目录
目录
一、初步认识IP协议
二、认识IP地址
三、协议报头格式
1.报头和有效载荷分离
2.20字节的固定数据
四、网段划分
1.一个小例子
2.认识IP地址的划分
3.数据的传输过程
4.特殊的IP地址
5.通信运营商
(1)通信运营商的作用
(2)DHCP技术
五、IP地址分类
1.早期分类模式
2.CIDR
3.IP地址数量不足的现状
六、内外IP和公网IP地址
1.内网和外网IP的规定
2.WAN口IP和LAN口IP
3.公网与私网IP的特征
4.NAT技术
七、路由
一、初步认识IP协议
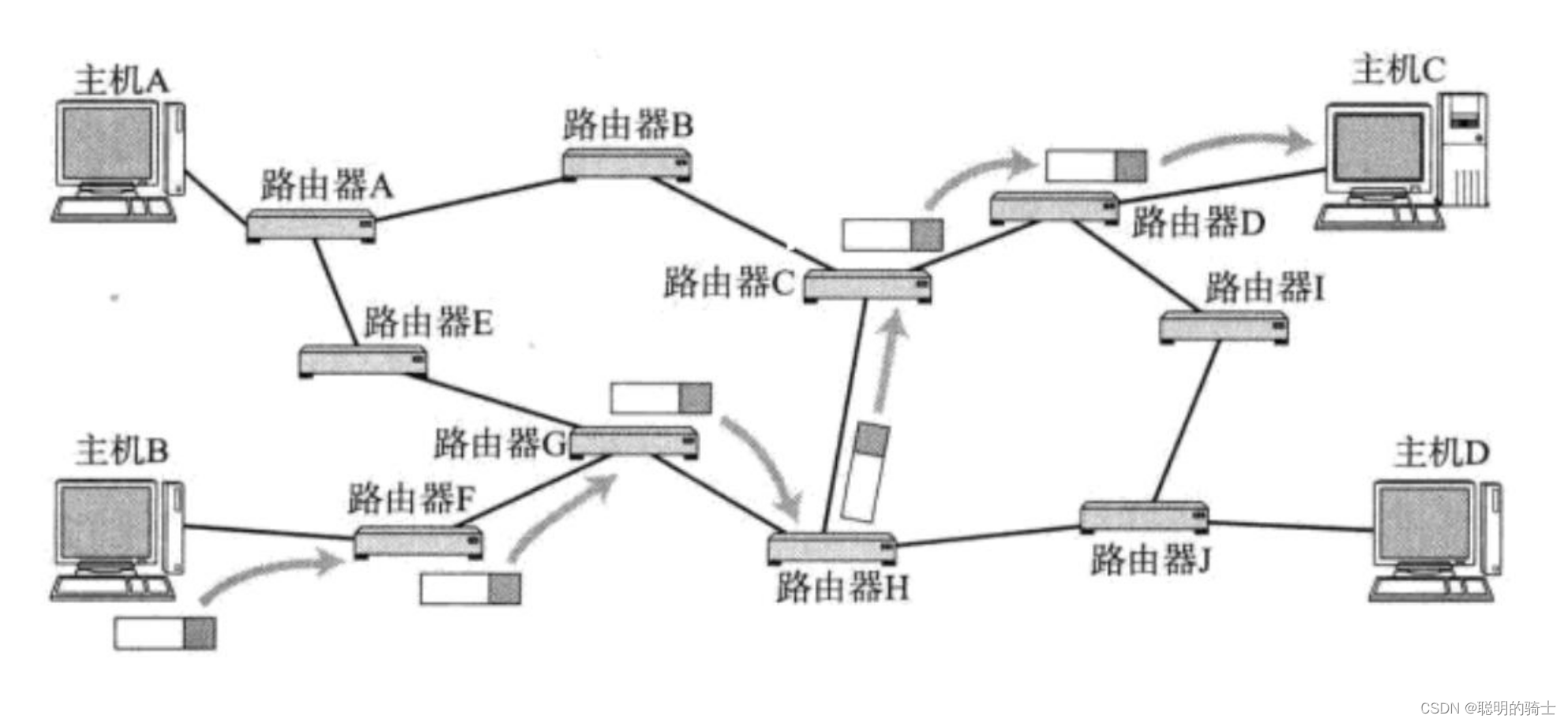
IP协议是网络层协议,它能提供将数据从主机A跨网络送到主机B的能力。
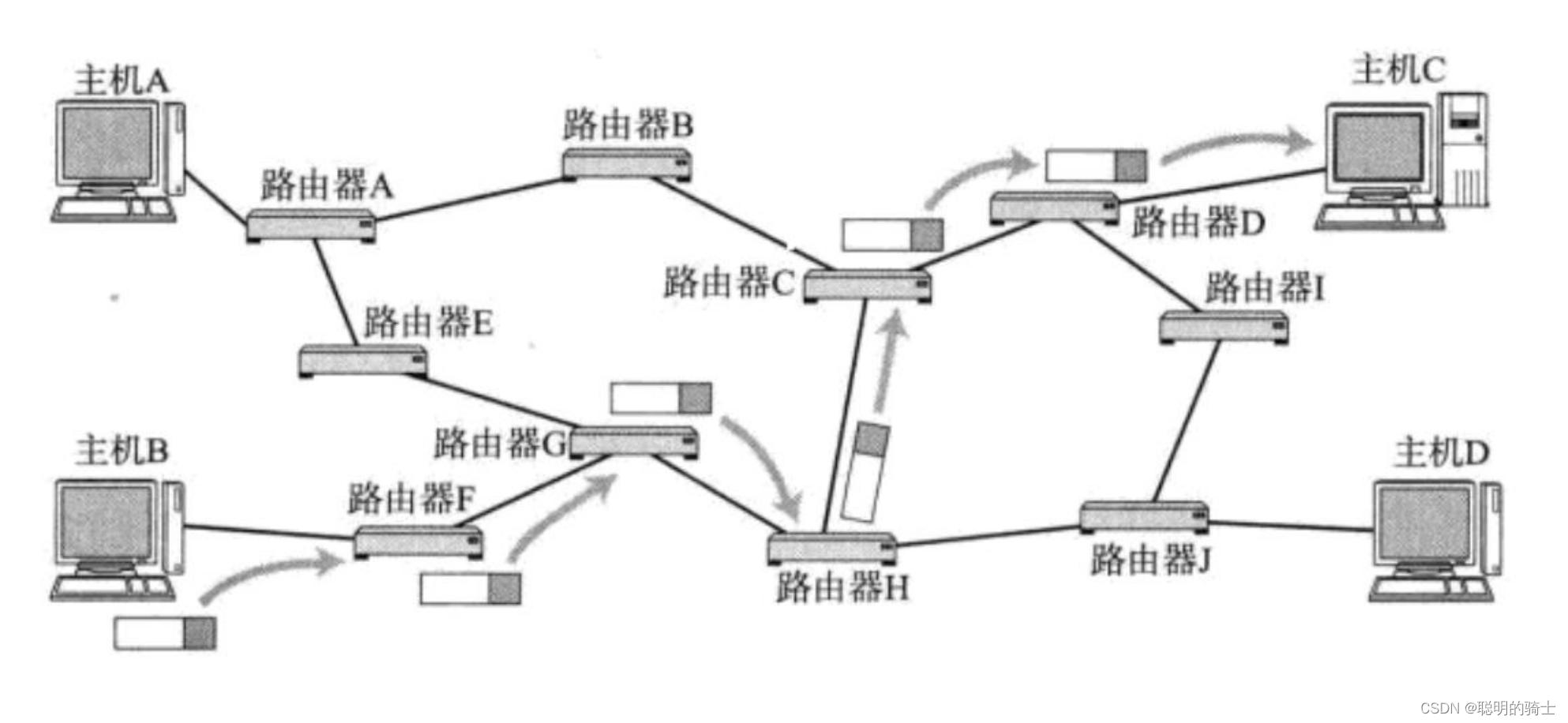
比方说,主机B发送数据到主机C,就可以从主机B出发到路由器F,再到路由器G,再到路由器H,再到路由器C,再到路由器D,最后到主机C。
主机和路由器有所不同:
- 主机:配有IP地址,可以进行网络通信的设备,比如电脑,手机等等。
- 路由器:配有IP地址,又能进行路由控制,也就是将数据从一个节点传送到另一个节点。
在这里,我们将主机和路由器都叫做节点。
数据从一个节点发送到另一个节点接收的过程称为一跳。比如,上面主机C收到数据的过程就经历了6跳。

虽然IP有这样的能力,但不代表它一定能成功。
所以,为了保证数据能百分百发送到对方主机,IP协议需要和TCP协议结合使用。TCP提供传输的策略,IP负责真正的转发报文执行。
毕竟IP的传输成功了已经很大了,TCP可以多次传递发送失败的报文,反正最后总会有一次成功的。
总之,TCP和IP组合可以将数据从主机A通过可靠的跨网络传输送到主机B。
二、认识IP地址
这是一张中国地图:
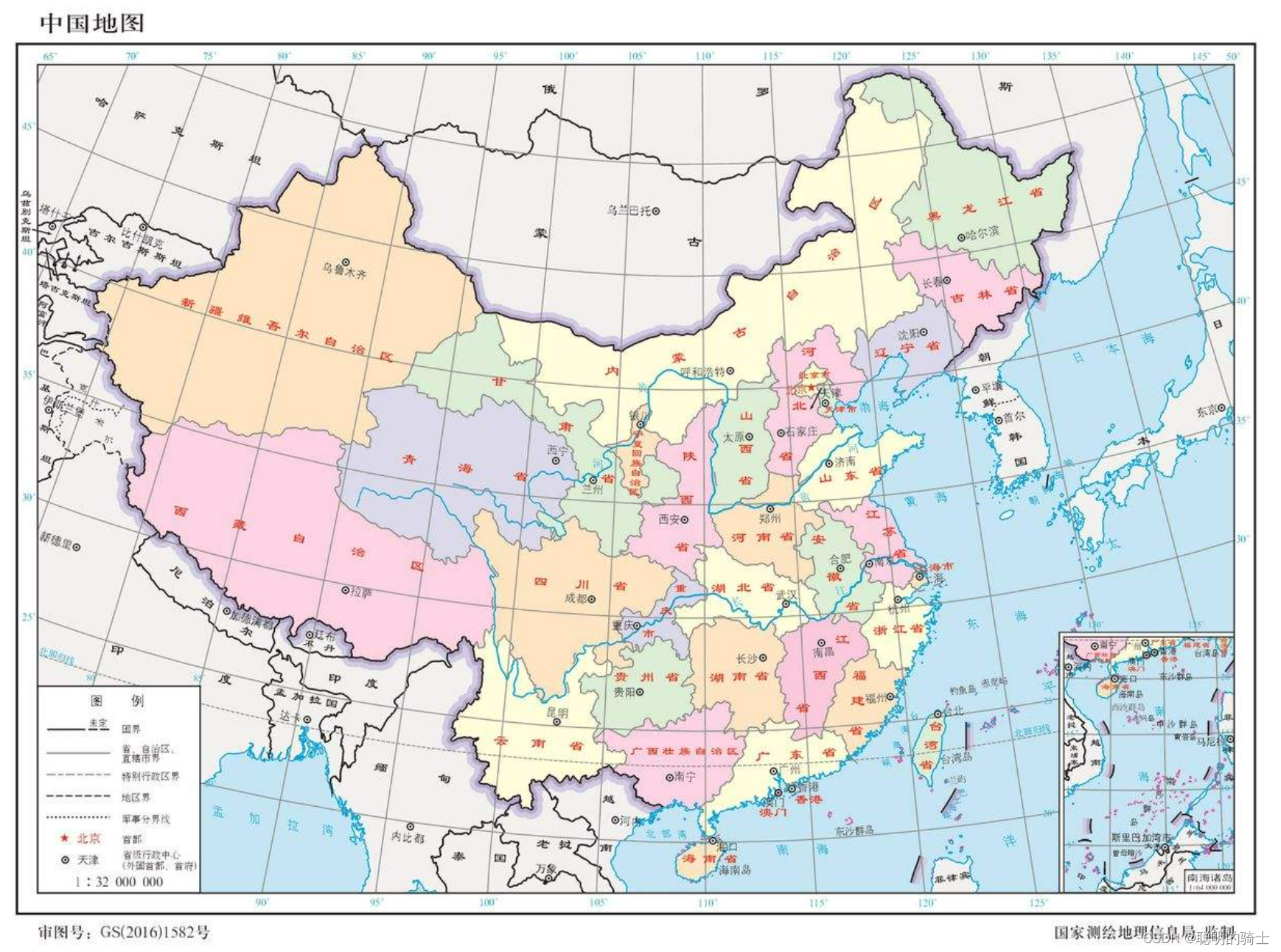
假如你现在在重庆,你想去天津旅游。假设两地没有直达的列车(现实中有),那么就近你可以先从重庆坐动车到湖北武汉,然后从武汉坐车到郑州,接着从郑州坐车到石家庄,最后从石家庄坐车到天津。
