前言
本文指的数据集为通用数据集,并不单是给机器学习领域使用。包含科研和工业领域需要自己制作数据集的。
首先,在制作大型数据集时,代码错误和数据问题可能会非常复杂。
前期逻辑总是简单的,库库一顿写,等排查的时候两眼无泪。
后期慢慢摸排和检查的时候不断完善代码,前期代码主要是完成功能,后期是增加维护性和检测性。
这部分工作其实前期可以考虑进去。
以下提供一些血泪经验
方法
1. 模块化设计
将代码分成多个小模块或函数,每个模块负责一个特定的任务。这样更容易定位和修复问题。
模块化在最开始拿到需求和实现思路的时候估计还做不到,但代码写到一定程度该考虑拆成模块的就得拆成模块。不然后期调试会特别复杂。
2.单元测试
TDD我是支持的,但同时写测试和代码我是做不到的。所以对我来说都是代码写到一定程度再考虑添加单元测试。分为功能测试,计算测试,还有数据样例测试。
3.日志记录
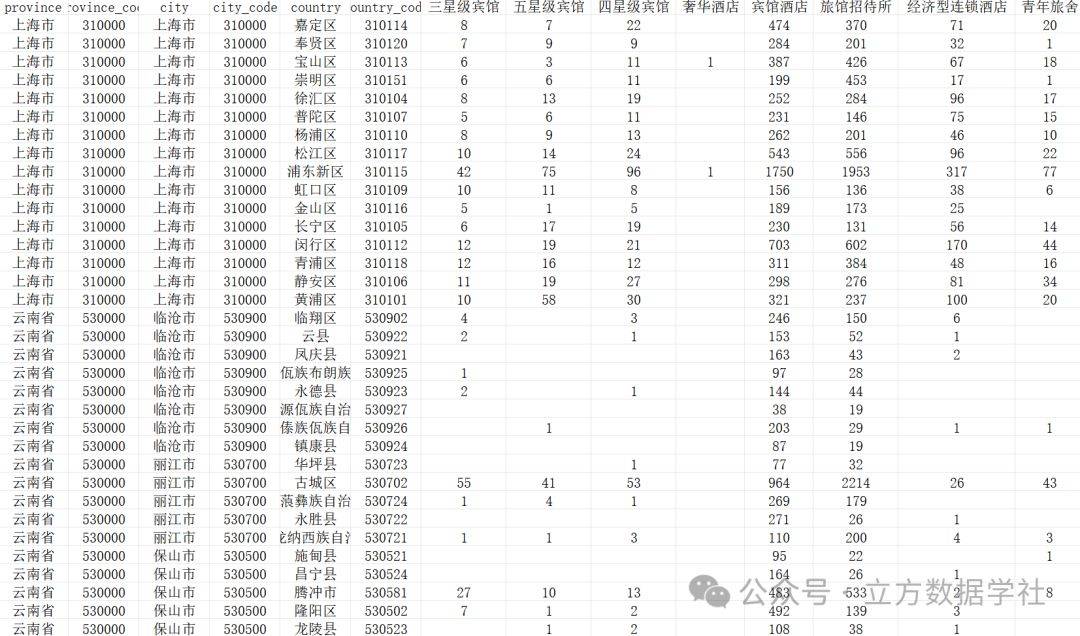
需要记录过程数据,推荐建立单独文件夹,存储计算中的过程数据。
注意!!! 这个除了开发阶段非常有用! 后期在程序上线生产环境后对于帮助排查bug也是非常有帮助的,上线后注意的是控制过程数据文件数量。
如图,一般建立check_data文件夹或者logs文件夹。

还可以用logging模块,代码如图:
import logginglogging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__)def process_data(data):logger.debug("Starting data processing")logger.debug("Data processing completed")但我个人倾向自定义log文件。logging模块的排版虽然整齐,无用字符也太多了。自己单独费点时间写个表保存。
晒一下,嘿嘿:

4. debug
打断点逐步调试啦!!没有捷径可走,加油吧少年!!
5.数据验证
在每个计算步骤核对计算结果确保计算正确。
6.版本控制
保存每个能跑的版本。不管是不是shit。
可以用管理工具git也可以手动保存。
7.数据抽样
对数据集进行抽样组成小样本数据集代入程序进行验证和核对结果,可以大大减少工作量!
8.自动化测试
编写自动化测试脚本,定期运行这些脚本以检测新引入的错误。可以使用CI/CD工具(如Jenkins、GitHub Actions)来实现这一点。
9.并行处理
将数据集切分多个进程进行计算,加快速度同时也会帮助更快发现问题!
提供一个按进程数均分数据集进行计算的代码:
from multiprocessing import Process
import timedef func_demo(age,name_list)for name in name_list:print(name,":",age)def func(param1,process_number):# 总输入xxx_list = [str(i) for i in range(100)]# 统计任务数量number = len(xxx_list) # 计算平均每个进程需承担多少任务delta = int(number / process_number)p_list = []# 启动多进程for i in range(0, process_number):# 按delta遍历取需要计算的任务。if i == process_number - 1:s = delta * ie = numberelse:s = delta * ie = delta * (i + 1)p = Process(target=calculate_name, args=(param1, xxx_list[s:e]))p.start()p_list.append(p)for p in p_list:p.join()# 测试划分的对不对
def test_p_delta():number = len(xxx_list)delta = int(number / 4)for i in range(0, 4):if i == 3:s = delta * ie = numberelse:s = delta * ie = delta * (i + 1)print("s:", s, " e:", e)if __name__ == '__main__':age=10process_number = 4func(age,process_number)
10.文档和注释
确保代码有充分的文档和注释,后期翻看的时候,也能快速理解代码逻辑和数据处理过程。
希望对看官有所帮助!!!