目录
- 网站地址
- 数据提取技术介绍
- 采集目标
- 流程分析
- python代码实现
- 教程和代码仅供学习交流,请勿用于其他非法用途!
- 欢迎加入python学习交流QQ群:891938703
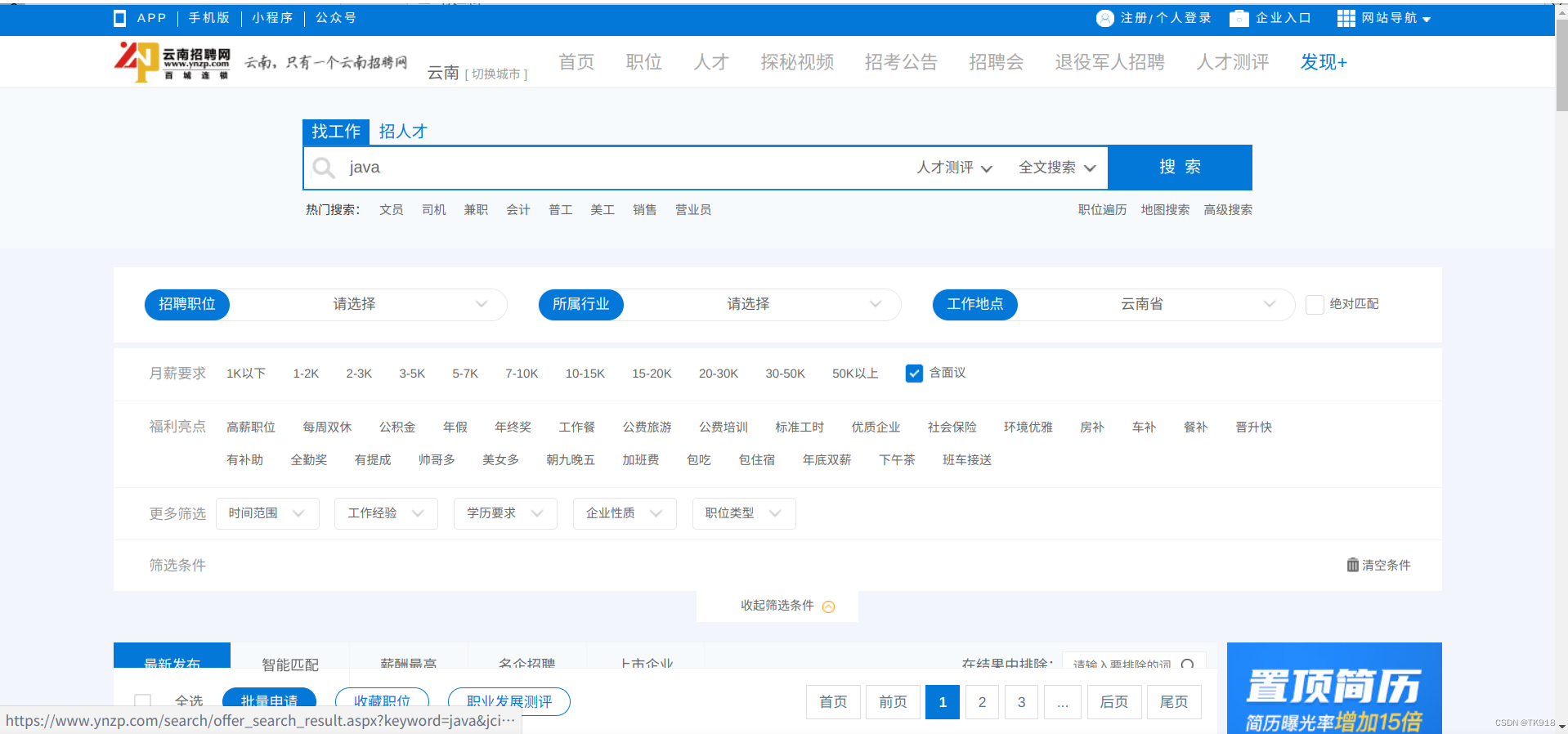
网站地址
https://www.ynzp.com/
这个网址特别适合新手拿来练习,你采集多了还有个验证码页面,验证码是4位数字,很清晰,应该用python自带的ddddorc这个库就能识别出验证码,要是你采集的数据多的话可以先用这个方法试试能不能搞定验证码,我倒是没有时间懒得试了。
数据提取技术介绍
本站点的数据是在后端就把搜索数据渲染在html页面里面,所以可以直接使用xpath来提取htnml网页的数据,没有学习的同学可以先学习一下xpath的相关知识,这里推荐一个知乎的帖子学习xpath:https://zhuanlan.zhihu.com/p/599176415?utm_id=0
保存的数据格式是csv文件,没有了解过这个格式的可以去学习一下,特别简单的一种数据存储格式(每一行内的数据用逗号分割)
采集目标
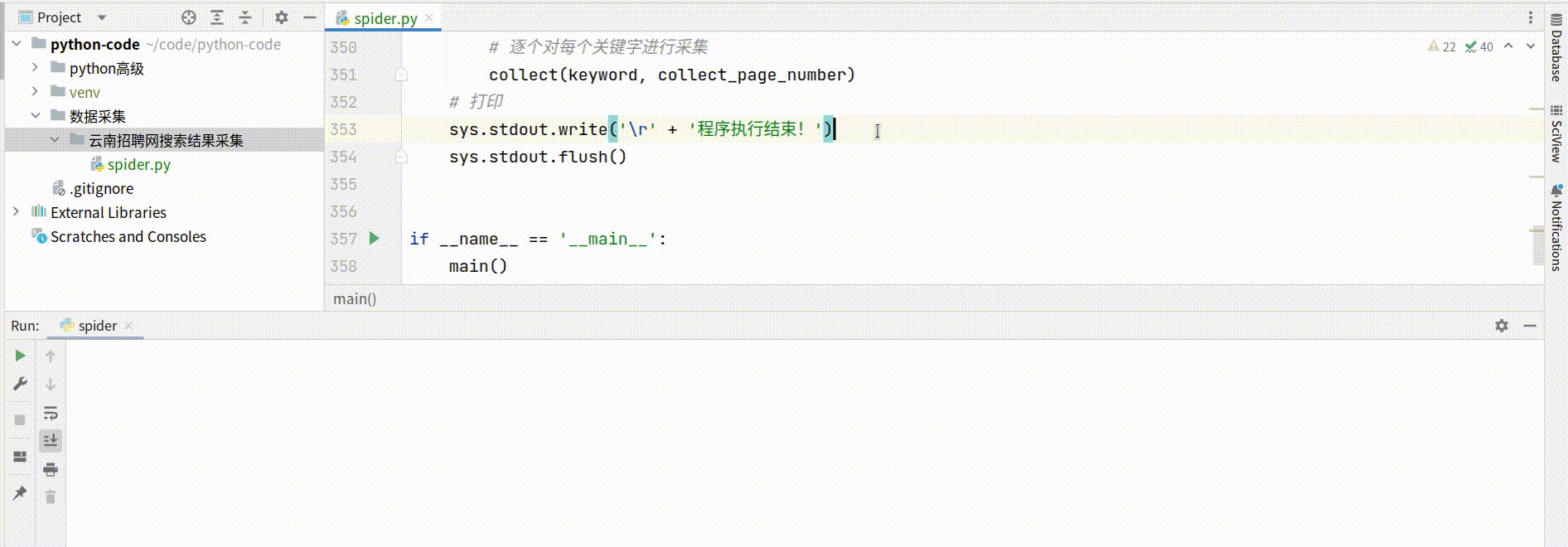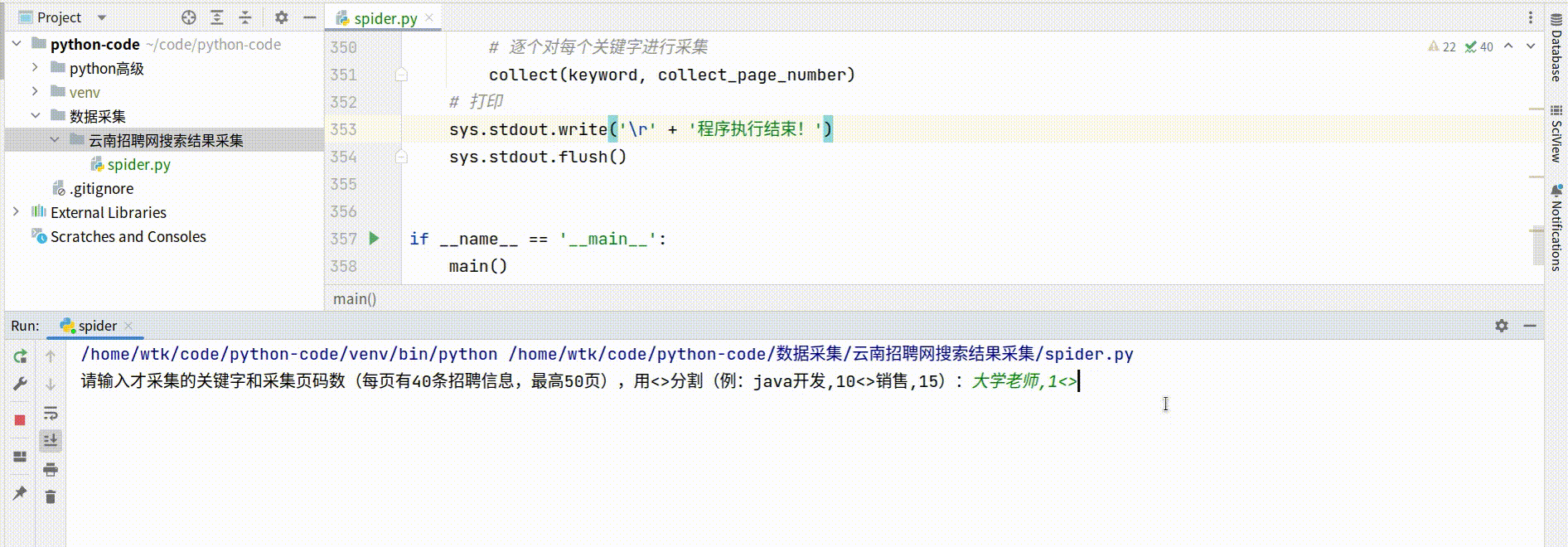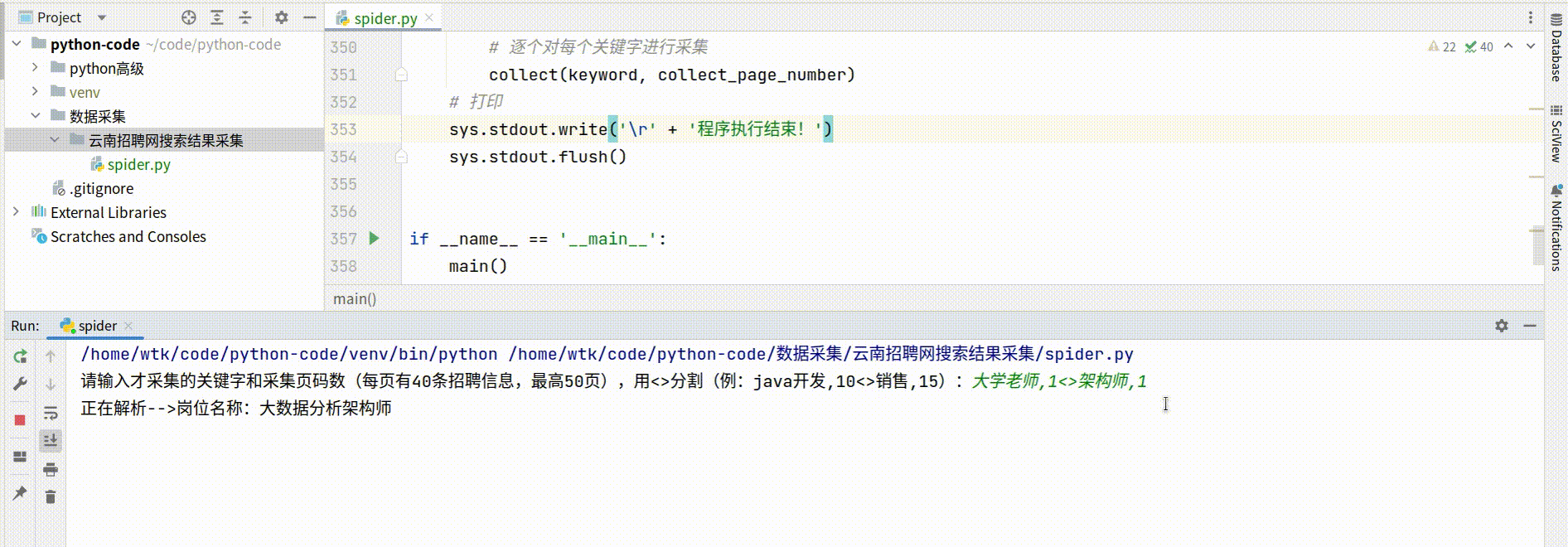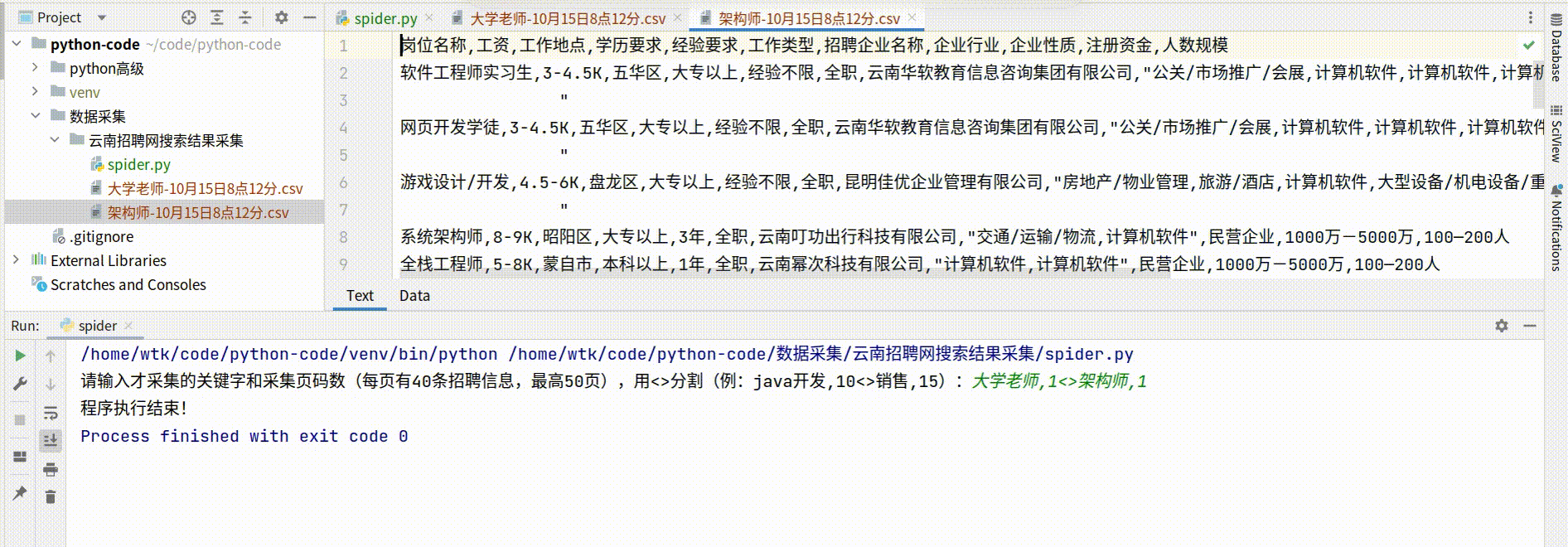
搜索结果页的数据,以及企业的一些基本信息,具体采集的字段有:岗位名称,工资,工作地点,学历要求,经验要求,工作类型,招聘企业名称,企业行业,企业性质,注册资金,人数规模。
流程分析
- 先在首页的搜索框输入岗位关键字,点击搜索,在弹出的搜索结果页面按F12键或者在网页上右键选择检查,就能打开浏览器的开发者工具了。
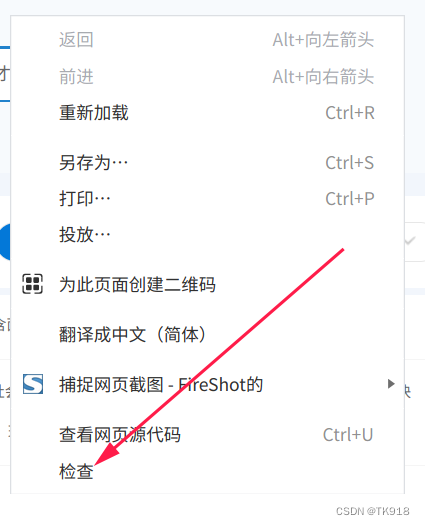
- 在弹出的开发者工具中,选择network选项
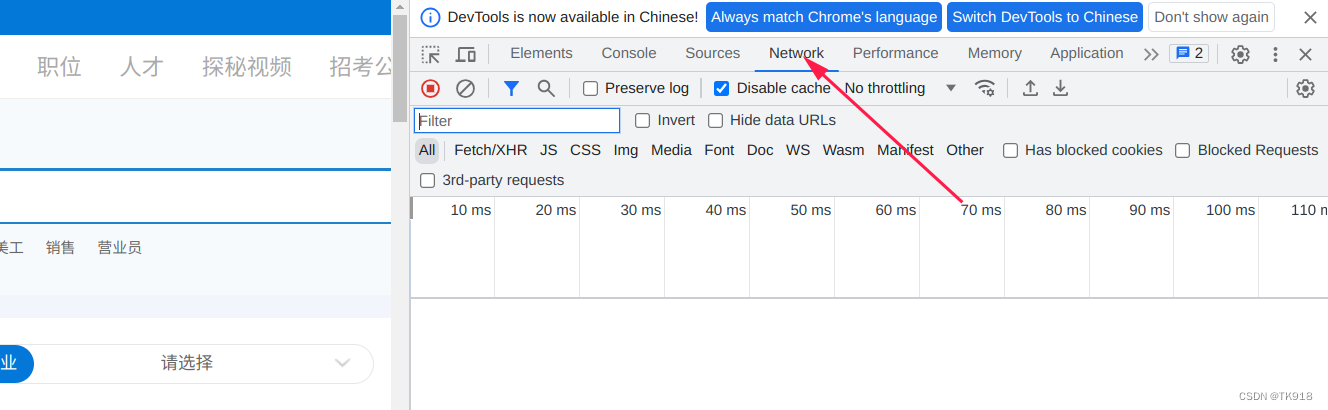
- 确定你当前窗口的链接是在搜索结果页面了,大致的url是:https://www.ynzp.com/search/offer_search_result.aspx?xxxxxxxxxxxxxxxxxxxxxxx
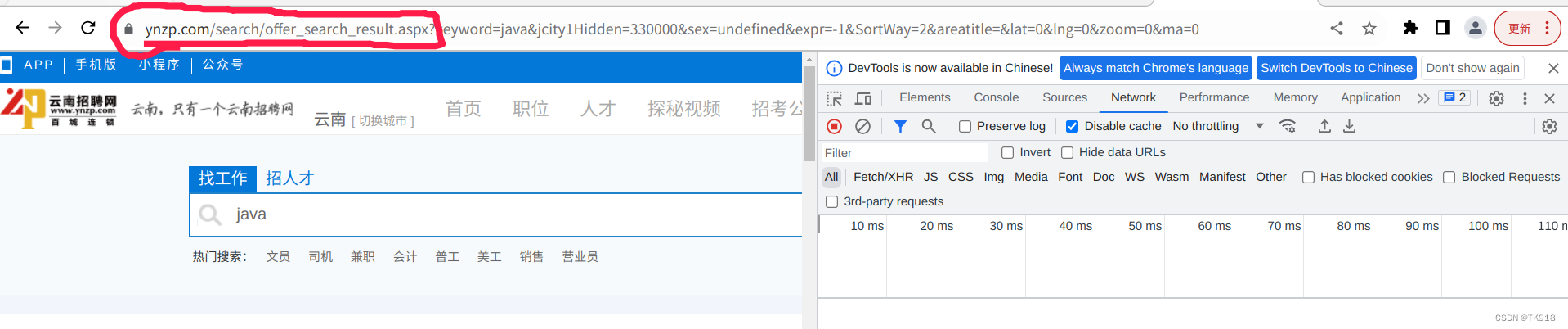
- 刷新网页,开发者工具的network选项卡就会抓取到浏览器发送给服务器的资源、网络请求
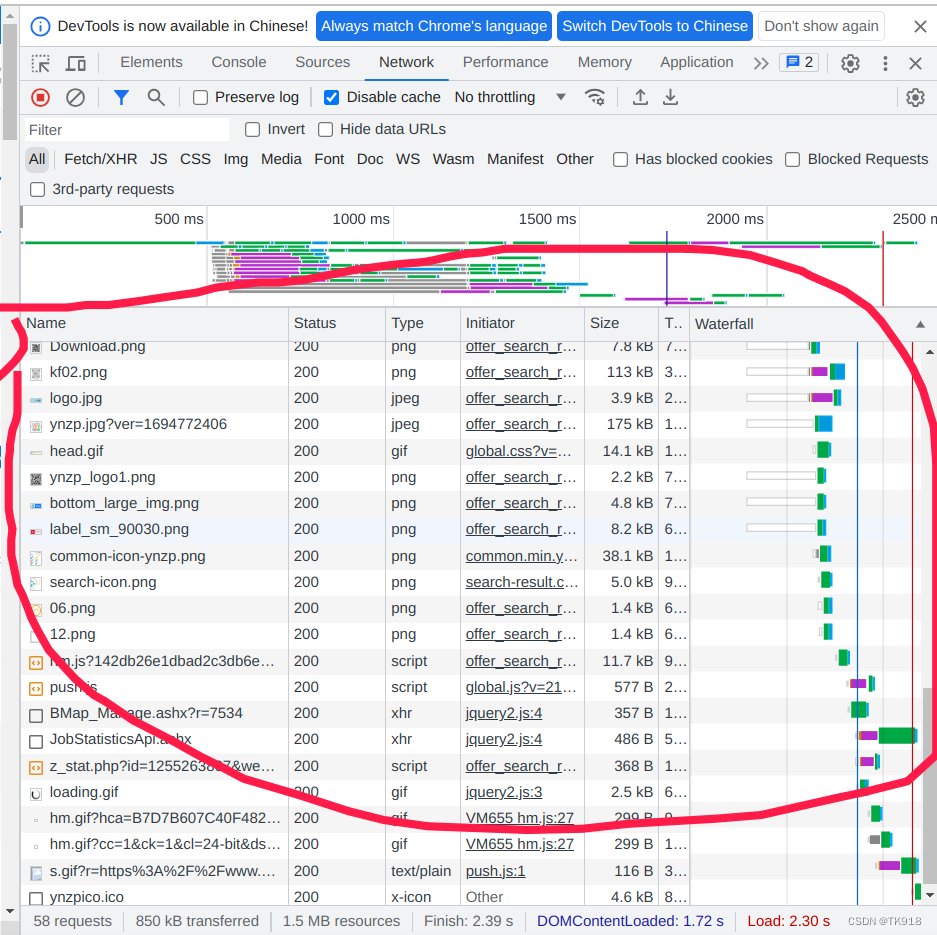
- 往上拉找到最上面的一个请求,offer_search_result.aspx,为什么上来直接找这个请求呢,可以说是经验。我们是使用网页中的搜索功能查询数据,一般url地址都会带search或者query这种字眼,比如我们要抓包网页登录请求,一般请求url都会带login字眼,我们先根据这种字眼来浏览请求信息,会提高我们的效率。
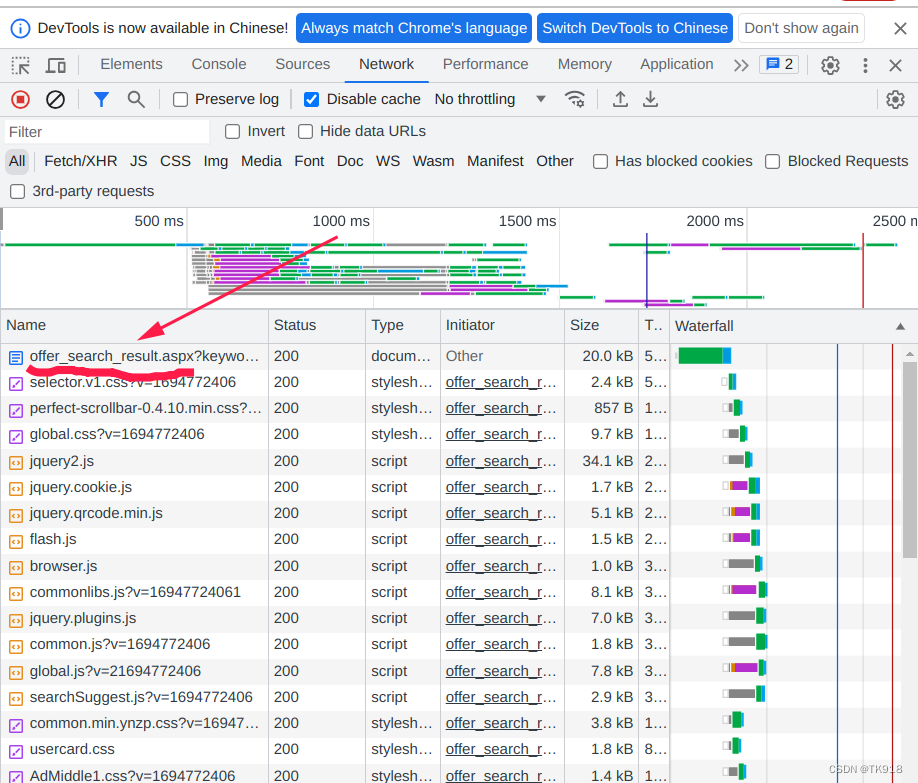
- 单击offer_search_result.aspx这个请求,查看请求的信息,首先看得出来这个请求是一个GET请求,那么一般请求的参数都会都会直接拼接在请求的url里面
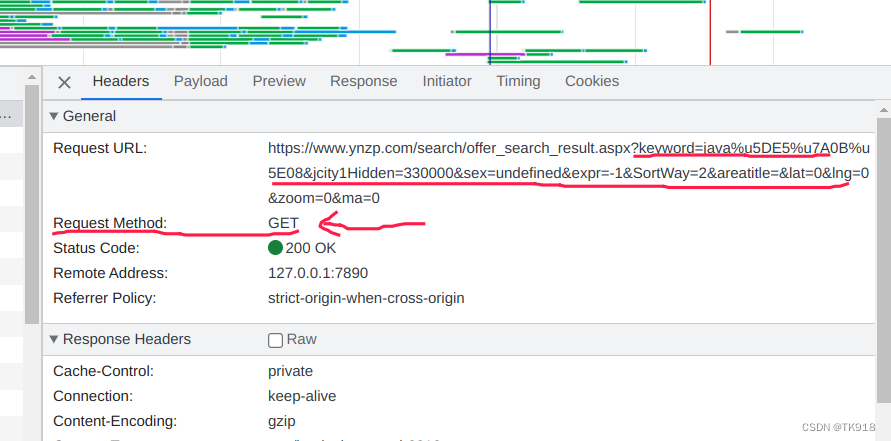
- 查看这个请求的响应信息,这一步至关重要,这里我们需要判断出这个请求的响应中是否携带我们所想要采集的数据,如果没有我们所想要的数据,那就只能排查其他的请求了。
点击response这一项

然后对照浏览器页面,大致浏览这个响应的html数据,发现我们要采集的数据已经存在响应中,就排除了岗位数据是再通过ajax这类请求获取再渲染到页面的,我们只用解析这个html即可得到我们想要的数据。

当然肯定会有同学说,这么多行代码也不好找啊,其实可以点击代码界面之后,按Ctrl+F键查找,复制网页上的目标采集数据,找得到就说明这个响应存在我们想要的数据了。

