卷积神经网络概述
卷积神经网络是深度学习在计算机视觉领域的突破性成果。在计算机视觉领域。往往输入的图像都很大,使用全连接网络的话,计算的代价较高。另外图像也很难保留原有的特征,导致图像处理的准确率不高。
卷积神经网络(Convolutional Neural Network)是含有卷积层的神经网络。卷积层的作用就是用来自动学习、提取图像的特征。
CNN网络主要有三部分构成:卷积层、池化层和全连接层构成,其中卷积层负责提取图像中的局部特征;池化层用来大幅降低参数量级(降维);全连接层类似人工神经网络的部分,用来输出想要的结果。
图像概述
图像是由像素点组成的,每个像素点的值范围为:[0,255],像素值越大意味着较亮。比如一张 200x200 的图像,则是由 40000 个像素点组成,如果每个像素点都是 0 的话,意味着这是一张全黑的图像。
彩色图一般都是多通道的图像,所谓多通道可以理解为图像由多个不同的图像层叠加而成,例如看到的彩色图像一般都是由 RGB 三个通道组成的,还有一些图像具有 RGBA 四个通道,最后一个通道为透明通道,该值越小,则图像越透明。
卷积层
卷积计算
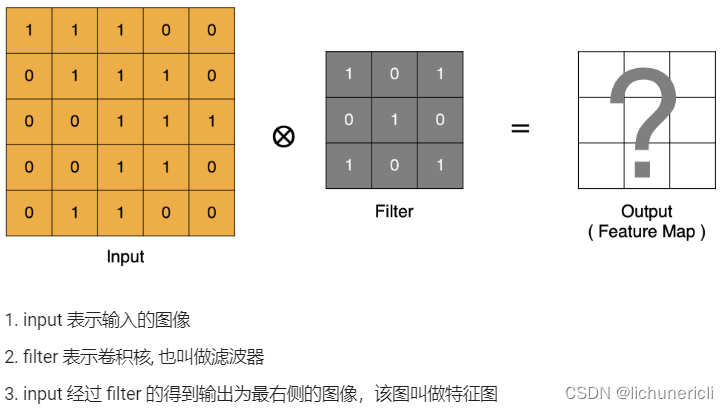
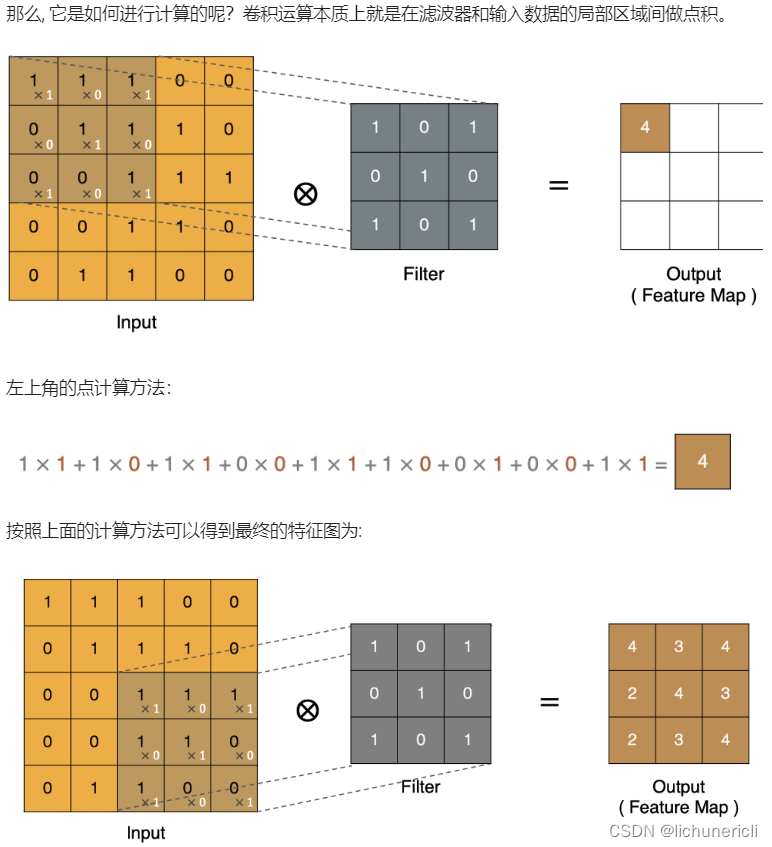
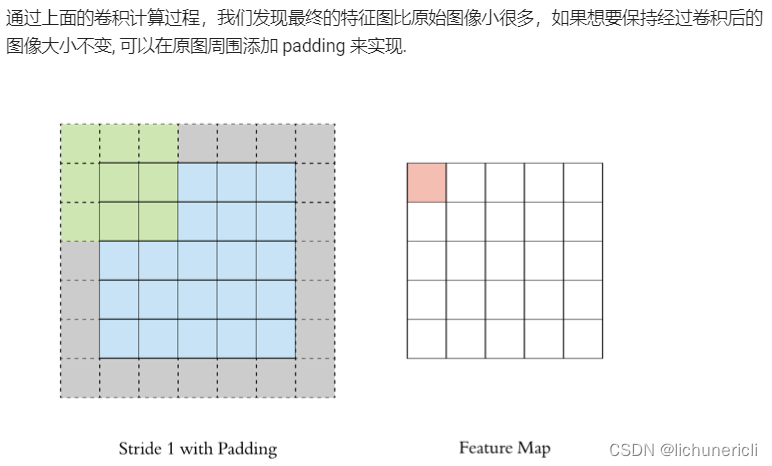
Padding
Stride
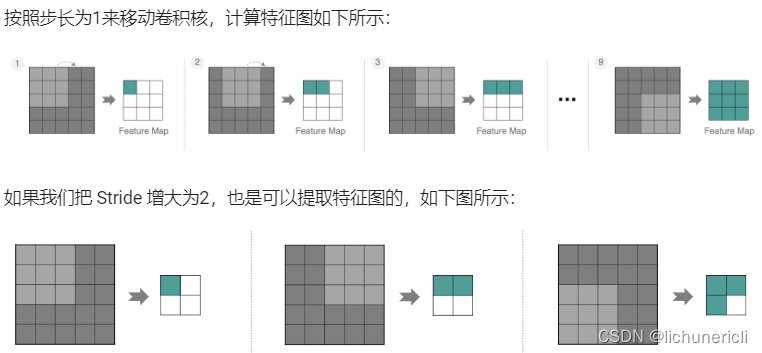
多通道卷积计算
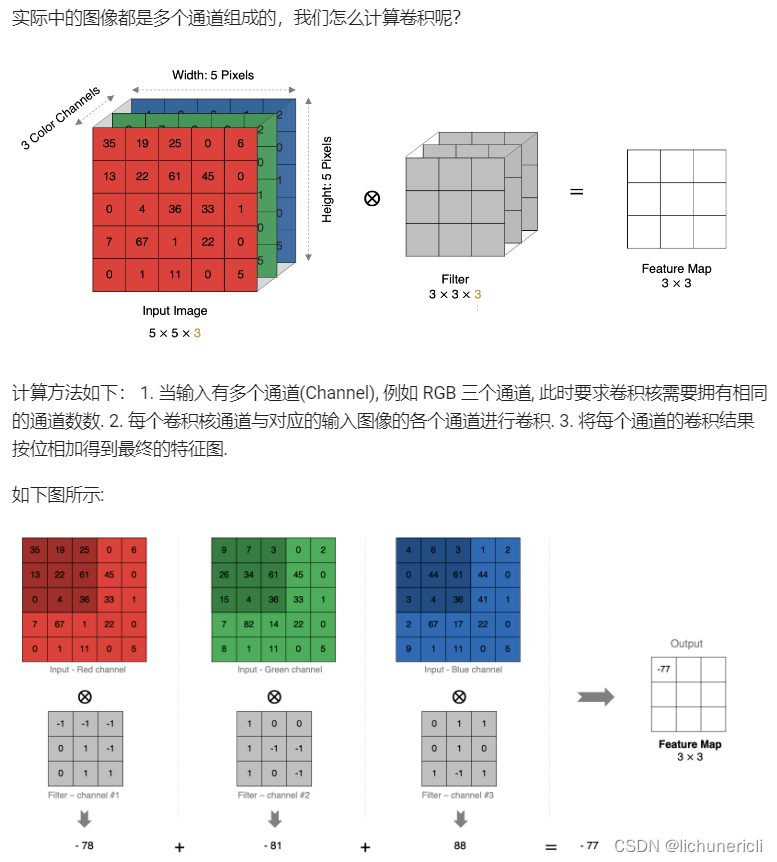
多卷积核卷积计算
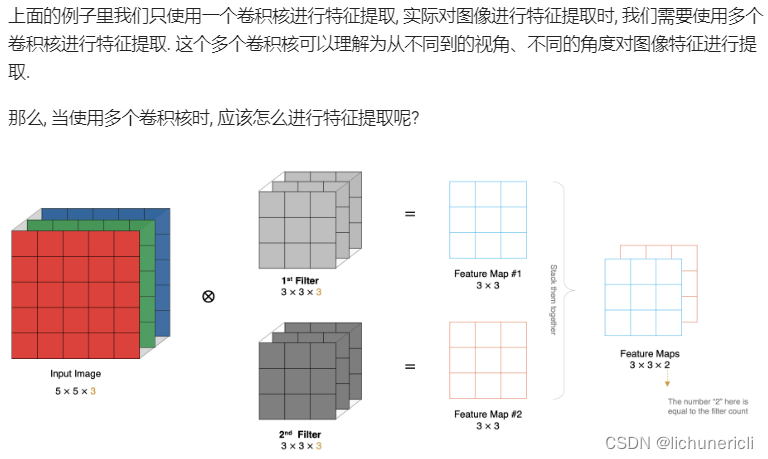
特征图大小

池化层
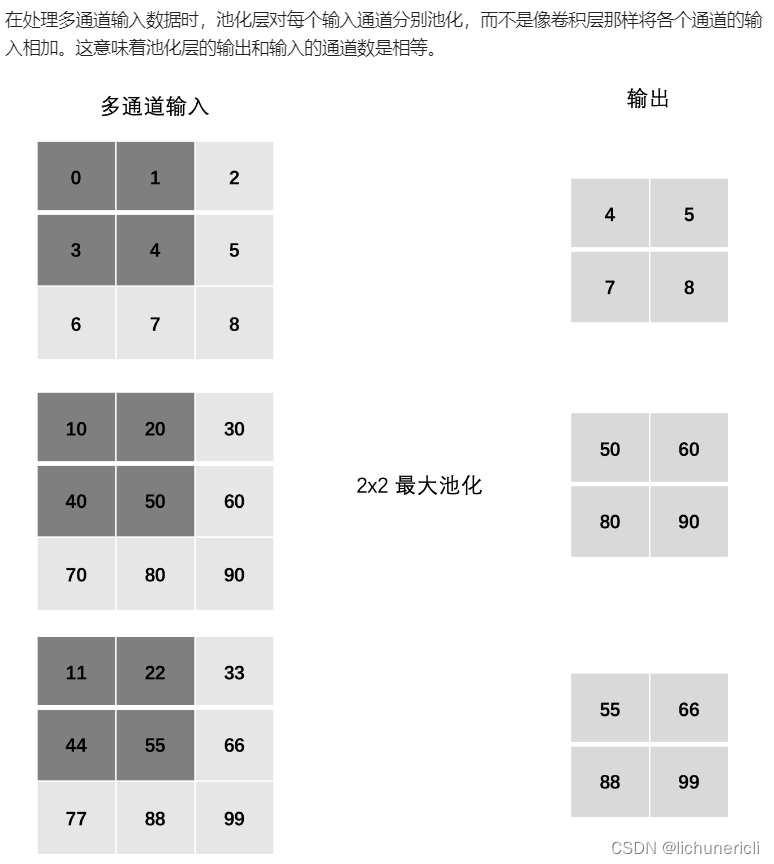
池化层 (Pooling) 降低维度,缩减模型大小,提高计算速度。即:主要对卷积层学习到的特征图进行下采样(SubSampling)处理。池化层主要有两种:最大池化、平均池化。
池化层计算
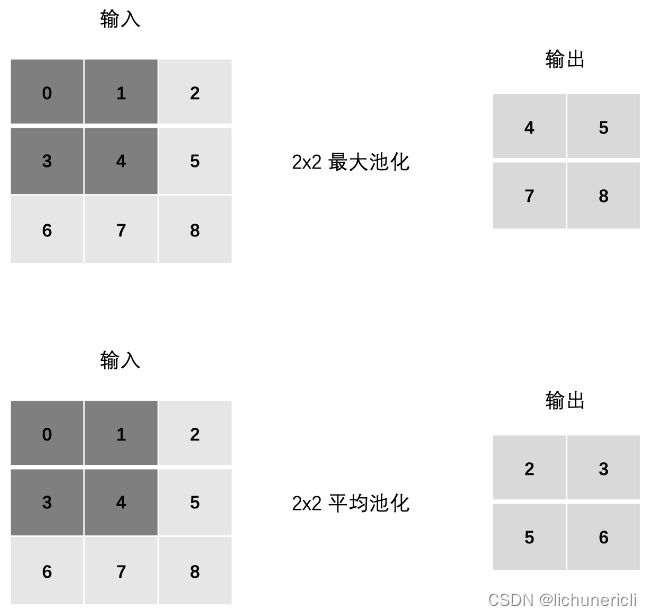
Stride
