文章目录
- 一、单点问题
- 二、主从模式
- 概念
- 配置主从结构
- 查看主从节点
- 断开从属关系
- 拓扑结构
- 主从复制原理
- replication复制
- offset偏移量
- 全量复制和部分复制
- 全量复制
- 部分复制
- 实时复制
- redis主节点无法重启
- 三、主从+哨兵模式
- 哨兵概念
- 监控程序
- 人工恢复
- 自动恢复
- 为什么是哨兵集合
- 使用docker搭建环境
- 为什么要使用docker
- 环境安装
- 编排redis主从节点
- 编排redis-sentinel节点
- 哨兵节点的作用演示
- 哨兵重新选取主节点的流程
- 四、集群模式
- 概念
- 如何分配数据
- 哈希求余
- 一致性哈希
- 哈希槽分区
- 搭建集群环境
- 创建shell脚本文件
- 创建docker-compose.yml
- 构建集群
- 实战演练
- 效果演示
- 故障处理
- 集群扩容
- 五、缓存
- 概念
- 为什么关系型数据库性能不高?
- 如何提高数据库能承担的并发量?
- 更新策略
- 定期生成
- 实时生成
- 注意事项
- 缓存预热(Cache preheating)
- 缓存穿透(Cache penetration)
- 缓存雪崩(Cache avalanche)
- 缓存击穿(Cache breakdown)
- 六、分布式锁
- 概念
- 锁释放问题
- 校验机制
- 引入lua脚本
- 引入"看门狗"
- redlock算法
一、单点问题
分布式系统,涉及到一个非常关键的问题,即单点问题。如果某个服务器程序,只有一个节点(一台物理服务器来部署这个服务器程序),就会存在以下两个问题。
1、可用性问题:如果这个机器挂了,意味着服务也就被中断了
2、性能/支持的并发量也是比较有限的
引入分布式系统,主要也是为了解决上述的单点问题,在分布式系统中,往往希望有多个服务器来部署Redis服务,从而构成一个Redis集群,此时就可以让这个集群给整个分布式系统中其它的服务,提供更稳定、更高效的数据存储功能。存在以下几种Redis的部署方式
1、主从模式
2、主从+哨兵模式
3、集群模式
二、主从模式
概念
在若干个Redis节点中,有的是"主"节点,有的是"从"节点,比如有三台物理服务器,分别部署了一个redis-server进程,可以把其中的一个节点设置为 “主节点”,另外两个设置为 “从节点”
从节点得听主节点的,即从节点上的数据要跟随主节点变化,从节点上的数据要与主节点上的数据保持一致,从节点就是主节点的一份副本。另外,从节点的数据是只读的,不能被修改!!!
更准确的说,主从模式,主要是针对"读操作"进行并发量和可用性的提高,而对于写操作,无论是可用性还是并发,都是非常依赖主节点,而主节点,又不能搞多个,毕竟 “一山不能容二虎”,但在实际业务场景中,读操作往往比写操作更频繁!!!
由于从节点的数据都是时刻与主节点保持一致的,所以其它的客户端从从节点读取数据,和从主节点这里读取数据,是没有区别的!!!
如果是某个从节点挂了,几乎没什么影响,可以继续从主机点或其它从节点读取数据,得到的效果完全相同。另外,这些物理服务器一般是不会放在同一个机房的,毕竟自然灾害、停电之类的问题无法避免,所以会将其放在多个地方
如果是主节点挂了,只是读操作,影响不大,但要是写操作,就没得写了
配置主从结构
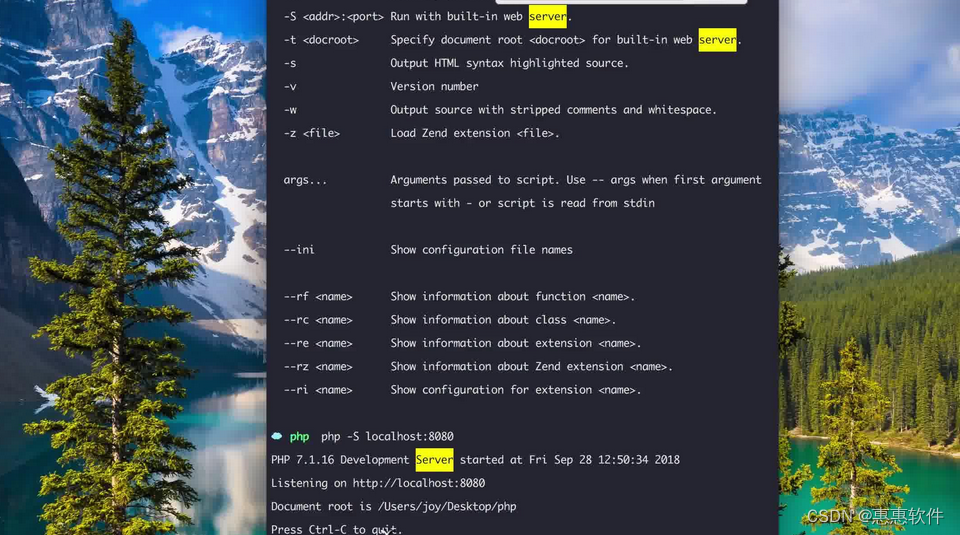
由于只有一台服务器,这里采用开启在同一台主机上开启多个redis-server进程的方式来是实现,采用一主两从,主节点不需要变动,但绑定的端口一定是不一样的!!!
绑定端口有两种方式,如下:
1、可以在启动程序的时候,通过命令行来指定端口 --port选项
2、也可以直接在配置文件中,来设定端口
这里采用第二种方式,先把主节点的配置文件拷贝过来

修改配置文件
设置端口号
设置为后台进程的方式启动
如下图,配置文件修改后,进程已经被启动了,但是,还没有构成主从结构,还需要继续配置
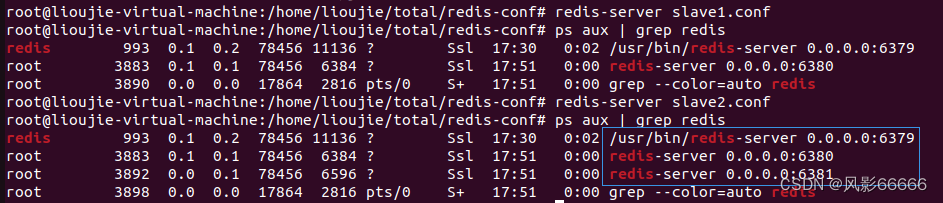
要想配置成主从结构,就需要使用slaveof,有以下三种方式,这里依然采用配置文件的方式

如下图,可看出除了有三个进程外,还有tcp连接,这是因为主节点和从节点是通过tcp连接建立联系的,即同步数据也是经过网络来是实现的

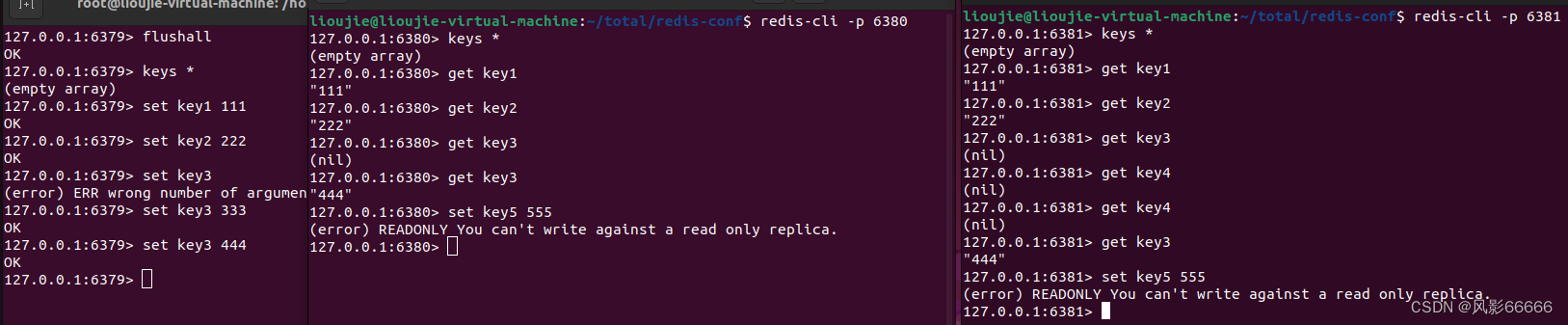
查看主从节点
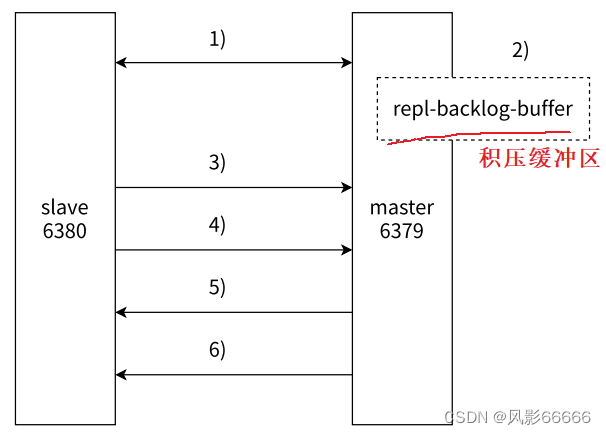
如下图,offset表示主节点和从节点之间,同步数据的进度,因为数据同步,不是瞬间完成的,最下面的四行,表示积压缓冲区,支持部分同步机制的实现
断开从属关系
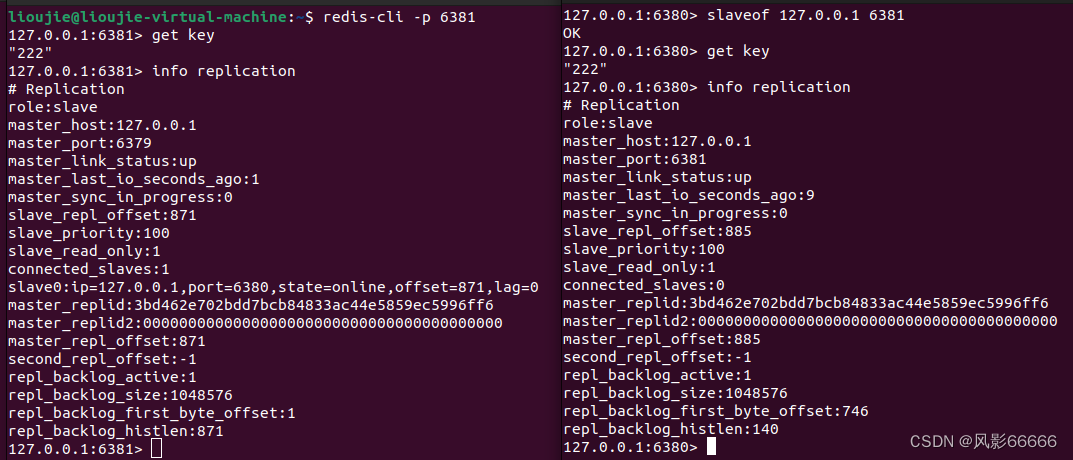
如下图,使用slaveof no one这个redis命令,来断开从节点与主节点的关系,该从节点原有的数据不会被抛弃,但是主节点新的修改,该节点也无法再同步数据了

