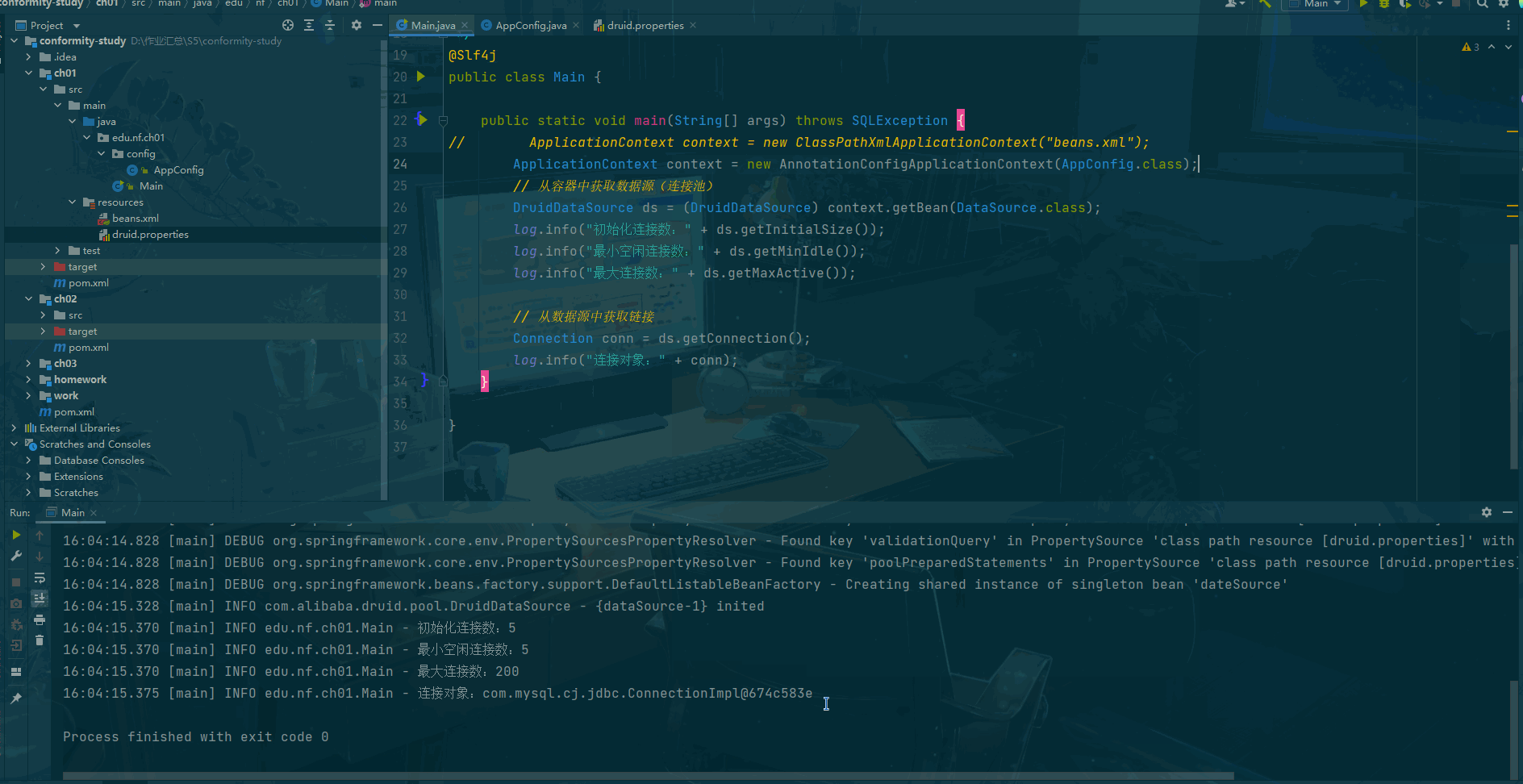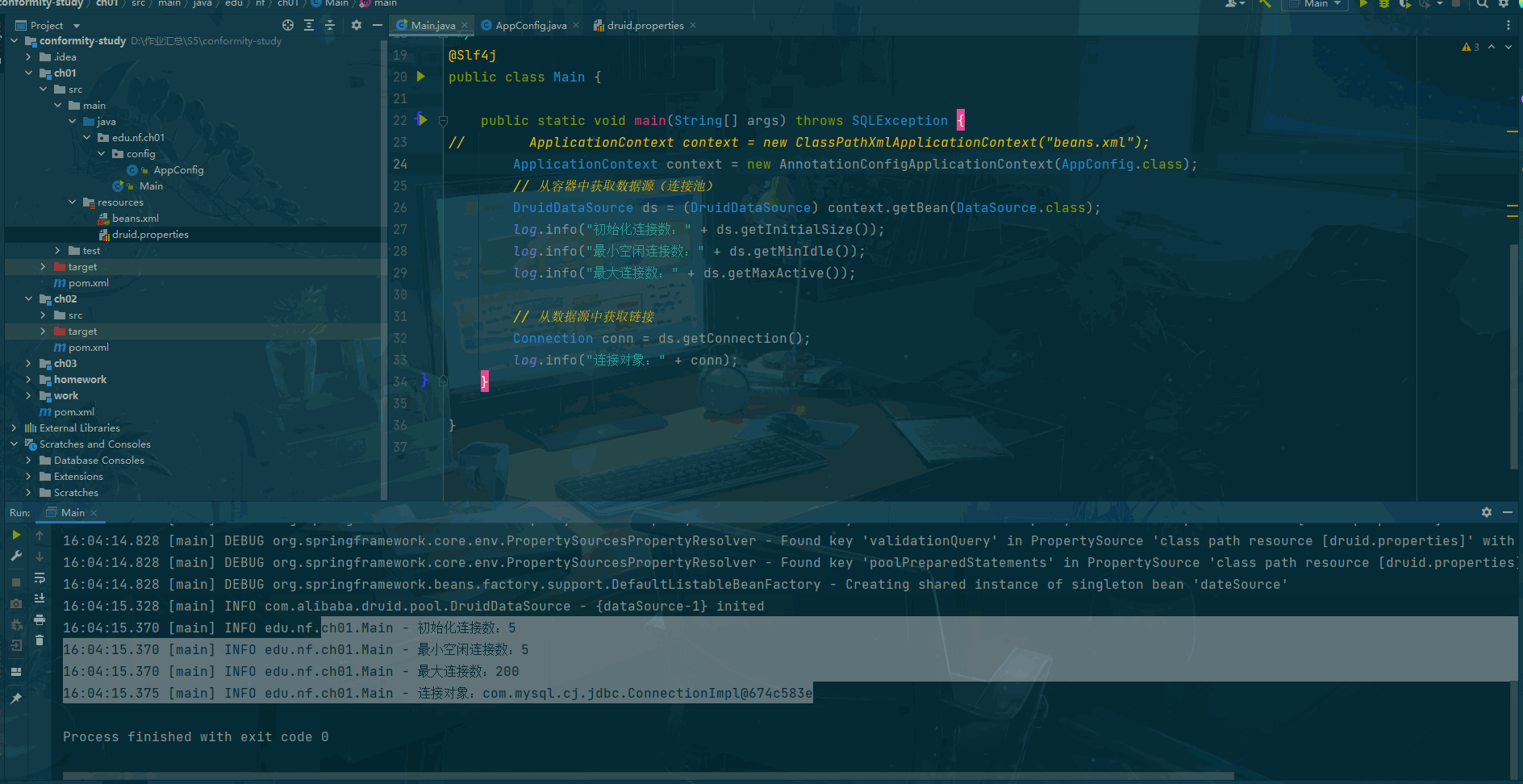
三、使用 Java 配置类的第二种方式 (推荐)
1、更改属性
username= root注意:druid.properties 文件,需要把 name 属性改为 username,因为使用输入流读取文件的时候,它会把 username 属性改为 name,不需要我们自己改了。如果是自己改成了 name的话会报错。
2、更改 AppConfig 配置类
@Configuration
public class AppConfig {@Bean(initMethod = "init", destroyMethod = "close")public DruidDataSource dateSource() throws Exception {// 创建 Properties 对象Properties prop = new Properties();// 获取一个输入流来读取 properties 文件InputStream input = AppConfig.class.getClassLoader().getResourceAsStream("druid.properties");// 将输入流加载到 properties 对象中prop.load(input);// 通过 DruidDataSourceFactory 来创建 DruidDataSource 实例DruidDataSource ds = (DruidDataSource) DruidDataSourceFactory.createDataSource(prop);return ds;}}这段代码也是用于配置Druid数据源的相关属性,但是使用了不同的方式来实现。在这里,使用了Properties类来读取配置文件中的属性值,并将其转换为DruidDataSource对象。
