理解Postgres的IOPS:为什么数据即使都在内存,IOPS也非常重要
磁盘IOPS(每秒输入/输出操作数)是衡量磁盘系统性能的关键指标。代表每秒可以执行的读写操作数量。对于严重依赖于磁盘访问的PG来说,了解和优化磁盘IOPS对实现最佳性能至关重要。本文讨论IOPS相关主题:IOPS是什么、如何影响PG、如何衡量它以及需要如何调优。
1、PG的IOPS是什么
从高层次看,一个IO操作要么是读数据(“Input”)请求,要么是写数据到磁盘的请求(“Output”),通常以每秒操作数来衡量。
你可能看到WOPS(每秒写操作数)或者ROPS(每秒读操作数)。一般来说,当谈论IOPS时,我们指特定磁盘卷上的读和写操作的综合。这是由操作系统处理的低级操作,应用程序(包括PG)不比担心单个操作可以读取或写入多少数据,甚至不比担心涉及哪种磁盘。事实上,就磁盘而言,操作系统本身通常处理一个抽象 - 它看到一个附加的块设备,该块设备处理读取或写入数据的请求,并且不必担心它是如何实现的。
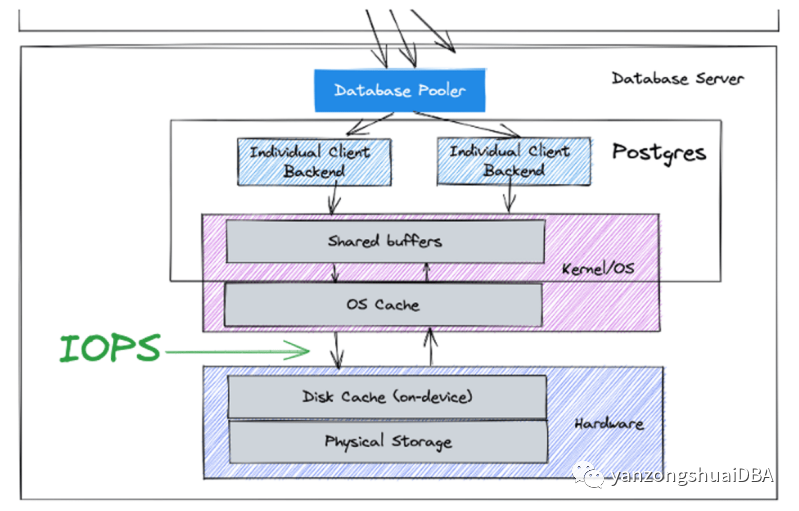
我们数据流介绍:https://www.crunchydata.com/blog/postgres-data-flow 中:数据存储在内存,一些读写请求会达到磁盘。即上图中“Hardware”层,任何数据跨越该层都意味着发生磁盘操作(IOPS)。
当访问数据库时,数据库服务有两种操作选择:
1)返回PG内部cache的数据,即shared_buffers中的数据
2)如果数据不在cache,则需要让操作系统从磁盘读取
当从磁盘读取数据时,操作系统负责处理读取请求并将数据返回给请求进程。所有现代操作系统 - 包括 PostgreSQL 支持的所有操作系统 - 将尝试使用系统内存来缓存磁盘数据,以便从应用程序的角度加速这些请求。这意味着如果您的工作集大于RAM,则磁盘I/O对性能的影响会更大。
2、即使数据在内存,也会使用IOPS
读写磁盘时发生Input和output。如果整个数据都在内存中,还会有IOPS吗?有几个PG操作可能会使用IO,这里列出几点包括:
1)检查点:表文件的脏页需要写到磁盘
2)写WAL日志,以及相关事务控制文件
3)备份
4)读数据到buffer cache中
5)创建或刷新物化视图
6)手动vacuum或者autovacuum:读并且可能修改数据
7)创建索引
8)查询产生临时文件
9)PG15之前版本,数据库统计操作
3、IOPS容量及突发IOPS
磁盘本身将具有 IOPS 容量,这是底层磁盘的一部分。系统可以处理的IOPS数量是有限的,这是操作系统基本配置和硬件限制。
许多基于云的系统允许IOPS爆发,以便可以在一天中某些时间或繁重工作负载时超出基本I/O。通常,突发系统可以让您在一天或一周内累积积分,然后如果您的系统需要超出基本 I/O,您可以使用更多 I/O,直到您完成已建立的突发。
突发I/O允许根据典型使用情况而不是峰值使用情况来配置 IOPS 容量,并且在活动高峰发生时仍然具有突发容量。这可以为您带来更好的价值 - 在某些情况下允许客户每月配置较小的实例并实现成本节省 - 但也有一个显着的缺点。如果您不仔细监控 IOPS 和突发配额使用情况,那么您可能会耗尽突发容量,此时性能将被限制在某个基线。这种情况只会在您已经爆发时发生,因此对性能的影响往往很大,并可能导致中断。
即使您使用不具有突发 IOPS 而是使用提供一致、有保证性能的磁盘,各个云提供商上的某些实例类型也具有其他 I/O 突发功能或缓存,这可能会影响所有磁盘 I/O 的性能。如果使用得当,这些功能可以提供巨大的价值,但同样需要注意 - 了解您的 IOPS 使用情况有哪些限制,并监控您是否正在接近这些限制。
4、IOPS和PG
IOPS可以衡量系统的繁忙程度,但当您接近系统使用限制时,请求可能需要更长时间才能完成,甚至开始排队,这称为 I/O 等待。查询变得更慢,最终用户会遇到延迟。
I/O 限制意味着系统的性能受到 I/O 容量的限制。不同的应用程序工作负载具有不同的查询模式和性能限制,因此您的数据库可能会受到 CPU 限制或内存限制。了解哪些系统资源正在限制性能非常重要,这样当问题始终是磁盘 I/O 性能限制时,您就不会花费时间和金钱升级到具有更多 CPU 或 RAM 的服务器。
5、磁盘IO等待
判断系统是否达到IO瓶颈的一个最佳指标是观察系统的CPU指标中是否出现IO等到。IO等到时间(通常写为iowait)是在有待处理的IO请求时,CPU的空闲时间,即当前运行进程还有可用的CPU容量,但是进程正在等到磁盘请求响应。如果这种情况频繁发生,就意味着磁盘子系统无法跟上请求,因此CPU在本可以工作时却处于空闲状态。
可以使用PG插件pg_proctab从数据库内部访问 /proc 虚拟文件系统下内核公开的各种统计信息。使用pg_cputime()函数可以找到百分之一秒内的IO等待。通常,您可以从服务器上的 shell 运行命令 getconf CLK_TCK 来检查确切的resolution。要获取系统花费在 I/O 等待上的时间百分比的时间点值,您可以运行:
SELECTto_char (iowait / (idle + "user" + system + iowait)::float * 100,'90.99%') AS iowait_pct
FROM
pg_cputime ();这会返回一个百分比数字,如下所示:
iowait_pct
------------
0.07%
(1 row)此处的数字非常小是正常的,除非系统负载很重,正在执行某种 I/O 密集型任务,例如运行备份或导入新数据。如果您经常看到 I/O 等待仅占整个系统时间的个位数百分比,则可能表明您超出了系统的 I/O 容量。
6、track_io_timing和pg_stat_database