如下图,当从节点断开后,又与主节点的某个从节点构成从属结构
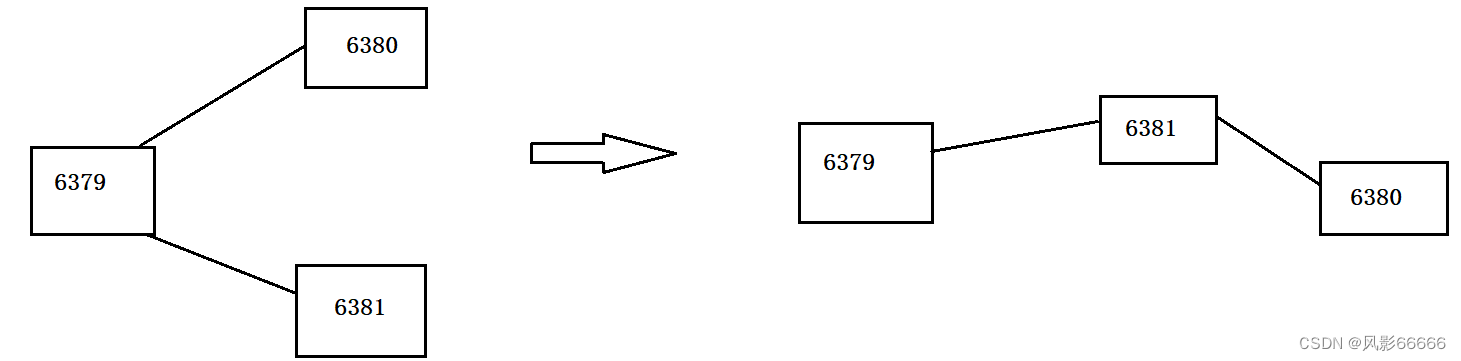
注意:上述的修改都是临时性的,当redis服务器重启后,又会恢复到最初在配置文件中设置的内容来建立主从结构
主节点和从节点是通过网络传输(TCP)来同步数据的!
TCP内部支持了nagle算法,默认是开启的

开启了,就会增加tcp的传输延迟,节省了网络带宽
关闭了,就会减少tcp的传输延迟,增加了网络带宽
该算法的目的是和tcp的捎带应答是一样的,针对小的tcp数据包,进行合并,减少了包的个数
拓扑结构
若干个节点之间,按照什么样的方式来进行组织连接
当写数据请求太多时,可以通过关闭主节点的AOF,只在从节点上开启AOF的方法来缓解主节点压力,但是这种设定方式,有一个严重的缺陷,即主节点一旦挂了,不能让它自动重启,如果自动重启,此时没有AOF文件,就会丢失数据,进一步的主从同步,会把从节点的数据也给删了。
改进方法:当主节点挂了后,就需要让主节点从从节点这里获取到AOF文件,再重启
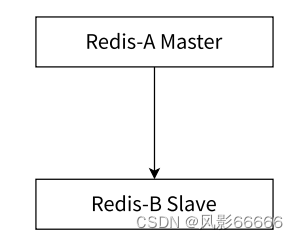
一主一从
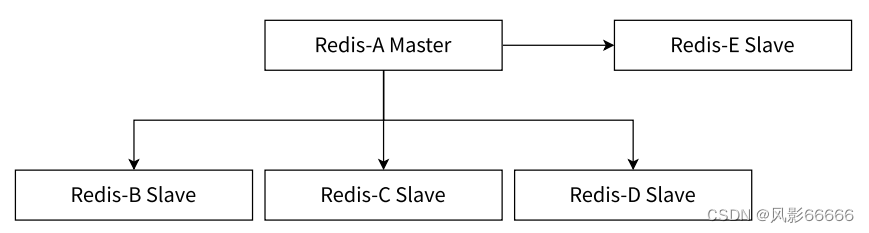
一主多从
随着从节点个数的增加,同步一条数据,就需要传输多次
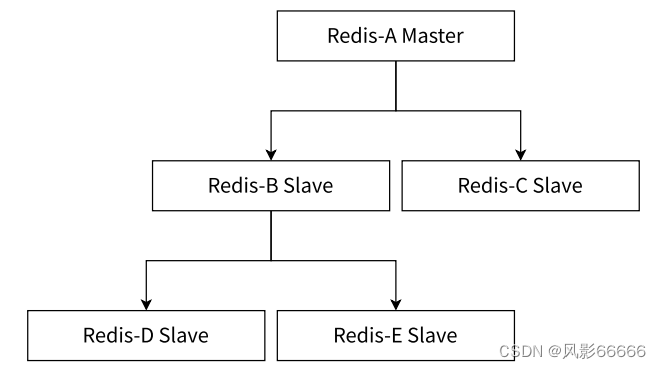
树形结构
主节点不需要那么高的网络带宽了,一旦数据进行修改了,同步的延时是比刚才更长的
主从复制原理
如下图,是从节点同步主节点数据的整个流程,TCP三次握手,是为了验证通信双方是否能正常读写数据(系统层面),即路是通的;发送ping命令,属于应用程序层面的,即车能跑
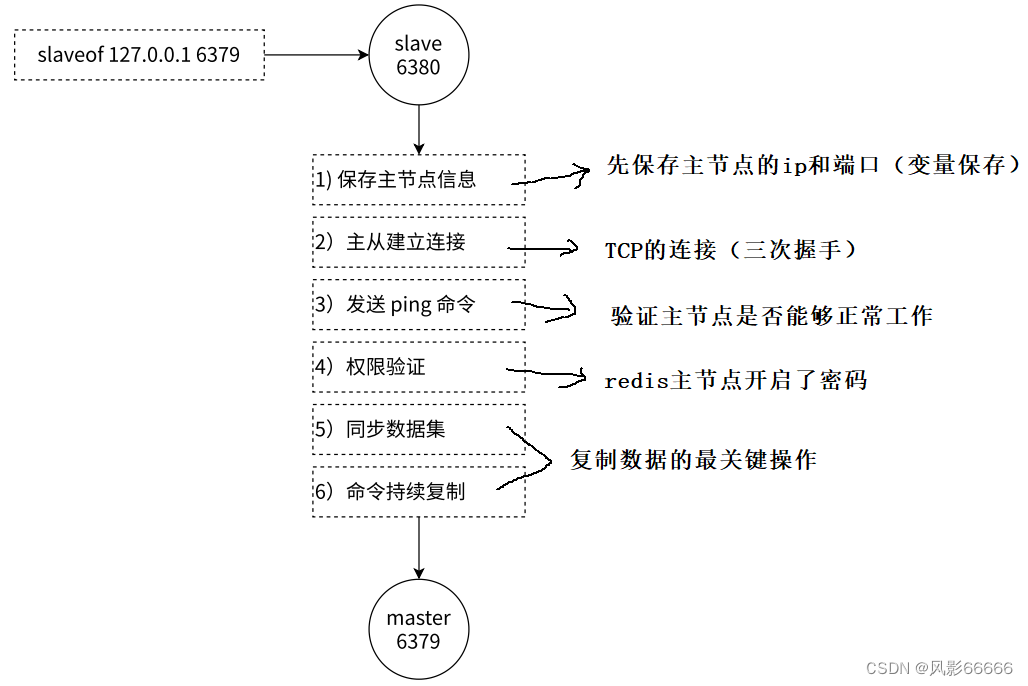
redis提供了psync命令,完成数据同步的过程,redis服务器会在建立好主从同步关系之后,自动执行psync命令,从节点负责执行psync,从节点从主节点这边拉取数据
replication复制
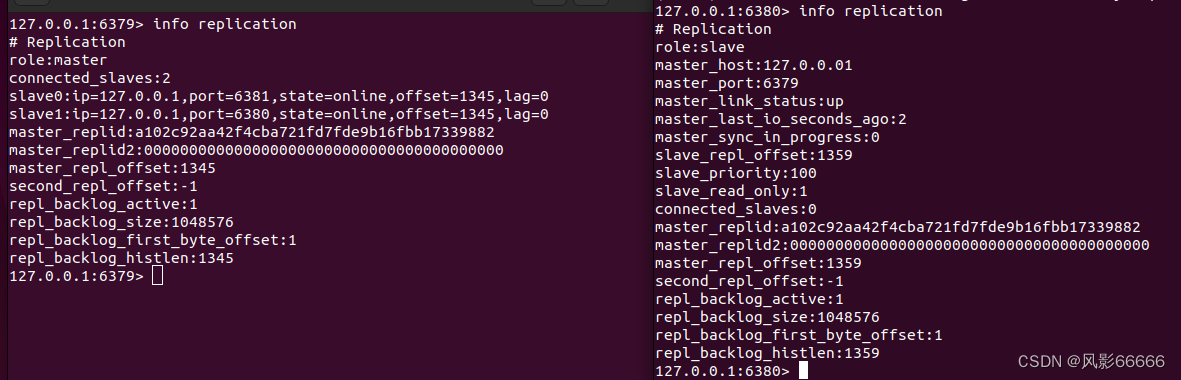
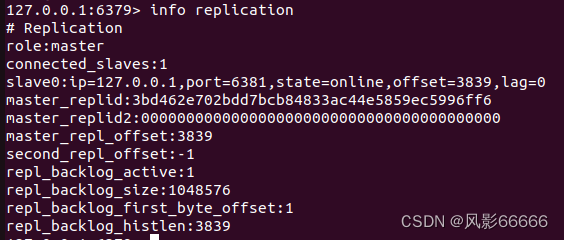
如下图,replid是主节点启动或从节点晋升成主节点的时候就会生成的,即使是同一个主节点,每次重启,生成的replid都是不同的,当主节点和从节点建立了复制关系,就会从主节点这边获取到replid
一般情况下,replid2是用不上的,有一个主节点A和一个从节点B,A生成replid,B获取到A的replid,如果A和B通信过程中出现了一些网络抖动,B可能就会认为A挂了,就会自己成为主节点,给自己生成一个replid,此时,B会通过replid2获取之前旧的replid,后续网络稳定了,B还可以根据replid2重新回到A的怀抱,需要手动干预,哨兵机制可以自动完成这个过程
offset偏移量
主节点和从节点上都会维护偏移量
主节点的偏移量:主节点会收到很多的修改操作的命令,每个命令都要占据几个字节,主节点会把这些修改命令,每个命令的字节数进行累加
从节点的偏移量:描述了,现在从节点这里数据同步到哪里了,如果从节点这边的偏移量和主节点的偏移量一样了,就表示主从节点数据一致了
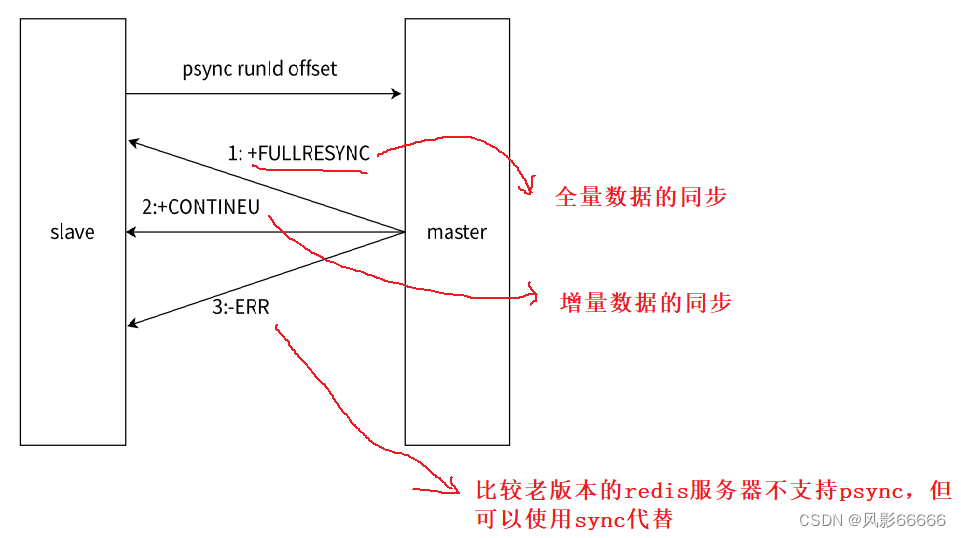
全量复制和部分复制
pysnc可以从主节点获取全量数据,也可以获取一部分数据,具体是哪一种,取决于offset,offset为-1,就是获取全量数据;offset为具体的正整数,就是从当前偏移量位置来进行获取
获取所有数据,是最稳妥的,但是也是比较低效的!!!
注意:不是从节点索要哪部分,主节点就一定给哪部分,主节点会自行判定,看当前是否方便给部分数据,不方便就只能给全量了
如下图,是psync的运行流程
全量复制
什么时候进行全量复制
1、首次和主节点进行数据同步
2、主节点不方便进行部分复制的时候
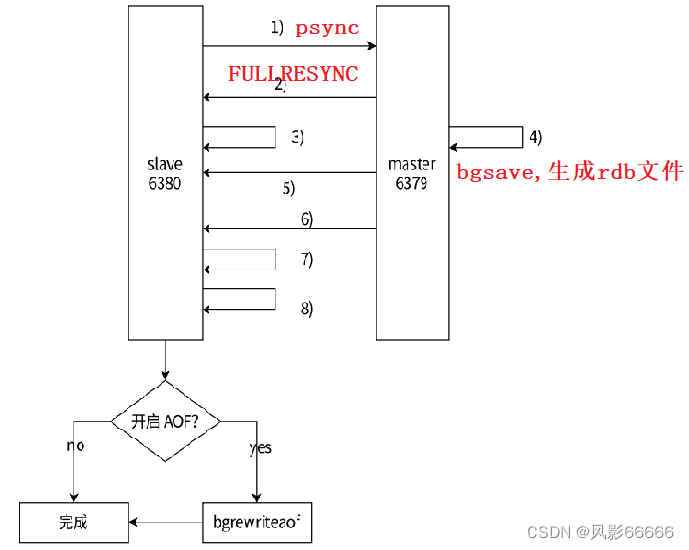
全量复制的流程,如下图
第三步,从节点接收主节点的运行信息进行保存
第四步,主节点重新生成rdb文件,有两个原因:1、rdb是二进制的格式,比较节省空间;2、不能使用已有的rdb文件,而是必须要重新生成以下,已有的rdb文件可能会和当前最新的数据存在较大差异
第五步,主节点发送rdb文件给从节点,从节点保存rdb数据到本地
第六步,主节点将从生成rdb到接收完成期间执行的写命令,写入缓冲区中,等从节点加载完rdb文件后,主节点再将缓冲区内的数据补发给从节点,补发的数据仍然按照rdb的二进制格式追加写入到收到的rdb文件中,保持主从一致性
第七步,从节点清空自身原有的旧数据
第八步,从节点加载rdb文件得到与主节点一致的数据
第九步,如果从节点,已经开启了aof,在上述的加载数据过程中,从节点就会产生储很多的aof日志,由于当前收到的是大批量的数据,产生的aof日志,整体来说,可能会存在一定的冗余信息等等,因此对aof日志进行整理,也是必要的过程
“无硬盘模式”
主节点生成的rdb的二进制数据,不是直接保存到文件中了,而是直接进行网络传输,省下了一系列读硬盘和写硬盘的操作,从节点也直接把收到的数据进行加载!!!
注意:主从复制中使用的是replicationid,简写replid,不是run id

