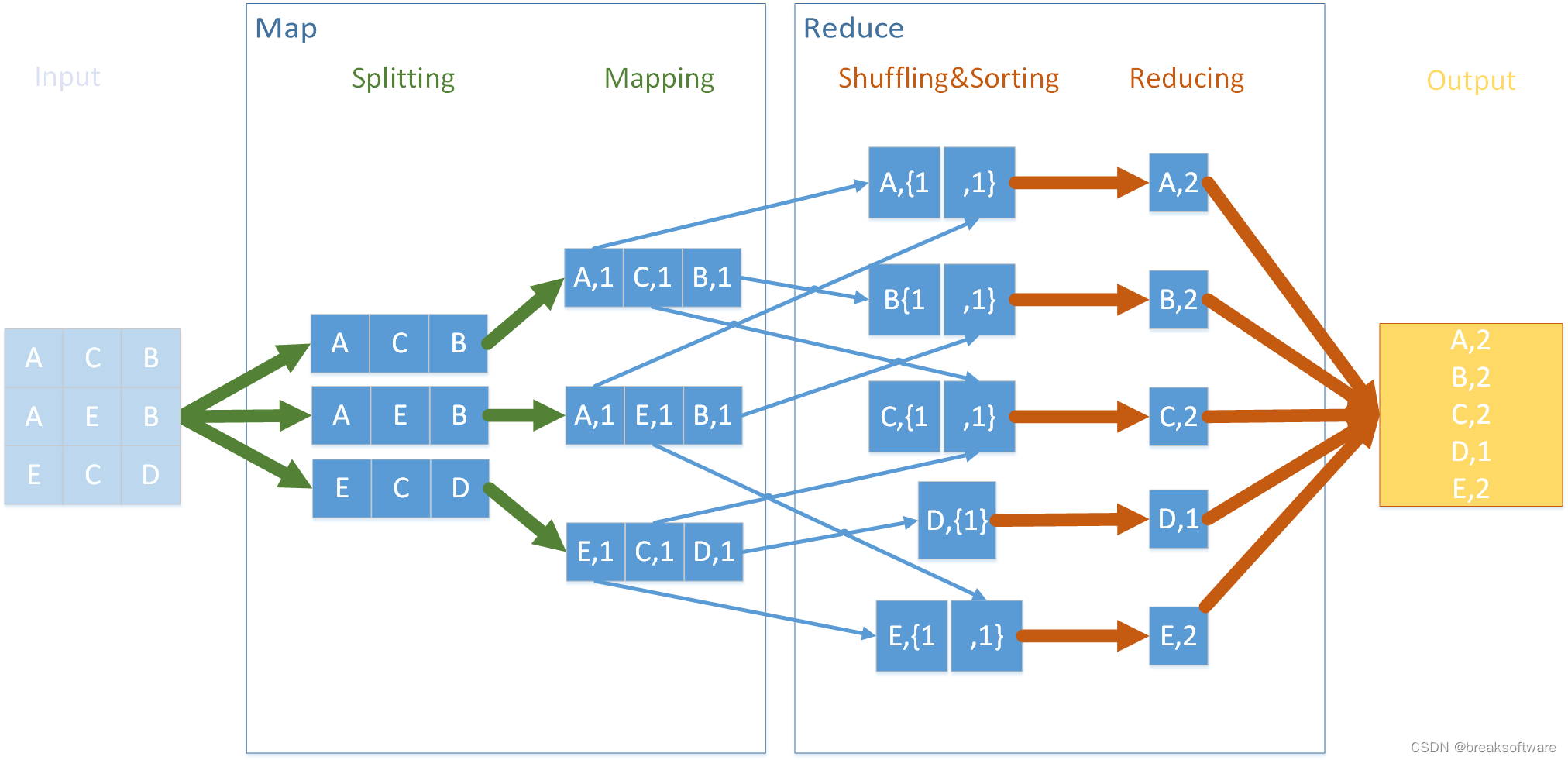
学习搭建Hadoop集群(完全分布式模式)
链接:https://pan.baidu.com/s/1wwTKk-XxHbccHjE-Xk2PTA
提取码:q7j7
在SecurityCRT 或者在 Xshell 进行虚拟机链接
(这里使用Xshell )

在hadoop001里配置
如果没有 /opt目录下创建software、module就先创建
(software 用于存储软件安装包,module 用于存放安装包解压后的文件)
mkdir +路径/文件名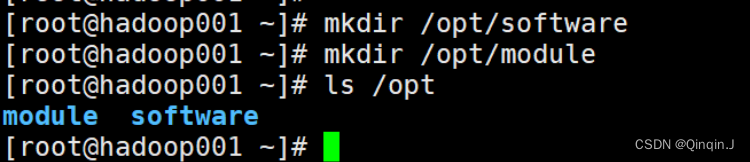
打开目录 /opt/software
上传压缩包(网盘里有压缩包)
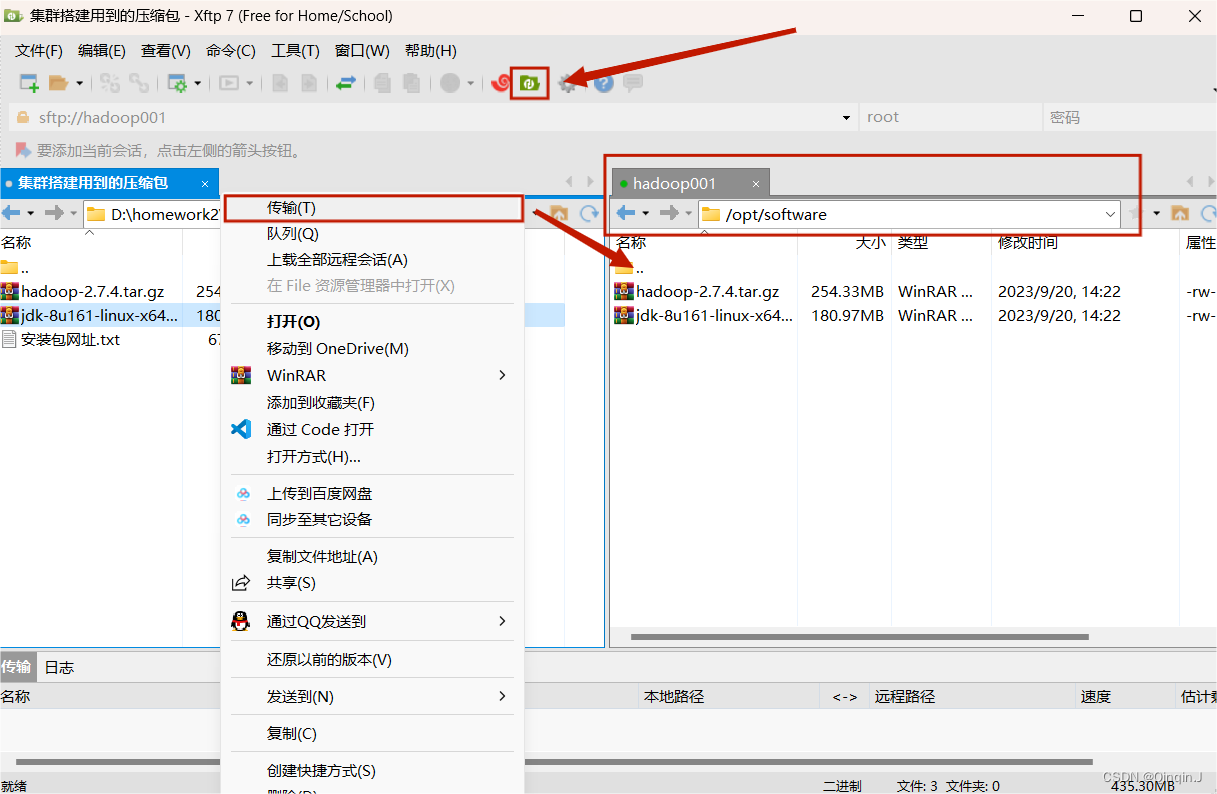
一、安装 jdk
先进入,命令:cd /opt/software
cd /opt/software命令:tar -zxvf jdk-8u161-linux-x64.tar.gz -C /opt/module/
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /opt/module/查看:ls /opt/module/
ls /opt/module/

查看路径(克隆新会话)
进入:cd /opt/module/jdk1.8.0_161/
cd /opt/module/jdk1.8.0_161/输入:pwd

配置path
命令:vi /etc/profile
vi /etc/profile
添加下面内容,保存退出(最好不复制输入)
export JAVA_HOME=/opt/module/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME=/opt/module/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin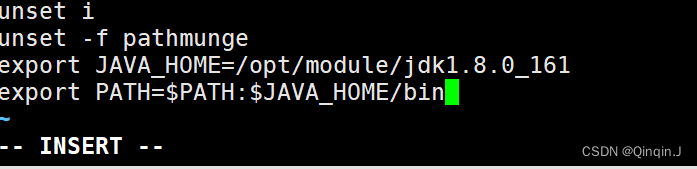
执行配置文件生效:source /etc/profile
查看:java -version
