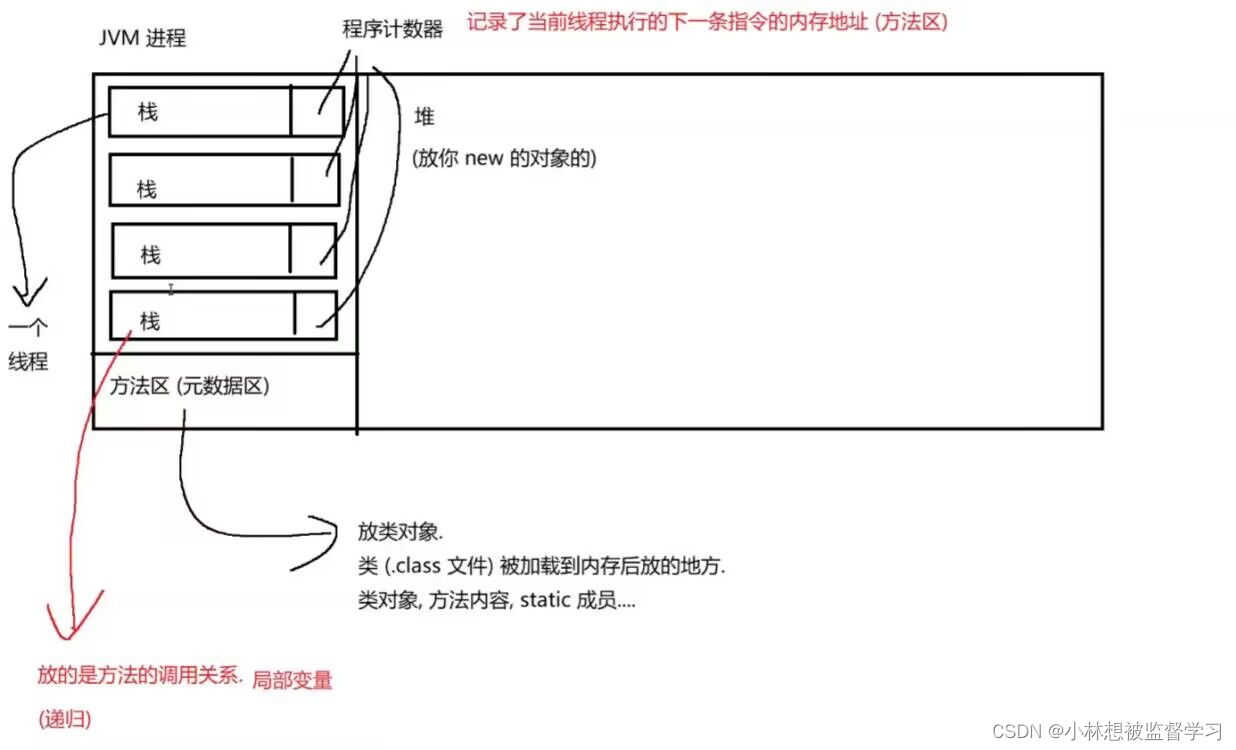
JVM的内存区域划分
JVM类加载机制
前言
Java程序最开始是一个 .java 的文件,JVM把它编译成 .closs 文件(字节码文件),运行 Java 程序, JVM 就会读取 .class 文件,把文件内容读取到内存中,构造出一个 .class 对象(类对象)
1.加载
JVM 加载 .class 文件的时候需要用到 “类加载器模块” ,JVM 中自带了三个类加载器模块
分别是,Bootstrap ClassLoader(负责加载标准库中的类)
Extension ClassLoader(负责加载 JVM 扩展的库)
Application ClassLoader(负责加载第三方库)
三个类加载器的优先级由高到低
要加载 .class 文件,我们就需要先找到 .class 文件,此时我们就涉及到双亲委派模型
什么是双亲委派模型
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载。
假设我们现在需要加载一个 .class 文件,此时类加载的请求就会传给 Application ClassLoader (负责加载第三方库),但 Application ClassLoader 不会直接就尝试寻找并加载 .class 文件,而是把这个请求发送给自己的父类 Extension ClassLoader(负责加载 JVM 扩展的库),同理 Extension ClassLoader 也会把类加载的请求传给 Bootstrap ClassLoader(负责加载标准库中的类) , Bootstrap ClassLoader 没有父类了,才会真正的去搜索 .class 文件,并加载到内存中,如果 Bootstrap ClassLoader 没有查找到 .class 文件,就将类加载的请求传回给子类 Extension ClassLoader 进行加载,同理,要是 Extension ClassLoader 没有查找到 .class 文件,也会将类加载的请求传回给子类 Application ClassLoader 进行加载,经过这段流程的寻找,一般就能找到对应的 .class 文件
