PostgreSQL 提供了丰富的数据库内核编程接口,允许开发者在不修改任何 Postgres 核心代码的情况下以插件的形式将自己的代码融入内核,扩展数据库功能。本文探究了 PostgreSQL 插件的一般源码组成,梳理插件的源码内容和实现方式;并介绍了 PostgreSQL 内核源码中处理 CREATE EXTENSION 创建插件的实现原理。
01 PostgreSQL 插件源码组成
PostgreSQL 中运行 CREATE EXTENSION 命令创建指定插件,最少需要两个文件:
- 插件控制文件 extension_name.control:这个文件必须放置在 PostgreSQL 安装目录中的
$PGHOME/share/postgresql/extension目录下,该文件的后缀必须为 .control且文件名与插件名称相同。 - SQL 脚本文件 extension_name–version.sql:一个插件至少有一个或多个 SQL 脚本文件,这些文件通常也放在 PostgreSQL 安装目录中的
$PGHOME/share/postgresql/extension目录下,但是可以通过控制文件可以为脚本文件指定不同的目录,这些文件的名称由插件名称和插件版本两个部分组成。
实现复杂功能的插件还有实现具体功能的源码文件,通常是 .c 文件,这些文件包含了插件功能实现的实际代码。这些源码文件通过 Makefile 文件使用 make 工具编译成动态库文件 extension_name.so,这个动态库文件名称通常也与插件名称一致,
最后,Makefile 文件中根据安装选择配置,将上述提到的三种文件复制到 PostgreSQL 指定的目录下完成安装过程。
下面,我们以 pg_qualstats 插件(pg_qualstats:https://github.com/powa-team/pg_qualstats 用于收集和展示查询语句的 WHERE 和 JOIN 等过滤条件相关的统计信息)为例详细了解一下插件中必有的控制文件、SQL 脚本文件和 Makefile 文件中的具体内容:
1.1 控制文件 control
PostgreSQL 插件的 control 文件是一个文本文件,用于描述插件的元数据信息和安装过程中的操作;这个文件必须要位于插件的根目录下,并且后缀必须命名为 control。
pg_qualstats.control 文件的内容如下,包括描述插件的作用和用途的 comment;指定插件默认版本号的 default_version;和指定插件的共享库文件路径和名称的 module_pathname;以及指定插件是否可以在不同的 PostgreSQL 安装路径下运行的 relocatable。
comment = 'An extension collecting statistics about quals'
default_version = '2.1.0'
module_pathname = '$libdir/pg_qualstats'
relocatable = false
除了上面这些字段,control 文件还有如下字段用于设置插件元数据信息:
- directory:指定插件的安装目录;默认情况下,插件会被安装到
$PGHOME/share/postgresql/extension目录下;如果需要安装到其他目录,可以通过这个参数进行设置。- default_version:指定插件的默认版本号;如果没有指定版本号,则默认为 1.0。
- comment:插件的注释信息,用于描述插件的作用和用途。
- encoding:指定插件的编码格式;默认情况下,插件会使用数据库的编码格式;如果需要使用其他编码格式,可以通过这个参数进行设置。
- module_pathname:指定插件的共享库文件路径和名称。
- requires:指定插件所依赖的其他插件。
- superuser:指定可以安装和卸载插件的超级用户;默认情况下,只有超级用户可以安装和卸载插件;如果需要允许其他用户进行安装和卸载操作,可以通过这个参数进行设置。
- relocatable:指定插件是否可以在不同的 PostgreSQL 安装路径下运行。
- schema:指定插件的安装模式,默认使用 public 模式。
1.2 SQL 脚本文件
插件的 sql 脚本是插件的核心部分,它定义了插件的功能和行为;用户可以根据插件的 sql 脚本来了解插件的使用方法和功能,以及如何集成插件到自己的应用程序中。
例如 pg_qualstats--2.1.0.sql 文件的内容包括该插件所需函数和视图的声明
-- complain if script is sourced in psql, rather than via CREATE EXTENSION
\echo Use "CREATE EXTENSION pg_qualstats" to load this file. \quitCREATE FUNCTION @extschema@.pg_qualstats_reset()
RETURNS void
AS 'MODULE_PATHNAME'
LANGUAGE C;CREATE FUNCTION @extschema@.pg_qualstats_example_query(bigint)
RETURNS text
AS 'MODULE_PATHNAME'
LANGUAGE C;
通常 PostgreSQL 插件的 sql 脚本一般包含以下内容:
- 创建插件所需的表、函数、视图等对象:这些对象是插件的核心功能实现,是插件的主要部分。
- 创建插件所需的配置项:插件通常需要一些配置项来控制其行为,例如日志级别、缓存大小等;这些配置项可以通过
ALTER SYSTEM或ALTER DATABASE命令进行设置。- 创建插件所依赖的其他插件:插件的 sql 脚本可以使用
CREATE EXTENSION命令方便地加载和卸载其他插件。- 提供一些示例代码:插件的 sql 脚本通常会提供一些示例代码,以便用户可以更好地理解插件的使用方法和功能;这些示例代码通常包含一些 SQL 查询语句,用于演示插件的使用方法和效果。
1.3 makefile 与动态库文件
实现复杂功能的插件通常还会有实现具体功能的源码文件,这些源码文件通过 Makefile 文件使用 make 工具编译成动态库文件 extension_name.so,并与其他文件一起安装到 postgresql 中。
例如,pg_qualstats.c 文件中就是使用 C 语言编码,实现了大量复杂功能处理逻辑。
Makefile 文件除了进行源码文件的编译工作,还会配置其他的查询编译安装选项