source /etc/profilejava -version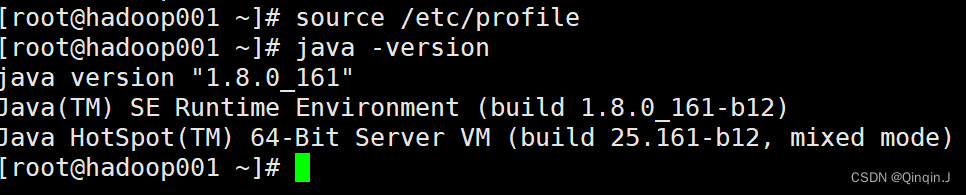
注意:(hadoop出现这种情况也可以这样的方法解决)
如果配置文件生效不了可以输入命令:reboot -n 客户机重启 ,然后重新编辑:vi /etc/profile 添加以下内容:(最好不复制输入)
export JAVA_HOME=/opt/module/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin保存退出,执行配置文件生效:source /etc/profile ,查看:java -version
source /etc/profile
java -version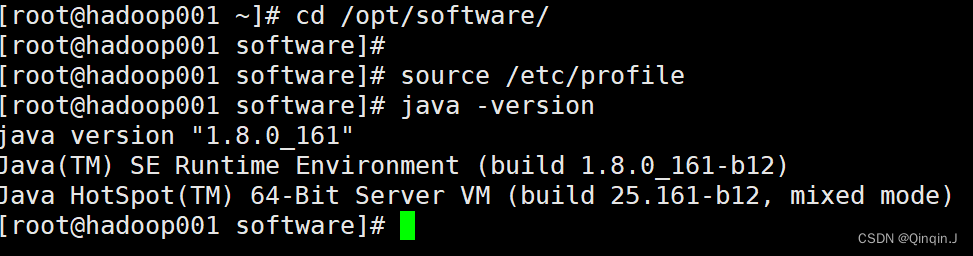
如果很着急使用可以直接在命令行输入以下内容:(最好不复制输入)
export JAVA_HOME=/opt/module/jdk1.8.0_161export PATH=$PATH:$JAVA_HOME/bin然后输入 java -version 查看
java -version二、安装 Hadoop
先进入,命令:cd /opt/software
cd /opt/software命令:tar -zxvf hadoop-2.7.4.tar.gz -C /opt/module/
tar -zxvf hadoop-2.7.4.tar.gz -C /opt/module/查看:ls /opt/module
ls /opt/module

查看路径(克隆新会话)
进入:cd /opt/module/ hadoop-2.7.4/
cd /opt/module/ hadoop-2.7.4/输入:pwd

配置path
命令:vi /etc/profile
vi /etc/profile
添加下面内容,保存退出(最好不复制输入)
export HADOOP_HOME=/opt/module/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME=/opt/module/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin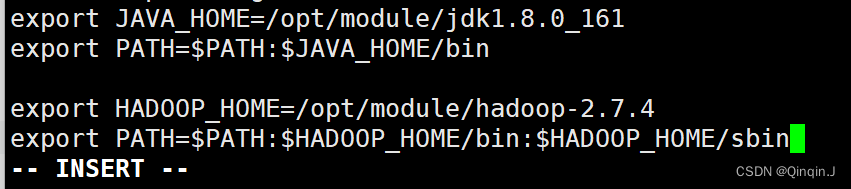