其中,重庆是出发点,天津是目的地,武汉、郑州、石家庄这些地方都是节点。由于你要去的是天津市,天津市在华北地区。所以,你肯定不会坐车去西北地区的兰州、西宁、拉萨、乌鲁木齐这样的地方。
也就是说,目的IP决定了报文在节点间传递的路径选择情况。
你到了天津可能会去解放北路、五大道、古文化街、天津之眼、津湾广场这样的地方,但它总归是天津的某一个地点。如果把天津看作一个网络,天津之眼这样的地方就可以看作一个具体的主机,而IP地址可以标识网络中主机的唯一性。
也就是说,IP = 目标网络 + 目标主机。
源IP和目的IP标识了网络中的两台主机。
三、协议报头格式
1.报头和有效载荷分离
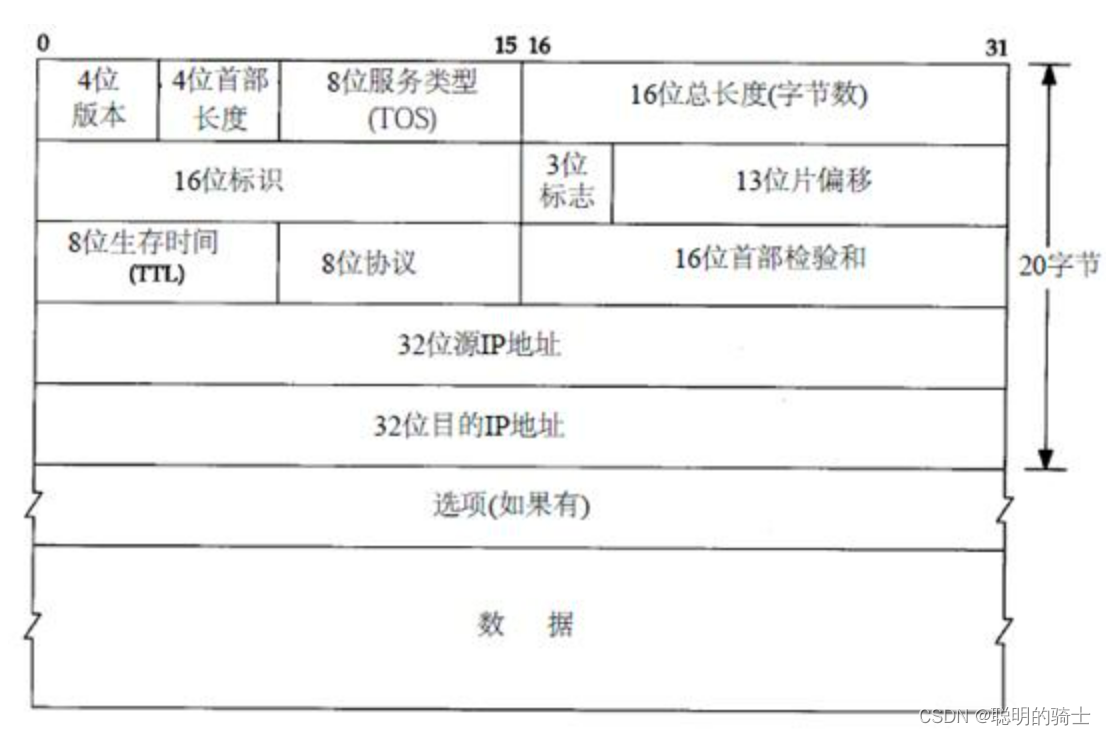
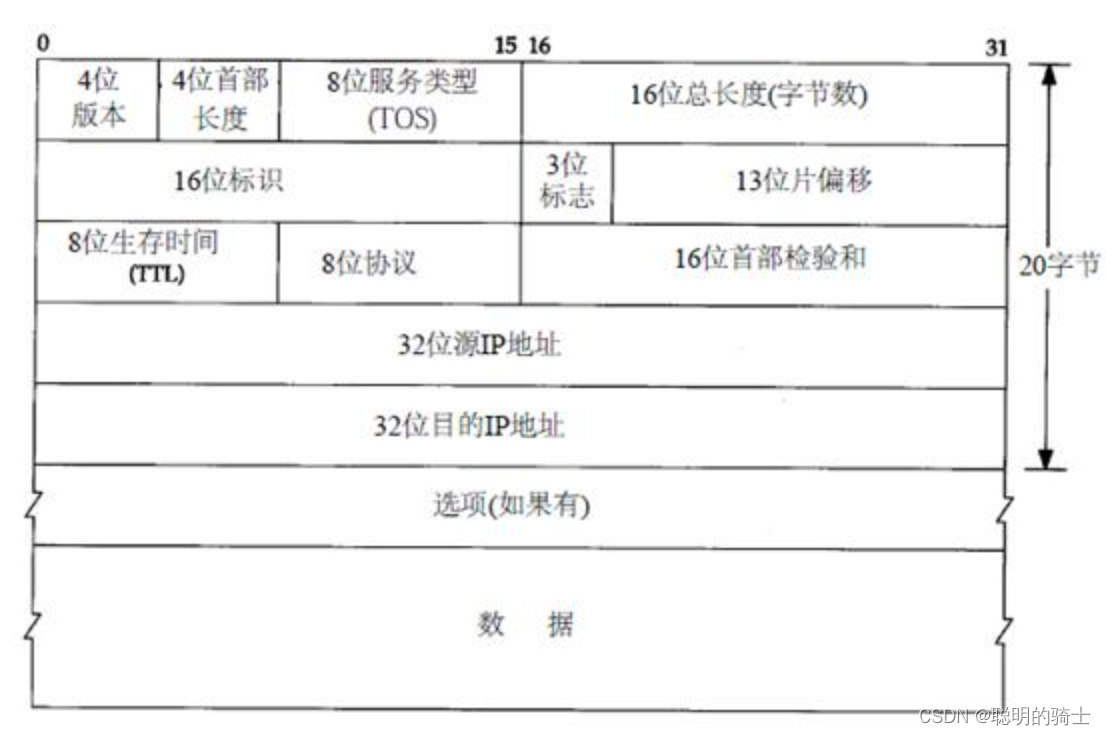
下面就是IP协议的格式,源IP和目的IP就不解释了:
老问题,报头和有效载荷如何分离?
IP报头由20位的标准长度和选项组成。
提取报文的前20个字节作为标准报头,4位首部长度乘以4就是整个报头的所占字节数,字节数减去20就是选项长度。
若差为0,说明没有选项,报文就是标准报头,直接读取有效载荷。
若差不为0,剩下几个字节,就说明有几个字节的选项。
下面我们会讲IP的20字节固定数据都有什么作用。
2.20字节的固定数据
16位标识、3位标志、13位片偏移这三个字段我会在后面的IP分片处讲到。
(1)4位版本
4位版本号指定IP协议的版本,对我们现在最常用的IPv4来说,其值是4。对于其他IPv4的扩展版本,则会有不同的版本号。
(2)4位首部长度
4位首部长度乘以4就是整个报头的所占字节数。
(3)8位服务类型
包括一个3位的优先权字段,4位的TOS字段和1位的保留字段(必须置0)。4位的TOS字段的每个比特位分别表示传输策略,最小延时,最大吞吐量,最高可靠性和最小费用。最多有一个位能置1,应用程序可根据实际需要设置它。
(4)16位总长度
表示整个报文(报头+有效载荷)的字节数。
(5)8位生存时间(TTL)
若将数据从主机B送到主机C,当路由器D发生故障时,它并没有把数据交给主机C,而是讲数据交给了路由器I,路由器I又将数据交给 路由器J,路由器J又将数据交给路由器H,路由器H又将数据交给路由器C,最后路由器C又将数据交给 路由器D,造成报文会一直在环路中发送。