部分复制
什么时候进行部分复制
从节点之前已经从主节点上复制过数据了。因为网络抖动或从节点重启了,从节点需要重新从主节点这边同步数据,此时看看能不能只同步一小部分数据(大部分数据都是一致的)
部分复制的流程,如下图
第一步,出现网络抖动,主节点和从节点之间重新建立连接
第二步,主从连接中断期间,主节点依然响应命令,但这些复制命令都因网络中断无法及时发送给从节点,所以暂时将这些命令滞留在积压缓冲区中,积压缓存区本质是一个环形队列
第三步,主从节点网络恢复后,从节点再次连接主节点
第四步,从节点将之前保存的replicationId和offset作为psync的参数发送给主节点,请求部分复制,replicationId是描述"数据的来源",offset是描述"数据的复制的进度"
第五步,主节点收到psync请求后,判断replicationld是否一样,不一样就进行全量复制,一样,就再看offset,如果这个进度在当前的积压缓冲区之内,就进行部分复制;如果当前从节点的进度已经超出积压缓冲区的范围,就进行全量复制
第六步,主节点将需要从节点同步的数据发送给从节点,最终完成一致性
实时复制
从节点已经和主节点同步好了数据了,但是之后,主节点这边会源源不断地收到新的修改数据的请求,主节点上的数据就会随之改变,也需要同步给从节点,从节点与主节点之间会建立TCP的长连接,然后主节点把自己收到的修改数据的请求,通过该连接发送给从节点,从节点再根据这些修改请求,修改内存中的数据
在进行实时复制的时候,需要保证连接处于可用状态,采用心跳包机制
主节点:默认,每隔10s 给从节点发送一个ping命令,从节点收到就返回pong
从节点:默认,每隔1s 给主节点发起一个特定的请求,上报当前从节点复制数据的进度
redis主节点无法重启
如下图,这个aof文件是redis服务器启动的时候,需要去加载的,redis server需要按照可读可写的方式打开这个aof文件,而这个文件对于root之外的用户只有读权限,因此,service redis-server start启动的redis服务器无法打开这个文件,也就启动失败了!

另一方面,我们前面开启了三个redis服务器进程,但使用的却是同一个aof文件,但实际上,三个redis server里面的数据不一定是一样的,所以需要区分aof文件,或者把工作目录区分开,就需要在配置文件中修改工作目录,即dir
步骤如下:
1、停止之前的redis服务器
2、删除之前工作目录下已经生成的aof文件,或者通过chown命令修改aof文件所属的用户
3、给从节点创建出新的目录,用来作为从节点的工作目录,并且修改从节点的配置文件,设定成新的目录为工作目录
4、启动redis服务器
三、主从+哨兵模式
哨兵概念
上述主节点挂了的问题,通过人工来解决,是很不靠谱的,所以就需要通过自动化的手段,来解决主节点挂了的问题
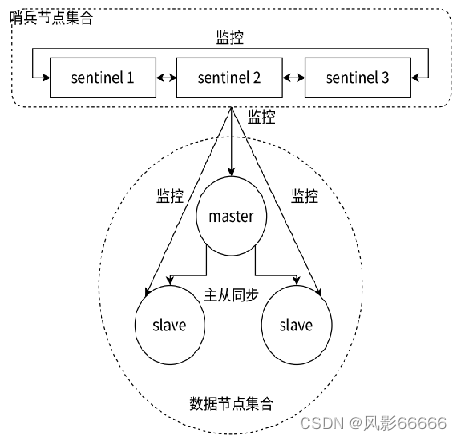
哨兵机制,是通过独立的进程来体现的,和之前redis-server是不同的进程,哨兵进程redis-sentinel不负责存储数据,只是对其它其它的redis-server进程起到监控的效果,通常,哨兵节点也会搞成一个集合,即搞多个哨兵节点
监控程序
服务器长期运行,总会有一些"意外",具体啥时候出现意外,也是无法得知的,而人又不可能像机器一样24小时去盯着服务器程序,所以就需要写一个程序,用程序来盯着服务器的运行状态
监控程序,往往需要搭配"报警程序",当发现服务器的运行出现状态异常了,就会触发报警程序,给程序员以短信、电话、邮件等等方式通知程序员,这个服务器程序出问题了!
人工恢复
1、先看看主节点还能不能抢救了,好不好抢救
2、如果主节点这边是什么原因挂的,不好定位,或者原因知道,但是短时间难以解决,就需要挑选一个从节点,设置为新的主节点
a、把选中的从节点,通过slaveof no one,自立山头;
b、把其它的从节点,修改slaveof的主节点ip port,连上新的主节点;
c、告知客户端(修改客户端的配置),让客户端能够连接新的主节点,用来完成修改数据的操作;
d、当之前挂了的主节点,修好了之后,就可以作为一个新的从节点,挂到这组机器中。
人工恢复的缺点
1、是一个很烦人的事情
2、这个操作过程,如果出错了,可能会导致问题更加严重
3、缺乏及时性,即使程序员第一时间看到了报警信息,第一时间处理,也会有浪费一些时间,这些时间内,整个redis一直不能写,这很不合适!!!
自动恢复
哨兵进程会监控现有的redis master 和slave,这些进程之间,会建立tcp长连接,通过这样的长连接,定期发送心跳包
恢复步骤如下:
1、如果是多个哨兵节点共同认为是主节点挂了,则认为是主节点挂了,主要是为了防止误判;
2、主节点确实挂了,这些哨兵节点中,就会推出一个leader,由这个leader负责从现有的从节点中,挑选一个作为新的主节点;
3、挑选出新的主节点之后,哨兵节点,就会自动控制被选中的节点,执行slaveof no one,并且控制其它从节点,修改slaveof到新的主节点;
4、哨兵节点会自动的通知客户端程序,告知新的主节点是谁,并且后续客户端再进行些写操作,就会针对新的主节点进行操作了。
redis哨兵核心功能
1、监控
2、自动的故障转移;
3、通知。
为什么是哨兵集合
redis哨兵节点,只有一个也是可以的,但也会有一些问题
1、如果哨兵节点只有一个,它本身也是容易出现问题的,万一这个哨兵节点挂了,后续redis节点也挂了,就无法进行自动的恢复过程了
2、出现误判的概率比较高,毕竟网络传输数据是容易出现抖动或者延迟或者丢包的,如果只有一个哨兵节点,出现上述问题之后,影响就比较大
基本的原则:在分布式系统中,应该避免使用 “单点”
使用docker搭建环境
为什么要使用docker
由于只有一个云服务器,把6个节点部署在一台机器上,配置起来很麻烦,比如依赖的端口号、配置文件、数据文件等等,如果直接部署,就需要小心翼翼地避开这些冲突,也会在不同主机上部署,存在较大差异
虚拟机这样的软件,就可以使用一台计算机,来模拟出多台计算机的情况,但是虚拟机有一个很大的问题,比较吃配置
docker可以认为是一个"轻量级"的虚拟机,起到了虚拟机这样的隔离环境的效果,同时又没有吃很多的硬件资源
环境安装
安装docker
安装docker-compose
apt install docker-compose
停止redis-server
service redis-server stop
使用docker获取redis镜像
docker pull redis:5.0.9
编排redis主从节点
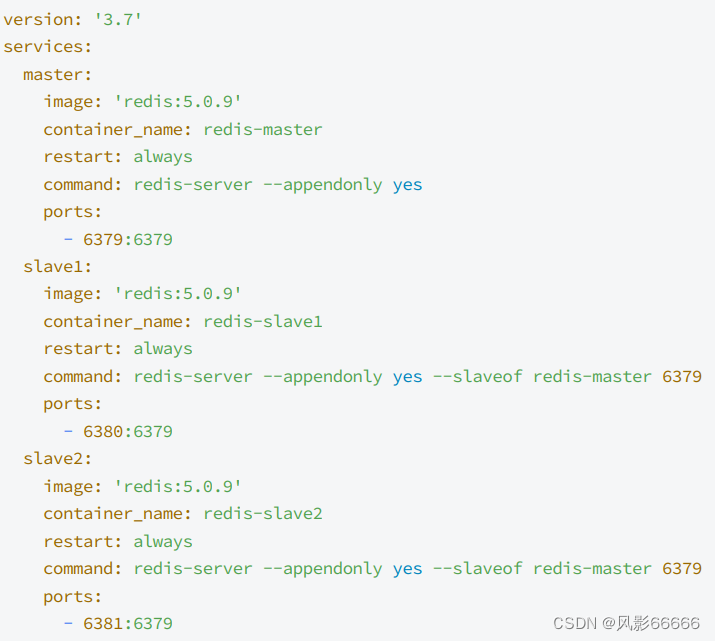
如下图,创建docker-compose.yml配置文件,把具体要创建哪些容器,每个容器运行的各种参数,描述清楚,后续通过一个简单的命令,就能批量的启动/停止这些容器了
注意:文件名不能更改!!!
docker容器,可以理解成是一个轻量的虚拟机,在这个容器里,端口号和外面宿主机的端口号是两个体系,两者不会互相冲突
当希望在容器外面能够访问到容器里面的端口号时,就可以把容器内部的端口映射成宿主机的端口
上图中,左边是宿主机的端口,右边是容器内部的端口,三个容器内部的端口都是独立的,彼此间不会发生冲突
上图中的command行,没有使用ip,而是主节点的容器名,是因为docker会自动进行域名解析,就能得到对应的ip
如下图,只要执行docker-compose up -d命令,就能启动所有容器
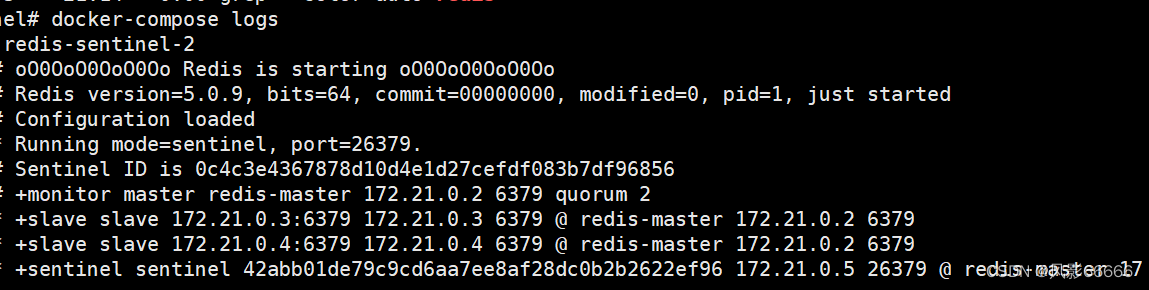
用docker-compose logs命令,可以查看运行日志