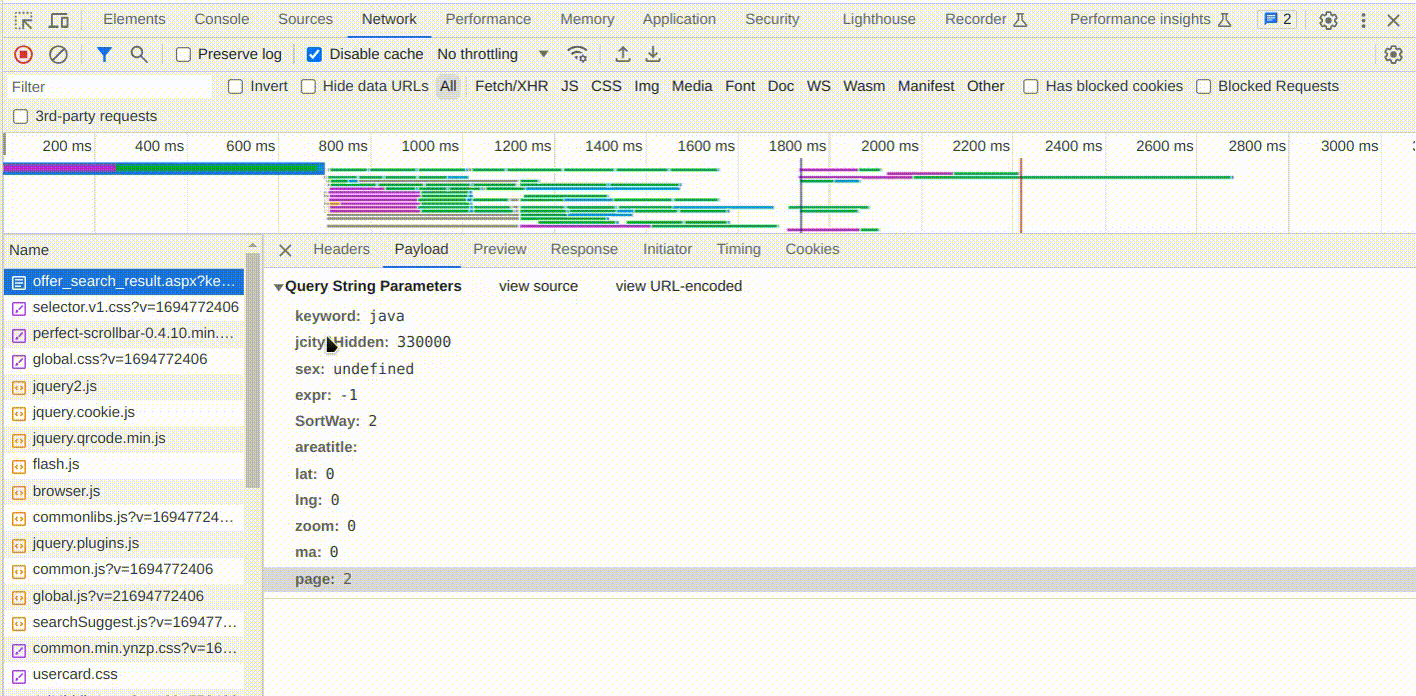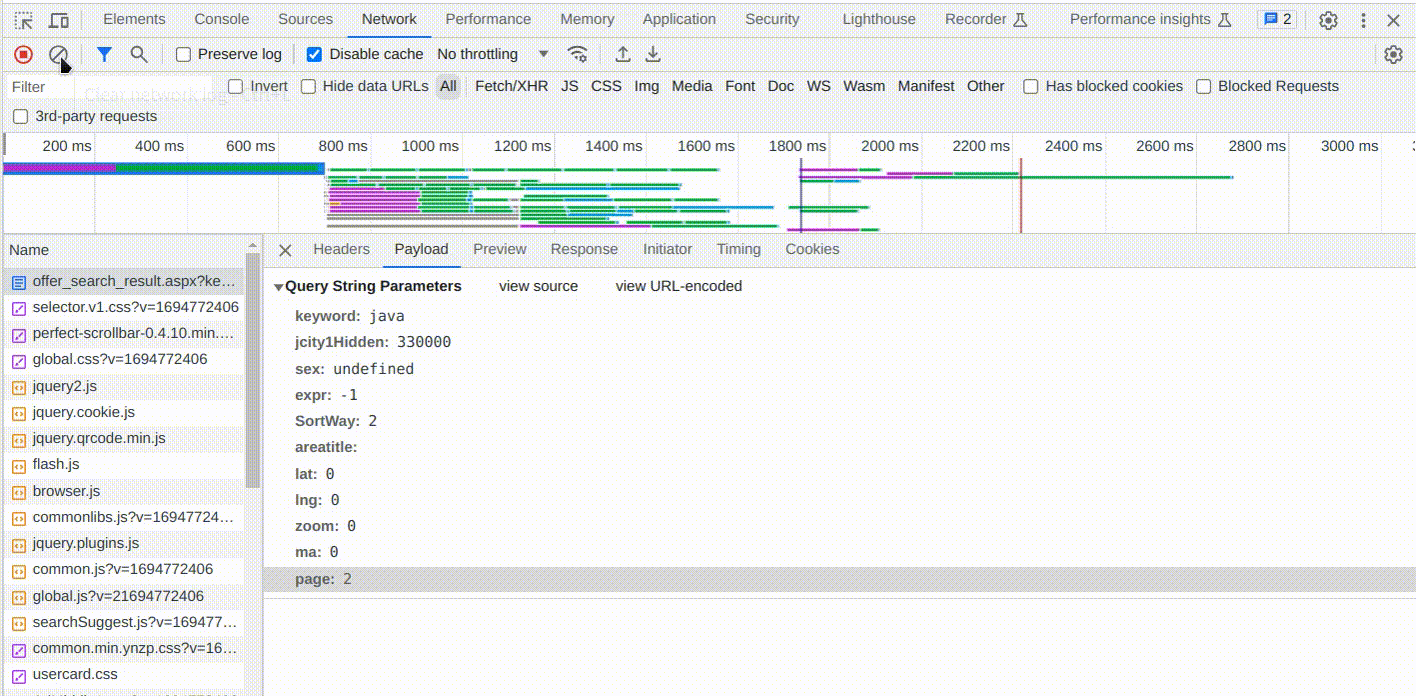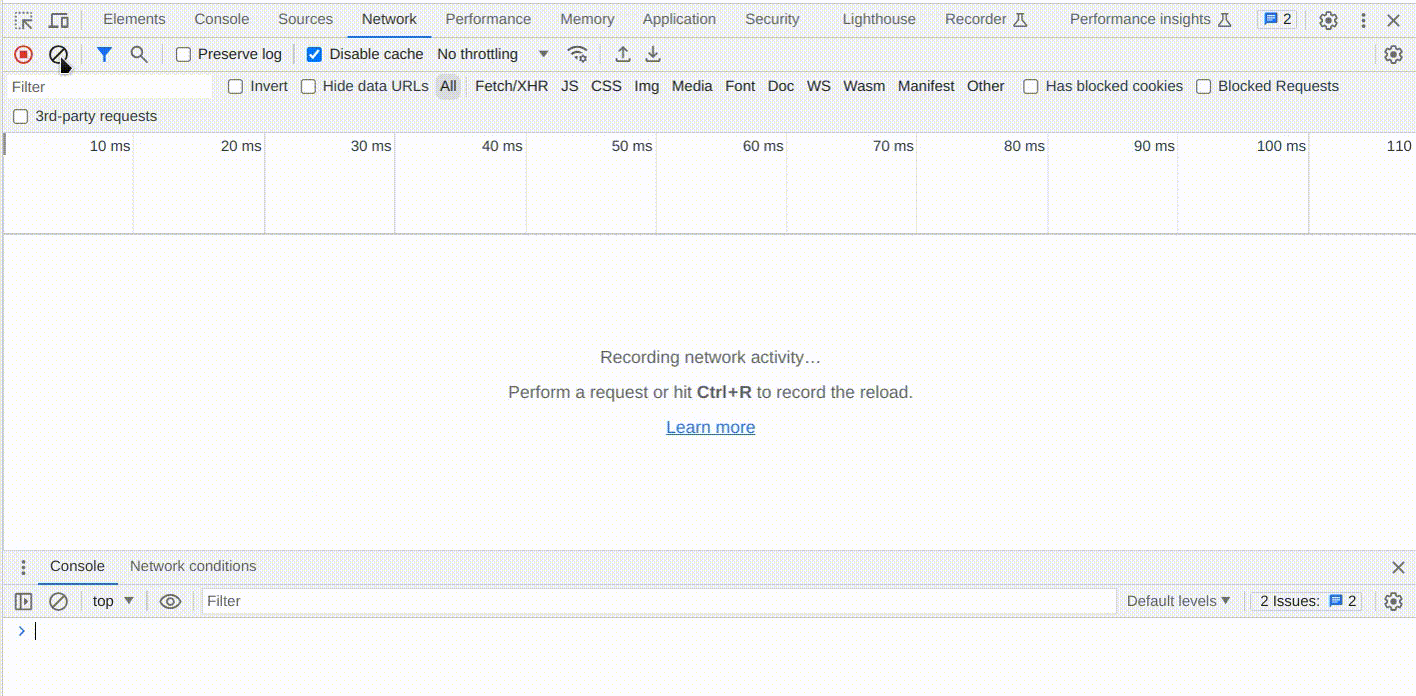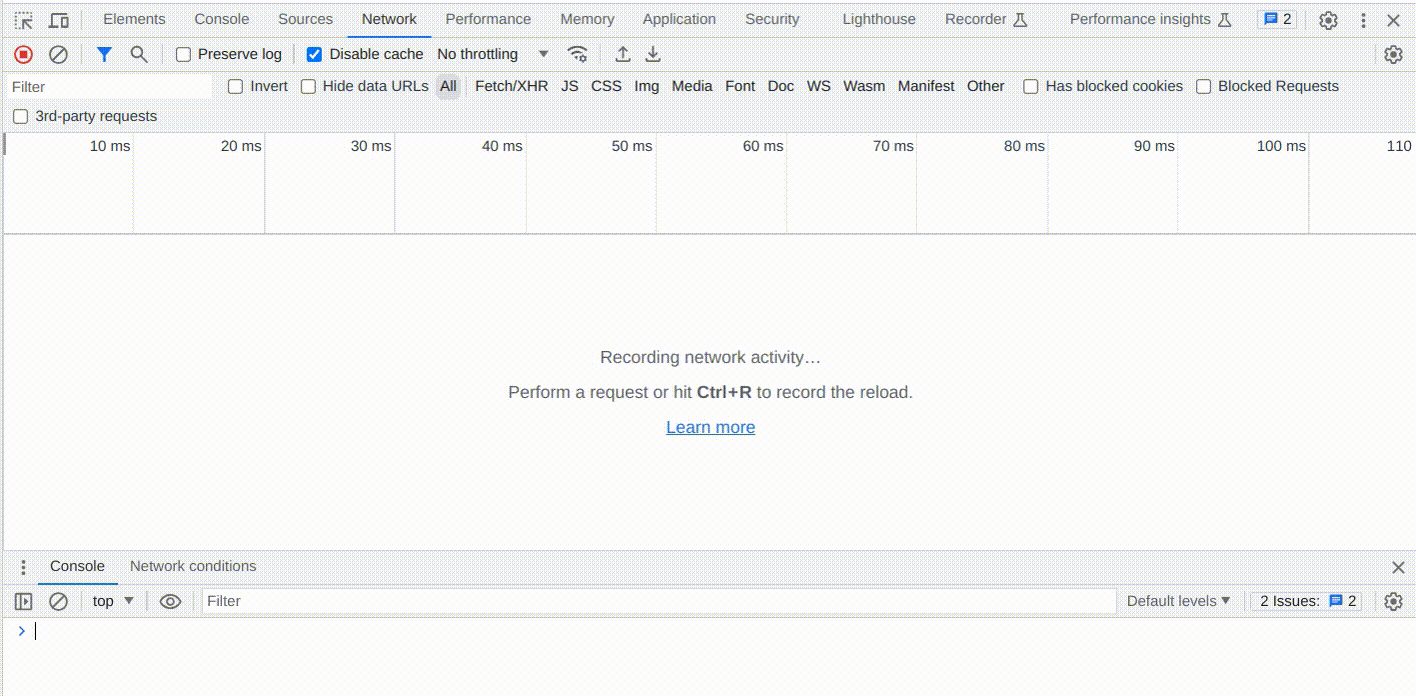
8. 通过前面几步,我们已经确定了offer_search_result.aspx这个请求的响应就包含我们想要的数据,接着我们需要分析一下这个请求都携带什么数据给服务器,服务器才能根据条件查询出对应的结果。因为这个请求是GET请求,请求参数一般都拼接在url中。
可以点击这个请求的payload这一栏查看请求的参数信息

可以看到这个请求的携带的参数有:
| 参数名称 | 猜测 |
|---|---|
| keyword | 看字面意思,根据经验以及盲猜,应该就是查询的关键字 |
| jcity1Hidden | 这个其实是地区代码,我们不用管也可以 |
| sex | 这个sex有点猜不到啊,应该是筛选岗位要求的性别条件吧 |
往下几个参数好像都不重要了,就不分析了。
浏览网页发现,做了分页显示,那我们要采集多页数据的话,需要搞明白网页是怎么获取到下一页的数据的,我们把开发者工具中的网络抓包记录清空
然后点击网页最底下的分页的第2页,抓第2页的数据包
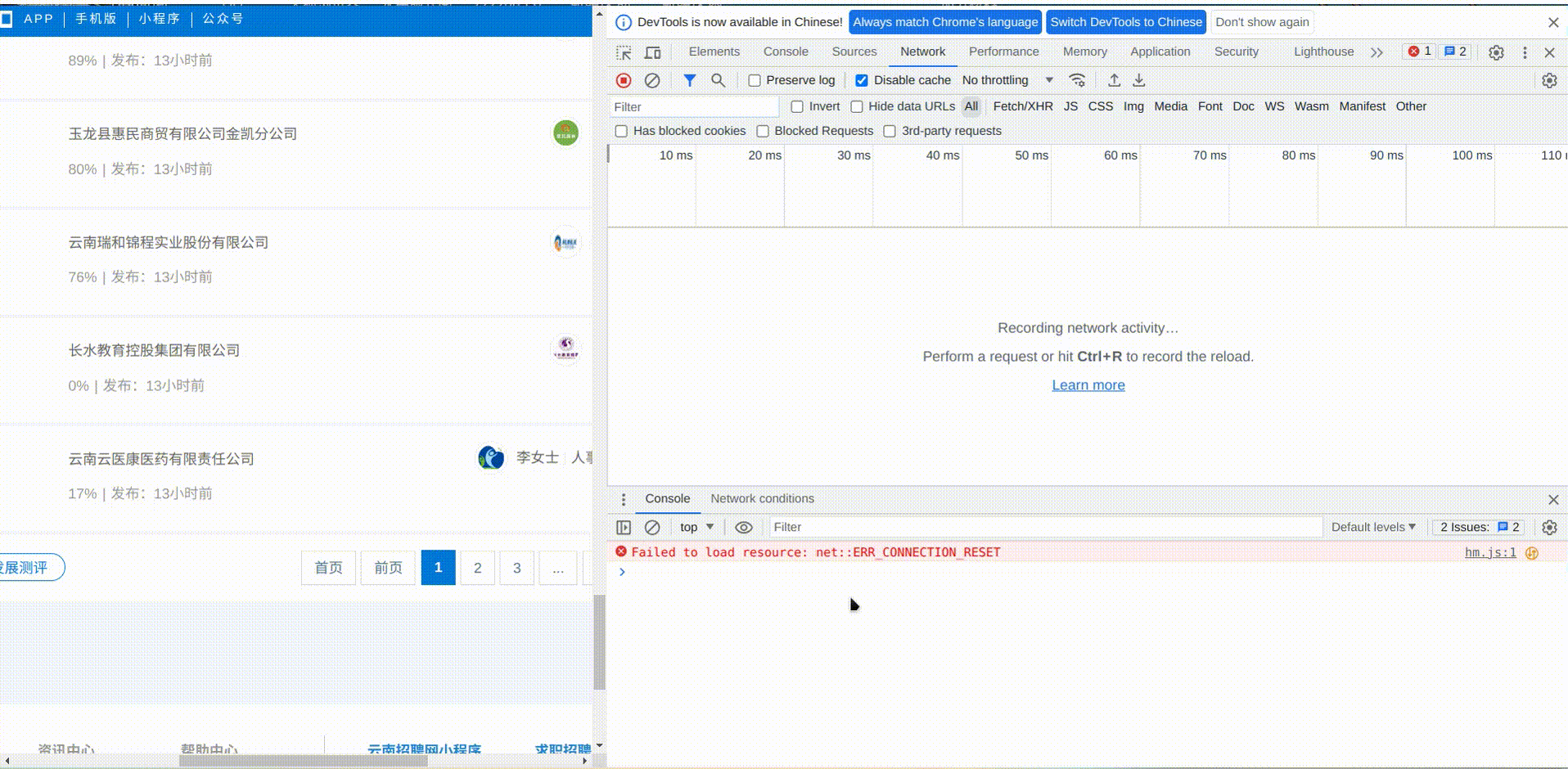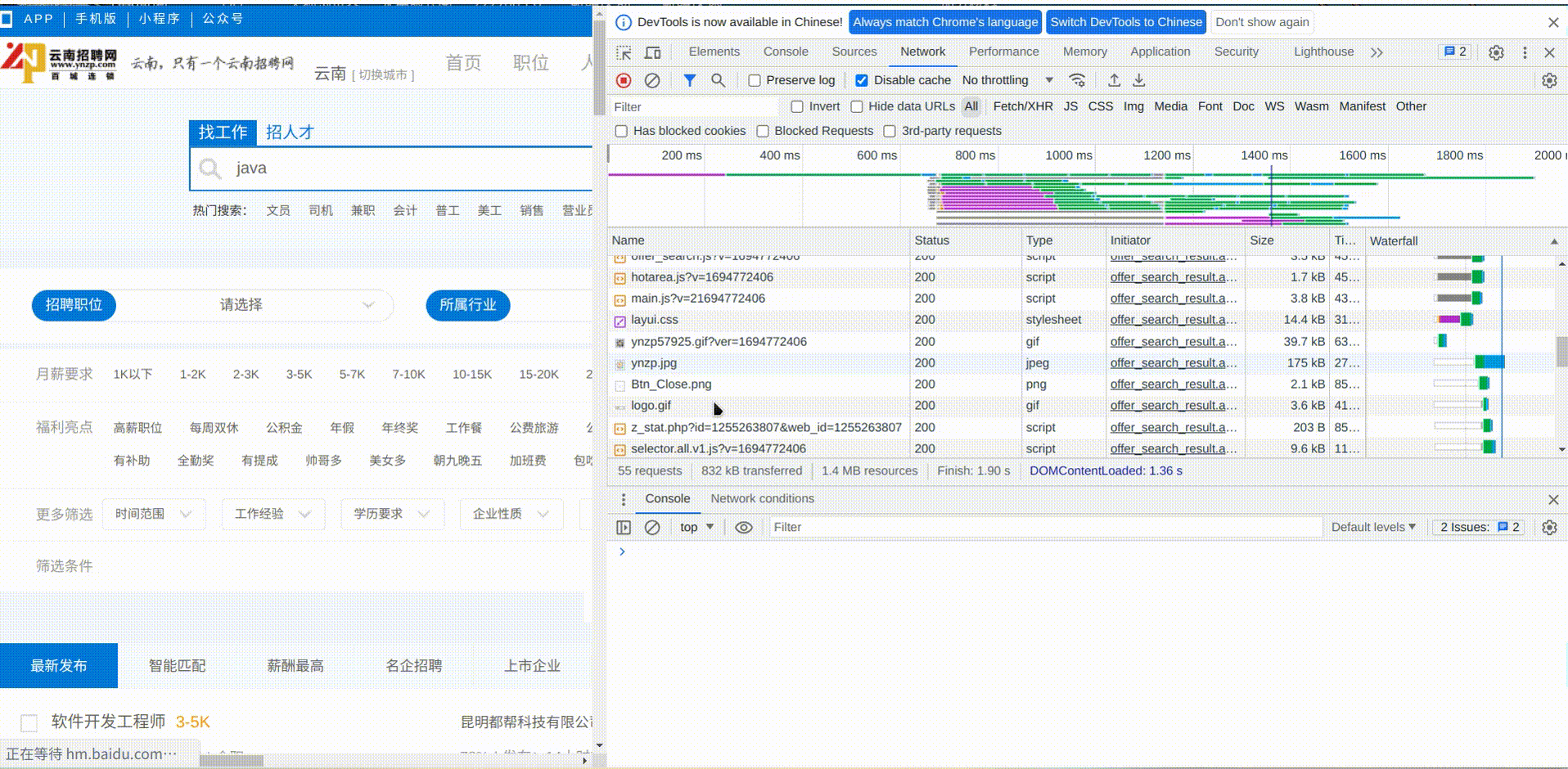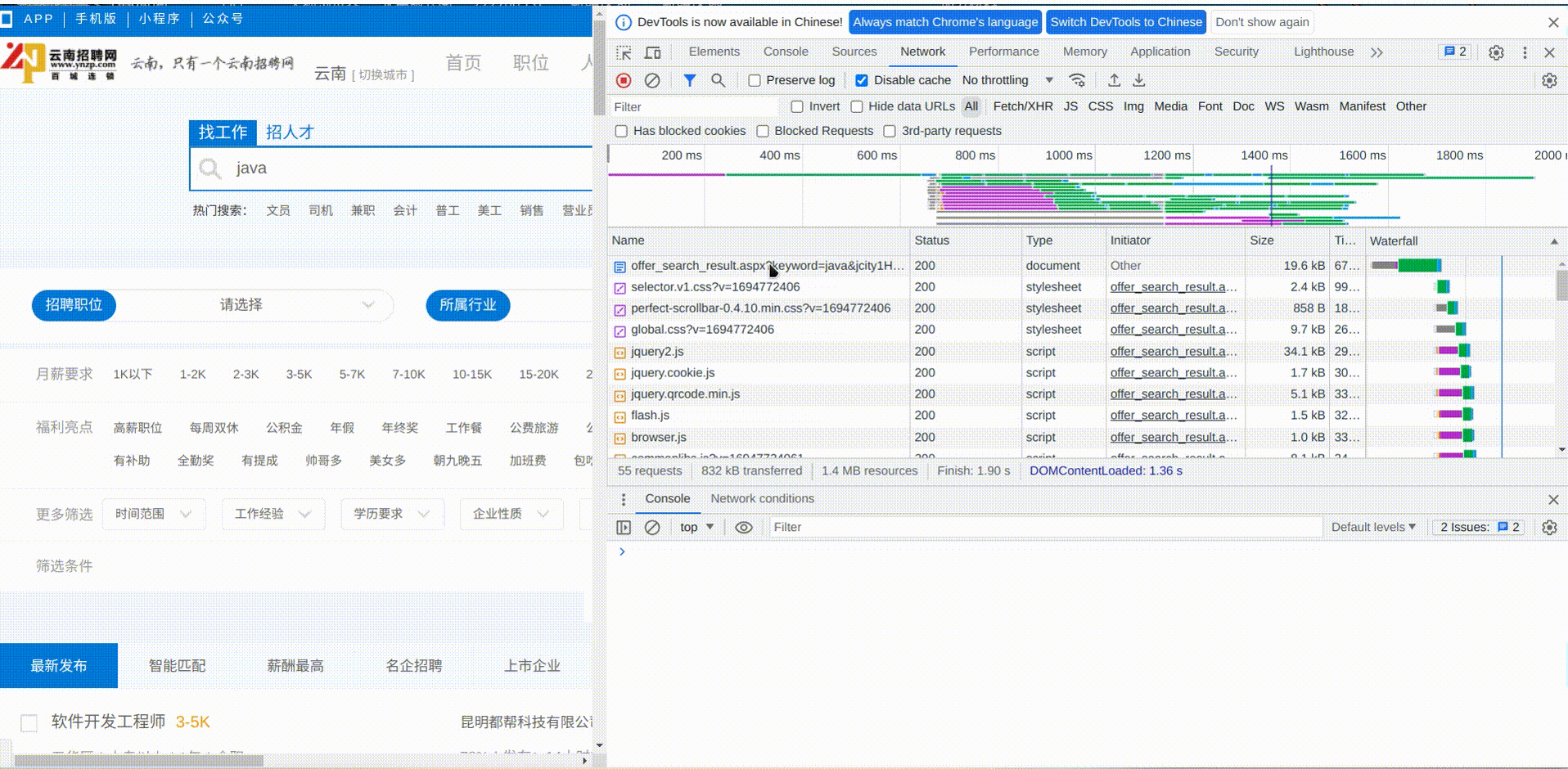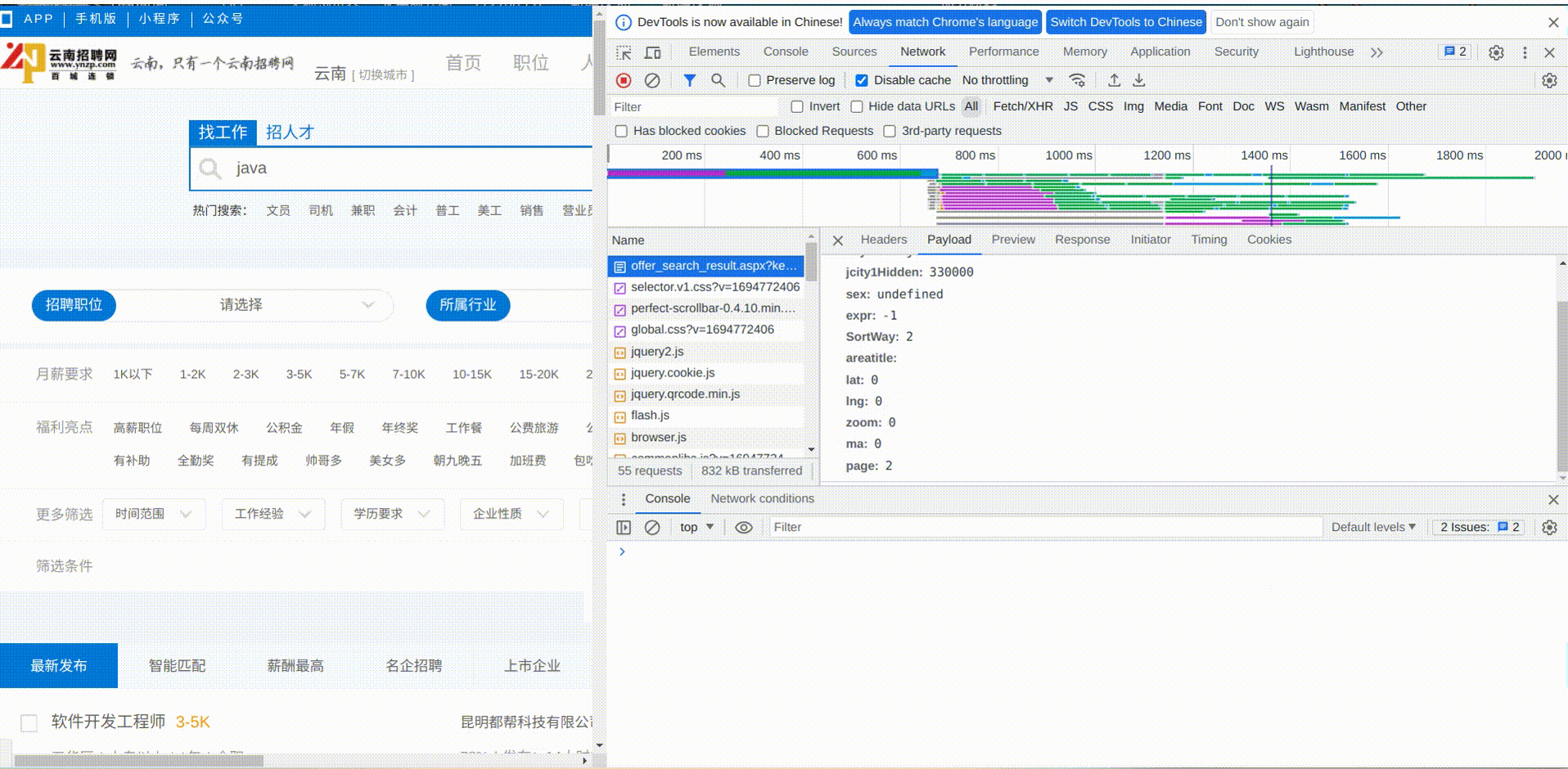
第2页的数据我们只用分析请求携带的参数就可以了,这里才会是决定获取的是第几页数据
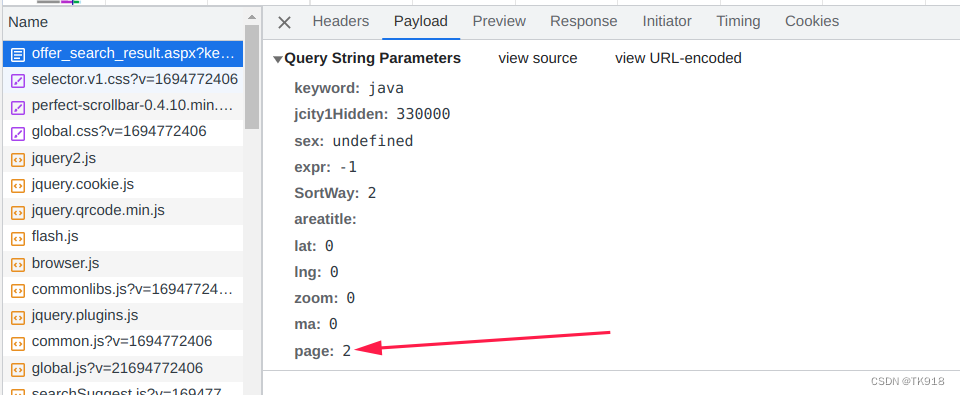
发现多了个page的参数,值为2,正好对应我们请求的第2页数据,前面没有这个参数,说明默认就是查询第1页数据,根据这个规律,我们直接修改浏览器上的url中的page参数为999,看页面的结果是如何
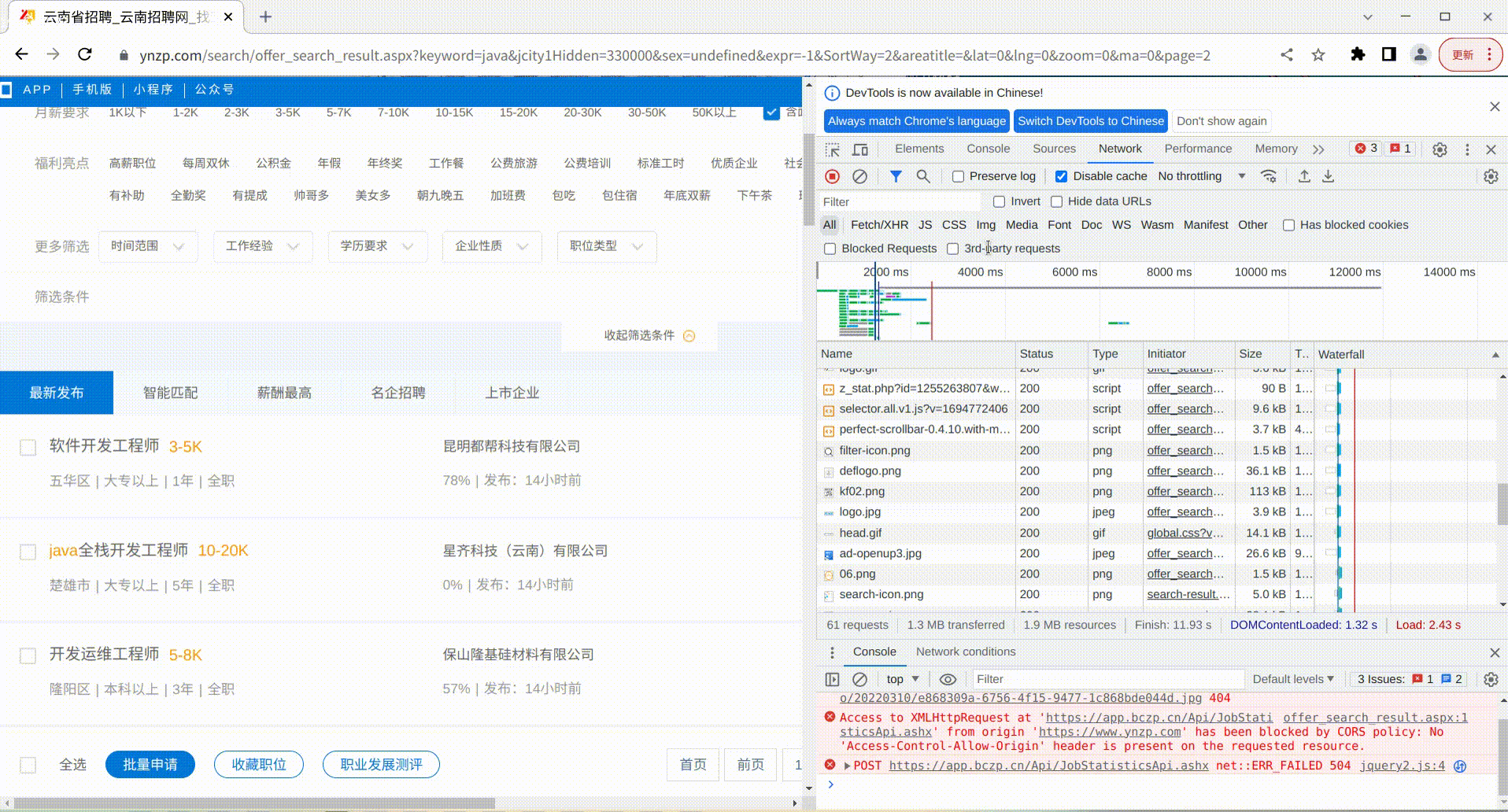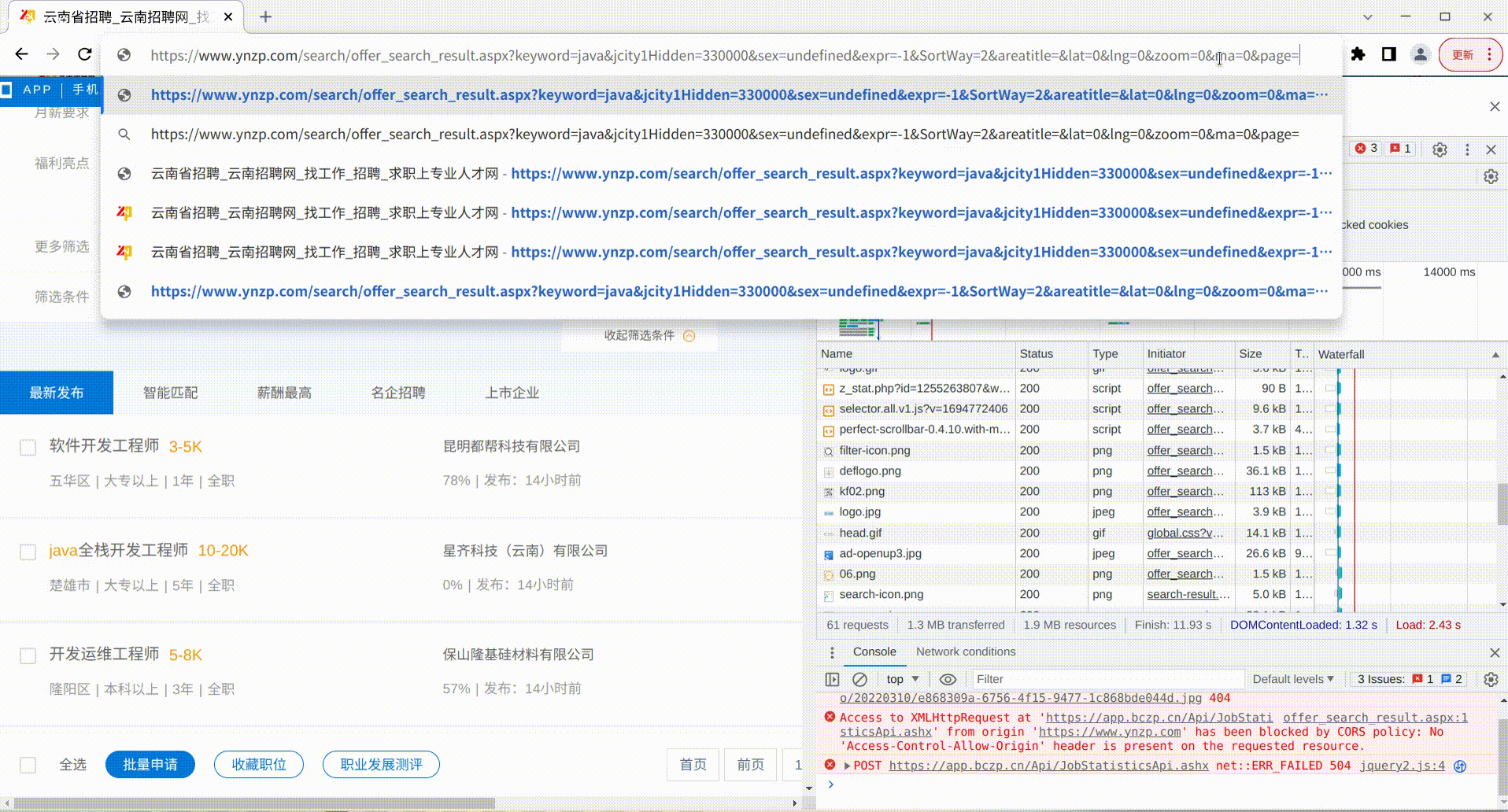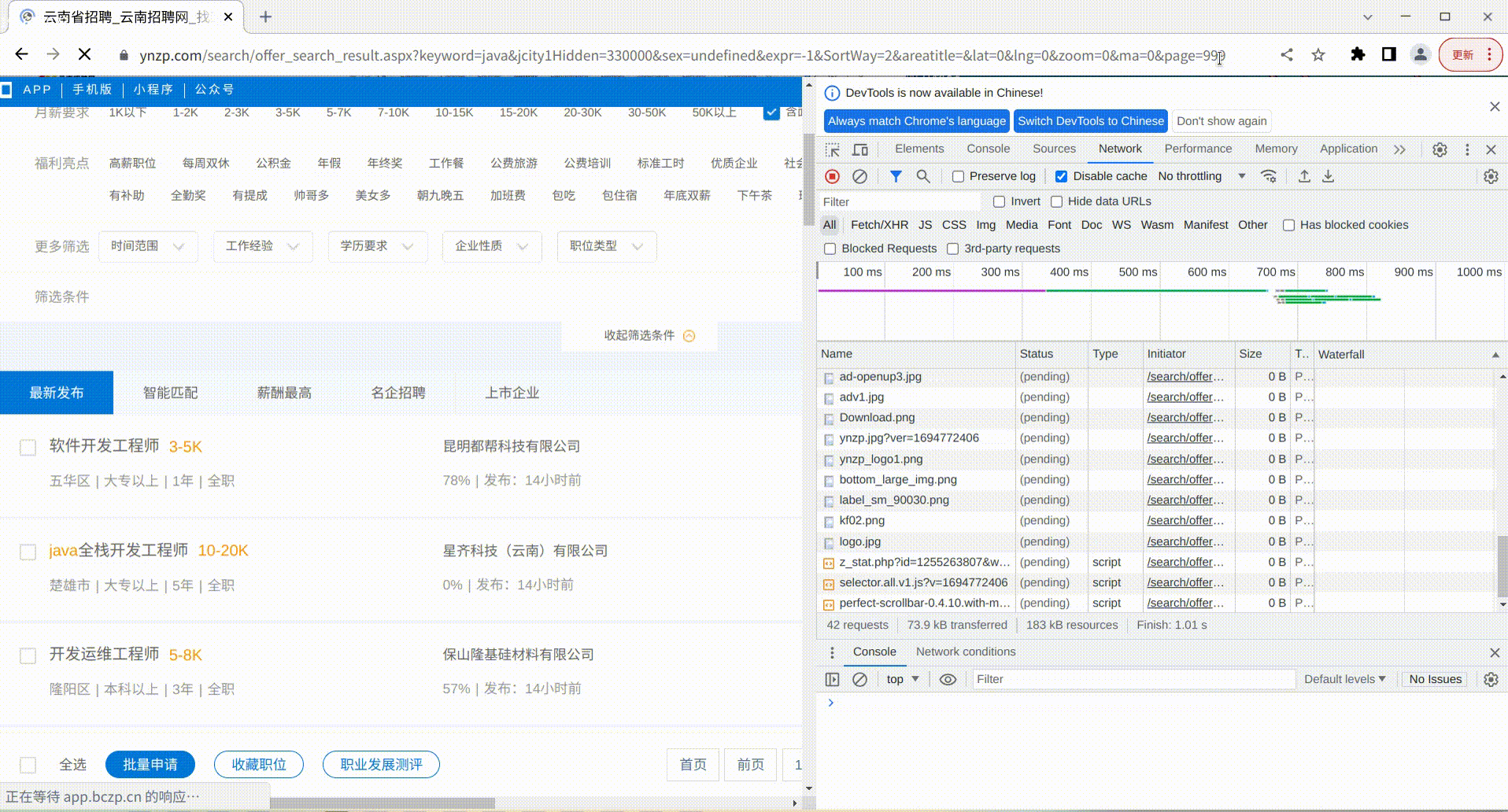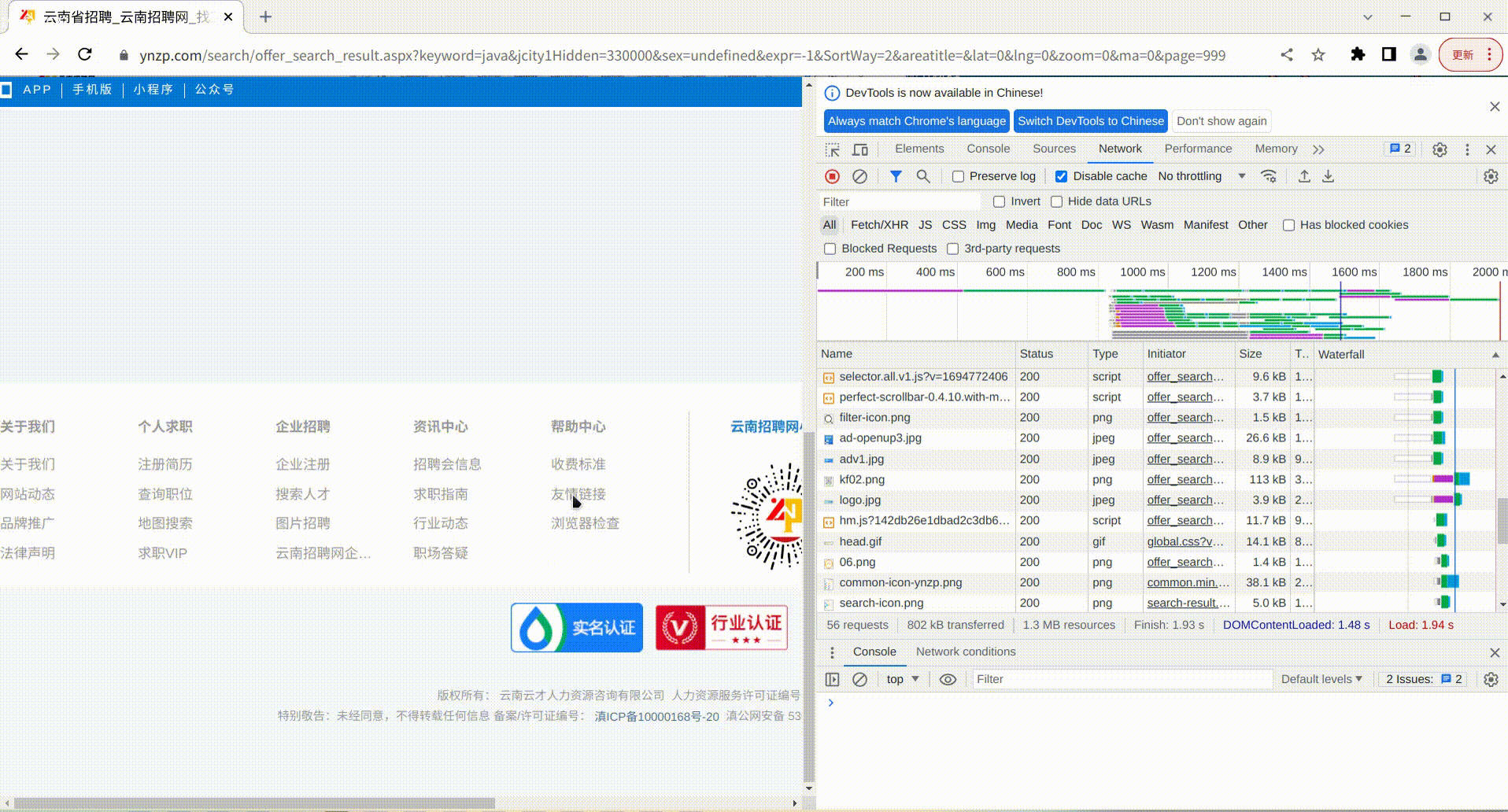
可以看得出来,当查询页码过大时,超过了数据库中查询到的页数,就会显示空的查询结果,那么我们使用python进行逐页采集的时候,只要采集的过程中,分析某一页的岗位数据为空时,就说明这个查询的结果以及采集完毕了。
- 因为响应的html中就有数据,可以使用xpath进行数据的提取,先使用xpath对页面数据进行定位提取,这里使用谷歌浏览器插件XPath Helper进行辅助,没有下载安装的去极简插件(https://chrome.zzzmh.cn/#/index)搜索XPath Helper进行下载安装到谷歌浏览器插件中并启用插件
Xpath Hepler非常好用,还会将匹配的页面区域进行渲染成黄色背景
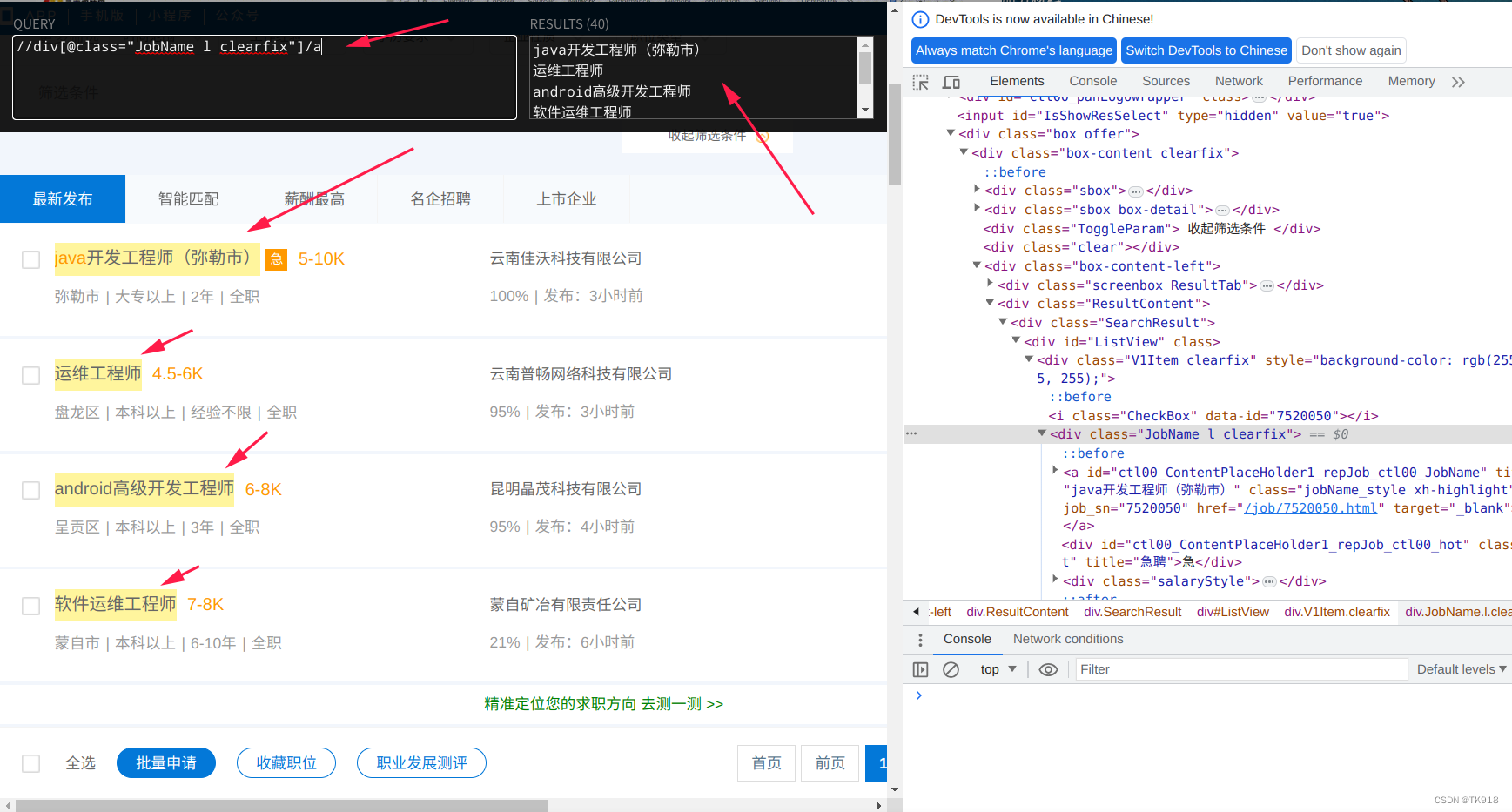
这里要写的xpath有点多,我就列个表格出来,大家可以自己试一下
| xpath语句 | 说明 | 区域 |
|---|---|---|
| //div[@class=“V1Item clearfix”] | 匹配出每一个岗位 |  |
| //div[@class=“V1Item clearfix”][1] | 选中上面匹配结果的第一个结果 | 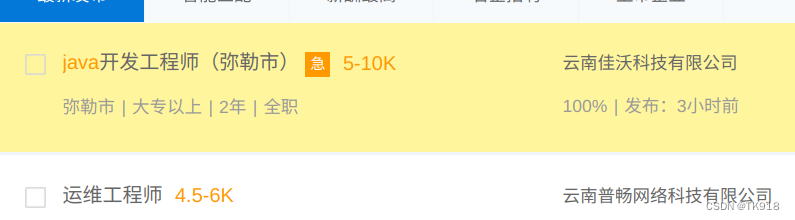 |
| //div[@class=“V1Item clearfix”][1]/div[“JobName l clearfix”]/a[@class=“jobName_style”] | 匹配到岗位名称,需要用@title提取完整岗位名称 |  |
| //div[@class=“V1Item clearfix”][1]/div[@class=“l ent_style1”] | 匹配公司名称 |  |