所以IP传输中,我们设置了一个8位生存时间TTL,表示在转发过程中,最多经历的转发跳数。数据每到达一个新的路由器,就相当于一跳完成了,报文中储存的TTL就减一。(我们日常的数据传输基本只进行几跳,而TTL的值为255)
当TTL减到0时,表示报文不应该再被转发了,该报文就会被路由器直接丢弃。
(6)16位首部检验和
这个校验和只用于检测IP报头的正确性,有效数据的检测在TCP的校验和中已经检查过了。
四、网段划分
1.一个小例子
某天,张三在散步,结果捡到一个钱包,里面有一张残破的学生证,学生证上能看清的只有一串学号。所以张三只能只能通过学号来寻找丢失钱包的主人。
由于每个人的学号在整个学校中是唯一的,所以张三通过一个人一个人比对的方式理论上能找到失主。但偌大一个学校几万学生,效率太低了。
张三就可以看作源IP的主机,钱包是报文,学号可看作目的IP地址,钱包的失主可看作目标主机。主机在全网中根据目的IP地址用单个排除法寻找目的IP,效率会非常低下。
假设在大学中的学生们创立了一个寻物的公益组织,一个学校中肯定会有不同的学院,像材料学院、化学学院还有电子信息与计算机学院等。
我们在每个学院中找到一个负责人,每个负责人会将他所在学院的所有人拉进一个群,而每一个负责人又会加入一个各学院负责人的群。
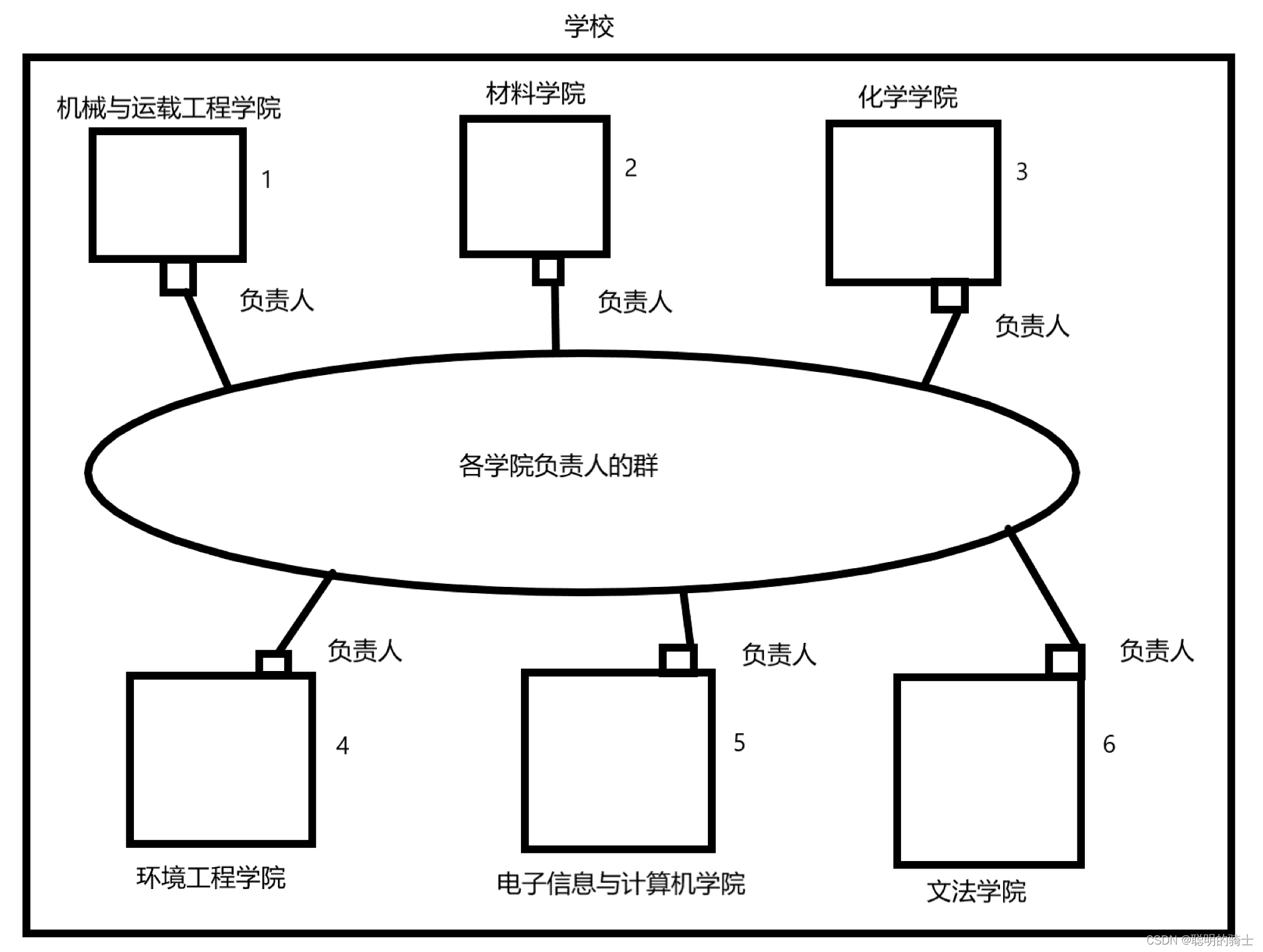
张三是电子信息与计算机学院的学生,计算机学院的编号为5,他的学生编号为091,他的学号就为5091。
全校没有任何一个同学的学号是一样的,假设捡到的钱包的学号为3103。张三自己找不到失主,就拍了张照片,发到电子信息与计算机学院的群里。
计算机院的负责人知道,学号前的数字表示学院,而3表示化学学院,所以他知道了丢钱包的人是化学学院的。
他就把照片再转发到各学院负责人的群里,通知化学学院的负责人他们院的学生丢东西了。
此时化学学院负责人发现就是他们院的同学丢的,就把照片转发到了化学学院的群里,通知103号同学。
在这个过程中,以群为单位来寻找,归还的效率提高了。
