诸公可知目前最牛逼的TTS免费开源项目是哪一个?没错,是Bert-vits2,没有之一。它是在本来已经极其强大的Vits项目中融入了Bert大模型,基本上解决了VITS的语气韵律问题,在效果非常出色的情况下训练的成本开销普通人也完全可以接受。
BERT的核心思想是通过在大规模文本语料上进行无监督预训练,学习到通用的语言表示,然后将这些表示用于下游任务的微调。相比传统的基于词嵌入的模型,BERT引入了双向上下文信息的建模,使得模型能够更好地理解句子中的语义和关系。
BERT的模型结构基于Transformer,它由多个编码器层组成。每个编码器层都有多头自注意力机制和前馈神经网络,用于对输入序列进行多层次的特征提取和表示学习。在预训练阶段,BERT使用了两种任务来学习语言表示:掩码语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)。通过这两种任务,BERT能够学习到上下文感知的词嵌入和句子级别的语义表示。
在实际应用中,BERT的预训练模型可以用于各种下游任务,如文本分类、命名实体识别、问答系统等。通过微调预训练模型,可以在特定任务上取得更好的性能,而无需从头开始训练模型。
BERT的出现对自然语言处理领域带来了重大影响,成为了许多最新研究和应用的基础。它在多个任务上取得了领先的性能,并促进了自然语言理解的发展。
本次让我们基于Bert-vits2项目来克隆渣渣辉和刘青云的声音,打造一款时下热搜榜一的“青岛啤酒”鬼畜视频。
语音素材和模型
首先我们需要渣渣辉和刘青云的原版音频素材,原版《扫毒》素材可以参考:https://www.bilibili.com/video/BV1R64y1F7SQ/。
将两个主角的声音单独提取出来,随后依次进行背景音和前景音的分离,声音降噪以及声音切片等操作,这些步骤之前已经做过详细介绍,请参见:民谣女神唱流行,基于AI人工智能so-vits库训练自己的音色模型(叶蓓/Python3.10)。 囿于篇幅,这里不再赘述。
做好素材的简单处理后,我们来克隆项目:
git clone https://github.com/Stardust-minus/Bert-VITS2
随后安装项目的依赖:
cd Bert-VITS2 pip3 install -r requirements.txt
接着下载bert模型放入到项目的bert目录。
bert模型下载地址:
中:https://huggingface.co/hfl/chinese-roberta-wwm-ext-large
日:https://huggingface.co/cl-tohoku/bert-base-japanese-v3/tree/main
语音标注
接着我们需要对已经切好分片的语音进行标注,这里我们使用开源库whisper,关于whisper请移步:闻其声而知雅意,M1 Mac基于PyTorch(mps/cpu/cuda)的人工智能AI本地语音识别库Whisper(Python3.10)。
编写标注代码:
import whisper
import os
import json
import torchaudio
import argparse
import torch lang2token = { 'zh': "ZH|", 'ja': "JP|", "en": "EN|", }
def transcribe_one(audio_path): # load audio and pad/trim it to fit 30 seconds audio = whisper.load_audio(audio_path) audio = whisper.pad_or_trim(audio) # make log-Mel spectrogram and move to the same device as the model mel = whisper.log_mel_spectrogram(audio).to(model.device) # detect the spoken language _, probs = model.detect_language(mel) print(f"Detected language: {max(probs, key=probs.get)}") lang = max(probs, key=probs.get) # decode the audio options = whisper.DecodingOptions(beam_size=5) result = whisper.decode(model, mel, options) # print the recognized text print(result.text) return lang, result.text
if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--languages", default="CJ") parser.add_argument("--whisper_size", default="medium") args = parser.parse_args() if args.languages == "CJE": lang2token = { 'zh': "ZH|", 'ja': "JP|", "en": "EN|", } elif args.languages == "CJ": lang2token = { 'zh': "ZH|", 'ja': "JP|", } elif args.languages == "C": lang2token = { 'zh': "ZH|", } assert (torch.cuda.is_available()), "Please enable GPU in order to run Whisper!" model = whisper.load_model(args.whisper_size) parent_dir = "./custom_character_voice/" speaker_names = list(os.walk(parent_dir))[0][1] speaker_annos = [] total_files = sum([len(files) for r, d, files in os.walk(parent_dir)]) # resample audios # 2023/4/21: Get the target sampling rate with open("./configs/config.json", 'r', encoding='utf-8') as f: hps = json.load(f) target_sr = hps['data']['sampling_rate'] processed_files = 0 for speaker in speaker_names: for i, wavfile in enumerate(list(os.walk(parent_dir + speaker))[0][2]): # try to load file as audio if wavfile.startswith("processed_"): continue try: wav, sr = torchaudio.load(parent_dir + speaker + "/" + wavfile, frame_offset=0, num_frames=-1, normalize=True, channels_first=True) wav = wav.mean(dim=0).unsqueeze(0) if sr != target_sr: wav = torchaudio.transforms.Resample(orig_freq=sr, new_freq=target_sr)(wav) if wav.shape[1] / sr > 20: print(f"{wavfile} too long, ignoring\n") save_path = parent_dir + speaker + "/" + f"processed_{i}.wav" torchaudio.save(save_path, wav, target_sr, channels_first=True) # transcribe text lang, text = transcribe_one(save_path) if lang not in list(lang2token.keys()): print(f"{lang} not supported, ignoring\n") continue #text = "ZH|" + text + "\n" text = lang2token[lang] + text + "\n" speaker_annos.append(save_path + "|" + speaker + "|" + text) processed_files += 1 print(f"Processed: {processed_files}/{total_files}") except: continue
标注后,会生成切片语音对应文件:
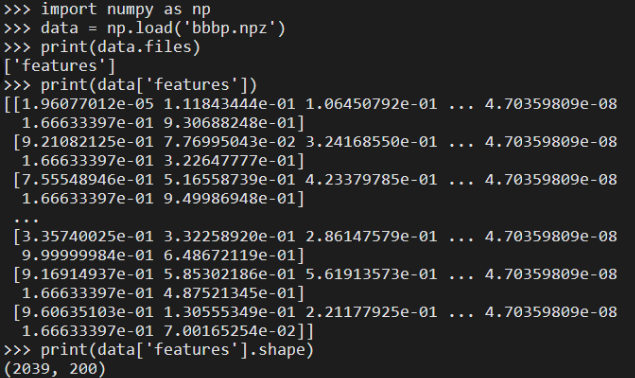
./genshin_dataset/ying/vo_dialog_DPEQ003_raidenEi_01.wav|ying|ZH|神子…臣民对我的畏惧…
./genshin_dataset/ying/vo_dialog_DPEQ003_raidenEi_02.wav|ying|ZH|我不会那么做…
./genshin_dataset/ying/vo_dialog_SGLQ002_raidenEi_01.wav|ying|ZH|不用着急,好好挑选吧,我就在这里等着。
./genshin_dataset/ying/vo_dialog_SGLQ003_raidenEi_01.wav|ying|ZH|现在在做的事就是「留影」…
./genshin_dataset/ying/vo_dialog_SGLQ003_raidenEi_02.wav|ying|ZH|嗯,不错,又学到新东西了。快开始吧。
说白了,就是通过whisper把人物说的话先转成文字,并且生成对应的音标:
./genshin_dataset/ying/vo_dialog_DPEQ003_raidenEi_01.wav|ying|ZH|神子…臣民对我的畏惧…|_ sh en z i0 … ch en m in d ui w o d e w ei j v … _|0 2 2 5 5 0 2 2 2 2 4 4 3 3 5 5 4 4 4 4 0 0|1 2 2 1 2 2 2 2 2 2 2 1 1
./genshin_dataset/ying/vo_dialog_DPEQ003_raidenEi_02.wav|ying|ZH|我不会那么做…|_ w o b u h ui n a m e z uo … _|0 3 3 2 2 4 4 4 4 5 5 4 4 0 0|1 2 2 2 2 2 2 1 1
./genshin_dataset/ying/vo_dialog_SGLQ002_raidenEi_01.wav|ying|ZH|不用着急,好好挑选吧,我就在这里等着.|_ b u y ong zh ao j i , h ao h ao t iao x van b a , w o j iu z ai zh e l i d eng zh e . _|0 2 2 4 4 2 2 2 2 0 2 2 3 3 1 1 3 3 5 5 0 3 3 4 4 4 4 4 4 3 3 3 3 5 5 0 0|1 2 2 2 2 1 2 2 2 2 2 1 2 2 2 2 2 2 2 1 1
./genshin_dataset/ying/vo_dialog_SGLQ003_raidenEi_01.wav|ying|ZH|现在在做的事就是'留影'…|_ x ian z ai z ai z uo d e sh ir j iu sh ir ' l iu y ing ' … _|0 4 4 4 4 4 4 4 4 5 5 4 4 4 4 4 4 0 2 2 3 3 0 0 0|1 2 2 2 2 2 2 2 2 1 2 2 1 1 1
./genshin_dataset/ying/vo_dialog_SGLQ003_raidenEi_02.wav|ying|ZH|恩,不错,又学到新东西了.快开始吧.|_ EE en , b u c uo , y ou x ve d ao x in d ong x i l e . k uai k ai sh ir b a
最后,将标注好的文件转换为bert模型可读文件:
import torch
from multiprocessing import Pool
import commons
import utils
from tqdm import tqdm
from text import cleaned_text_to_sequence, get_bert
import argparse
import torch.multiprocessing as mp def process_line(line): rank = mp.current_process()._identity rank = rank[0] if len(rank) > 0 else 0 if torch.cuda.is_available(): gpu_id = rank % torch.cuda.device_count() device = torch.device(f"cuda:{gpu_id}") wav_path, _, language_str, text, phones, tone, word2ph = line.strip().split("|") phone = phones.split(" ") tone = [int(i) for i in tone.split(" ")] word2ph = [int(i) for i in word2ph.split(" ")] word2ph = [i for i in word2ph] phone, tone, language = cleaned_text_to_sequence(phone, tone, language_str) phone = commons.intersperse(phone, 0) tone = commons.intersperse(tone, 0) language = commons.intersperse(language, 0) for i in range(len(word2ph)): word2ph[i] = word2ph[i] * 2 word2ph[0] += 1 bert_path = wav_path.replace(".wav", ".bert.pt") try: bert = torch.load(bert_path) assert bert.shape[-1] == len(phone) except Exception: bert = get_bert(text, word2ph, language_str, device) assert bert.shape[-1] == len(phone) torch.save(bert, bert_path)