具体来说,@Bean注解用于将创建的DruidDataSource对象注册到Spring容器中,而类中的dateSource方法用于创建DruidDataSource对象。在该方法中,首先创建一个Properties对象,然后通过getClassLoader().getResourceAsStream("druid.properties")方法获得一个输入流,用于读取配置文件中的属性值。最后,通过调用DruidDataSourceFactory.createDataSource(prop)方法,将Properties对象转换为DruidDataSource对象,完成数据源的创建。
注意:不要写错输入流读取的 properties 文件的名字,否则无法获取到 properties 的属性。
3、测试
@Slf4j
public class Main {public static void main(String[] args) throws SQLException {ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);// 从容器中获取数据源(连接池)DruidDataSource ds = (DruidDataSource) context.getBean(DataSource.class);log.info("初始化连接数:" + ds.getInitialSize());log.info("最小空闲连接数:" + ds.getMinIdle());log.info("最大连接数:" + ds.getMaxActive());// 从数据源中获取链接Connection conn = ds.getConnection();log.info("连接对象:" + conn);}}运行结果
加上这个就是三种方式的整合了,大家根据自己的需求使用。
四、这个案例有什么有?
这个案例的用途是演示如何使用Spring框架整合Druid数据源连接池,并通过 xml 和配置文件的方式管理和获取数据库连接。具体用途包括:
连接池管理:通过将Druid数据源连接池纳入Spring容器管理,可以方便地配置连接池的相关属性,如最大连接数、最小空闲连接数等,以及自动初始化和销毁连接池。
简化数据库连接获取:使用Spring的IoC方式,可以通过注入Druid数据源连接池对象到需要数据库连接的组件中,避免手动管理数据库连接的创建和释放,简化了代码开发和维护。