查找本质是排除的过程,选择一个群,就是排除了其他的所有群,查找效率大大提高了。
放到IP协议中也是一样,学号可以看作IP地址。各学院群可以看作子网,每个院的负责人可以看作路由器。负责人群可以看作公网,丢失钱包的人可以看作目标主机。
为了跨网络高效的数据传输,所以要进行子网划分 。(每个学院都有自己的群)先找到IP地址表示的目标网络(学院)再在子网中找到目标主机(学生)。
IP地址的构成是子网划分的结果,是为了提高一台主机查找到另一台主机的效率。
2.认识IP地址的划分
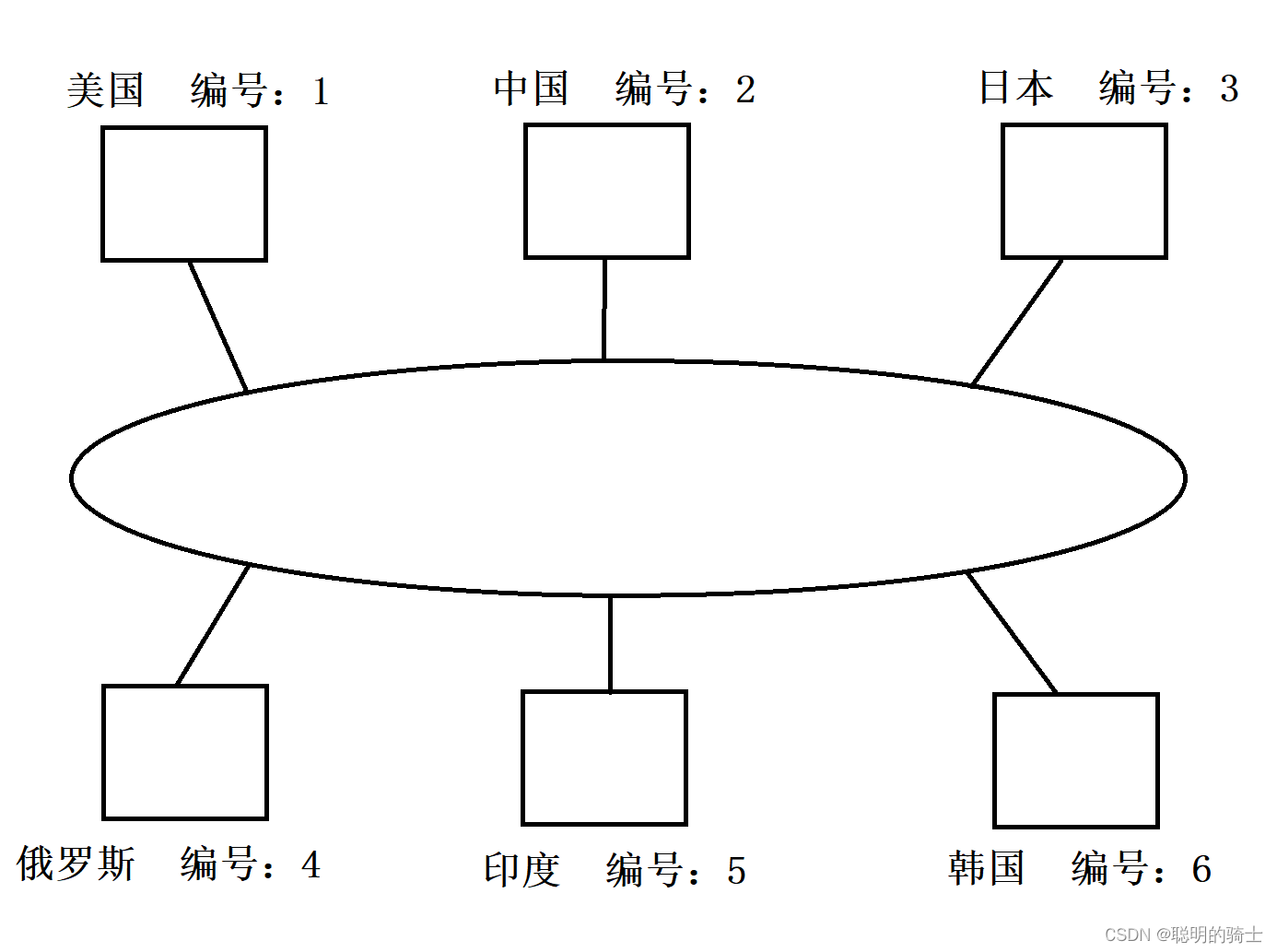
实际的IP是按照人口区域划分的,比如东亚、东南亚、北美这种,但为了大家更好理解,在这里我们就简单按照国家和省市区为单位划分子网。
世界上有众多国家,大家都会在一个公网中,每一个国家对应IP地址中的第一个字节,在上图中,中国的IP地址统一为2.x.x.x,而日本是3.x.x.x。
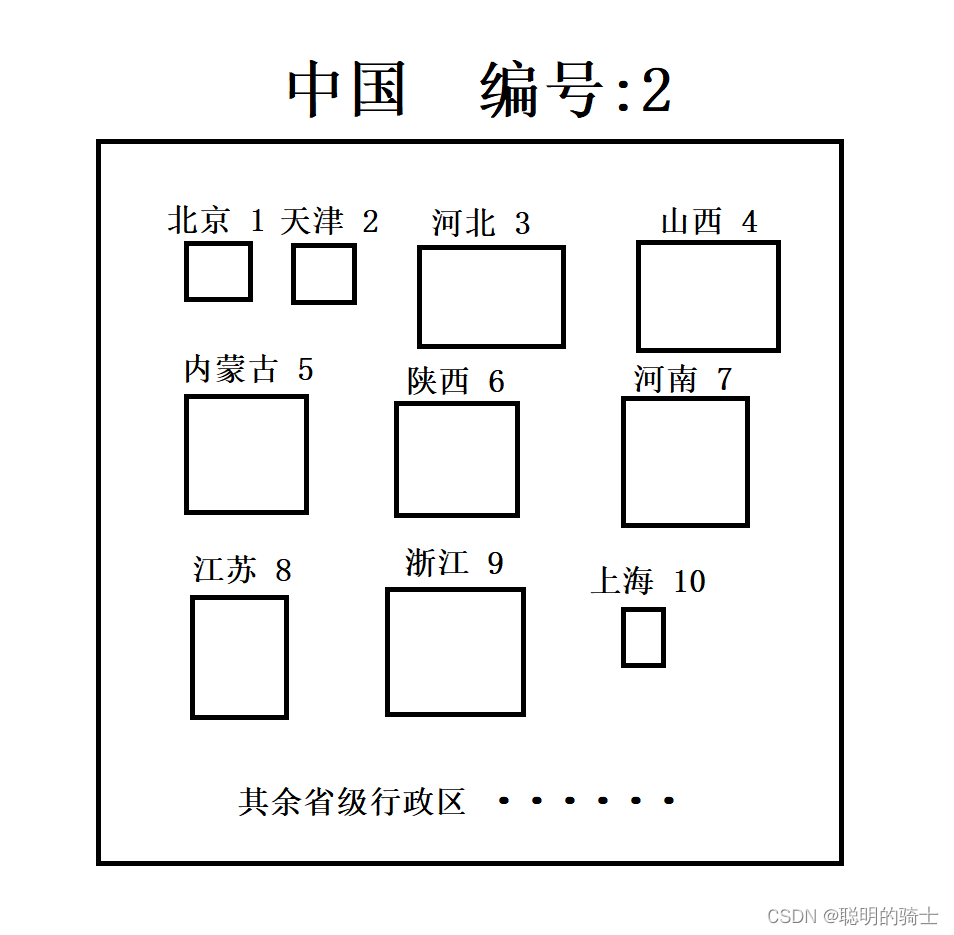
而每个国家又有多个行政区,比如在中国有34个省级行政单位。我们将IP地址中的第二个字节分配给这些省(自治区、直辖市、特别行政区),第一个字节仍保持不变。如北京就是2.1.x.x,天津就是上海就是2.2.x.x这样,河北就是2.3.x.x这样。
每个省级行政区内又有很多区县。我们以天津市为例,天津分为16区,将IP地址的第三个字节分配给这些区,第一个和第二个字节仍保持不变。如和平区就是2.2.1.x,河西区就是2.2.2.x,武清区就是2.2.11.x。

每个区中又很有多台主机,也就是有多个节点,包括服务器也是一个节点,将IP地址中的第四个字节分配给这些节点,如和平区的张三的电脑就是2.2.1.2等。
声明:实际的IP地址会按照不同人口比例的地区进行划分,非常复杂。上面的模型只是模式相似,与现实相去甚远,只是为了方便理解。
根据IP地址中的前3个字节,就可以将数据报文通过多个路由器跳转送到目标主机所在子网的入口路由器,此时也就确定了目标主机所在的子网络。
目标主机所在子网的路由器再根据主机号,也就是IP地址中的最后一个字节来确定某个主机,最后将数据发送到目标主机上。