执行配置文件生效:source /etc/profile
查看:hadoop version
source /etc/profilehadoop version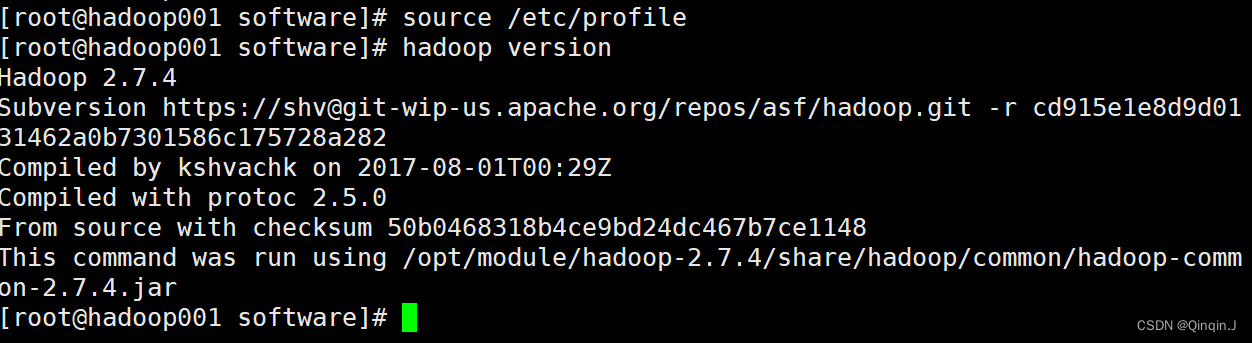
进入hadoop查看目录结构
进入hadoop命令:cd /opt/module/hadoop-2.7.4
cd /opt/module/hadoop-2.7.4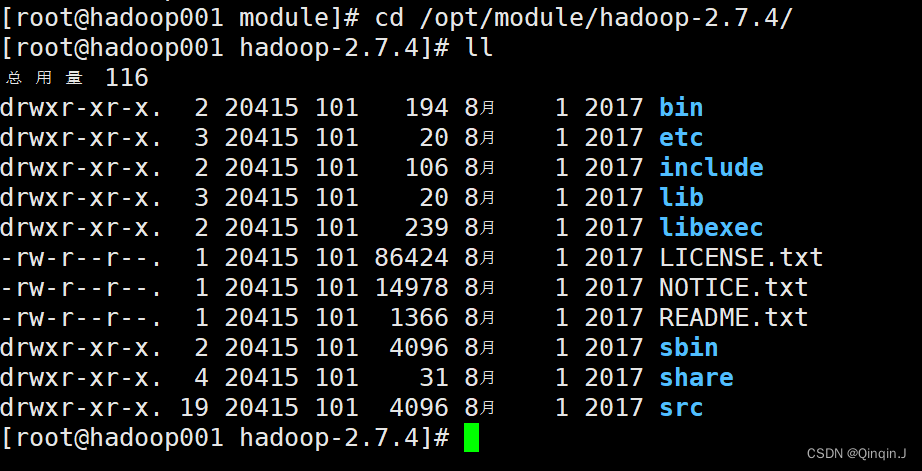
三、Hadoop 集群配置
可以只使用一台虚拟机(这里使用hadoop001)hadoop002和hadoop003保持连接状态
1、配置 Hadoop 集群主节点
进入 hadoop安装位置
cd $HADOOP_HOME进入hadoop
cd etc/hadoop
(1)修改 hadoop-env.sh 文件
vim hadoop-env.sh或者(vi vim 都可以)
vi hadoop-env.sh ![]()
修改export JAVA_HOME=路径
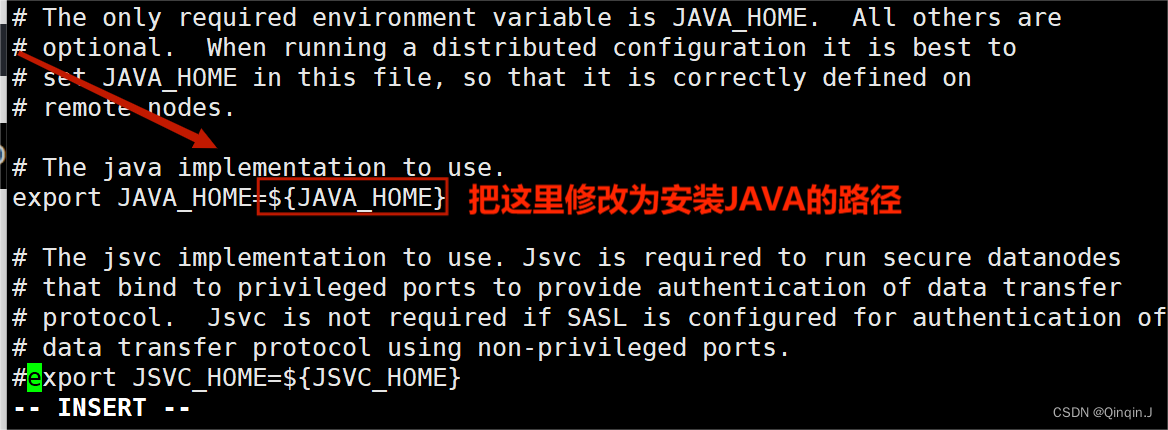
查路径,先克隆新会话
echo $JAVA_HOME
然后修改 hadoop-env.sh 文件,保存退出

(2)修改 core-site.xml 文件
vim core-site.xml该文件是Hadoop的核心配置文件,其目的是配置 HDFS 地址、端口号,以及临时文件目录。配置文件中配置了 HDFS 的主进程NameNode运行主机(也就是此次Hadoop集群的主节点位置)同时配置了Hadoop运行时生成数据的临时文件。
添加以下内容
<property><!--用于设置Hadoop的文件系统,由URL指定--><name>fs.defaultFS</name><!--用于指定namenode地址在hadoop001机器上--><value>hdfs://hadoop001:9000</value>
</property>
<!--配置Hadoop的临时目录,默认/tmp/hadoop-${user.name}-->