| //div[@class=“V1Item clearfix”][1]/div[@class=“JobInfo l”]/span | 匹配城市、学历工作经验、工作类型的要求 | 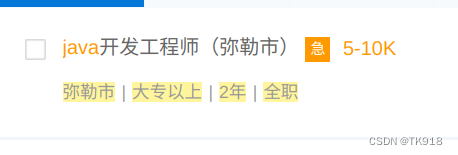 |
| //div[@id=“ctl00_ContentPlaceHolder1_AspNetPager1”]/span[8]/a/@href | 提取到最后一页的url,这里不一定能取到,需要在python里面取最后一个span |
这里就不再一一列举了,各位可以根据自己的需求,写出符合自己需求的xpath语句。
我在代码中还采集了企业的资料,具体就是点击企业名称就会跳转到企业资料页面,在这个页面禁用了鼠标左右键,无法右键打开浏览器的控制台,可以直接按F12或者通过浏览器菜单的开发者工具进行打开,这样也可以进入开发者工具,这个页面也是使用xpath可以直接提取到数据的,大家可以根据python代码自己下去分析。
python代码实现
先用pip安装这些库
pip install requests
pip install lxml
具体的python代码实现,支持多个关键字以及指定采集页码数量,采集的数据保存文件与代码文件将会在同一目录下。
输入例子:
采集java工程师10页和python爬虫5页:java工程师,10<>python爬虫,5
import csv
import random
import sys
import time
import urllib.parseimport requests
from lxml import etree# 存储企业资料
enterprise_information = dict()def get_random_user_agent() -> str:"""随机取一个User-Agent返回:return: str"""user_agent = [# Opera"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60","Opera/8.0 (Windows NT 5.1; U; en)","Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50",# Firefox"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0","Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",# Safari"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2",# chrome"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11","Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16",# 360"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36","Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko",# 淘宝浏览器"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",# 猎豹浏览器"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",# QQ浏览器"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E) ",# sogou浏览器"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)",# maxthon浏览器"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.3.4000 