IP地址中的前3个字节被叫做网络号,最后一个字节被叫做主机号。不同网段(子网)的网络号必须不同,同一网段内主机号必须不同。
网络号保证了两个相连的子网具有不同的标识,主机号保证了同一子网内不同主机有不同的标识。
3.数据的传输过程
假设你现在在日本留学,用Wechat给你在天津大学上学的同学发了一个消息,当数据到了IP层被封装以后,假设源IP地址是3.1.1.1,目的IP地址是2.2.3.4。
每个子网都有一个入口路由器,该路由器是子网内部所有路由器的上层路由器,也叫做默认路由器。
每一个入口路由器都横跨两个子网,一个是它所在的子网,还有一个是它下一层的子网。
数据被发送出去以后,首先到达的是你所在区子网的路由器,路由器发现目的IP中的前三个字节是3.1.1,而整个日本子网的IP地址中第一个字节是3,所以它将数据不断交给上层路由器,最后到了维护全日本网络的入口路由器。
由于日本和中国的入口路由器处于一个公网内,所以它知道这个目的IP在中国,也就将这个数据发给了中国的入口路由器。
数据到达中国的入口路由器后,再根据第二个字节传递到天津市的入口路由器中。
数据到达天津市的入口路由器后,再根据第三个字节传递到南开区的入口路由器中。
数据到达南开区的入口路由器后,再根据最后一个字节传递到你天津大学的同学主机上。
通过子网划分的方式,让数据报每传送一次就能排除大量的IP地址,比起遍历的方式,效率确实得到了大幅提升。
4.特殊的IP地址
- IP地址中,主机号为0的IP代表网络号,如192.168.128.0,这个IP地址只起到标识作用,不能绑定主机。
- 主机号为1,如192.168.128.1代表当前子网的默认路由器(入口路由器),所以这个IP地址也不能绑定主机。
- 主机号为255,如192.168.128.255表示广播地址,表示把数据发到本网络中的所有的主机上,同样不可绑定。
- 127.0.0.1表示本地环回,数据不会发送到网络上,而是经过网络的分层处理再被本主机接收,以前用过很多次了。
5.通信运营商
(1)通信运营商的作用
在现实中,我们的网段划分都是经过设计的,所以说互联网是一个被设计过的世界。
那么设计者是谁呢?
