参考资料
- RabbitMQ官方网站
- RabbitMQ官方文档
- 噼咔噼咔-动力节点教程
文章目录
- 一、认识RabbitMQ
- 1.1 消息中间件(MQ = Message Queue 消息队列
- 1.2 主流的消息中间件
- 1.3 MQ的应用场景
- 1.3.1 异步处理
- 1.3.2 系统解耦
- 1.3.3 流量削峰
- 1.3.4 日志处理
- 二、RabbitMQ运行环境搭建
- 2.1 了解版本兼容问题
- 2.2 Dokcer安装
- 2.2.1 docker-compose.yml
- 2.2.3 启动
- 2.3 WEB控制台简介
- 2.3.1 页头信息
- 2.4 admin页面
- 2.4.1 用户标签
- 2.4.2 Virtual hosts (虚拟主机
- 三、RabbitMQ工作模型
- 3.1 快速理解工作流程
- 3.2 快速理解消息中间件 broker 的构成
- 3.3 消息队列的核心三要素
- 3.3.1 生产者 producer
- 3.3.2 消费者 consumer
- 3.3.3 代理 broker
- 3.4 RabbitMQ的基础概念名词
- 3.4.1 连接(Connection )
- 3.4.2 信道(Channel)
- 3.4.3 虚拟主机( Virtual host )
- 3.4.4 交换机( Exchange)
- 3.4.5 路由键( Routing Key )
- 3.4.6 绑定( Binding )
- 3.4.7 队列 ( Queue )
- 3.4.8 消息(Message )
一、认识RabbitMQ
1.1 消息中间件(MQ = Message Queue 消息队列
简单来说,消息中间件就是指保存数据的一个容器(服务器),可以用于两个系统之间的数据传递。
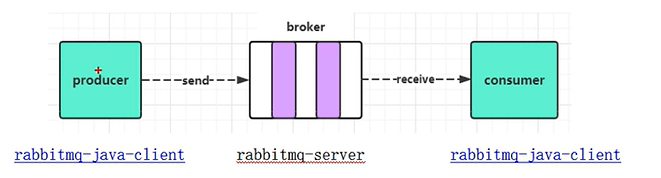
消息中间件一般有三个主要对象:
- 生产者:producer
- 消费者:consumer
- 消息代理(也叫消息队列、消息服务器):broker
生产者发送信息到消息服务器,然后消费者会从消息代理中获取数据并进行处理。关系图如下。
其中,broker作为独立的中间件,是不需要我们手动编写的。
1.2 主流的消息中间件
- RabbitMQ
- kafka(
丝线交织 - RocketMQ(java,阿里开源,实战丰富
- pulsar(最新流行
1.3 MQ的应用场景
1.3.1 异步处理
在企业级java开发中,有很多需要异步线程处理的场景,这些场景如果比较简单且低负载,我们使用多线程,配合线程池即可很好是胜任。
但是如果出现大流量、高并发的数据传递时,使用消息中间件就很有必要了。
比如动力节点提到的这个场景:
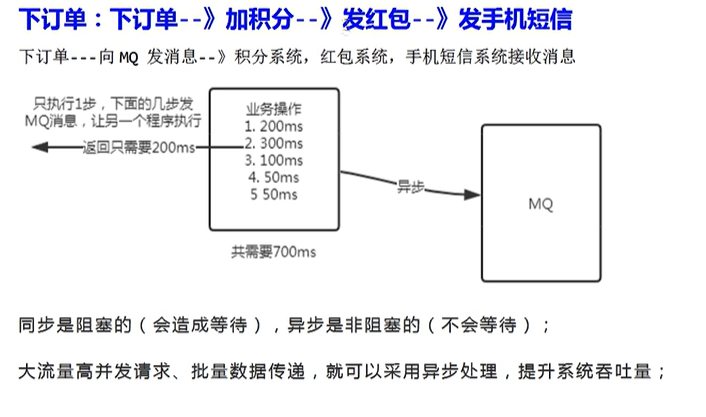
- 按照普通的同步流程,这一系列操作会造成系统的阻塞,用户点击下订单后需要等待全部流程结束
- 而使用MQ,就可以实现异步处理,生产者只需要处理下订单即可,剩下的交给MQ来管理。
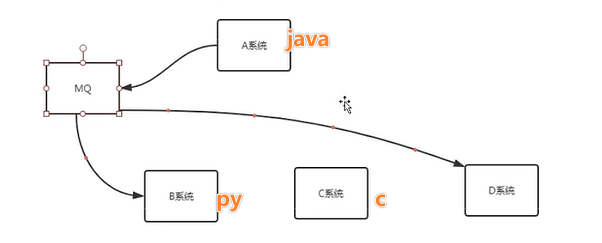
1.3.2 系统解耦
MQ可以作为字面意义的消息中间件,负责调度不同系统之间的交互请求,通过消息进行业务流转(而不是不同的系统之间直接调用)。