编排redis-sentinel节点
如下图,创建docker-compose.yml配置文件

对于上图中的volumes行,哨兵节点,会在运行过程中,对配置文件进行自动的修改,因此,就不能拿一个配置文件,给三个容器分别进行映射
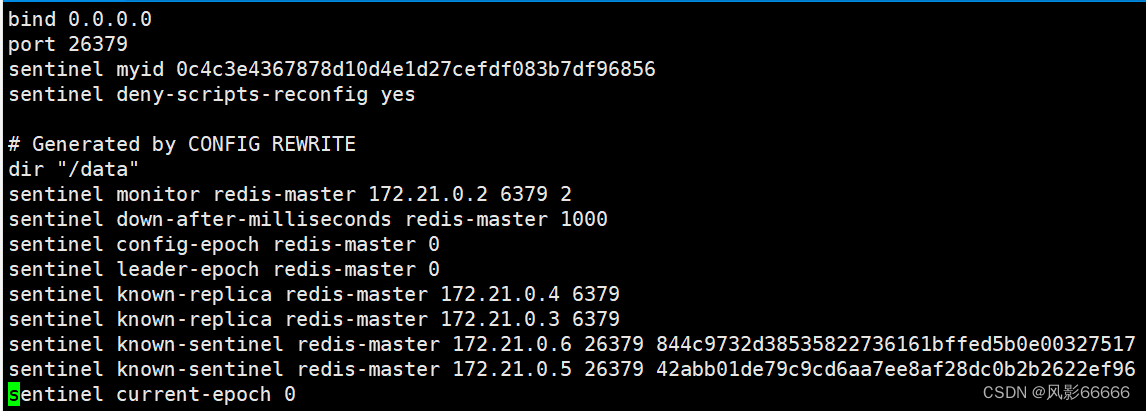
创建三个.conf配置文件,放在与上面相同的目录下,第二个redis-master,表明让它监控哪个redis服务器,其实是ip,但是docker会进行域名解析,6379是端口号,后面的2是法定票数,就是为了更稳建的确认,当前redis-server是否挂了,不能只听一个哨兵的一面之词,down-after-milliseconds是心跳包的超时时间
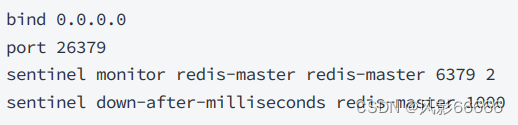
如下图,用docker-compose up -d启动所有容器
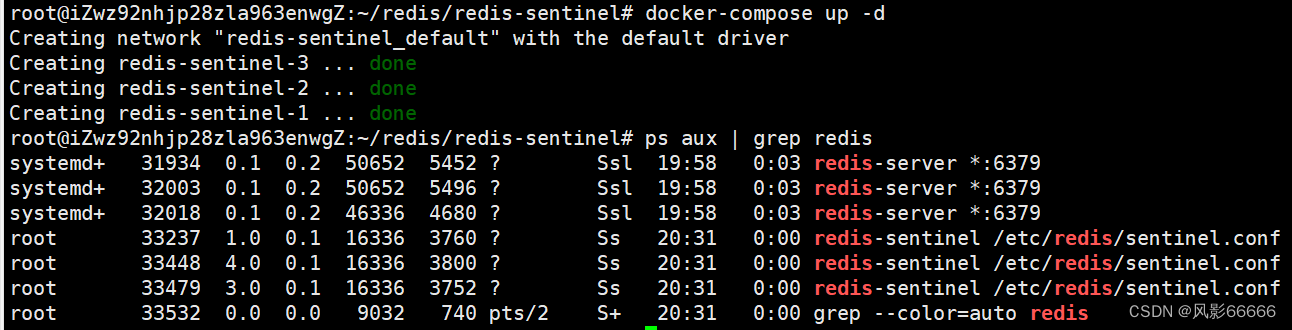
如下图,查看日志,这个哨兵节点,不认识redis-master,redis-master相当于一个域名,因为三个redis-server同属于一个局域网,三个redis-sentinel同属于另外一个局域网,默认情况下,这两个网络,不是互通的!!!

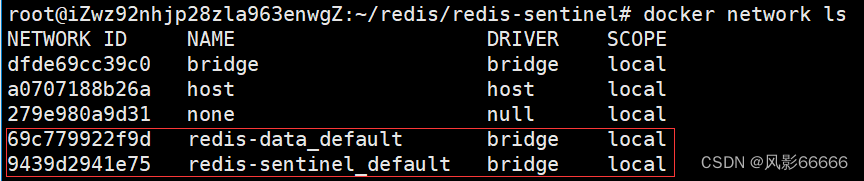
解决办法:将redis-sentinel加入到redis-server所属的局域网中即可,将下面这段代码拷贝到redis-sentinel的yml文件中
为什么不把六个容器,都写到同一个yml文件中,一次全都启动,不久直接保证互通问题了?
如果使用这种方案,由于docker-compose启动容器的顺序不确定,就不能保证redis-server一定是在哨兵之前启动的,最终结果也能正确运行,但是执行的日志可能有变数,分成两组来启动,就可以保证上述顺序,观察到的日志,是比较可控的
如下图,哨兵节点启动之后,对应的.conf配置文件被自动进行修改了
哨兵节点的作用演示
哨兵存在的意义,能够在redis主从结构出现问题的时候(比如主节点挂了),此时哨兵节点就能够自动的选择出一个主节点,来代替之前挂了的节点,保证整个redis仍然是可用状态
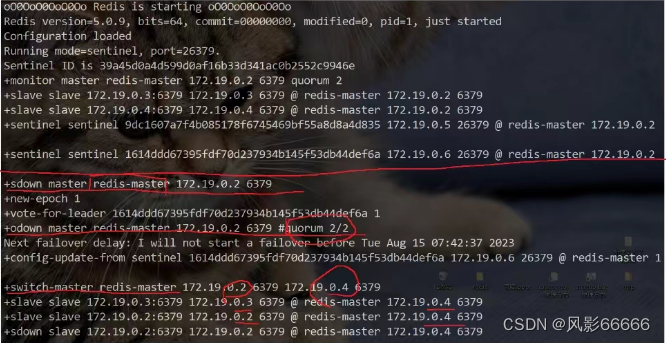
如下图,手动把主节点干掉,此时哨兵节点就开始工作了

用docker stop redis-master干掉主节点,日志如下图
sdown(主观下线):本哨兵节点,认为该主节点挂了
odwn(客观下线):好几个哨兵节点都认为该节点挂了,达成了一致(法定票数),此时,主节点挂了这个事情就被证实了,此时就需要哨兵节点选出一个从节点,作为新的主节点,此处就需要提拔出一个新的主节点!
哨兵重新选取主节点的流程
1、主观下线
哨兵节点通过心跳包,判断redis服务器是否正常工作,如果心跳包没有如约而至,就说明redis服务器挂了,但不能排除网络波动的影响,所以只能单方面认为这个redis节点挂了
2、客观下线
多个哨兵都认为主节点挂了(认为挂了的哨兵节点数目达到法定票数),哨兵们就认为这个主节点数是客观下线
3、要让多个哨兵节点,选出一个leader节点,由这个leader负责选出一个从节点作为新的主节点,如果总的票数超过哨兵节点个数的一半,选举就完成了,最好是把哨兵节点个数设置为奇数个,方便选举!!!
如下图,是三个哨兵节点的ID
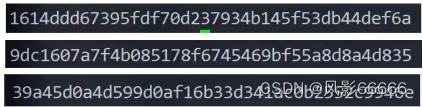
如下图,1号哨兵节点给自己投了一票,2号和3号也给一号各投了一票