那就是通信运营商,在我们国家就是移动,电信,联通三巨头,其他国家也有自己运营商,比如美国的威瑞森、德国的德国电信、英国的沃达丰等等。
运营商不仅设计了互联网的网段划分,而且搭建了物理层中的各种通信设备,比如信号基站。正因为运行商的工作,网络数据才能经过各种硬件设备传输,我们才能进行网络通信。
正因为运营商是底层网络的设计者,我们上网需要使用这些公司提供的机制和设备,所以我们使用网络需要向运营商交钱。
(2)DHCP技术
如果我们需要在子网中新增一台主机,则这台主机的IP地址中,网络号必须和这个子网的网络号一致,主机号必须不能和子网中的其他主机一样。
所以,通过合理设置主机号和网络号,就可以保证在每个子网中,每台主机的IP地址都不相同。
为了实现子网中IP地址的管理,人们发明了一种技术叫做DHCP。它能够自动的给子网内新增的主机节点分配IP地址,避免了手动管理IP的不便。
一般的路由器都带有DHCP功能,它也使用这个功能管理自己的局域网,因此路由器也可以看做一个DHCP服务器。
你可能从来没有注意到它的存在,实际上我们每天都在和它打交道。
在你的电子设备在没有联网的时候是没有IP地址的。而我们在连接wifi时,往往需要输入账号和密码,本质上就是在向路由器申请IP地址。密码核对成功,路由器就会给你的设备分配一个子网内的IP地址。网络连接断开时,该IP地址又会被收回。
五、IP地址分类
1.早期分类模式
在最早没有的时候,把所有IP地址分为五类:
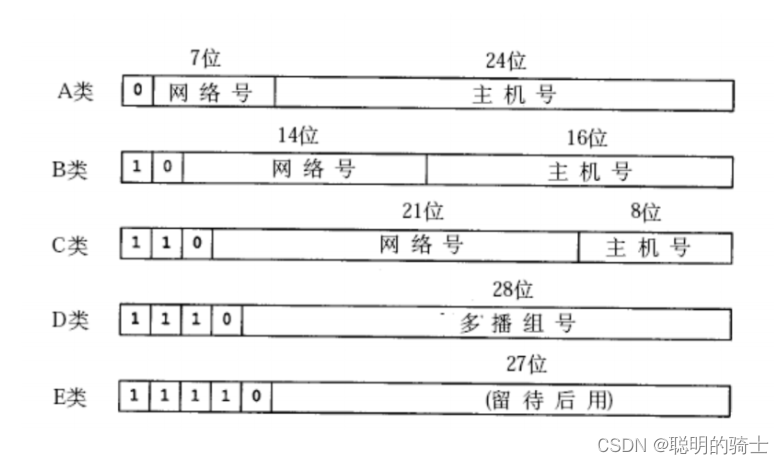
- A类:IP的第一个比特位为0,后面7个比特位为网络号,剩余24位为主机号。最多能构建2的7次方个网络,每个网络最多可容纳2的24次方个主机。(0.0.0.0到127.255.255.255)
- B类:IP的第一个比特位为1,第二个为0,后面14个比特位为网络号,剩余16位为主机号。最多能构建2的14次方个网络,每个网络最多可容纳2的16次方个主机。(128.0.0.0到191.255.255.255)
- C类:IP的第一和第二个比特位为1,第三个为0,后面21个比特位为网络号,剩余8位为主机号。最多能构建2的21次方个网络,每个网络最多可容纳2的8次方个主机。(192.0.0.0到223.255.255.255)
- 我们只需要知道D类和E类前三个和前四个比特位为1,后一个为0,能够构建的网络更多,每个网络能容纳的主机数更少。(D类224.0.0.0到239.255.255.255,E类240.0.0.0到247.255.255.255)
网络号和我们讲过的网段划分一样,用来标识不同子网。只是将不同范围的网络号分为了ABCDE五类,某一个子网可以领取几类IP地址去使用。
但随着网络的飞速发展,这种划分方案的局限性很快显现出来。
大多数组织都申请主机数适中的B类网络地址,导致B类地址很快就分配完了。
而A类地址可分配的主机数太多,实际网络架设中,不会存在一个子网内有这么多主机的情况,而IP地址被分配给一个组织后就不能再分配给其他组织了,因此大量的IP地址都被浪费掉了。
2.CIDR
针对这种情况人们提出了新的划分方案CIDR(无类域间路由)。
一方面,它不再不区分IP地址的类型,并按我们上面子网划分的思想划分IP。另一方面,它引入子网掩码用于区分网络号和主机号。
子网掩码有以下特征:
- 子网掩码也是一个32位的正整数,通常用一串“0”来结尾。
- 将IP地址和子网掩码进行“按位与”操作,得到的结果就是网络号。
- 网络号和主机号的划分与这个IP地址是A类、B类还是C类无关。
子网掩码在跨网络传输中如何起到作用呢?
一个路由器收到了一个IP报文,目的IP地址是140.252.20.68,该路由器所处网段的子网掩码为255.255.255.0(子网掩码和网络号都会提前配置在路由器中)。

将它们转换为二进制:
140.252.20.68转化为二进制是1000 1100.11111100.0001 0100.0100 0100
255.255.255.0转化为二进制是1111 1111.1111 1111.1111 1111.0000 0000
IP地址和子网掩码按位与后,得到的网络号是1000 1100.11111100.0001 0100.0000 0000转化为十进制为140.252.20.0。
如果该结果与路由器自己网段的网络号相同,那么该数据应当由该路由器管理的主机或子网接收,数据将被保留在本网段的子网中。
如果不同,则表明数据不是发给该路由器管理的主机或子网的。路由器会将数据给到上一层路由器去处理。
子网的网络范围表示该路由器可管理的IP地址,如果你注意观察子网掩码,你会发现它前面是一串1,后面是一串0。
如果你从运算的角度思考,你会发现原来IP地址为1的部分在网络中还是1,是0的部分也还是0。而后面的一串0按位与后结果只会是0。
所以说,一串1的这几个比特位表示网络号,而后面的一串0对应的比特位表示主机号,后8位从0000 0000(0)到1111 1111(255)都是子网的IP地址范围(当然有一部分IP不能作为主机的IP地址)。
网络号 主机号
(1111 1111.1111 1111.1111 1111).(0000 0000)
下面的例子你就能看得更明白了。

路由器收到了一个IP报文,目的IP地址是140.252.20.68,该路由器所处网段的子网掩码为255.255.255.240。
将它们转换为二进制:
140.252.20.68转化为二进制是1000 1100.11111100.0001 0100.0100 0100
255.255.255.240转化为二进制是1111 1111.1111 1111.1111 1111.1111 0000
IP地址和子网掩码按位与后,得到的网络号是1000 1100.11111100.0001 0100.0100 0000转化为十进制为140.252.20.64。
同样,前28位为网络号,后四位为主机号,主机号可从0000到1111。最后一个字节可从0100 0000(64)增长到0100 1111(79)。
网络号 主机号
(1111 1111.1111 1111.1111 1111.0000)(0000)
也就是说,我们可以控制子网掩码中的1的个数来控制网络号和主机号的长度,从而做到对网络数量和单网络主机承载量的合理调整。从而避免大量的IP地址被浪费。
而且,如果你将掩码设置为255.0.0.0、255.255.0.0、255.255.255.0,你会发现它们正好对应了A类、B类和C类IP地址,也就是说子网掩码是兼容之前的IP分类的。
3.IP地址数量不足的现状
我们知道,IP地址(IPv4)是一个4字节32位的正整数,理论上IP地址仅有2的32次方个(43亿左右)。而TCP/IP协议要求每个主机都要有一个独一无二的IP地址。又因为一些特殊的IP地址的存在,所以IP地址数量远不足43亿。另外,每一个网卡都需要配置一个或多个IP地址,而我们的电子设备中很可能拥有不止一个网卡。
既然IP地址一直处于严重不足的现状,那我们为什么能够保证这么多的电子设备能够入网呢?