Chrome/30.0.1599.101 Safari/537.36",# UC浏览"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36","Mozilla/5.0 (iPhone; CPU iPhone OS 13_3_1 like Mac OS X; zh-CN) AppleWebKit/537.51.1 (KHTML, like Gecko) Mobile/17D50 UCBrowser/12.8.2.1268 Mobile AliApp(TUnionSDK/0.1.20.3)","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36","Mozilla/5.0 (Linux; Android 8.1.0; OPPO R11t Build/OPM1.171019.011; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/76.0.3809.89 Mobile Safari/537.36 T7/11.19 SP-engine/2.15.0 baiduboxapp/11.19.5.10 (Baidu; P1 8.1.0)","Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36","Mozilla/5.0 (iPhone; CPU iPhone OS 13_3_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 SP-engine/2.14.0 main%2F1.0 baiduboxapp/11.18.0.16 (Baidu; P2 13.3.1) NABar/0.0 ","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36","Mozilla/5.0 (iPhone; CPU iPhone OS 12_4_4 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 MicroMessenger/7.0.10(0x17000a21) NetType/4G Language/zh_CN","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36","Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36"]return user_agent[random.randint(0, len(user_agent) - 1)]def get_web_server_enterprise_data(enterprise_data_url: str) -> dict:"""查询招聘企业的信息:param enterprise_data_url: 访问企业资料的链接:return: dict 存储企业数据的字典"""# 判断链接的类型,有两种,show.aspx?id=420152&lx=2&Ent_SN=2765266,这种提取出ent_snif enterprise_data_url.startswith("show.aspx"):ent_sn = enterprise_data_url.split("Ent_SN=")[1]else:# /ent/2973425.htmlent_sn = enterprise_data_url.split('/ent/')[1].split(".html")[0]# 根据ens_sn查询是否以及保存过这个企业的基本信息global enterprise_information# 从字典中查询data = enterprise_information.get(ent_sn)if data is not None:# 字典中查到了这个企业的数据,直接返回了,不用发请求获取了return data# 拼接请求地址enterprise_data_url = "https://www.ynzp.com/ent/{}.html".format(ent_sn)headers = {"User-Agent": get_random_user_agent()}# 发送请求获取响应html_content = get_web_server_data(enterprise_data_url, headers, dict())# 解析出企业的资料html_element = etree.HTML(html_content)# 企业所属行业industry = html_element.xpath('//div[@id="EntBaseInfo"]/ul/li[1]/span[2]/text()')if len(industry):industry = industry[0]else:industry = "无"# 企业性质enterprise_nature = html_element.xpath('//div[@id="EntBaseInfo"]/ul/li[2]/span[2]/text()')if len(enterprise_nature):enterprise_nature = enterprise_nature[0]else:enterprise_nature = "无"# 注册资金registered_capital = html_element.xpath('//div[@id="EntBaseInfo"]/ul/li[3]/span[2]/text()')if len(registered_capital):registered_capital = registered_capital[0]else:registered_capital = "无"# 人数规模,html里有点特别size_personnel = html_element.xpath('//div[@id="EntBaseInfo"]/ul/li[4]/text()')if len(size_personnel):size_personnel = size_personnel[0]else:size_personnel = "无"# 组装数据保存并返回enterprise_data = {"industry": industry,"enterprise_nature": enterprise_nature,"registered_capital": registered_capital,"size_personnel": size_personnel}# 将数据存入字典中enterprise_data[ent_sn] = enterprise_datareturn enterprise_datadef handle_html_content(html_content: str) -> list:"""解析处理html内容:param html_content: html内容:return: list 解析出的一整页的所有岗位信息"""# 解析html内容html_element = etree.HTML(html_content)position_list = list()# 遍历每一个招聘信息for recruit_item_elem in html_element.xpath('//div[@class="V1Item clearfix "]'):# 岗位名称job_name = recruit_item_elem.xpath('./div[@class="JobName l clearfix"]/a/@title')[0]sys.stdout.write('\r' + '正在解析-->岗位名称:' + job_name)sys.stdout.flush()# 工资salary = recruit_item_elem.xpath('./div[@class="JobName l clearfix"]/div[@class="salaryStyle"]/text()')[0]# 去除两边的空格和换行salary = salary.strip()# 公司、企业名称corporate_name = recruit_item_elem.xpath('./div[@class="l ent_style1"]/a/text()')[0]# 