4、此时leader选举完毕,leader就需要挑选出一个从节点,作为新的主节点,从以下几个方面考虑
①优先级:每个redis数据节点,都会在配置文件中,有一个优先级的设置,slave-priority,优先级高的从节点就会胜出
②offset:最大就是胜出,数值越大,说明从节点的数据和主节点就越接近
③run id:每个redis节点启动的时候随机生成的一串数字,此时随便选一个都行
5、当把新的主节点选好后,leader就会控制这个节点,执行slave no one成为master,再控制其它节点,执行slave of,让这些其它节点,以新的master作为主节点
注意:挂了不一定是进程崩溃了,只要无法正常访问,都可以认为是挂了
四、集群模式
概念
广义的集群:只要你是多个机器,构成了分布式系统,都可以称为是一个"集群"
狭义的集群:redis提供的集群模式,这个集群模式之下,主要是解决存储空间不足的问题
前面的哨兵+主从,只是提高了系统的可用性,本质上还是redis主从节点存储数据,其中,就要求一个主节点/从节点存储整个数据的"全集"
引入集群,就是每台机器存储一部分数据,比如1TB的数据,有3台机器,就每一台存储1/3TB的数据,当然,这里的3台机器,又要搭配若干个从节点
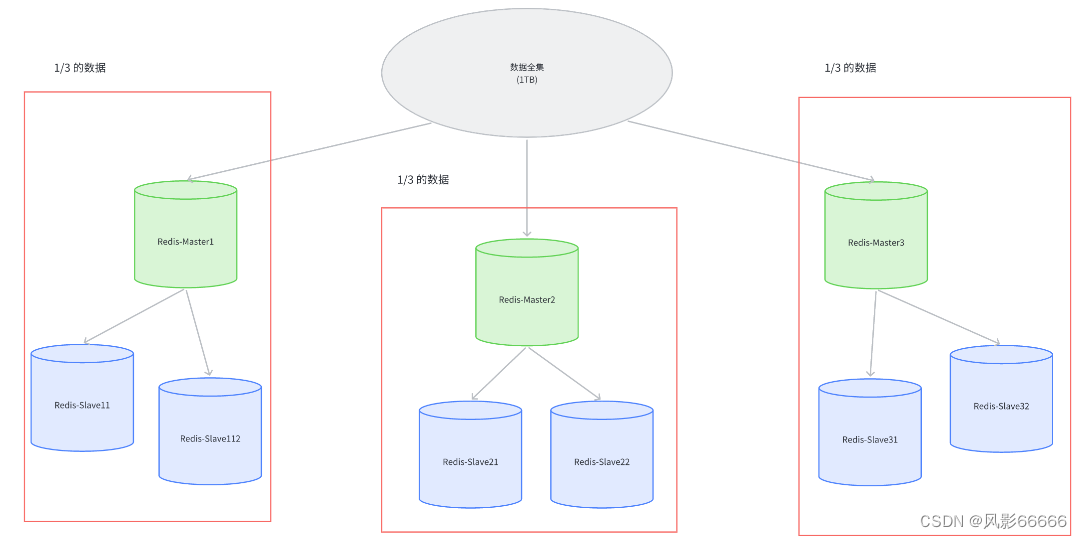
如何分配数据
上图中的每一个红色方框部分,都可以称为是一个分片
哈希求余
该方式借鉴了哈希表的基本思想,利用hash函数,把一个key映射到整数,再针对数组的长度求余,就可以得到一个数组下标
比如有3个分片,编号0、1、2,此时就可以针对要插入的数据的key(redis都是键值对结构的数据)计算hash值,(比如使用md5)再把这个hash值余上分片个数,就得到了一个编号,也就能把这个数据放到下标对应的分片中了
分片的主要目的就是为了提高存储能力,一旦服务器集群需要扩容,就需要更高的成本,即需要有更多的分片,同时也需要搬运数据
如下图,假设下面的三位数是md5算法计算后的hash值,可以看出在扩容后,20个数据,却只有4个数据不需要搬运,而如果是20亿,那要搬运的数据就非常可怕了,这就需要通过"替换"的方式来是西安扩容,即采用更多的机器,提前扩容,然后用新的集群替换掉当前集群,但成本更高,操作步骤也非常复杂

MD5算法本身是一个计算hash值的算法,针对一个字符串,里面的内容进行一系列的数学变换,成为一个整数,是一个十六进制的数字
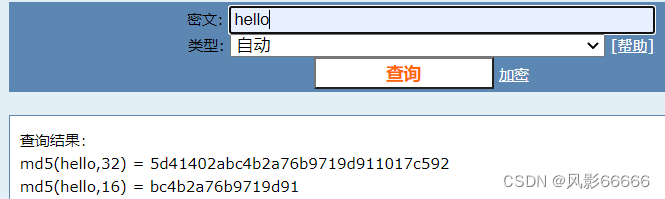
特点如下:
1、MD5计算结果是定长的,无论输入的原字符串多长,最终算出的结果就是固定长度
2、MD5计算结果是分散的,哪怕两个字符串大部分相同,只有一个小的地方不同,计算出来的md5值也会差别很大
3、MD5计算结果是不可逆的,给你md5值,很难还原出原始的字符串的
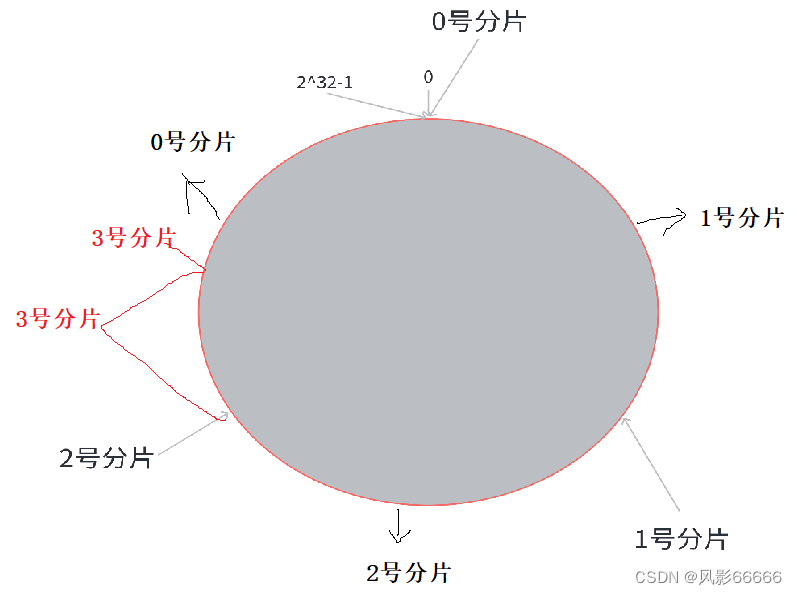
一致性哈希
上述是当前key属于哪个分片,是交替的,而一致性哈希,则是将交替出现改为了连续出现
如下图,把0->2^32-1数据范围看成一个圆,分成3块,顺时针旋转,当遇到1号分片,就代表前面那块区域属于1号分片,当需要扩容时,就把其中一个分片分成两份,如下图,把0号分片的范围分成两半,缺点是几个分片上的数据量,就可能不均匀了
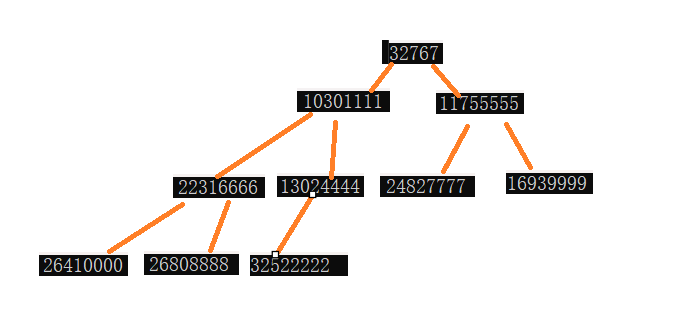
哈希槽分区
是redis真正采用的分片算法
如下图,hash_slot就是计算出来的哈希槽,crc16是一种计算hash值的算法
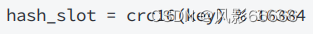
假设有3个分片,就可以分出三块,如下图,每个分片持有的槽位号,可以是连续的,也可以是不连续的,另外,虽然不是严格意义的"均匀",但差异也非常小了

每个分片都会使用"位图",来表示出当前有多少槽位号,16384个bit位,用每一位0/1区分自己这个分片当前是否持有该槽位号
这种算法本质就是把一致性哈希合哈希求余进行了结合
如下图,可以从每个分片中分出一块,拼凑给新的分片,同时,也只有被移动的槽位,对应的数据才需要被搬运,redis中,当前某个分片包含哪些槽位都是可以手动配置的