<property><name>hadoop.tmp.dir</name><!--Hadoop安装路径--><value>/opt/module/hadoop-2.7.4/data</value>
</property>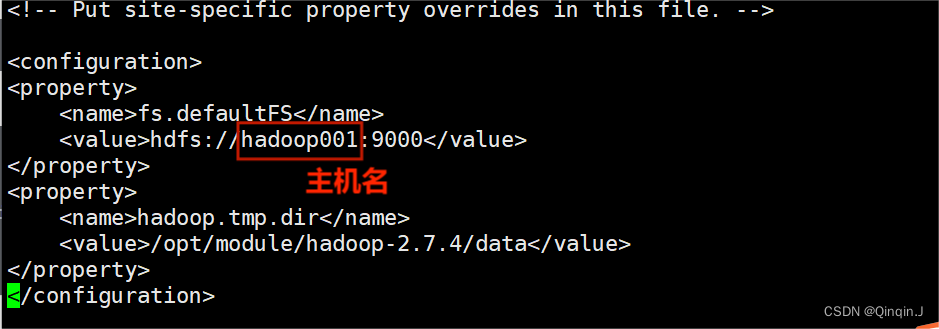
(3)修改 hdfs-site.xml 文件
vi hdfs-site.xml该文件作用于设置 HDFS 的NameNode 和 DataNode 两大进程。
添加以下内容
<property><!--指定 HDFS 副本的数量--><name>dfs.replication</name><value>3</value>
</property>
<!--secondary namenode 所在主机的IP和端口-->
<property><name>dfs.namenode.secondary.http-address</name><value>hadoop02:50090</value>
</property>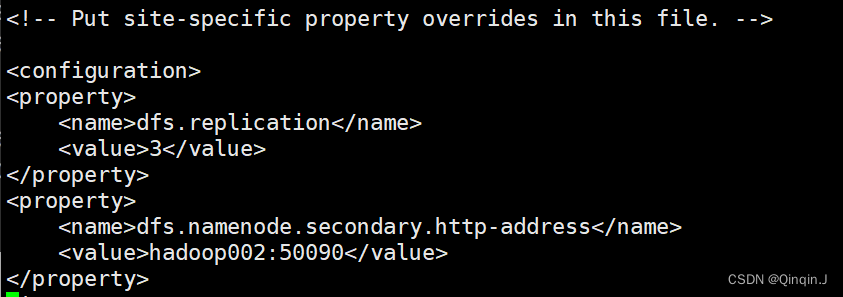
(4)修改 mapred-site.xml 文件
如果vi出了新文件,要重命名文件夹名:
cp -R mapred-site.xml.template mapred-site.xmlvi mapred-site.xml
该文件时 MapReduce 的核心配置文件,用于指定 MapReduce 运行时框架
添加以下内容
<!--指定 MapReduce 运行时框架,这里指定在 YARN上,默认是 local-->
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>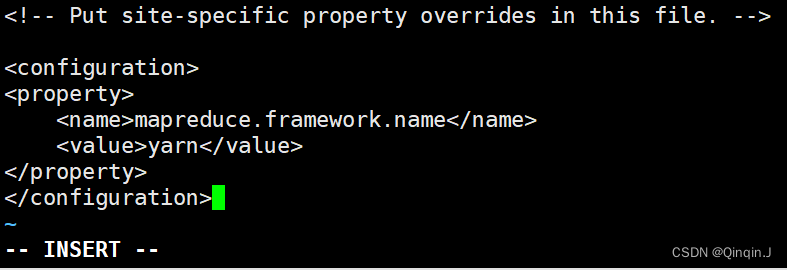
(5)修改 yarn-site.xml 文件
vi yarn-site.xml本文件是 YARN 框架的核心配置文件,需要指定 YARN 集群的管理者。 在配置文件中配置 YARN 的主进程 ResourceManager 运行主机为hadoop001,同时配置了 NodeManager 运行时的附属服务,需要配置为 mapreduce_shuffle 才能正常运行 MapReduce 默认程序。
