前言
最近一段时间一直想要写一个urdf格式化插件。
至于为什么嘛,因为使用sw2urdf插件,导出的urdf,同一标签的内容,是跨行的,这就导致,内容比较乱,而且行数比较多。影响阅读。
因此,自己想写格式化的脚本。
最近就开始分享一些,之前的思考。
正文
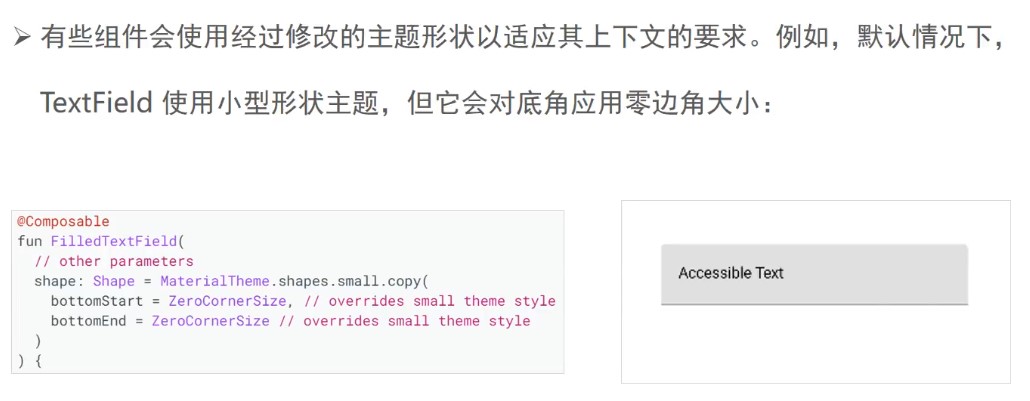
import xml.etree.ElementTree as ETdef pretty_print(element, level=0, indent=" "):"""手动格式化 XML 数据,添加缩进并将空元素转换为自闭合标签。:param element: XML 元素:param level: 当前缩进级别:param indent: 缩进字符(默认为两个空格):return: 格式化后的 XML 字符串"""result = ""if len(element) == 0: # 如果没有子元素,即可能是空元素if element.text and element.text.strip(): # 如果有文本内容result += f"{indent * level}<{element.tag}>{element.text.strip()}</{element.tag}>\n"else:result += f"{indent * level}<{element.tag} "# 如果有属性,添加到标签中if element.attrib:result += " ".join([f'{key}="{value}"' for key, value in element.attrib.items()])result += " />\n" # 使用自闭合标签形式else:result += f"{indent * level}<{element.tag}"# 如果有属性,添加到标签中if element.attrib:result += " " + " ".join([f'{key}="{value}"' for key, value in element.attrib.items()])result += ">\n"# 处理元素的文本内容if element.text and element.text.strip():result += f"{indent * (level + 1)}{element.text.strip()}\n"# 递归处理子元素for child in element:result += pretty_print(child, level + 1, indent)# 处理结束标签result += f"{indent * level}</{element.tag}>\n"return result# 读取 XML 文件
file_path = 'test.urdf' # 请将此路径替换为实际的文件路径
tree = ET.parse(file_path)
root = tree.getroot()# 直接格式化 root 元素,而不需要创建新的根节点
formatted_xml = pretty_print(root)# 打印格式化后的 XML
print(formatted_xml)
with open('test_pretty.urdf', 'w') as f:f.write(formatted_xml)
这里,代码主要是通过xml.etree.ElementTree解析xml文件。
然后在函数中补充上空格,<,/>等标签。
注意,这个函数是个递归的函数,会在函数内部调用函数本身。
实现的效果如下

可以发现,目前的问题是:
- 没有注释
- urdf最开始的标签,不见了。









![[答疑]用例规约:系统请求3dsMax创建体块](https://i-blog.csdnimg.cn/img_convert/84d1fd9eddce1fe203dc19534b6e4b2e.png)