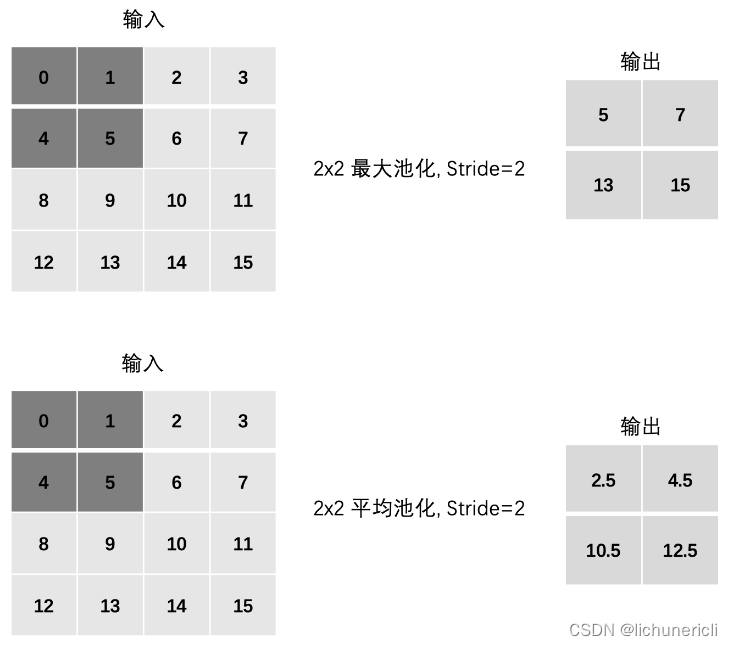
Padding
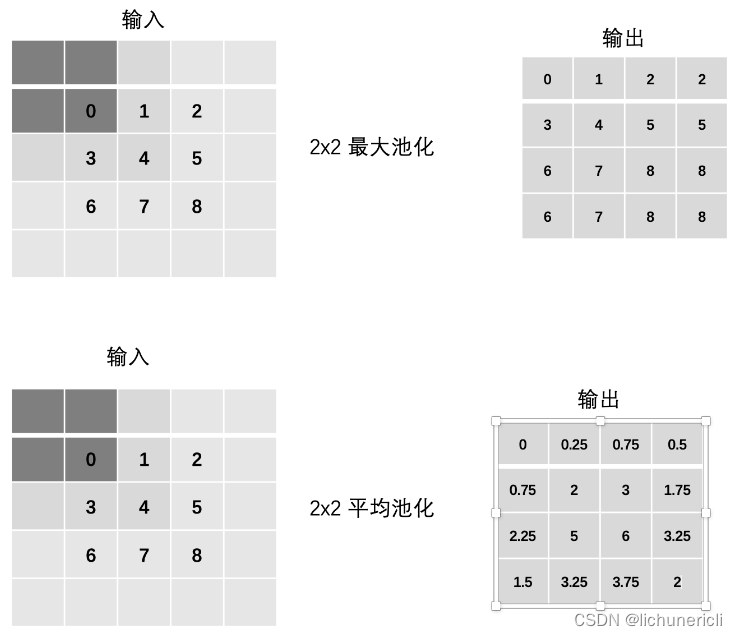
多通道池化计算
案例-图像分类
CIFAR10 数据集
from torchvision.datasets import CIFAR10
from torchvision.transforms import Compose
from torchvision.transforms import ToTensor
from torch.utils.data import DataLoader# 1. 数据集基本信息
def test01():# 加载数据集train = CIFAR10(root='data', train=True, transform=Compose([ToTensor()]))valid = CIFAR10(root='data', train=False, transform=Compose([ToTensor()]))# 数据集数量print('训练集数量:', len(train.targets))print('测试集数量:', len(valid.targets))# 数据集形状print("数据集形状:", train[0][0].shape)# 数据集类别print("数据集类别:", train.class_to_idx)# 2. 数据加载器
def test02():train = CIFAR10(root='data', train=True, transform=Compose([ToTensor()]))dataloader = DataLoader(train, batch_size=8, shuffle=True)for x, y in dataloader:print(x.shape)print(y)breakif __name__ == '__main__':test01()test02()搭建图像分类网络