添加以下内容
<property><!--指定 YARN集群的管理者(ResourceManager)的地址--><name>yarn.resourcemanager.hostname</name><!-- 主机名--><value>hadoop001</value>
</property>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>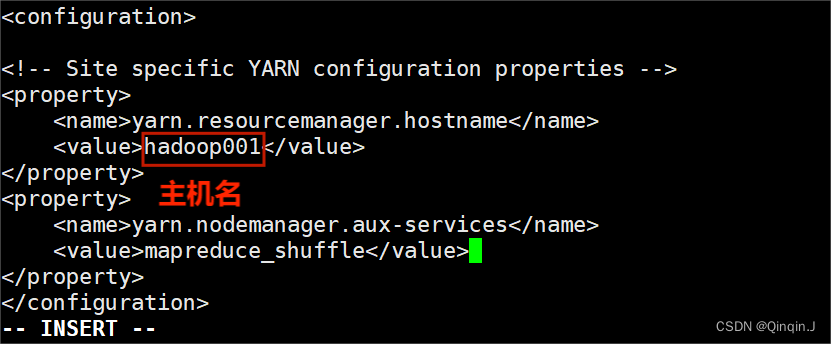
(6)修改 slaves 文件
该文件用于记录 Hadoop 集群所有从节点(HDFS 的 DataNode 和 YARN 的 NodeManager 所在主机)的主机名,用来配合一键启动集群从节点(并且还需要验证关联节点配置了 SSH 免密登录)。打开该配置,先文件删除里面的内容
vi slaves
配置如下
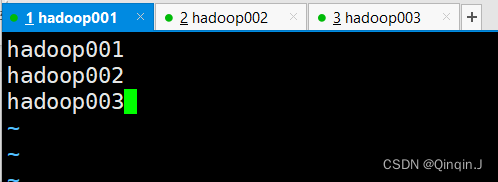
配置文件配置了 Hadoop集群所有从节点的主机名为 hadoop001、hadoop002 和 hadoop003(这是因为此次在该3台机器上搭建 Hadoop 集群,同时前面的配置文件 hdfs-site.xml 指定了 HDFS 服务副本数量为3 )。
2、将集群主节点的配置文件分发到其他子节点
完成 Hadoop 集群主节点 hadoop001 的配置后,还需要将系统环境配置文件、JDK安装目录和 Hadoop安装目录分发到其他子节点 hadoop002 和 hadoop003上。
scp /etc/profile hadoop002:/etc/profile
scp /etc/profile hadoop003:/etc/profile这个为安装hadoop的路径 /opt/module/
scp -r /opt/module/ hadoop002:/opt/
scp -r /opt/module/ hadoop003:/opt/
![]()
![]()
一堆码一直在刷就成功了,不用把他停住,给他自己停
执行完上述所有指定后,还需要在其他子节点 hadoop002、hadoop003 上分别执行