Redis集群是最多有16384个分片吗?
此时每个分片上就只有一个槽位,此时很难保证数据在各个分片上的均衡性,有的槽位可能有多个key,有的槽位可能没有key
key是要先映射到槽位,再映射到分片数,如果每个分片包含的槽位比较多,如果槽位个数相当,就可以认为是包含的key数目相当的;如果每个分片包含的槽位非常少,槽位个数不一定能直观的反应到key的数目
实际上,redis的作者建议集群分片数不应该超过1000,如果真有16384个分片,整个数据服务器的集群规模就太可怕了,几万台主机构成的集群,可用性也是非常堪忧的!!!
为什么是16384个槽位?
心跳包中包含了该节点持有哪些slots,这个是用位图结构表示的,16384个slots,需要的位图大小是2kb,如果给定的slots数更多,比如65536,就需要8kb大小的位图,在频繁的网络心跳包中,是一个不小的开销
搭建集群环境
如下图, 是要搭建的集群环境,这里还是采用docker来是实现
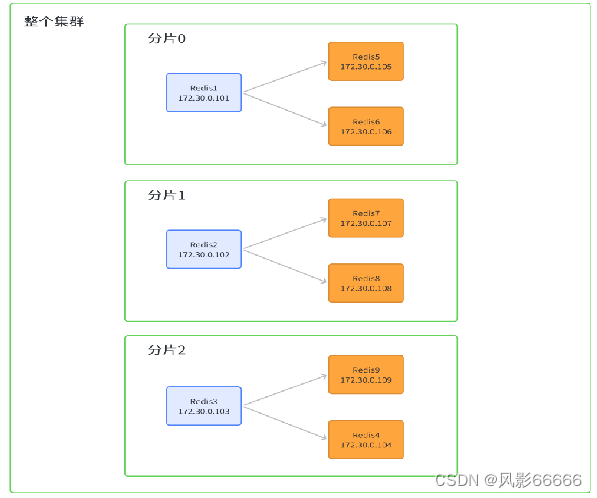
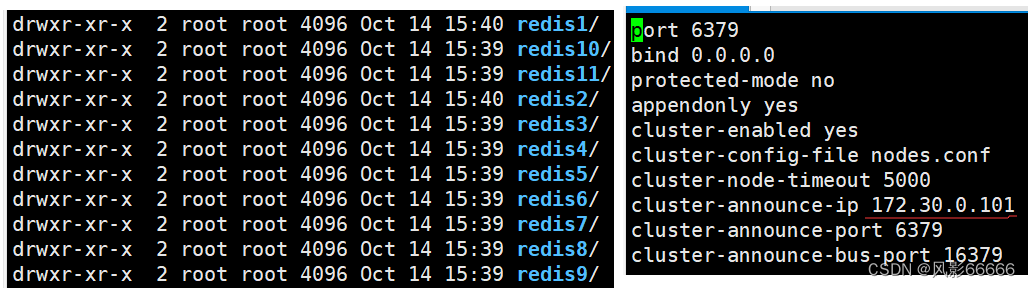
创建shell脚本文件
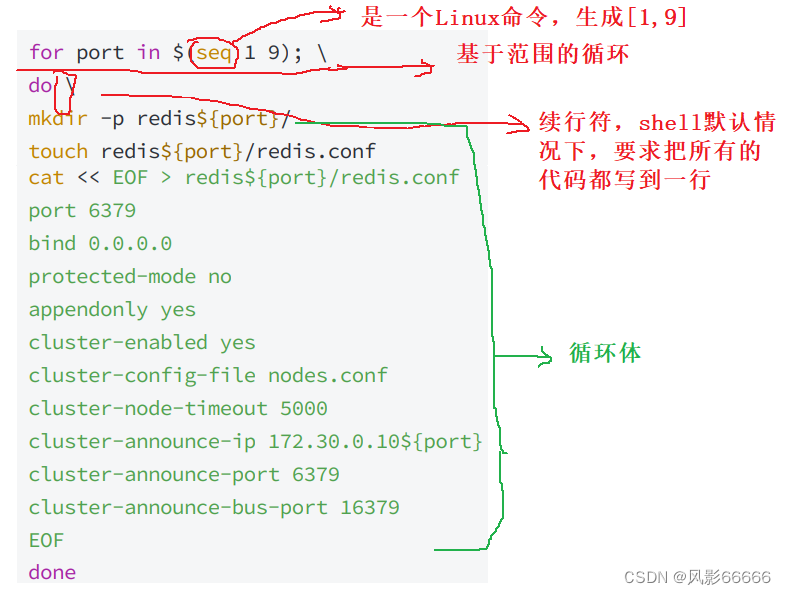
需要创建的节点有11个,一个一个手动创建很麻烦,所以这里借助shell脚本来实现,如下图,对于for循环,do done来表示代码块的开始和结束,{}用来表示变量,shell中不是用+来拼接字符串的,而是直接写到一起
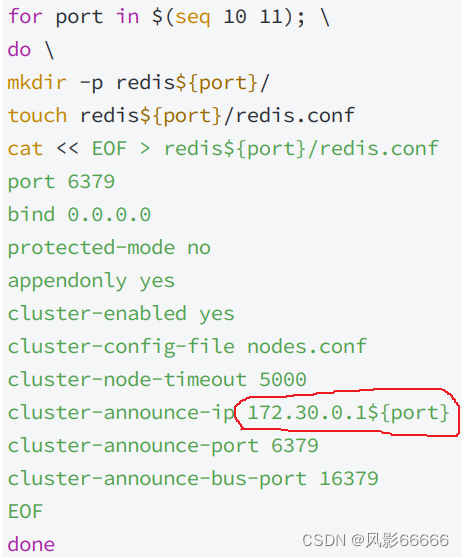
如下图,是要扩容的两个分片的配置
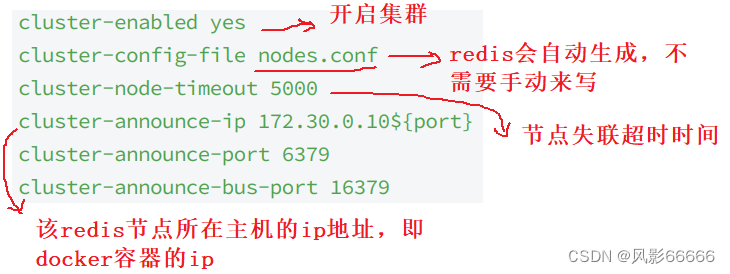
如下图,port是容器内的端口
业务端口:用来进行业务数据通信的,响应redis客户端的请求
管理端口:为了完成一些管理上的任务来进行通信的,如果某个分片中的redis主节点挂了,就需要让从节点称为主节点,就需要通过刚才的管理端口来完成对应的操作
将上述信息写入到generate.sh文件中
创建docker-compose.yml
如下图,创建docker-compose.yml文件,并写入配置信息,一共要有11份,大致相同,个别地方需要修改
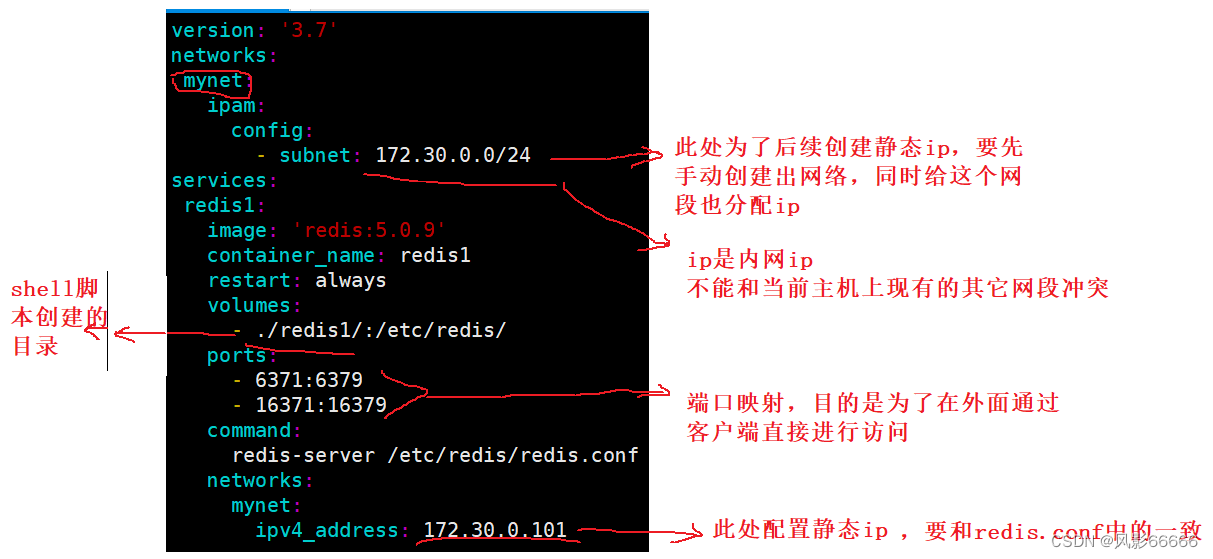
注意:启动前,一定要把之前已经运行的redis啥的都干掉,否则就可能会因为端口冲突等原因,导致现在的启动失败!!!
构建集群
如下图,create表示构建集群,replicas 2表示描述集群的每个分片,应该是有2个从节点,其它的则是每个参与构建集群的ip和端口,端口都是容器内部的端口号,这个命令是直接在命令行上执行的,而不是redis-cli

注意:redis在构建集群的时候,谁是主节点,谁是从节点,谁和谁是一个分片,都不是固定的,本身从集群的角度出发,提供的这些节点之间就应该是等价的!!!
实战演练
效果演示
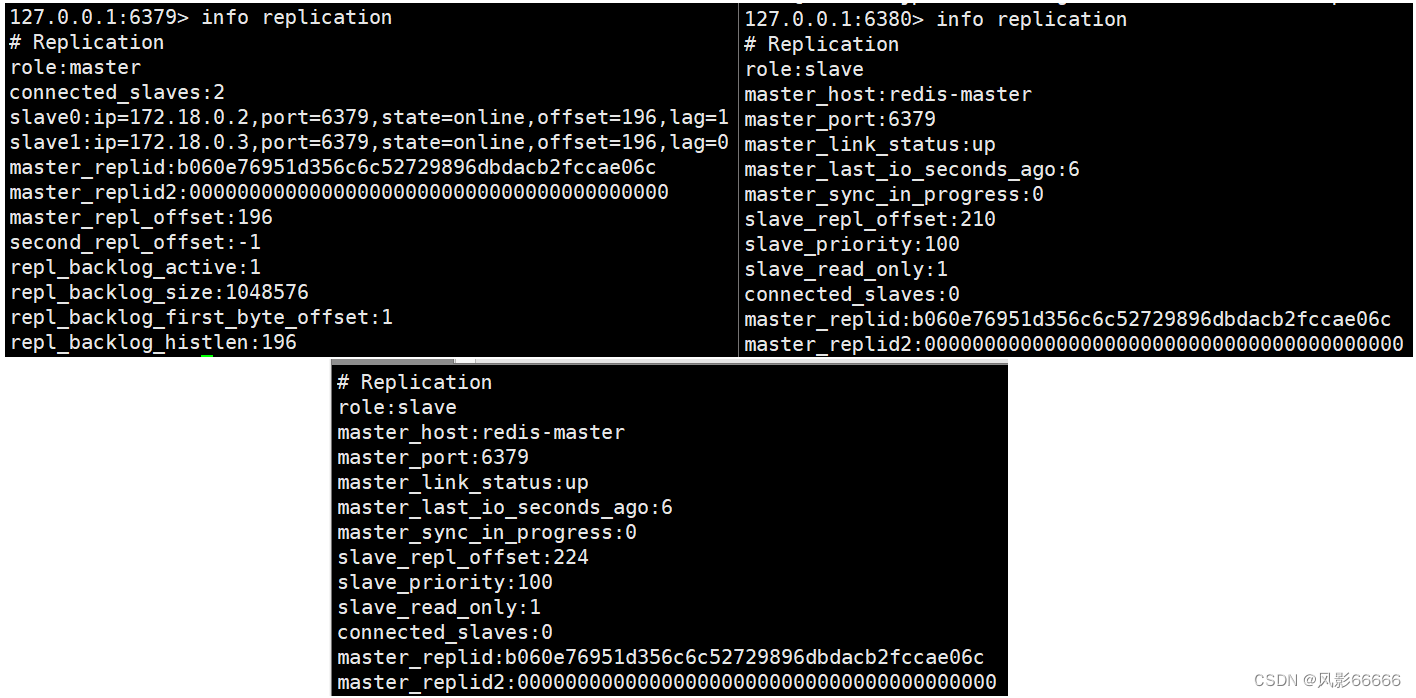
如下图,配置文件写了端口映射后,两种方式都能连接服务器,从101-109九个节点,现在是一个整体,使用客户端连上任意一个节点,本质上都是等价的

如下图,cluster nodes查看集群信息

如下图,要设置的键值经过hash求值后,被映射到102,9189是槽位号,但当前是101,就会报错,要想解决这个问题,就得在连接服务器时,带上-c选项,redis客户端就会根据当前key实际算出来的槽位号,自动找到匹配的分片主机,进一步地完成操作

如下图,当映射到哪个分片时,就会切换到对应的节点
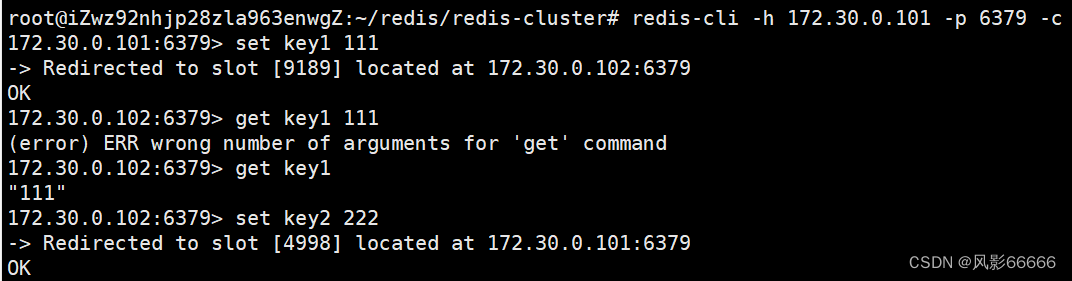
如下图,对于一次性与多个key有关的命令,则会报错,因为key是分散在不同的分片上,就可能会出现问题