class ImageClassification(nn.Module):def __init__(self):super(ImageClassification, self).__init__()self.conv1 = nn.Conv2d(3, 6, stride=1, kernel_size=3)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(6, 16, stride=1, kernel_size=3)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.linear1 = nn.Linear(576, 120)self.linear2 = nn.Linear(120, 84)self.out = nn.Linear(84, 10)def forward(self, x):x = F.relu(self.conv1(x))x = self.pool1(x)x = F.relu(self.conv2(x))x = self.pool2(x)# 由于最后一个批次可能不够 32,所以需要根据批次数量来 flattenx = x.reshape(x.size(0), -1)x = F.relu(self.linear1(x))x = F.relu(self.linear2(x))return self.out(x)编写训练函数
使用多分类交叉熵损失函数,Adam 优化器:
def train():# 加载 CIFAR10 训练集, 并将其转换为张量transgform = Compose([ToTensor()])cifar10 = torchvision.datasets.CIFAR10(root='data', train=True, download=True, transform=transgform)# 构建图像分类模型model = ImageClassification()# 构建损失函数criterion = nn.CrossEntropyLoss()# 构建优化方法optimizer = optim.Adam(model.parameters(), lr=1e-3)# 训练轮数epoch = 100for epoch_idx in range(epoch):# 构建数据加载器dataloader = DataLoader(cifar10, batch_size=BATCH_SIZE, shuffle=True)# 样本数量sam_num = 0# 损失总和total_loss = 0.0# 开始时间start = time.time()correct = 0for x, y in dataloader:# 送入模型output = model(x)# 计算损失loss = criterion(output, y)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 参数更新optimizer.step()correct += (torch.argmax(output, dim=-1) == y).sum()total_loss += (loss.item() * len(y))sam_num += len(y)print('epoch:%2s loss:%.5f acc:%.2f time:%.2fs' %(epoch_idx + 1,total_loss / sam_num,correct / sam_num,time.time() - start))# 序列化模型torch.save(model.state_dict(), 'model/image_classification.bin')编写预测函数
def test():# 加载 CIFAR10 测试集, 并将其转换为张量transgform = Compose([ToTensor()])cifar10 = torchvision.datasets.CIFAR10(root='data', train=False, download=True, transform=transgform)# 构建数据加载器dataloader = DataLoader(cifar10, batch_size=BATCH_SIZE, shuffle=True)# 加载模型model = ImageClassification()model.load_state_dict(torch.load('model/image_classification.bin'))model.eval()total_correct = 0total_samples = 0for x, y in dataloader:output = model(x)total_correct += (torch.argmax(output, dim=-1) == y).sum()total_samples += len(y)print('Acc: %.2f' % (total_correct / total_samples))总结
可以从以下几个方面来调整网络:
- 增加卷积核输出通道数
- 增加全连接层的参数量
- 调整学习率
- 调整优化方法
- 修改激活函数
- 等等...
把学习率由 1e-3 修改为 1e-4,并网络参数量增加如下代码所示:
class ImageClassification(nn.Module):def __init__(self):super(ImageClassification, self).__init__()self.conv1 = nn.Conv2d(3, 32, stride=1, kernel_size=3)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(32, 128, stride=1, kernel_size=3)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.linear1 = nn.Linear(128 * 6 * 6, 2048)self.linear2 = nn.Linear(2048, 2048)self.out = nn.Linear(2048, 10)def forward(self, x):x = F.relu(self.conv1(x))x = self.pool1(x)x = F.relu(self.conv2(x))x = self.pool2(x)# 由于最后一个批次可能不够 32,所以需要根据批次数量来 flattenx = x.reshape(x.size(0), -1)x = F.relu(self.linear1(x))x = F.dropout(x, p=0.5)x = F.relu(self.linear2(x))x = F.dropout(x, p=0.5)return self.out(x)