source /etc/profile立即刷新配置文件。
四、Hadoop 集群测试
格式化文件系统
通过 Hadoop 集群的安装和配置。此时还不能直接启动集群,因为在初次启动 HDFS 集群时,必须对主节点进行格式化处理
hdfs namenode -format或者
hadoop namenode -format执行上述任意一条都可以对 Hadoop 集群进行格式化。执行命令后,必须出现有 successfully formatted 信息才表示格式化成功
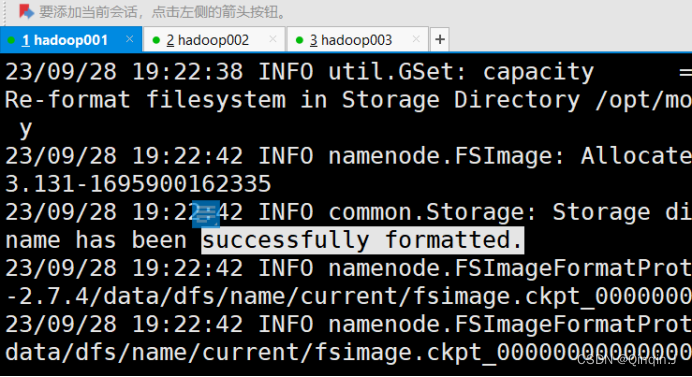
如果没有出现请检查一下Hadoop 安装和配置文件是否正确 ,如果都正确,则需要删除所有主机的 /hadoop-2.7.4 目录下的 tmp文件夹,重新执行格式化命令,对 Hadoop 集群进行格式化。
注意:格式化只能进行一次,如果多此进行可能会导致服务器运行的java进程不完全
五、启动集群服务
1、在主节点hadoop001上使用以下指令启动所有 HDFS 服务进程
start-dfs.sh2、在主节点hadoop001上使用以下指令启动所有 YARN 服务进程
start-yarn.sh或者在主节点 hadoop001上执行以下命令,直接启动整个 Hadoop 集群服务
start-all.sh3、查看 Hadoop 集群服务是否启动成功
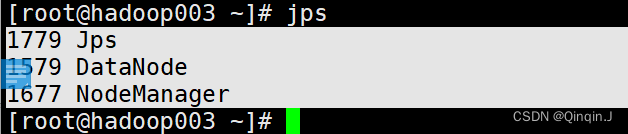
在各自机器上使用 jps 指令查看各节点的服务进程启动情况
hadoop001

hadoop002

hadoop003
六、通过 UI 查看 Hadoop 运行状态
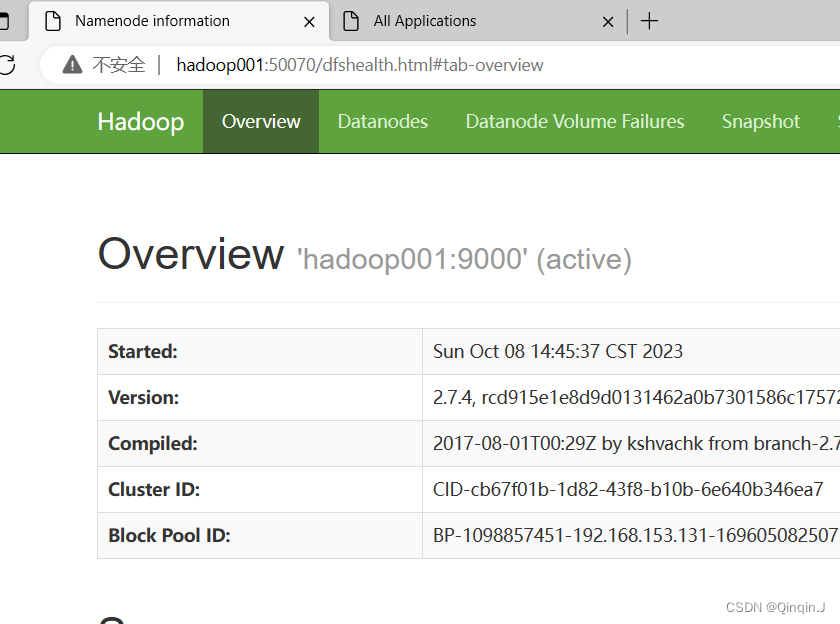
(1)查看HDFS 集群状态
通过浏览器分别访问http://hadoop001:50070(集群服务IP+端口号),查看HDFS 集群状态
(2)查看YARN 集群状态
通过浏览器分别访问http://hadoop001:8088 ,查看YARN 集群状态
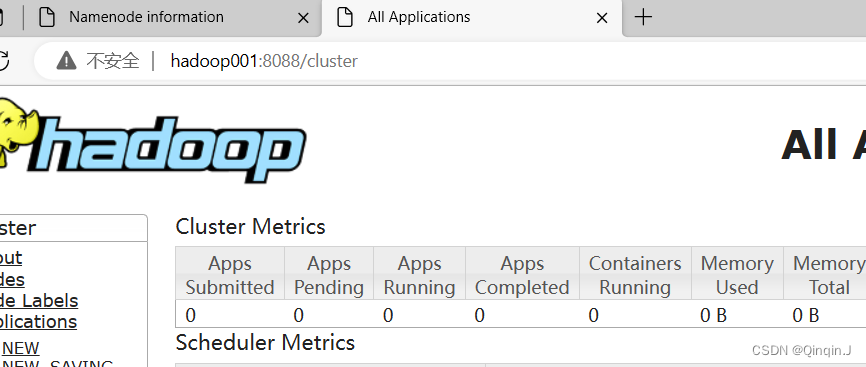
