2021-arxiv-Prefix-Tuning- Optimizing Continuous Prompts for Generation

Paper:https://arxiv.org/pdf/2101.00190.pdf
Code:https://github.com/XiangLi1999/PrefixTuning
前缀调优:优化生成的连续提示
prefix-tunning 的基本思想也是想减少对模型的参数的改动,低资源对大模型进行SFT达到预期的效果。该方法想法比较直接,自然语言的token固定无法使用反向传播进行优化,那么就在原始输入的token前面添加固定长度的任务相关的virtual tokens ,一起作为新的输入。在训练的时候,会freeze模型的参数,只训练该部分prefix token的参数。
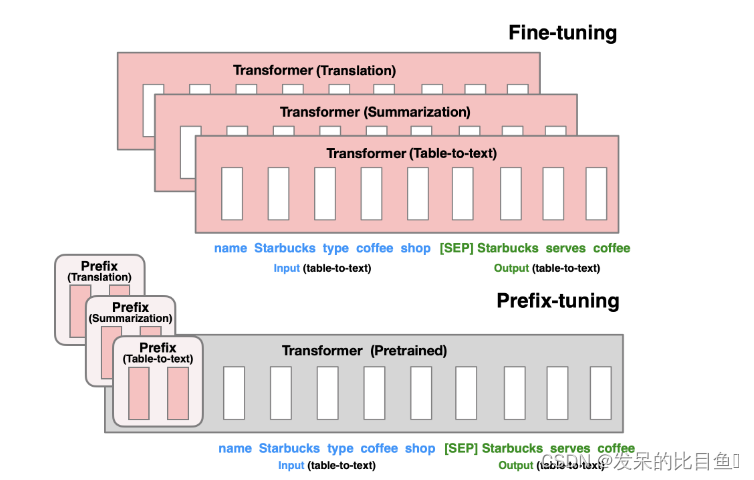
模型架构
对于fine-tuning,会更新模型的所有参数,但是prefix-tuning只更新prefix-tokens的参数,这样不同的任务在微调后,只需要保存对应任务的prefix tokens,因此相较于fine-tuning,prefix-tuning的成本会小的多。
和Pre-training不同的是,prefix- tuning 在上游任务中训练一个语言模型,并可以用于很多不同的下游任务。可以为每个用户设置一个单独的前缀,只对该用户的数据进行训练,从而避免数据交叉污染。此外,基于前缀的架构使甚至可以在一个批次中处理来自多个用户/任务的样本,这是其他轻量级微调方法所不能做到的。
table-to-text任务:输入 X XX 表示一个线性的表格,输出 Y YY 表示一个短文本;
自回归模型:在某一时刻 i ii,Transformer的每一层的隐状态向量拼接起来之后用于预测下一个词;
整体采用encoder-to-decoder架构;
方法:Prefix-Tuning
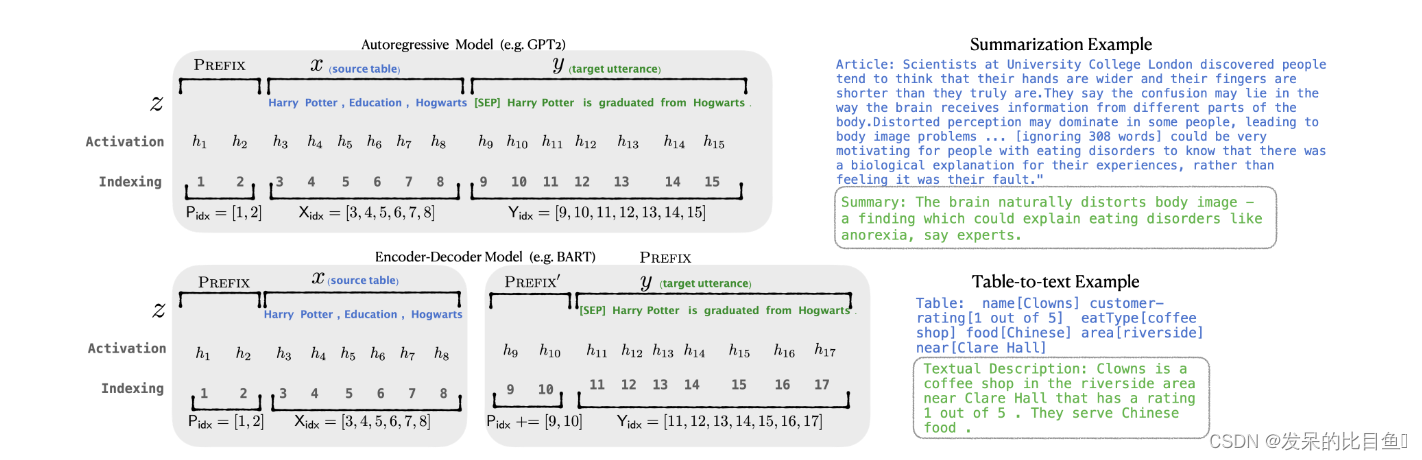
可以将token优化为连续词嵌入,而不是优化离散标记,其效果将向上传播到所有 Transformer 激活层,然后向右传播到后续标记。 这比需要匹配真实单词嵌入的离散提示更具表现力。 同时,这不如干预所有激活层的表现力,这避免了长期依赖并包括更多可调参数。 因此,Prefix-Tuning优化了前缀部分对应的所有层参数。
- 添加一个prefix,自回归模型表示为 z = [ prefix; x ; y ] \mathrm{z}=[\text { prefix; } \mathrm{x} ; \mathrm{y}] z=[ prefix; x;y],encoder decoder模型表示为 z = [ prefix; x ; prefix ′ ; y ] \mathrm{z}=\left[\text { prefix; } \mathbf{x} ; \text { prefix }^{\prime} ; \mathrm{y}\right] z=[ prefix; x; prefix ′;y]