配置灵活性:通过将连接池的配置属性提取到Spring配置文件中,在不修改代码的情况下可以根据需求调整连接池的配置,如增加最大连接数或调整最小空闲连接数等。
日志输出:通过使用log4j等日志库,可以方便地输出连接池初始化信息、连接对象等日志信息,便于排查数据库连接相关的问题。
总而言之,这个案例可以帮助开发人员更好地理解和使用Spring框架整合Druid数据源连接池,从而提升数据库连接的管理效率和代码的可维护性。
五、xml 配置和 Java 配置类的方式有什么区别?
在Spring中整合数据源(连接池)可以使用XML配置和Java配置类两种方式。它们有以下区别:
-
配置方式:XML配置使用XML文件来描述Bean的配置信息,而Java配置类则使用Java代码来定义Bean的配置信息。
-
语法特点:XML配置是基于标记语言的配置方式,需要遵循一定的标签和语法规则,例如使用
<bean>标签定义Bean、使用属性和子元素设置Bean的属性值等。而Java配置类则是基于编程的方式,使用Java代码进行配置,可以利用编程语言的特性进行更灵活的配置。 -
可读性和易用性:XML配置相对于Java配置类来说,更容易阅读和理解,因为它具有良好的结构和注释功能。另外,XML配置可以被非开发人员修改和管理,而不需要重新编译代码。相比之下,Java配置类虽然代码可读性较强,但对于非开发人员来说可能不太友好。
-
复杂性:XML配置在面对复杂的配置场景时,可能会变得冗长和繁琐。而Java配置类可以通过编程的方式进行逻辑判断、条件配置等,更加适合处理复杂的配置需求。
-
版本兼容性:XML配置是一种通用的配置方式,可以适用于各种版本的Spring框架。而Java配置类则需要依赖特定版本的Spring框架,较老的Spring版本可能不支持Java配置。
综上所述,选择XML配置还是Java配置类取决于个人偏好和具体的项目需求以及团队约定。一般而言,对于简单的配置场景,XML配置方式更为常见和方便;而对于复杂的配置需求或者希望利用编程灵活性的情况下,使用Java配置类更合适。
六、gitee 案例
完整代码地址:qiuqiu/conformity-study (gitee.com)