Hadoop默认开设HDFS端口号为9000,监控HDFS集群端口号为50070,监控YARN集群端口号为8088。
七、Hadoop集群初体验
进入HDFS 集群状态
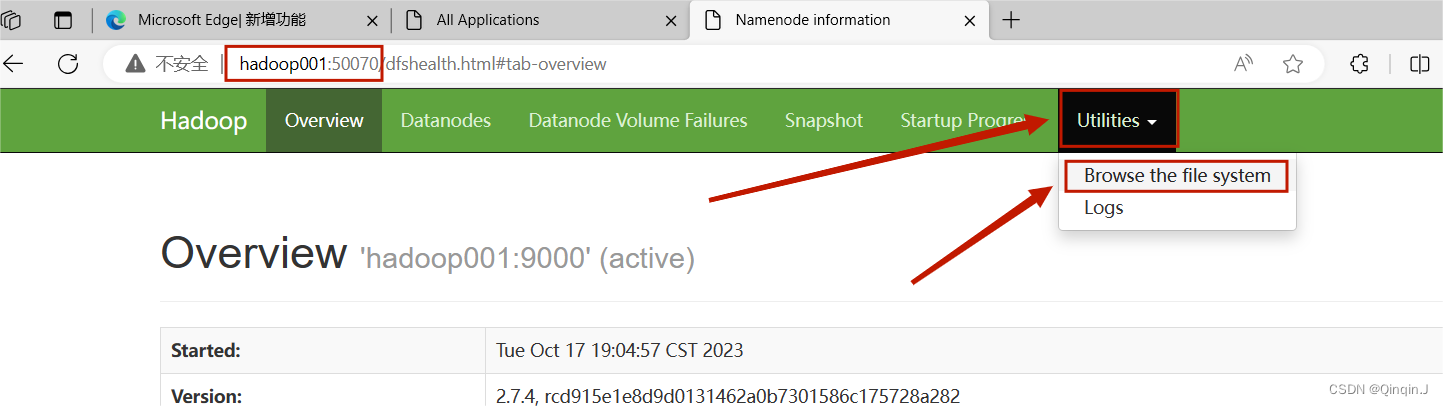
进入这里后
在主节点hadoop001上执行以下命令
创建/export/data,并进入
mkdir -p /export/data
cd /export/data
新建一个word.txt文件,并且编辑以下内容
vi word.txt添加以下内容(可随意添加)
hello itcast
hello itheima
hello hadoop 
查看word.txt文件内容:
cat word.txt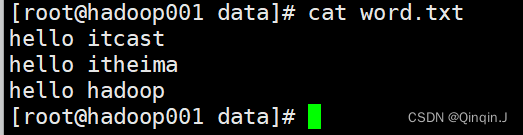
在HDFS上创建 /wordcount/input 目录,并将 word.txt 文件上传至该目录下
hadoop fs -mkdir -p /wordcount/input
hadoop fs -put word.txt /wordcount/input
刷新一下HDFS集群状态
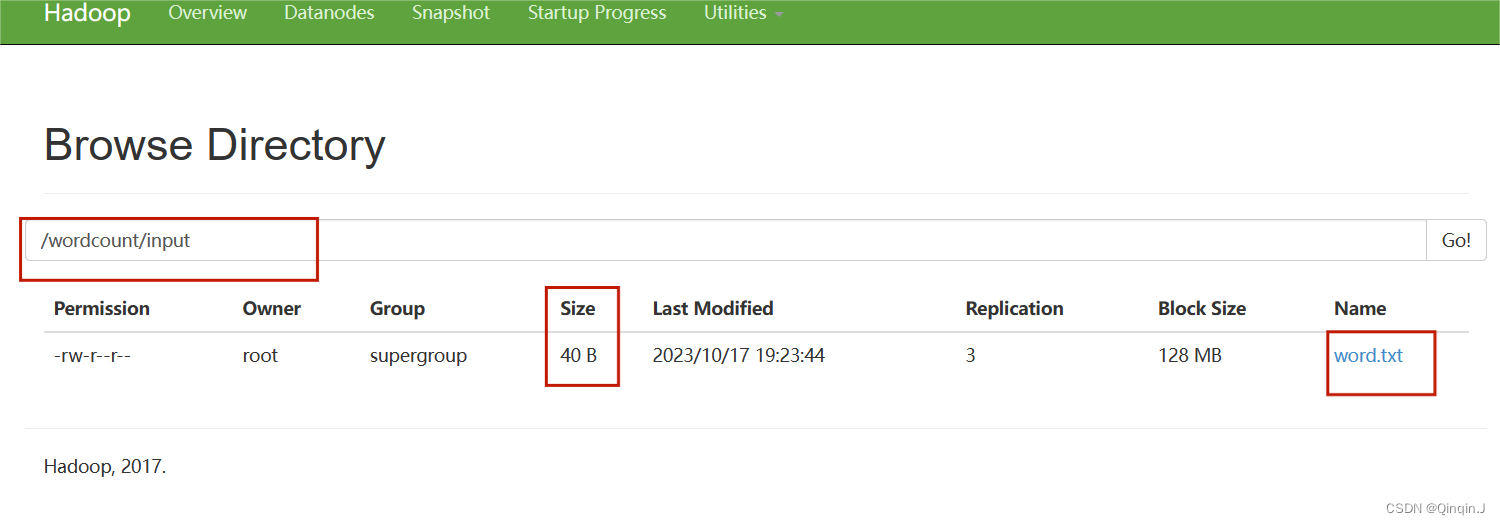
进入 /share/hadoop/mapreduce目录下,使用 ll 指令查看文件夹内容
cd $HADOOP_HOME/share/hadoop/mapreduce 
图中这个 jar包中包含了计算机单词个数、计算Pi值等功能。可以用来对HDFS的 word.txt文件进行单词统计,通过以下命令执行

hadoop jar hadoop-mapreduce-examples-2.7.4.jar wordcount /wordcount/input /wordcount/output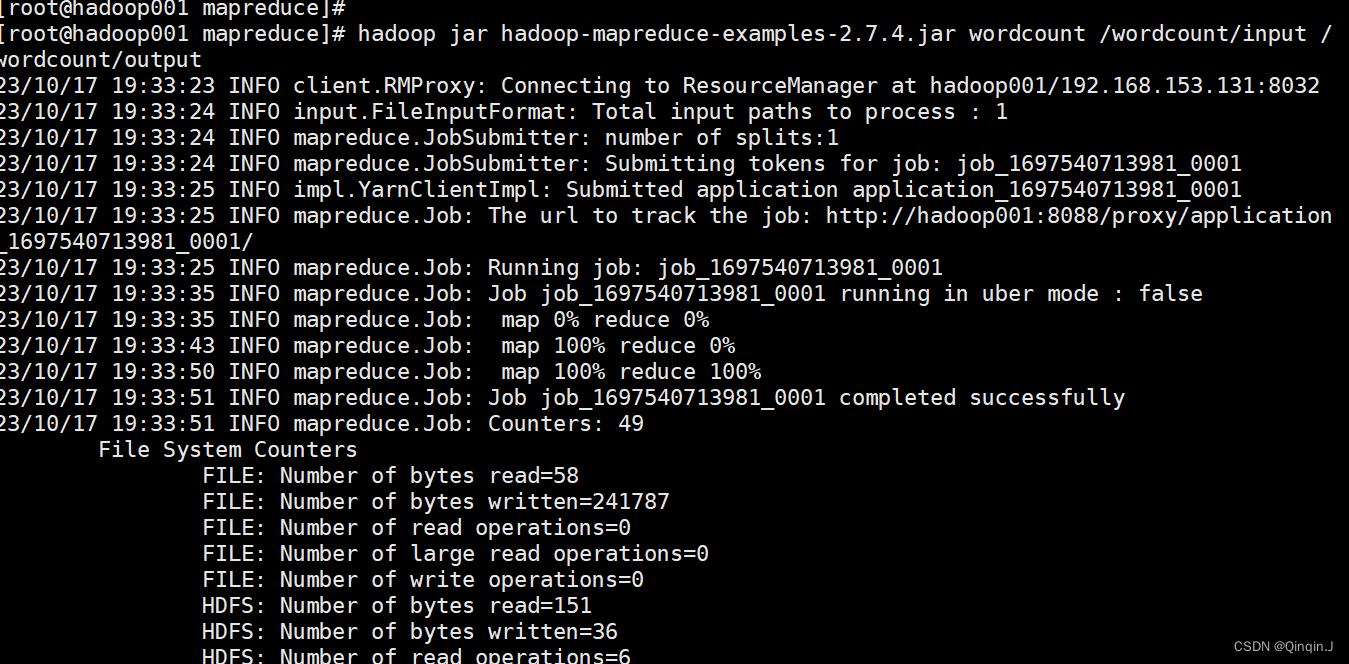
如果要重新执行要在后面添加第几次
例如:hadoop jar hadoop-mapreduce-examples-2.7.4.jar wordcount /wordcount/input /wordcount/output4
刷新YARN 集群状态,如果未出现以下情况,重新查看一下 mapred-site.xml文件是否编写正确