故障处理
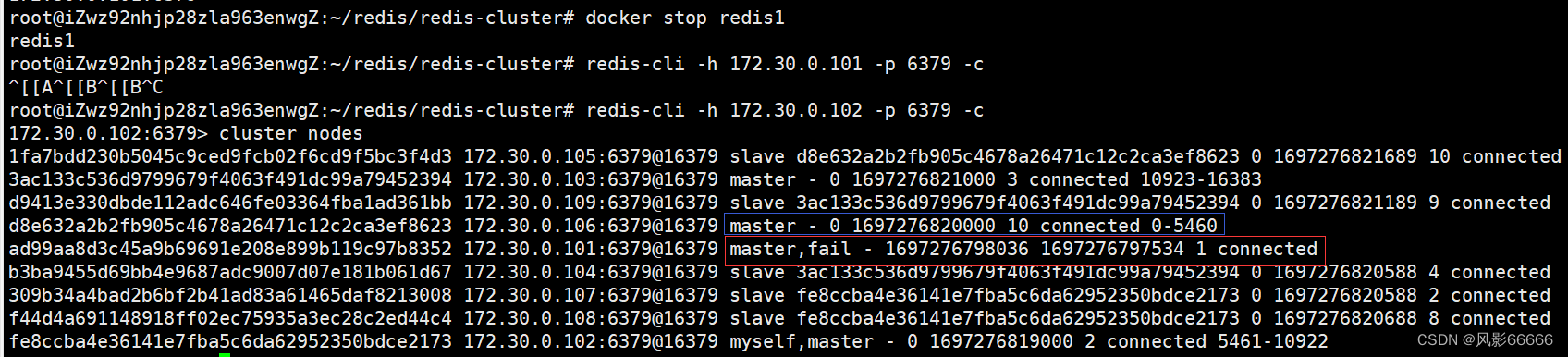
如下图,当某个分片的主节点挂了,就会自动地把该主节点旗下从节点,挑选一个出来,提拔成为主节点,fail就表示节点挂了,之前的时候,101是主节点,105和106是从节点,当101挂了之后,106成为了新的主节点,而105成为了106的从节点,当恢复101后,它会成为从节点

故障判定
通过心跳包,来识别出某个节点是否挂了
1、节点A给节点B发生ping包,B就会给A返回一个pong包,ping和pong除了message type属性之外,其余部分都相同,包含了集群的配置信息
2、每个节点,每秒钟,都会给一些随机的节点发起ping包,而不是全发一遍,减少心跳包数量
3、当节点A给节点B发送ping包,不能如期响应的时候,此时A就会尝试重置和B的tcp连接,如果连接失败,A就会把B设为PFAIL状态(相当于主观下线)
4、A判定B位PFAIL之后,会通过redis内置的Gossip协议,和其它节点进行沟通,向其它节点确认B的状态,每个节点都会维护一个自己的"下线列表"
5、A发现其它很多节点,也认为B位PFAIL,并且数目超过总集群个数的一半,那么A就会把B标记成FAIL(相当于客观下线),并且把这个消息同步给其它节点,其它节点也会把B标记位FAIL
故障迁移
如果B为从节点,就不需要进行故障迁移,如果是主节点,就会由B的从节点(比如C和D)触发故障迁移
1、从节点判定自己是否具有参选资格,如果从节点和主节点已经太久没通信(与主节点数据可能差异太大),时间超过阈值,就失去了竞选资格
2、具有资格的节点,比如C和D,就和先休眠一定时间,休眠时间 = 500ms基础时间 + [0,500ms]随机时间 + 排名 * 1000ms,offset的值越大,则排名越靠前(越小),数据就越接近主节点
3、比如C的休眠时间到了,C就会给其它所有集群中的节点,进行拉票操作,但是只有主节点才有投票资格
4、主节点就会把自己的票投给C(每个主节点一票),当C收到的票数超过主节点数目的一半,C就会晋升成为主节点,C自己负责执行slaveof no one,让D执行slaveof C
5、C还会把自己成为主节点的消息,同步给集群的其它节点,大家也会更新自己保存的集群结构信息
谁休眠时间短,大概率就是新的主节点了,更多的时候,是为了选一个节点出来,至于选谁,则没那么重要!!!
集群宕机的三种情况
1、某个分片,所有的主节点和从节点都挂了,该分片就无法提供数据服务了
2、某个分片,主节点挂了,但是没有从节点
3、超过半数的master节点都挂了,如果突然一系列的master都挂了,此时说明集群遇到了非常严重的情况,就得赶紧停下来,检查是不是出问题了
建议:如果集群中有个节点挂了,无论是什么节点,都需要尽快地处理好
集群扩容
添加主节点
如下图,把110和111加入到集群中,110为master,数据分片从3 -> 4,110对应的是要加入的新节点,101是集群中的任意节点,表示加入到哪个集群


重新分配slots
把之前三组master上面的slots拎出来一些,分配给新的master

如下图,all:表示从其它每个持有slots的master拿槽位,也能手动指定,从一个或某几个节点来移动,以done结尾,输入all后,会给出搬运的计划,当后面出现询问输入yes后,搬运真正开始,此时不仅仅是slots重新划分,也会把slots上对应的数据,也搬运到新的主机上

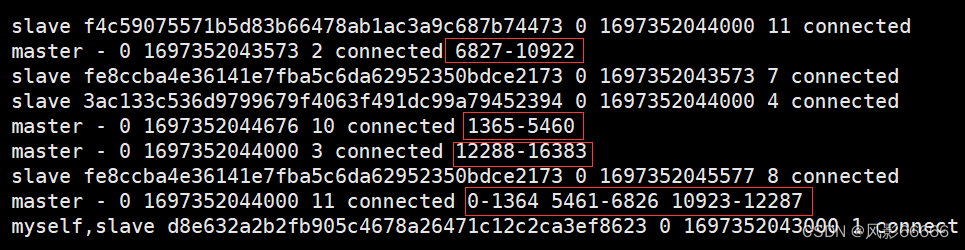
如果在搬运slots/key的过程中,此时客户端能否访问redis集群?
针对这些未搬运的key,此时是可以正常访问的,针对这些正在搬运中的key,是有可能会出现出错的情况的。假设客户端访问k1,集群通过分配算法,得到k1是第一个分片的数据,就会重定向到第一个分片的节点,就可能在重定向过去之后,正好k1被搬走了,自然也就无法访问了
添加从节点
如下图,id后面跟新分片的主节点的id,第一个地址是新添加的节点,第二个是集群的任意节点


五、缓存
概念
为什么关系型数据库性能不高?
1、数据库把数据存储在硬盘上,硬盘的IO速度并不快,特别是随机访问
2、如果查询不能命中索引,就需要进行表的遍历,会大大增加硬盘IO次数
3、关系型数据库对于SQL的执行会做一系列的解析,校验,优化工作
4、如果是一些复杂操作,比如联合查询,需要进行笛卡尔积操作,效率更是会降低很多
所以通常是使用redis作为数据库的缓存,因为数据库是非常重要的组件,且数据库的速度又比较慢,效率会很低,承担的并发量很有限,一旦请求数量多了,数据库的压力就会很大,甚至很容易宕机。服务器每次处理一个请求,一定要消耗一些硬件资源(cpu、内存、硬盘、网络),任意一种资源的消耗超出了机器能提供的上限,机器就很容易出现故障
如何提高数据库能承担的并发量?
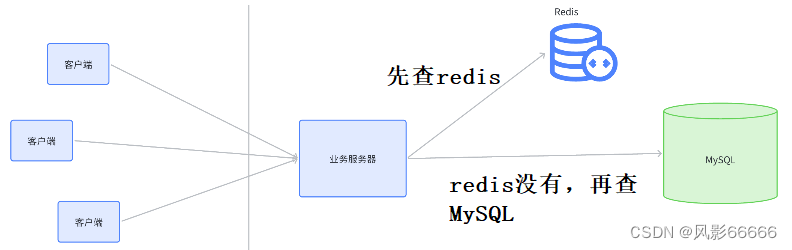
1、开源:引入更多的机器,构成数据库集群
2、节流:引入缓存,把一些频繁读取的热点数据,保存到缓存上,后续在查询数据的时候,如果缓存中已经存在了,就不再访问数据库了
更新策略
定期生成
会把访问的数据,以日志的形式记录下来,然后每隔一定时间更新一次,比如每天或每月,以搜索引擎为例
通过日志,把都使用到了哪些词,给记录下来。就可以针对这些日志进行统计(程序来做),统计这一天/月每个词出现的频率,再根据频率降序排序,再取出前20%的词,就可以把这些词认为是"热点词",然后把这些热词中,涉及到的搜索结果,提前拎出来,放到类似于"redis"这样的缓存中
写一套离线的流程(使用shell,python写脚本代码),可以写出定时任务来触发
1、完成统计热词过程
2、根据热词,找到搜索结果的数据
3、把得到的缓存数据同步到缓存服务器中
4、控制这些缓存服务器自动重启
优点:上述过程,实际比较简单,过程更可控,方便排查问题
缺点:实时性不够,如果出现一些突发性事件,有一些本来不是热词的内容,成了热词,新的热词可能会给后面的数据库带来较大压力
实时生成
如果在redis中查到了,就直接返回,没查到,就从数据库查,把查到的结果同步也写入redis,经过一段时间的"动态平衡",redis中的key就逐渐都成了热点数据
当然,不停的写入redis,就会使redis的内存占用越来越多,逐渐达到内存上限(redis配置的),如果继续往里面插入数据,就会触发问题,所以redis引入了"内存淘汰策略"
FIFO:把缓存中存在时间最久的(最先到来的)淘汰掉
LRU:记录每个key的最近访问时间,把最近访问时间最老的key淘汰掉
LFU:记录每个key最近一段时间的访问次数,把访问次数最少的淘汰掉
Random:从所有的key中抽取幸运儿随机淘汰掉