工作地点work_location = recruit_item_elem.xpath('./div[@class="JobInfo l"]/span[1]/text()')[0]# 学历educational_qualifications = recruit_item_elem.xpath('./div[@class="JobInfo l"]/span[2]/text()')[0]# 工作经验work_experience = recruit_item_elem.xpath('./div[@class="JobInfo l"]/span[3]/text()')[0]# 工作类型work_type = recruit_item_elem.xpath('./div[@class="JobInfo l"]/span[4]/text()')[0]# 提取公司资料的url,获取公司的数据enterprise_information_url = recruit_item_elem.xpath('./div[@class="l ent_style1"]/a/@href')[0]enterprise_data = get_web_server_enterprise_data(enterprise_information_url)# 组装数据position_data = {"job_name": job_name,"salary": salary,"corporate_name": corporate_name,"work_location": work_location,"educational_qualifications": educational_qualifications,"work_experience": work_experience,"work_type": work_type,"enterprise_data": enterprise_data}# 添加到该页的总列表中position_list.append(position_data)return position_listdef get_web_server_data(url: str, headers: dict, params: dict) -> str:"""发送请求到服务器,将响应的html文本内容返回:param url: 请求的地址:param headers: 请求头:param params: 请求参数(这里都是GET请求,都是拼接到url中):return: str类型的html内容"""# 查询关键字万一有中文,先进行转码,前端他用了escape这个函数将关键字进行转码,服务器不允许直接发中文参数值if params.get("keyword"):params["keyword"] = urllib.parse.quote(params.get("keyword").encode('unicode-escape')).replace('%5Cu', '%u')# 拼接请求参数到urlurl += "?"for key in params.keys():# 逐个参数拼接到urlurl += "{}={}&".format(key, params.get(key))# 拼接到最后会多一个&,需要删除掉url = url[:-1]# 发送请求response = requests.get(url, headers=headers)# 判断服务器响应状态码是否为200 OKif response.status_code != 200:raise Exception("请求出错了!")