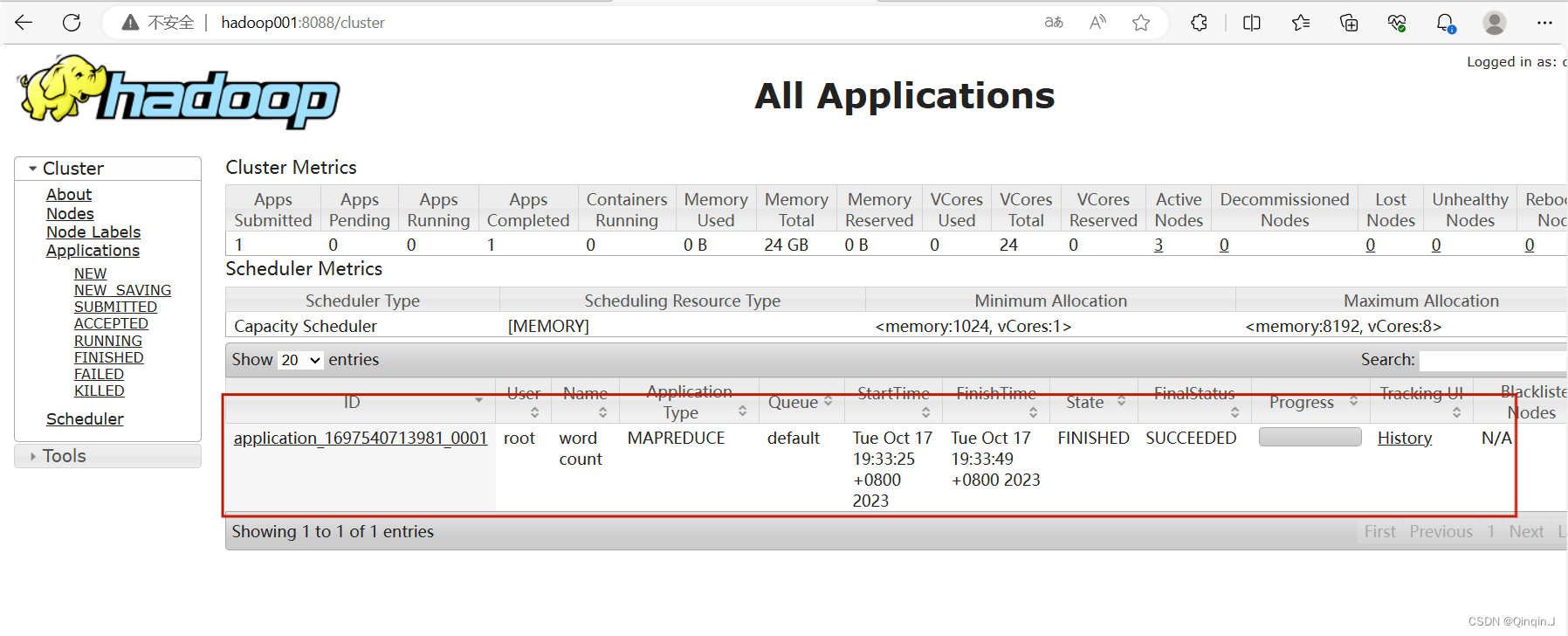
刷新查看HDFS的UI
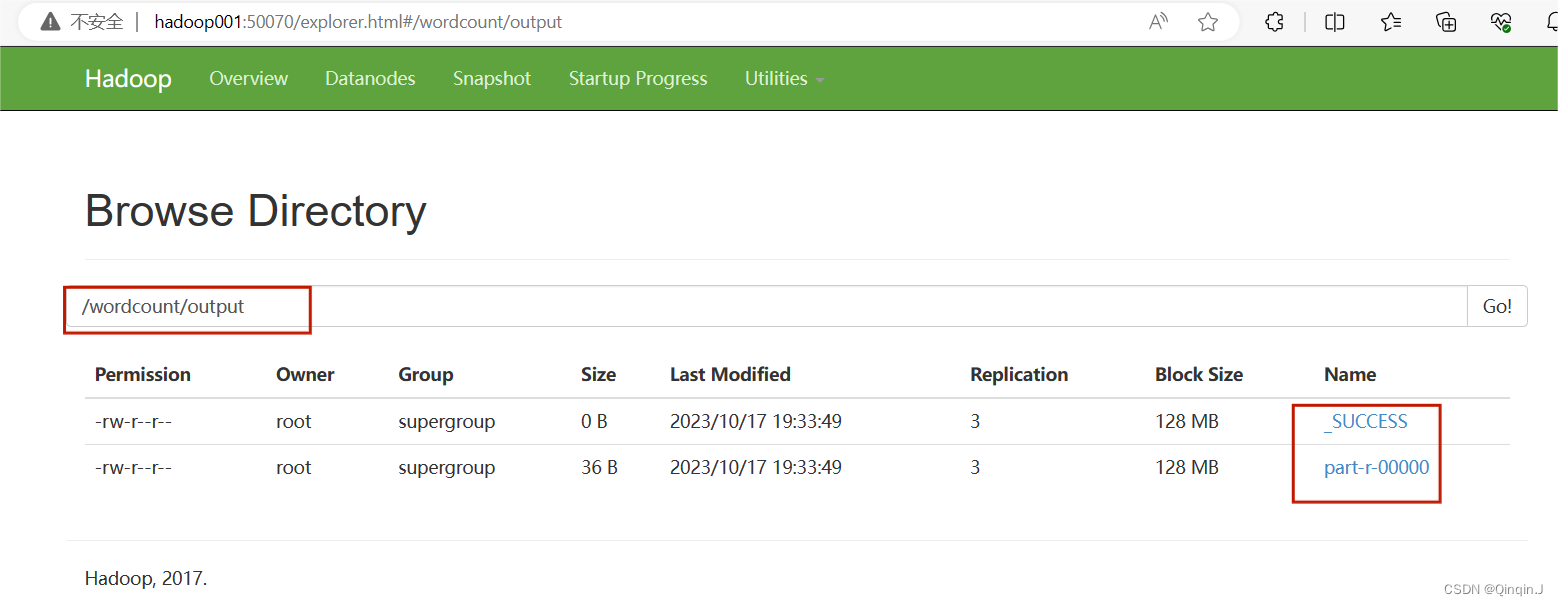
下载part-r-00000文件
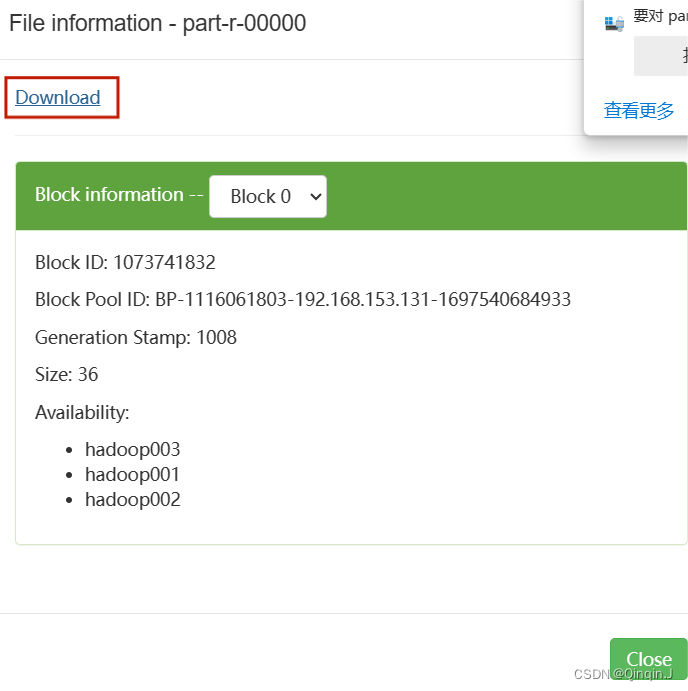
打开查看是否执行成功,由图可知道已执行成功
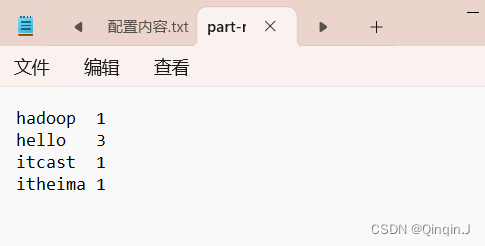
八、解决 jps 查看不了完整的 java 服务器进程
(1)缺少 datanode 进程
原因:多次格式化可能会导致,输入jps出现的java进程服务不完全
当初始化成功的时候,会产生一个集群ID,分布在这三个地方:NameNode、seondary NameNode、DataNode
第二次初始化时,只会更新 NameNode的集群ID
解决:
进入hadoop001、hadoop002和hadoop03将这data个文件删除
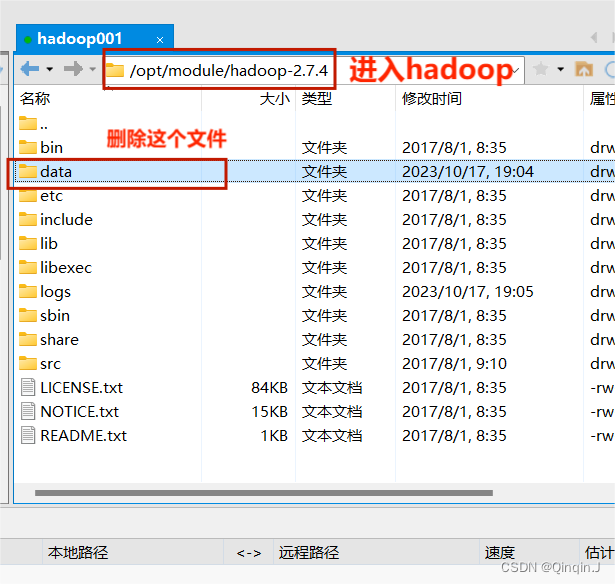
在hadoop001主节点上
先将集群服务关闭 stop-all.sh
stop-all.sh进行格式化:hdfs namenode -format
hdfs namenode -format重启服务 start-all.sh
start-all.sh如果还是不能解决,检查一下配置 hadoop集群主节点的文件是否正确,输入 jps 命令查看
(2)SecondaryNameNode 位置错了,在 001 上启动,在 002 上没有
vi hdfs-site.shscp hdfs-site.xml hadoop002:/opt/module/hadoop-2.7.4/etc/hadoop/
scp hdfs-site.xml hadoop003:/opt/module/hadoop-2.7.4/etc/hadoop/start-all.sh(3)启动报错
(4)所有的进程都正常,但是无法访问网站
systemctl stop firewalld.service
systemctl disable firewalld.service查看防火墙状态
systemctl status firewalld