CIDR虽然提高了IP地址利用率,减少了浪费,但是IP地址的绝对数量并没有增加,仍然处于严重不足的状态。
这时候人们又提出了三种新的技术解决这个问题:
- 动态分配IP地址:只给接入网络的设备分配IP地址,因此同一个MAC地址的设备,每次接入互联网中,得到的IP地址不一定是相同的。这个技术我们在上面说过。
- NAT技术:后面会重点介绍。
- IPv6:IPv6用16字节128位来表示一个IP地址,这样就大大增加了IP地址的数目,从根本上解决了问题。它由中国发明并完善,而且在国内我们很多计算机都已经使用了IPv6。但IPv4还是国际主流,再加上IPv4早已被编入主流操作系统中,所以目前IPv6的推行还有很大困难。
六、内外IP和公网IP地址
1.内网和外网IP的规定
如果一个组织内部组建自己的局域网,IP地址只用于局域网内的通信,而不直接连到公网上。理论上内部使用任意的IP地址都可以,但是RFC1918规定了用于组建局域网的私有IP地址范围:
- 10.*,前8位是网络号,后24位是主机号,所以共有16777216个地址。
- 127.16到127.31,前12位是网络号,后20位是主机号,所以共有1048576个地址。
- 192.168.*前16位是网络号,后16位是主机号,所以共有36636个地址。
在这个范围中的IP地址都称为内网IP(私有IP),其余的都称为公网IP(全局IP)。
2.WAN口IP和LAN口IP
每个路由器会横跨两个子网,一个是它构建的局域网,另一个是它的上一级网络。所以每个路由器都配有两个IP地址,一个叫WAN口IP,另一个叫LAN口IP。
WAN口IP在上层子网中使用。
在我们上面的说的子网划分中,假如我们现在的路由器是管理天津市和平区主机所在的局域网的,而天津市全市的入口路由器管理各区路由器的子网就是上一层网络,WAN口IP就是该路由器在这个网段中的IP地址。
WAN口IP在本层子网中使用。
另一个IP地址是LAN口IP,该路由器管理天津市和平区主机所在的局域网,LAN口IP就是该路由器在这个网段中的IP地址。
由于路由器使用两套不同的IP地址,所以每个子网内的主机IP地址不能重复,但子网之间的IP地址就可以重复了。
3.公网与私网IP的特征
下面是一个网络的简单图例:

我们先看图的左下角,所有家用路由器的LAN口IP都是192.168.1.1/24(192.168.1.1表示IP地址,/24表示子网掩码的前24位为1),这个IP地址是家用路由器构建的,局域网内的所有设备都通过该路由器通信。
在这个家用路由器构建的局域网中,路由器的子网IP192.168.1.1就是唯一的。

但是两个家用路由器的WAN口IP不同,因为它们需要在运营商路由器构建的网络中标识自己的唯一性。家用路由器的WAN口IP与运营商路由器的LAN口IP是对应的。
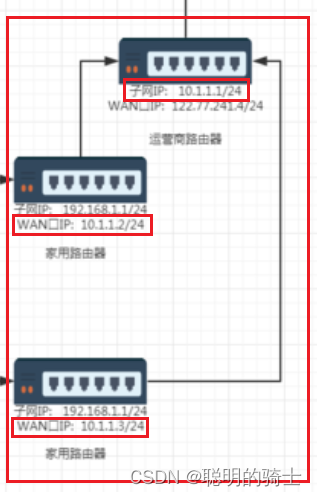
在广域网中,各个运营商路由器的WAN口IP也是一样的。
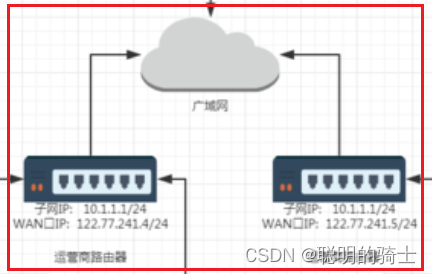
所以我们对这个体系做出总结如下:
局域网中,一个子网中所有节点的IP地址都不能相同,要具有唯一性。不同子网中的IP地址可以相同。
公网中,IP地址必须具有唯一性,不论属于哪个子网。
我们前面画的网段划分是公网网段划分的理想示意图,没有加入任何内网。实际上在到达一个国家的某个行政区时,就已经开始采用这种构建内网的方式了。
所以,我们平时在B站,抖音等软件里都能看到评论归属地,但最细也只能到我国的省级行政区,无法看到区县这样的信息。
这是因为各个行政区见使用的还是公网IP,识别属地很容易。在本行政区内大多使用内网IP,识别就比较困难了。
4.NAT技术
假设,我们现在要用我们的电脑给服务器发送一条数据,我电脑的内网IP地址为192.168.1.201/24,服务器的公网IP地址为122.77.241.3/24。
如果将192.168.1.201/24作为源IP,122.77.241.3/24作为目的IP填入报头且传输过程中不做更改,就会发生下面的问题:
你的电脑首先会发送数据给家用路由器,家用路由器用子网掩码按位与后,发现该数据不是发送到本网段的,然后会把数据交给了运营商路由器。
运营商路由器用同样的判断方式,发现数据不是发给本网段的,而是要发送给公网中的服务器的,所以运营商路由器将数据发送给了服务器。
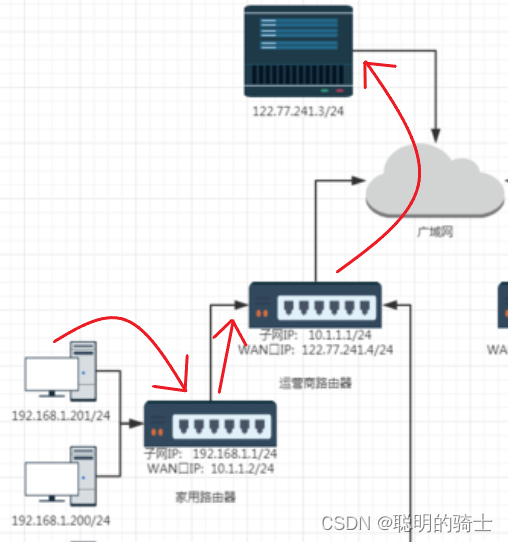
服务器对数据做处理并将处理后的数据放入IP报文内,并将源IP设为122.77.241.3/24,将目的IP设为192.168.1.201/24。
此时问题就出现了。
此时的目的IP是一个内网IP,内网与公网的IP相互没有联系。所以当数据发到运营商路由器那里时,运营商路由器一方面根本不知道这个IP在哪里,而且它们维护的子网下可能会有很多这样的IP,更不能保证数据传回了。

为了解决公网和内网的通信问题,我们引入了NAT(网络地址转换)技术。
内网中的主机需要和公网网进行通信时,路由器会适时将IP报头中的源IP和目的IP替换成该路由器的WAN口IP或LAN口IP,以保证数据可以在不同的网络中传递。
首先,我们看看数据的发送。
你的电脑将数据发送到家用路由器时,IP报头中的源IP是一个内网IP192.168.201/24,目的IP是一个公网IP122.77.241.3/24。
家用路由器再将数据发送给运营商路由器时,IP报头中的源IP会替换成了家用路由器的WAN口IP10.1.1.2/24,同样是一个内网IP地址,但可以满足在上一层网络通信。
运营商路由器再将数据发送到公网给服务器的时候,将IP报头中的源IP地址也会替换成了运营商路由器的WAN口IP122.77.241.4/24。这是一个公网IP,在全网都具有唯一性。
此时,数据就能通过公网被发送给服务器进行处理。
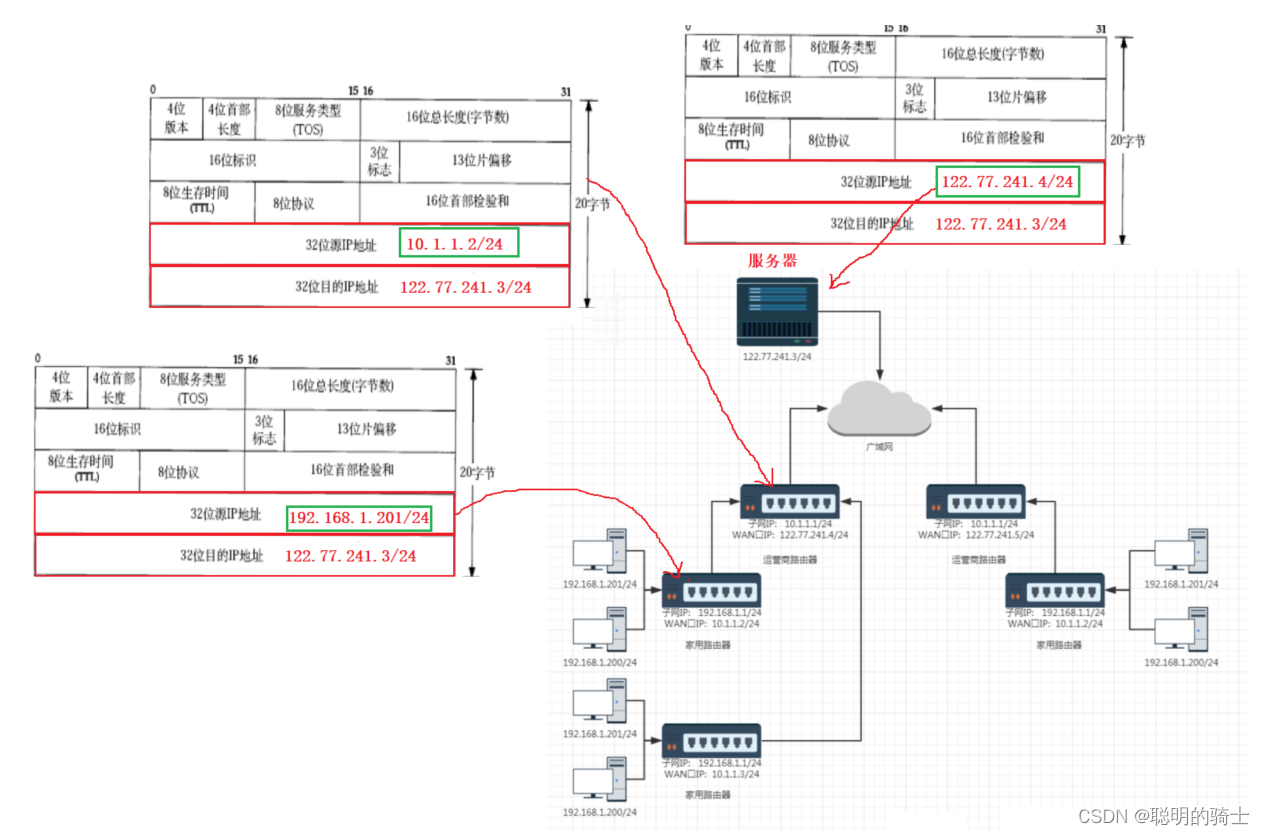
接着,我们看看数据的接收。
服务器将处理后的数据发送到广域网最后到达运营商路由器时,IP报头中的源IP是一个公网IP122.77.241.3/24,目的IP是一个公网IP122.77.241.4/24。
家用路由器再将数据发送给运营商路由器时,运营商路由器发现这个数据要发给自己的子网,所以IP报头中的目的IP会替换成了家用路由器的LAN口IP10.1.1.2/24。这是一个内网IP地址,可以满足内网的通信。
运营商路由器再将数据发送到家用路由器时,会将IP报头中的目的IP地址也会替换成家用路由器的LAN口IP192.168.201/24,依旧是一个内网IP。
此时,数据就能从家用路由器发送到你的主机上,数据的传输也就完成了。
七、路由
在复杂的网络拓扑结构中找出一条通往终点的路线称为路由,数据从一个节点传递到另一个节点称为一跳。
我们在上面的NAT已经说过,当IP数据报到达路由器以后,如果目的IP在本网段内就直接将数据发送给目标主机。如果不在本网段内,就发送给它上一层网络的路由器。
那么路由器是如何判断当前这个IP数据报该发送到哪里呢?