模型训练
此时,打开项目目录中的config.json文件:
{ "train": { "log_interval": 100, "eval_interval": 100, "seed": 52, "epochs": 200, "learning_rate": 0.0001, "betas": [ 0.8, 0.99 ], "eps": 1e-09, "batch_size": 4, "fp16_run": false, "lr_decay": 0.999875, "segment_size": 16384, "init_lr_ratio": 1, "warmup_epochs": 0, "c_mel": 45, "c_kl": 1.0, "skip_optimizer": true }, "data": { "training_files": "filelists/train.list", "validation_files": "filelists/val.list", "max_wav_value": 32768.0, "sampling_rate": 44100, "filter_length": 2048, "hop_length": 512, "win_length": 2048, "n_mel_channels": 128, "mel_fmin": 0.0, "mel_fmax": null, "add_blank": true, "n_speakers": 1, "cleaned_text": true, "spk2id": { "ying": 0 } }, "model": { "use_spk_conditioned_encoder": true, "use_noise_scaled_mas": true, "use_mel_posterior_encoder": false, "use_duration_discriminator": true, "inter_channels": 192, "hidden_channels": 192, "filter_channels": 768, "n_heads": 2, "n_layers": 6, "kernel_size": 3, "p_dropout": 0.1, "resblock": "1", "resblock_kernel_sizes": [ 3, 7, 11 ], "resblock_dilation_sizes": [ [ 1, 3, 5 ], [ 1, 3, 5 ], [ 1, 3, 5 ] ], "upsample_rates": [ 8, 8, 2, 2, 2 ], "upsample_initial_channel": 512, "upsample_kernel_sizes": [ 16, 16, 8, 2, 2 ], "n_layers_q": 3, "use_spectral_norm": false, "gin_channels": 256 }
}
这里需要修改的参数是batch_size,通常情况下,数值和本地显存应该是一致的,但是最好还是改小一点,比如说一块4060的8G卡,最好batch_size是4,如果写8的话,还是有几率爆显存。
随后开始训练:
python3 train_ms.py
程序返回:
[W C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\torch\csrc\distributed\c10d\socket.cpp:601] [c10d] The client socket has failed to connect to [v3u.net]:65280 (system error: 10049 - 在其上下文中,该请求的地址无效。).
[W C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\torch\csrc\distributed\c10d\socket.cpp:601] [c10d] The client socket has failed to connect to [v3u.net]:65280 (system error: 10049 - 在其上下文中,该请求的地址无效。).
2023-10-23 15:36:08.293 | INFO | data_utils:_filter:61 - Init dataset...
100%|█████████████████████████████████████████████████████████████████████████████| 562/562 [00:00<00:00, 14706.57it/s]
2023-10-23 15:36:08.332 | INFO | data_utils:_filter:76 - skipped: 0, total: 562
2023-10-23 15:36:08.333 | INFO | data_utils:_filter:61 - Init dataset...
100%|████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:00<?, ?it/s]
2023-10-23 15:36:08.334 | INFO | data_utils:_filter:76 - skipped: 0, total: 4
Using noise scaled MAS for VITS2
Using duration discriminator for VITS2
INFO:OUTPUT_MODEL:Loaded checkpoint './logs\OUTPUT_MODEL\DUR_4600.pth' (iteration 33)
INFO:OUTPUT_MODEL:Loaded checkpoint './logs\OUTPUT_MODEL\G_4600.pth' (iteration 33)
INFO:OUTPUT_MODEL:Loaded checkpoint './logs\OUTPUT_MODEL\D_4600.pth' (iteration 33)
说明没有问题,训练日志存放在项目的logs目录下。
随后可以通过tensorboard来监控训练过程:
python3 -m tensorboard.main --logdir=logs\OUTPUT_MODEL
当loss趋于稳定说明模型已经收敛:

模型推理
最后,我们就可以使用模型来生成我们想要听到的语音了:
python3 webui.py -m ./logs\OUTPUT_MODEL\G_47700.pth
注意参数为训练好的迭代模型,如果觉得当前迭代的模型可用,那么直接把pth和config.json拷贝出来即可,随后可以接着训练下一个模型。
结语
基于Bert-vits2打造的渣渣辉和刘青云音色的鬼畜视频已经上线到Youtube(B站),请检索:刘悦的技术博客,欢迎诸君品鉴和臻赏。