track_io_timing 控制服务器是否收集 I/O 性能指标。这个是PG向操作系统发出的请求,和实际磁盘IO略有不同,实际磁盘IO可能发生IO合并。track_io_timing 与 EXPLAIN 命令的 BUFFERS 选项结合使用特别有用,这样您就可以看到执行查询时在磁盘 I/O 上花费了多少时间。这对性能调优很有用。默认情况下会禁用收集,因为某些系统配置对计时调用的开销很高,这意味着收集这些数据可能会对性能产生负面影响。
开启前可以使用pg_test_timing工具来检查下开启后对性能影响,开启后IO数据会写入pg_stat_database和explain plan buffers。
以下是大量IO的示例:
EXPLAIN (ANALYZE, BUFFERS)
SELECTCOUNT(id)
FROM
pages;QUERY PLAN
----------------------------------------------Finalize Aggregate (cost=369672.42..369672.43 rows=1 width=8) (actual time=6041.280..6044.729 rows=1 loops=1)Buffers: shared hit=12855 read=326149 dirtied=580I/O Timings: shared/local read=15953.695-> Gather (cost=369672.21..369672.42 rows=2 width=8) (actual time=6040.119..6044.696 rows=3 loops=1)Workers Planned: 2Workers Launched: 2Buffers: shared hit=12855 read=326149 dirtied=580I/O Timings: shared/local read=15953.695-> Partial Aggregate (cost=368672.21..368672.22 rows=1 width=8) (actual time=6019.362..6019.364 rows=1 loops=3)Buffers: shared hit=12855 read=326149 dirtied=580I/O Timings: shared/local read=15953.695-> Parallel Seq Scan on pages (cost=0.00..362738.57 rows=2373457 width=71) (actual time=2.644..5770.110 rows=1878348 loops=3)Buffers: shared hit=12855 read=326149 dirtied=580I/O Timings: shared/local read=15953.695Planning:Buffers: shared hit=30 dirtied=1Planning Time: 0.216 msJIT:Functions: 11Options: Inlining false, Optimization false, Expressions true, Deforming trueTiming: Generation 1.166 ms, Inlining 0.000 ms, Optimization 0.669 ms, Emission 19.474 ms, Total 21.309 msExecution Time: 6067.862 ms下面是数据从共享缓冲读取的示例:
QUERY PLAN
--------------------------------------------------------------------------------------------Aggregate (cost=746.64..746.65 rows=1 width=8) (actual time=5.224..5.225 rows=1 loops=1)Buffers: shared hit=508-> Seq Scan on nyc_streets (cost=0.00..698.91 rows=19091 width=11) (actual time=0.003..1.428 rows=19091 loops=1)Buffers: shared hit=508Planning:Buffers: shared hit=72Planning Time: 0.238 msExecution Time: 5.308 ms
(8 rows)track_io_timing 还将开始收集多个视图的统计信息,包括 pg_stat_database、pg_stat_all_tables、pg_stat_user_tables。此数据显示块读取(使用的 I/O)和块命中(数据已位于共享缓冲区中)。数据持续更新,通常会找与块命中相比读取块非常高的用户表。
SELECT*
FROM
pg_statio_user_tables;
relid | schemaname | relname | heap_blks_read | heap_blks_hit | idx_blks_read | idx_blks_hit | toast_blks_read | toast_blks_hit | tidx_blks_read | tidx_blks_hit