# 设置编码,将响应编码设置为我们的目标编码,防止乱码response.encoding = response.apparent_encoding# 读取响应的html内容并返回html_context = response.textreturn html_contextdef save_data_to_csv(keyword, position_list: list) -> None:"""将岗位数据存储成csv文件:param keyword::param position_list::return:"""# 文件内容头(第一行的列名称)header = ["岗位名称", "工资", "工作地点", "学历要求", "经验要求", "工作类型","招聘企业名称", "企业行业", "企业性质", "注册资金", "人数规模"]# 获取时间,拼接在文件名中lt = time.localtime()t = "{}月{}日{}点{}分".format(lt.tm_mon, lt.tm_mday, lt.tm_hour, lt.tm_min)file_name = "./{}-{}.csv".format(keyword, t)with open(file_name, "w+", encoding="utf-8") as f:csv_file = csv.writer(f)# 先写入第一行的列名称csv_file.writerow(header)for position_dict in position_list:row = list()# 调整一下每一行写入的数据的顺序# 岗位名称row.append(position_dict["job_name"])# 工资row.append(position_dict["salary"])# 工作地点row.append(position_dict["work_location"])# 学历要去row.append(position_dict["educational_qualifications"])# 经验要求row.append(position_dict["work_experience"])# 工作类型row.append(position_dict["work_type"])# 招聘企业名称row.append(position_dict["corporate_name"])# 企业行业row.append(position_dict["enterprise_data"]["industry"])# 企业性质row.append(position_dict["enterprise_data"]["enterprise_nature"])# 注册资金row.append(position_dict["enterprise_data"]["registered_capital"])# 人数规模row.append(position_dict["enterprise_data"]["size_personnel"])# 将列表写成文件中的一行csv数据csv_file.writerow(row)# 打印sys.stdout.write('\r' + '将关键字:{}\t查询到的数据写入文件:{}\t完毕!'.format(keyword, file_name))sys.stdout.flush()def collect(keyword: str, collect_page_number: int) -> None:"""采集流程的主要控制函数:param keyword: 搜索关键字:param collect_page_number: 要采集的页码数:return: None"""# 搜索的请求链接url = "https://www.ynzp.com/search/offer_search_result.aspx"# 模拟浏览器的请求头,防止被识别为爬虫headers = {"Host": "www.ynzp.com",# 随机用一个User-Agent"User-Agent": get_random_user_agent()}# 请求参数request_params = {# 搜索关键字"keyword": keyword,"jcity1Hidden": "330000","sex": "undefined","expr": -1,"SortWay": 2,"areatitle": "","lat": 0,"lng": 0,"zoom": 0,"ma": 0,# 默认页码是1"page": 1}# 改关键字的最大页码数last_search_result_page_num = collect_page_number# 该搜索关键字的所有岗位列表all_result_position_list = list()# 每一页for page_number in range(1, collect_page_number + 1):# 更新请求携带的页码request_params["page"] = page_number# 调用函数,发送请求得到数据html_content = get_web_server_data(url, headers, request_params)# 如果是第一页,那就提取一下这个关键字搜索到的最大页数if page_number == 1:# 使用etree解析html内容html_element = etree.HTML(html_content)# ['offer_search_result.aspx?keyword=java&jcity1Hidden=330000&sex=undefined&expr=-1&SortWay=2&areatitle=&lat=0&lng=0&zoom=0&ma=0&page=14']# last_page_href = html_element.xpath('//div[@id="ctl00_ContentPlaceHolder1_AspNetPager1"]/span[8]/a/@href')[# 0]page_spans = html_element.xpath('//div[@id="ctl00_ContentPlaceHolder1_AspNetPager1"]/span')# 当搜索结果不满第一页时,不会显示分页这些的if len(page_spans):last_page_span = page_spans[-1]last_page_href = last_page_span.xpath('./a/@href')[0]# 分割出最后一页是多少last_page = last_page_href.split("page=")[1]else:last_page = 1# 记录一下last_search_result_page_num = int(last_page)# 处理服务器响应的数据now_page_position_list = handle_html_content(html_content)# 将当前页的岗位列表信息添加到整个关键字搜索结果岗位列表all_result_position_list += now_page_position_listif page_number >= last_search_result_page_num:# 页码数大于搜索结果尾页,则结束这个关键字的采集break# 采集完所有页码的数据,保存到文件,传入关键字做为文件名称开头sys.stdout.write('\r' + '采集关键字【{}】结束,正在将数据存入csv文件'.format(keyword))sys.stdout.flush()save_data_to_csv(keyword, all_result_position_list)def main():collect_condition = input("请输入才采集的关键字和采集页码数(每页有40条招聘信息,最高50页),用<>分割(例:java开发,10<>销售,15):")sys.stdout.write('\r' + '程序开始运行')sys.stdout.flush()# 分割出每个采集的关键字for i in collect_condition.split("<>"):# 分割出关键字名称和这个岗位的采集数量i = i.split(",")keyword = i[0]collect_page_number = int(i[1])# 服务器限制了一个关键字最高查询到50页的数据(2000条)if collect_page_number > 50: collect_page_number = 50# 逐个对每个关键字进行采集collect(keyword, collect_page_number)# 打印sys.stdout.write('\r' + '程序执行结束!')sys.stdout.flush()if __name__ == '__main__':main()