答案是每个节点(路由器和主机)内部维护的路由表了。
在Linux上,使用route指令可以查看当前机器上的路由表,可见我们的计算机也有路由功能,也可看作路由器。

我们使用下图的路由表来讲解。不过我删除了Metric和Ref两列数据,因为现在不用关心它是什么意义。

- 路由表的Destination表示目的IP地址,Genmask是子网掩码,Gateway是下一跳地址,也就是下一个路由器IP地址。Iface是发送接口,也是物理上存在的接口,通过网线和对应网络相连。
- 这台主机有两个网络接口(Iface),一个网络接口eth0连到192.168.10.0/24网络,另一个网络接口eth1连到192.168.56.0/24网络。
- Flags中的U表示此条目有效,G标志表示此条目的下一跳地址是某个路由器的地址,没有G的条目表示目的网络地址是与本机接口直接相连的网络,不必经路由器转发。
- default表示缺省网段,如果数据不属于上述任何网段,该数据会直接发送到缺省网段内。
这样说大家肯定不明白,我举两个例子:
例一:如果要发送的数据的目的IP是192.168.56.3
首先,目的IP会跟第一行的子网掩码做按位与运算得到网络号192.168.56.0,结果与第一行的目的网络地址不符。
接着,目的IP会跟第二行的子网掩码再次做按位与运算得到192.168.56.0,结果正是第二行的目的网络地址,因此该节点将会把数据从eth1接口发送出去。
由于192.168.56.0/24正是与eth1接口直接相连的网络,因此节点可以在该网络中查找目的IP是否有主机占用。如果有主机使用该IP地址,节点会把数据发送到该主机上。
例二:如果要发送的数据包的目的地址是202.10.1.2
数据依旧从第一行到倒数第二行通过子网掩码进行按位与运算,并与路由表前几项的网络号进行对比。我们发现它们都不匹配,说明该数据不应该发送到该节点的网段。
所以,数据会按最后一行的缺省路由,从eth0接口发往IP地址为192.168.10.1的路由器,由IP地址为192.168.10.1的路由器根据它的路由表决定下一跳的地址。
总而言之,当一个报文来到节点后,会经过四步完成数据报文的发送:
- 遍历路由表
- 目的IP和路由表中的每一行的子网掩码按位与,确定该数据报要去的目标网络。
- 对比结果和目标网络
- 通过Iface接口发出报文。
还记得IP协议报头中的8位生存时间(TTL)字段吗?该字段的值表示数据传递的最大跳数,该值减为0时报文被丢弃。
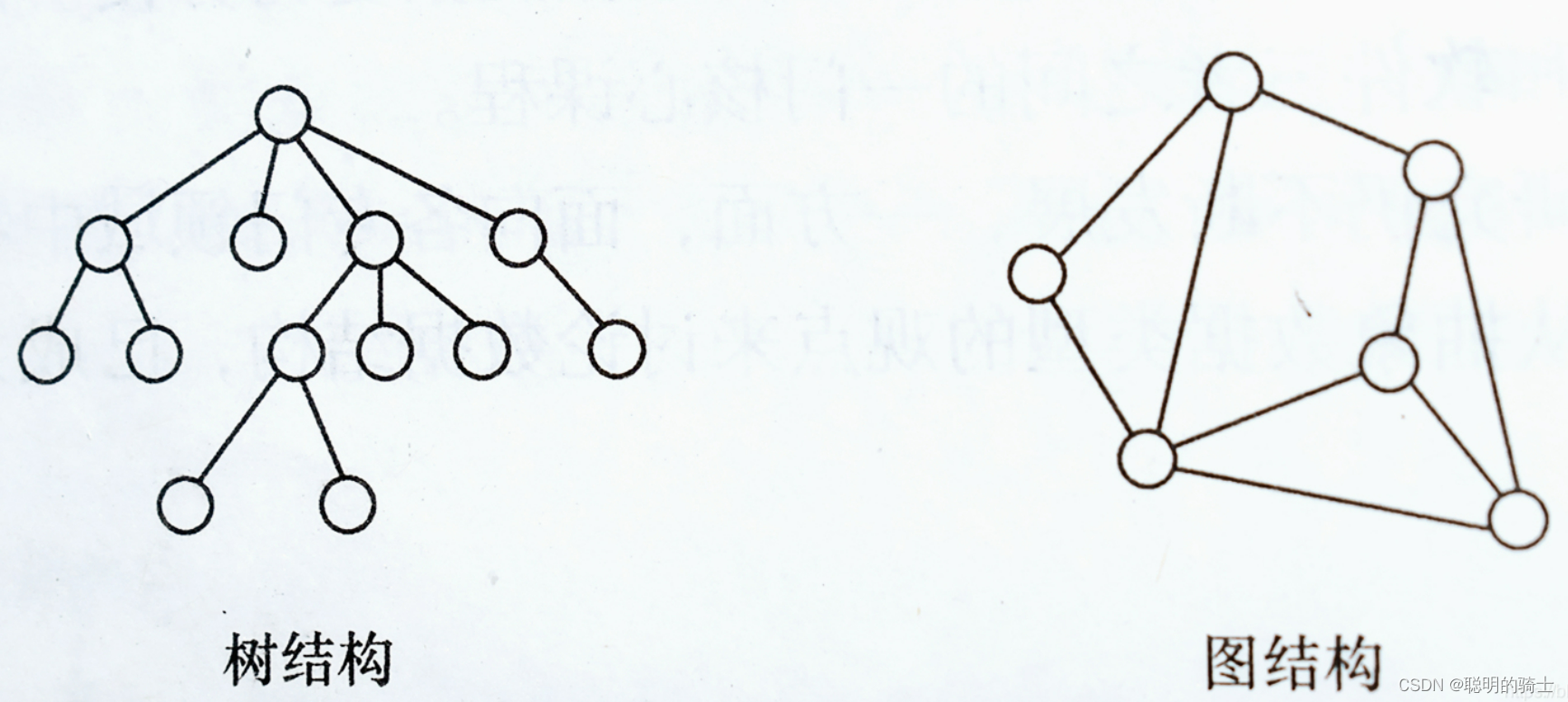
在数据传送的过程类似于多叉树模型,每一跳都在向下遍历,能排除相当多的主机。但实际上,网络是一个图状结构,比我们想的复杂得多。