--------+--------------------+----------------------------------------------------------+----------------+---------------+---------------+--------------+-----------------+----------------+----------------+---------------16716 | segment_production | tracks | 50209 | 5295312 | 1380 | 67935 | 4 | 313 | 5 | 31916836 | segment_production | access_token_created | 25354 | 489153 | 66 | 31543 | 0 | 0 | 0 | 016590 | production | access_token_created | 2765 | 63595 | 2 | 318 | 0 | 0 | 0 | 016626 | production | api_key_created | 4 | 136 | 2 | 318 | 0 | 0 | 0 | 0将这些统计信息转换为字节而不是使用块单位会很有帮助,特别是当统计信息进入全堆栈分析工具时。虽然有适用于某些统计数据的可变块大小设置,但大多数 PostgreSQL 的缓冲区高速缓存个数(包括EXPLAIN BUFFERS)将基于数据库的固定页面大小 8192。
7、PG16中的pg_stat_io
包含一个名为pg_stat_io的新系统视图 ,它提供磁盘 I/O 的每个集群视图。与大多数系统视图一样,这些统计数据是累积的,记录自上次在此服务器上重置统计数据以来的所有 I/O 活动。这看起来像:
SELECT*
FROMpg_stat_io
WHEREreads > 0
OR writes > 0;backend_type | object | context | reads | read_time | writes | write_time | writebacks | writeback_time | extends | extend_time | op_bytes | hits | evictions | reuses | fsyncs | fsync_time | stats_reset
--------------------+----------+----------+-------+-----------+--------+------------+------------+----------------+---------+-------------+----------+-------+-----------+--------+--------+------------+-------------------------------autovacuum worker | relation | normal | 29 | 0 | 0 | 0 | 0 | 0 | 14 | 0 | 8192 | 10468 | 0 | | 0 | 0 | 2023-09-06 14:32:36.930008-05autovacuum worker | relation | vacuum | 13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8192 | 379 | 0 | 0 | | | 2023-09-06 14:32:36.930008-05client backend | relation | bulkread | 926 | 0 | 0 | 0 | 0 | 0 | | | 8192 | 14 | 0 | 137 | | | 2023-09-06 14:32:36.930008-05client backend | relation | normal | 105 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 8192 | 7110 | 0 | | 0 | 0 | 2023-09-06 14:32:36.930008-05checkpointer | relation | normal | | | 1031 | 0 | 0 | 0 | | | 8192 | | | | 320 | 0 | 2023-09-06 14:32:36.930008-05standalone backend | relation | normal | 535 | 0 | 1019 | 0 | 0 | 0 | 673 | 0 | 8192 | 88526 | 0 | | 0 | 0 | 2023-09-06 14:32:36.930008-05standalone backend | relation | vacuum | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8192 | 918 | 0 | 0 | | | 2023-09-06 14:32:36.930008-05请注意reads,虽然此视图中的和列中的数字writes确实对应于 PostgreSQL 发出的各个 I/O 操作,但如果您有单独的指标,这些数字可能与存储系统记录的值不匹配。操作系统甚至存储层可能会合并或拆分I/O请求,因此实际记录的数量可能会有所不同,具体取决于您查看的位置。因此,在调整或查看活动随时间的变化时,比较来自同一来源的数字非常重要。
pg_stat_io 表的另一个非常酷的事情是它将显示活动的“上下文”。因此 pg_stat_io 会将 I/O 使用情况分解为批量读取、批量写入、vacuum或正常工作活动等类别。如果您试图找出 I/O 峰值来自何处(例如大量读取,甚至可能是真空进程),这尤其有用。
pg_stat_io 还为自动启动者构建内部 I/O 跟踪并将其随着时间的推移存储在您自己的数据库中敞开了大门。
要重置所有服务器统计信息,请运行:SELECT pg_stat_reset();
pg_stat_statements 模块重置,运行:SELECT pg_stat_statements_reset;
原文
https://www.crunchydata.com/blog/understanding-postgres-iops