2.验证
找到 .class 文件以后还需要验证 .class 文件的格式是否符合约束要求
3.准备
准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置类变量初始值 的阶段。
4.解析
解析阶段是 Java 虚拟机将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程。
5.初始化
初始化阶段,Java 虚拟机真正开始执行类中编写的 Java 程序代码,将主导权移交给应用程序。初始化 阶段就是执行类构造器方法的过程。
类在什么时候被加载
懒汉模式,用到了才加载
1.构造类的实例
2.使用了类的静态方法,静态属性
3.子类的加载会触发父类
类加载了以后,后面就不必再次加载了
JVM垃圾回收机制
很多编程语言都有垃圾回收的机制,Java也不例外,垃圾回收机制可以自动的将不再使用的对象进行销毁,释放对象所占用的内存空间
在 JVM 的内存区域划分中,我们进行垃圾回收的主要位置是堆,因为栈和计数器是和线程共存亡的,当线程结束以后便会自动释放栈和计数器所占的内存,而我们实例化的对象都是放到堆中的
进行垃圾回收,首先我们需要考虑哪些对象是死亡对象(垃圾),当一个对象没有被引用指向的时候,我们就可以认为这个对象是死亡对象,因为这个对象用户已经无法访问到它了
死亡对象的判断算法
1.引用计数算法
引用计数描述的算法为: 给对象增加一个引用计数器,每当有一个地方引用它时,计数器就+1;当引用失效时,计数器就-1;任 何时刻计数器为0的对象就是不能再被使用的,即对象已"死"。 引用计数法实现简单,判定效率也比较高,在大部分情况下都是一个不错的算法。比如Python语言就采 用引用计数法进行内存管理。 但是,在主流的JVM中没有选用引用计数法来管理内存,最主要的原因就是引用计数法无法解决对象的 循环引用问题
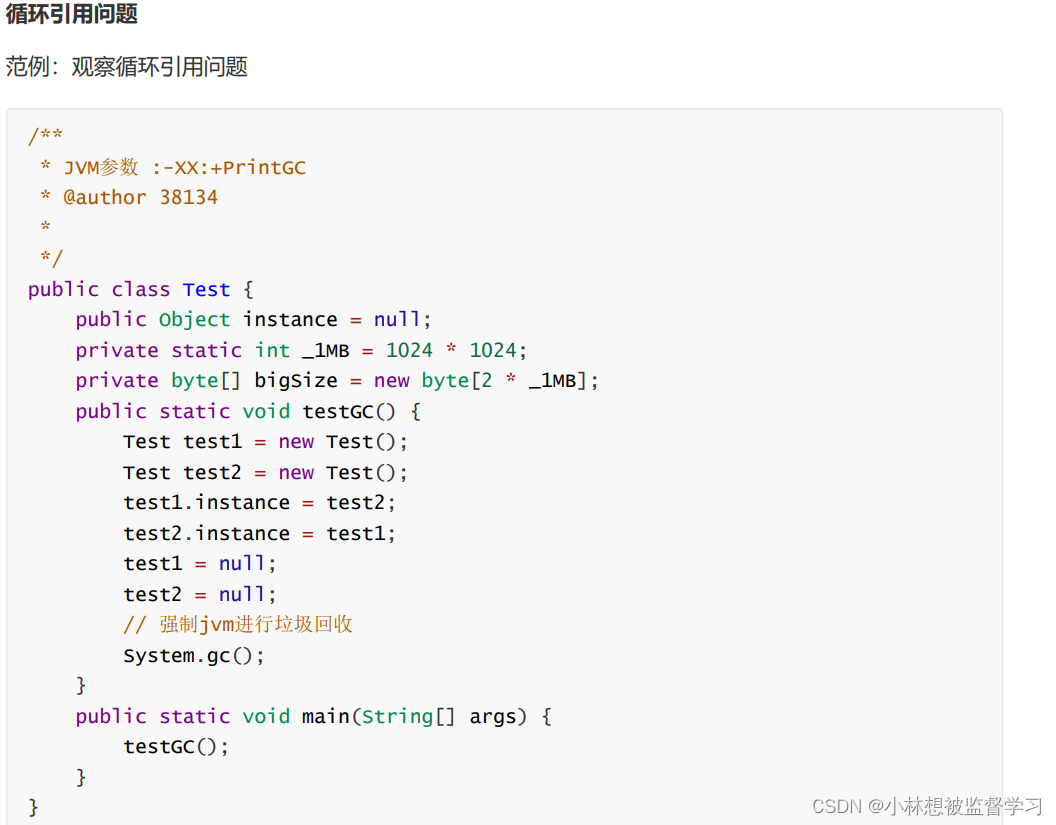