- 起到了类似中转调度中心的作用。
- 甚至不同的系统也可以使用不同的语言进行开发
1.3.3 流量削峰
用于QPS极高的情况,比如双十一订单量暴增的时候,如果直接将用户的请求打到数据库,则会造成极大的数据库压力。
使用MQ匀速消费可以将QPS降低到一个系统可接受的水平,保证系统的稳定运行。

1.3.4 日志处理
主要是kafka这个服务器来做。
如果系统采用微服务处理,(比如有1000个微服务)每个单独的服务都会有大量的日志,如果要定位异常就需要每台服务器都要翻找日志,kafka解决了大量日志传输的问题,给出了ELK日志解决方案:

将所有的日志通过kafka集中到一个地方进行查看。
拓展阅读: ELK日志分析系统
由以下三个中间件组成
- Elasticsearch
- Logstash
- Kibana
具体详解:
https://blog.csdn.net/weixin_49022211/article/details/109514485
https://blog.csdn.net/zkc7441976/article/details/115868050
二、RabbitMQ运行环境搭建
为了快速学习,使用docker快速部署
2.1 了解版本兼容问题
https://www.rabbitmq.com/which-erlang.html
2.2 Dokcer安装
参考原文链接:https://blog.csdn.net/qq_39340792/article/details/117715984
2.2.1 docker-compose.yml
version: '3.1'
services:rabbitmq:restart: alwaysimage: rabbitmq:managementcontainer_name: rabbitmqhostname: rabbitports:- 5672:5672- 15672:15672environment:TZ: Asia/ShanghaiRABBITMQ_DEFAULT_USER: rabbitRABBITMQ_DEFAULT_PASS: 123456volumes:- ./data:/var/lib/rabbitmq- ./conf:/etc/rabbitmq注意:./conf目录即配置挂载目录需事先创建好,如果未事先创建或是空文件夹启动时会报错。
可以先不挂载该目录启动,然后 通过 docker cp 命令将配置目录拷贝出来。
示例:
docker cp rabbitmq:/etc/rabbitmq ./conf
2.2.3 启动
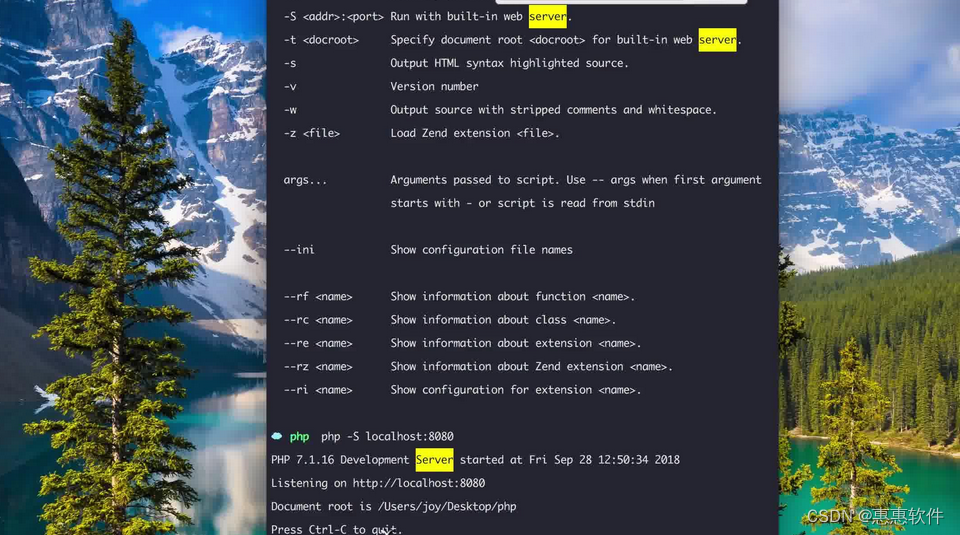
执行 docker-compose up -d命令启动。
浏览器访问 http://localhost:15672/ 进入RabbitMQ Management 页面。输入上面的用户名和密码登录。
页面如下
2.3 WEB控制台简介
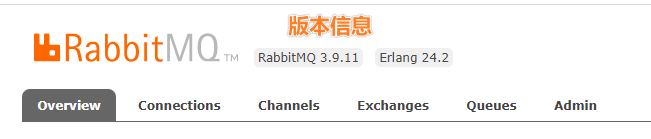
2.3.1 页头信息
标签页分别是
- 概述 overview
- 连接 connections
- 信道 channels
- 交换机 exchanges
- 队列 queues