- 输入部分prefix, x ,y 的position id分别记作 P i d x , X i d x 和 Y i d x ; P_{\mathrm{idx}}, X_{\mathrm{idx}} \text { 和 } Y_{\mathrm{idx}} \text {; } Pidx,Xidx 和 Yidx;
- prefix-tuning初始化一个训练的矩阵,记作 P θ ∈ R ∣ P i d x ∣ × dim ( h i ) \mathrm{P}_\theta \in \mathbb{R}^{\left|\mathrm{P}_{\mathrm{idx}}\right| \times \operatorname{dim}\left(\mathrm{h}_{\mathrm{i}}\right)} Pθ∈R∣Pidx∣×dim(hi),这部分参数用于存储prefix parameters:
h i = { P θ [ i , : ] , if i ∈ P i d x LM ϕ ( z i , h < i ) , otherwise h_i= \begin{cases}P_\theta[i,:], & \text { if } i \in \mathrm{P}_{\mathrm{idx}} \\ \operatorname{LM}_\phi\left(z_i, h_{<i}\right), & \text { otherwise }\end{cases} hi={Pθ[i,:],LMϕ(zi,h<i), if i∈Pidx otherwise
即,处于前缀部分token,参数选择设计的训练矩阵,而其他部分的token,参数则固定且为预训练语言模型的参数。
- 训练目标为:
max ϕ log p ϕ ( y ∣ x ) = ∑ i ∈ Y i d x log p ϕ ( z i ∣ h < i ) \max _\phi \log p_\phi(y \mid x)=\sum_{i \in \mathrm{Y}_{\mathrm{idx}}} \log p_\phi\left(z_i \mid h_{<i}\right) ϕmaxlogpϕ(y∣x)=i∈Yidx∑logpϕ(zi∣h<i)




![[python 刷题] 19 Remove Nth Node From End of List](https://img-blog.csdnimg.cn/07b6189a539e4dd2bf62f3e5a7a7e8a8.jpeg#pic_center)