2.可达性分析(Java中实际采取的方案)
JVM 首先会遍历代码中所有的引用,根据引用找到对应的对象,将能通过引用访问到的对象标记成可达,完成整个遍历以后,没有被标记成可达的对象,也就是不可达,就相当于是垃圾了
在分析完哪些对象是垃圾对象以后,我们就需要将这些垃圾对象进行回收,回收有以下的几种算法
垃圾回收
1.直接释放
直接释放对象,很简单干脆,但是存在内存碎片问题
因为在申请内存的时候,都是申请的连续的内存空间,直接释放内存的话就会破坏原有的连续性,产生内存碎片,随着程序运行得越来越多,内存碎片也会越来越多,越来越碎,这样就会出现明明有内存但是无法申请的情况,这是一个很严重的问题
2.复制算法
把一个内存分两份,用一份丢一份(用双倍的空间来存储对象),存储对象的时候用两倍的空间存储,一开始将对象统一存放在左边的空间,当要进行垃圾回收的时候,就将不需要回收的对象复制到右边,然后再将左边的内存全部释放,下一次进行垃圾回收就将复制到左边,把右边的内存全部释放,这样就能解决内存碎片问题
但是,该算法会浪费一半的空间,而且要频繁进行对象的复制,会大大影响效率
3.分代算法(GC)(当前JVM采用)
当前 JVM 垃圾收集都采用的是"分代收集(Generational Collection)"算法,这个算法并没有新思想,只 是根据对象存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代。在新生代中,每 次垃圾回收都有大批对象死去,只有少量存活,因此我们采用复制算法;而老年代中对象存活率高、没 有额外空间对它进行分配担保,就必须采用"标记-清理"或者"标记-整理"算法。
将整个堆分为三个部分:1.新生代,2.幸存区,3.老年代
JVM 会周期性的遍历三个部分中的对象
一开始创建的对象放到新生代,遍历新生代中的对象,将垃圾对象进行释放(大多数的对象活不过第一轮GC遍历),不是垃圾对象的就复制到幸存区中
幸存区分为两个部分,采用的是复制算法,在幸存区经过多轮GC遍历还没有成为垃圾对象被回收的对象就会被复制到老年代,老年代中的对象是不容易被回收的对象,所以进行GC遍历的频率也较低