- 系统配置 admin

2.4 admin页面
2.4.1 用户标签
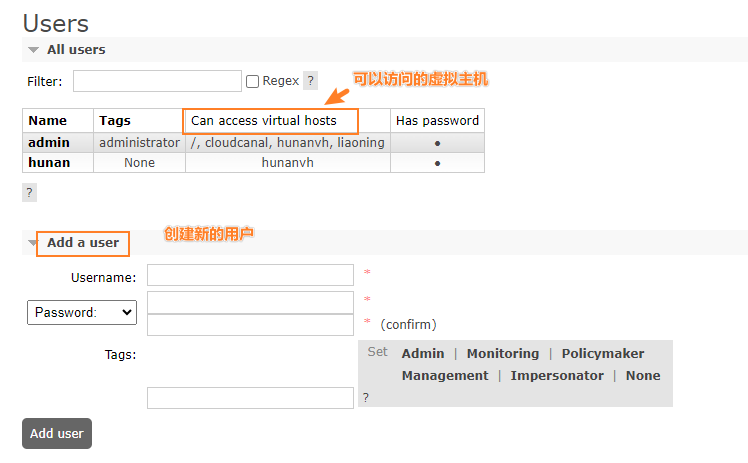
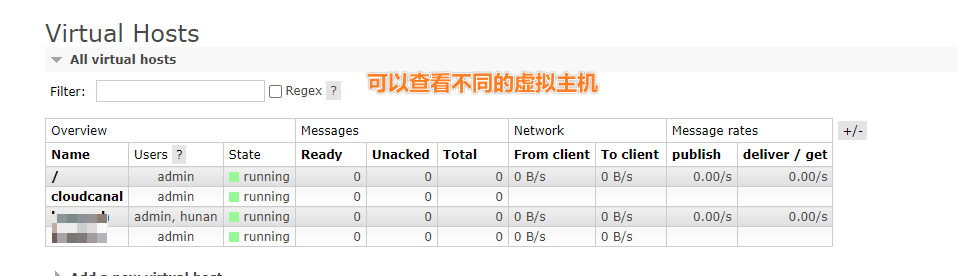
2.4.2 Virtual hosts (虚拟主机
三、RabbitMQ工作模型
作为rabbitMQ的核心重点,理解工作模型有助于快速上手

3.1 快速理解工作流程
大致的工作流程前面已经提到了——
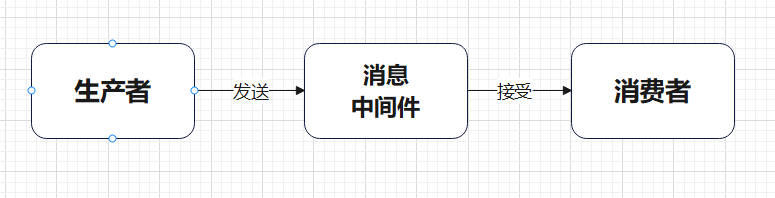
那么在上图中可以发现生产者是如何具体将消息传达到消费者中的。大致流程简单描述如下
- 首先,生产者通过虚拟信道和虚拟主机中的交换机建立连接
- 同时,消费者也通过虚拟信道和虚拟主机件的消息队列建立连接
- 生产者的消息,通过交换机传递到消息队列中,消费者从消息队列中接受消息
至此完成的消息的传递
3.2 快速理解消息中间件 broker 的构成
视频给了一个很形象的类比。有助于我们理解mq的基本构成
| rabbitMQ服务器 | Mysql服务器 |
|---|---|
| 一个服务器可以创建多个不同的虚拟主机 | 一个服务器可以创建多个不同的数据库 |
| 一个虚拟机可以有多个不同的消息队列 | 一个数据库可以有多个不同的表格 |
| 队列中可以存储多条消息 | 表格中可以存储多条记录 |
3.3 消息队列的核心三要素
这三要素是所有MQ中间件通用
3.3.1 生产者 producer
发送消息的应用。(可以是java程序,也可以是其他语言的程序
3.3.2 消费者 consumer
接受消息的应用。(可以是java程序,也可以是其他语言的程序
3.3.3 代理 broker
即消息服务器,消息中间件,也叫消息队列。
rabbitMQ server 就是 message broker
3.4 RabbitMQ的基础概念名词
3.4.1 连接(Connection )
连接 RabbitMo 服务器的TCP 长连接
3.4.2 信道(Channel)
连接中的一个虚拟通道,消息队列发送或者接收消息时,都是通过信道进行的;
3.4.3 虚拟主机( Virtual host )
一个虚拟分组,在代码中就是一个字符串。
当多个不同的用户使用同一个RabbitMQ 服务时,可以划分出多个 Virtual host。每个用户在自己的 Virtual host 创建 exchange/queue 等;
(分类比较清晰、相互隔离)
3.4.4 交换机( Exchange)
交换机负责从生产者接收消息,并根据交换机类型分发到对应的消息队列中,起到一个路由的作用
3.4.5 路由键( Routing Key )
交换机根据路由键来决定消息分发到哪个队列,路由键是消息的目的地址
也就是说其实在每一个channel中都有一个路由key,通过这个key就可以快速定位到具体的队列。避免了消息乱发队列的情况。
3.4.6 绑定( Binding )
绑定是队列和交换机的一个关联连接(关联关系)
3.4.7 队列 ( Queue )
存储消息的缓存队列
3.4.8 消息(Message )
由生产者通过 Rabbitmq 发送给消费者的信息; (消息可以任何数据字符串、user 对象,json 串等等)