注意事项
缓存预热(Cache preheating)
redis服务器首次接入,服务器是没有数据的,此时所有的请求都会打给数据库,数据库压力很大,随着时间的推移,redis上的数据越积累越多,数据库承担的压力就逐渐减小了
缓存预热,就是用来解决上述问题的,把定期生成和实时生成结合,先通过离线的方式,通过一些统计的途径,先把热点数据找到一批,导入到redis中,此时导入的这批热点数据,就能帮数据库承担很大的压力,随着时间的推移,逐渐使用新的热点数据淘汰旧的数据
缓存穿透(Cache penetration)
查询的某个key,在redis中没有,数据库中也没有,这个key肯定不会被更新到redis中,如果这次查询没有,下次查,仍然没有,如果像这样的数据,存在很多,并且还反复查询,一样也会给数据库带来很大的压力
为何会产生?
1、业务设计不合理,比如缺少必要的参数校验环节,导致非法的key也被进行查询了
2、开发/运维误操作,不小心把部分数据从数据库上误删了
3、黑客恶意攻击
解决办法
通过改进业务/加强监控报警
更靠谱的方案(降低问题的严重性)
1、如果发现这个key,在redis和数据库都不存在,仍然写入redis中,value设成一个非法值,比如""
2、还可以引入布隆过滤器,每次查询redsi/数据库之前,都先用布隆过滤器判定一下key是否存在(把所有的key都插入到布隆过滤器中)
缓存雪崩(Cache avalanche)
由于在短时间内,redis上大规模的key失效,导致缓存命中率陡然下降,且数据库的压力迅速上升,甚至直接宕机
为何会产生?
1、redis直接挂了,redis宕机或redis集群模式下大量节点宕机
2、redis正常,但是可能之前短时间内设置了很多key给redis,且设置的过期时间是相同的
解决办法
1、加强监控报警,加强redis集群可用性的保证
2、不给key设置过期时间或设置过期时间的时候添加随机因子(避免同一时刻过期)
缓存击穿(Cache breakdown)
相当于缓存雪崩的特殊情况,针对热点key,突然过期了,导致大量的请求直接访问数据库,甚至引起数据库宕机
解决办法
1、基于统计的方式发现热点key,并设置永不过期
2、进行必要的服务降级(假设本身服务器的功能有10个,适当的关闭一些不重要的功能,只保留核心功能),访问数据库的时候使用分布式锁,限制同时请求数据库的并发数
六、分布式锁
概念
在分布式系统中,是有很多线程的(每个服务器,都是独立的进程),因此,之前的锁(std::mutex),本质都是只能在一个进程内部生成,就难以对现在分布式系统中的多个进程之间产生制约,在分布式系统中,多个进程之间的执行顺序也是不确定的(随机性),也就存在线程安全问题,需要用分布式锁来解决这个问题
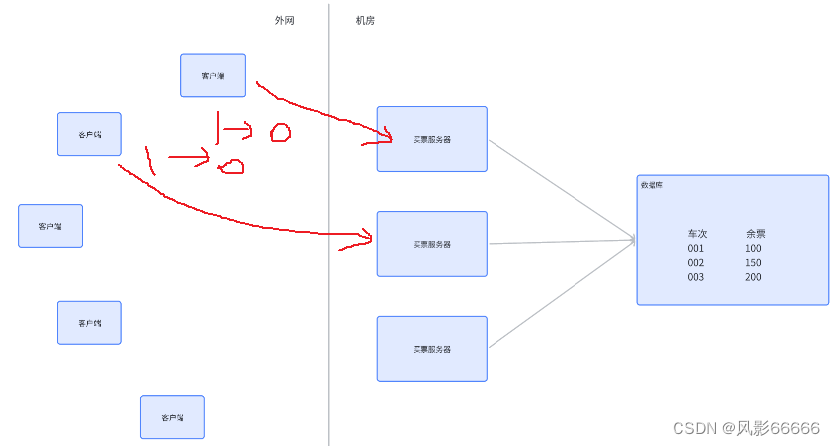
如下图,以卖票为例,客户端1先执行查询余额,发现剩余一张,在即将执行1->0过程之前,客户端2也执行查询余额,也是剩余一张,客户端2也执行1->0过程,这样一张票就卖给了两个人,超卖了!
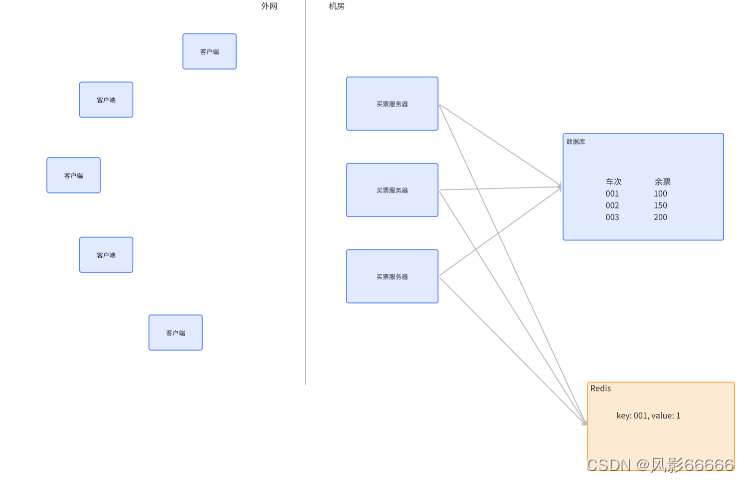
所谓的分布式锁,也是一个或一组单独的服务器程序,给其他的服务器提供"加锁"这样的服务,比如redis,当然,也能使用mysql或zookeeper这样的组件来实现分布式锁
如下图,引入分布式锁,买票服务器,在进行买票操作的过程中,就需要先加锁(往redis上设置一个特殊的key-value,完成上述买票操作,再把这个key-value删除),其它服务器也想买票的时候,也得去redis上尝试设置key-value,如果key-value已经存在,就认为"加锁失败"(至于是放弃或阻塞,看具体的实现策略),就可以保证,第一个服务器执行"查询 -> 更新"过程中,第二个服务器不会执行"查询",也就解决了上述"超卖"的问题
上述买票场景,使用MySQL的事务,也可以批量执行查询+修改操作,但是分布式系统中,要访问的共享资源不一定是MySQL,也可能是其它的存储介质,就没有事务,也可能是执行一段特定的操作,是通过统一的服务器完成执行操作
锁释放问题
使用setnx可以实现"加锁",使用del来实现"解锁",执行后续逻辑过程中,程序崩溃(服务器直接掉电、进程异常终止)了,没有执行解锁,而C++中的RAII也无法解决这个问题,这样的情况会导致redis上设置的key无人删除,进而使得其它服务器无法获取到锁
解决办法
可以给set的key设置过期时间,一旦时间到了,key就会自动被删除掉了,set ex nx来完成设置,setnx、expire这样的设置方式是不行的,redis上的多个命令之间,无法保证原子性,此时就可能出现,这两个命令,一个成功,一个失败的情况,相比之下,使用一条命令设置,更加稳妥
校验机制
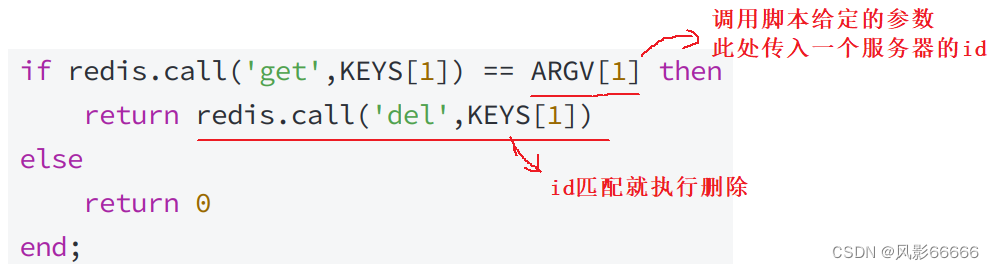
出现了服务器1执行了加锁,服务器2执行了解锁的问题怎么办?
正常来说,肯定不是故意的,但是代码总会有bug,不小心执行到了解锁操作,就可能进一步给整个系统带来更严重的问题(比如超卖)
解决办法
1、给服务器编号,每个服务器都有一个自己的身份标识
2、进行加锁的时候,设置key-value,key对应着要针对哪个资源加锁(比如车次),value就可以存储刚才服务器的编号,标识出当前这个锁是哪个服务器加上的,后续解锁的时候,就可以进行校验了
3、解锁的时候,先查询一下这个锁对应的服务器编号,然后判定一下这个编号是否就是当前执行解锁的服务器编号,如果是,才能真正执行del,如果不是,就失败,这样就能有效避免"误解锁"
引入lua脚本
在解锁的时候,先查询判定,再进行del,此处是两步操作,不是原子的,就可能会出现问题
一个服务器内部,也可能是多线程的,此时,就可能同一个服务器,两个线程都在执行解锁操作,如下图,DEL会被重复执行,看似也没有什么问题,但是如果服务器2在两次DEL之间,执行加锁操作,就可能会出现问题了,服务器2的线程正好要执行加锁,此时,由于A已经把锁释放了,线程C的加锁是能够成功的,但是紧接着,线程B执行DEL,就把刚刚线程C的加锁操作给解锁了
本质:get和del操作不是原子的!!!

解决办法
虽然redis事务比较弱,但是能够避免插队,可以解决上述问题,但这里用lua脚本更合适,可以使用lua编写一些逻辑,把这个脚本上传到redis服务器上,然后就可以让客户端来控制redis,执行脚本了
redis执行lua脚本的过程,也是原子的,相当于执行一条命令
引入"看门狗"
要在加锁的时候,给key设置过期时间,过期时间,设置多少合适?如果设置得太短,就可能在你的业务逻辑还没执行完时,就释放锁了;如果设置得太长,就会导致锁释放不及时的问题,所以更好的方式是"动态续约"
动态续约,需要服务器这边有一个专门的线程,负责续约这件事,这个线程也被称为"看门狗"
初始情况下,设置一个过期时间,比如1s,就提前在还剩300ms(不一定是300ms)的时候,如果当前任务还没执行完,就把过期时间再续上1s,等到时间又快到了,任务还没执行完,就再续等等,如果服务器,中途崩溃了,自然就没人负责续约了,此时,锁就能在较短的时间内被自动释放!!!
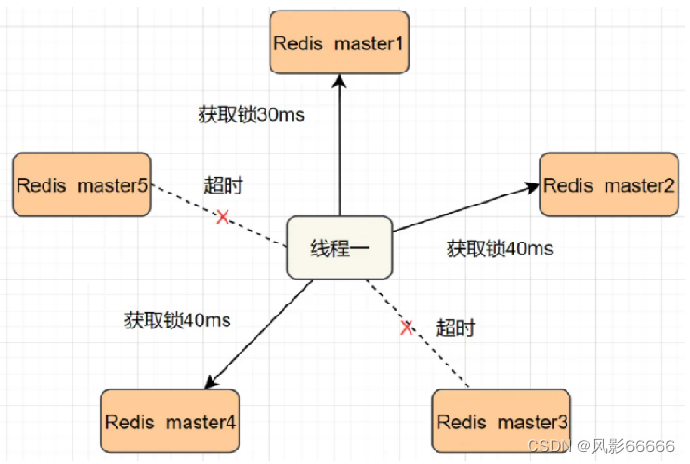
redlock算法
使用redis作为分布式锁,redis本身也是有很大可能挂了的,要想保证"高可用",就需要通过这样一系列的"预案演习"
进行加锁,就是把key设置到主节点上,如果主节点挂了,有哨兵自动把从节点升级成主节点,进一步保证刚才的锁仍然可用
主节点和从节点之间的数据同步,是存在延时的,可能主节点收到了set请求,还没来得及同步给从节点,主节点挂了,即使从节点升级成为主节点,但是刚才的加锁对应的数据,也是不存在的
解决方式
如下图,此处加锁,就是按照一定的顺序,针对这些组redis都进行加锁操作,如果某个节点挂了(某个节点加不上锁,没关系,可能是redis挂了),就继续给下一个节点加锁即可,如果写入key成功的节点个数超过总数的一半,就认为是加锁成功,同理,进行解锁时,也会把上述节点都设置一遍解锁