例如,pg_qualstats 插件中的 Makefile 文件中,EXTENSION 字段指定额插件的名称;MODULES 指定需要编译的插件源码文件;PG_CONFIG 指定了 PostgreSQL 的 pg_config 命令的路径;DATA 则是指定需要安装的插件数据文件的名称;PGXS 指定 PostgreSQL 扩展构建系统的路径。
EXTENSION = pg_qualstats
EXTVERSION = $(shell grep default_version $(EXTENSION).control | sed -e "s/default_version[[:space:]]*=[[:space:]]*'\([^']*\)'/\1/")
TESTS = $(wildcard test/sql/*.sql)
REGRESS = $(patsubst test/sql/%.sql,%,$(TESTS))
REGRESS_OPTS = --inputdir=test
MODULES = $(patsubst %.c,%,$(wildcard *.c))
PG_CONFIG ?= pg_configall:release-zip: allgit archive --format zip --prefix=pg_qualstats-$(EXTVERSION)/ --output ./pg_qualstats-$(EXTVERSION).zip HEADunzip ./pg_qualstats-$(EXTVERSION).ziprm ./pg_qualstats-$(EXTVERSION).zipsed -i -e "s/__VERSION__/$(EXTVERSION)/g" ./pg_qualstats-$(EXTVERSION)/META.jsonzip -r ./pg_qualstats-$(EXTVERSION).zip ./pg_qualstats-$(EXTVERSION)/rm ./pg_qualstats-$(EXTVERSION) -rfDATA = $(wildcard *--*.sql)
PGXS := $(shell $(PG_CONFIG) --pgxs)
include $(PGXS)
除了上面介绍的字段,插件的 Makefile 文件还有如下字段用于配置插件编译安装选项:
- EXTENSION:指定插件的名称;使用 CREATE EXTENSION 命令安装插件时,使用该名称引用插件。
- EXTVERSION:指定插件的版本号;使用 CREATE EXTENSION 命令安装插件时,则该版本号将与插件关联。
- REGRESS:指定需要运行的插件测试脚本文件。
- REGRESS_OPTS:指定运行插件测试时的选项;例如,可以使用 -k 选项指定只运行包含特定关键字的测试用例。
- TESTS:指定需要运行的插件测试文件;与 REGRESS 不同的是,TESTS 不包括插件的初始化和清理过程。
- MODULES:指定需要编译的插件源码文件。
- PG_CONFIG:指定 PostgreSQL 的 pg_config 命令的路径。
- DATA:指定需要安装的插件数据文件。
- DOCS:指定需要安装的插件文档文件的名称。
- PGXS:指定 PostgreSQL 扩展构建系统的路径。
- CFLAGS:指定 C 编译器的选项。
02 实现一个简单的插件
为了更好的理解,PostgreSQL 插件的实现方式,这里给出一个简单的插件实现 demo 更好地体会插件实现与安装过程
我们创建一个名为 char_count 的简单插件,该插件的功能是计算给定字符串的指定字符的数量。该插件提供了一个函数 char_count(TEXT, CHAR),这个函数有两个输入参数,第一个是字符串,第二个是需要统计数量的字符;函数的返回值是一个整数,表示字符串中所需字符的出现次数。
2.1 使用 plpqsql 实现插件
使用 CREATE EXTENSION 创建插件地最基础构成是上一节说明地三个文件:控制文件,SQL 脚本文件和 Makefile 文件
下面我们分别实现这三个文件:
(1)控制文件 char_count.control
首先编写控制文件,主要设置了 comment,default_version,module_pathname 和 relocatable 四个选项
#char_count extension
comment = 'function to count number of specified characters'
default_version = '1.0'
module_pathname = '$libdir/char_count'
relocatable = true
(2)SQL 脚本文件 char_count–1.0.sql
SQL 脚本文件的命名中注意与插件名称和版本一致,脚本中主要定义了 char_count(TEXT, CHAR) 这个函数,这个函数有两个输入参数,第一个 TEXT 是目标字符串,第二个 CHAR 是需要统计数量的字符;函数的返回值 charCount 是一个整数,表示字符串中指定字符的出现次数。
\echo Use "CREATE EXTENSION char_count" to load this file. \quitCREATE OR REPLACE FUNCTION char_count(TEXT, CHAR) RETURNS INTEGER AS $$
DECLAREcharCount INTEGER := 0;i INTEGER := 0;inputText TEXT := $1;targetChar CHAR := $2;
BEGIN
WHILE i <= length(inputText) LOOPIF substring( inputText from i for 1) = targetChar THENcharCount := charCount + 1;END IF;i := i + 1;END LOOP;RETURN(charCount);
END;
$$ LANGUAGE plpgsql;
(3)Makefile
Makefile 文件中我们指定了几个关键的字段,插件名称 EXTENSION,DATA 指定需要安装的 SQL 脚本文件,PG_CONFIG 和 PGXS分别指定当前 pg 安装的 pg_config 命令路径与插件构建所需的系统路径。
EXTENSION = char_count
DATA = char_count--1.0.sql
PGFILEDESC = "char_count - count number of specified character"
REGRESS = char_countifdef USE_PGXS
PG_CONFIG = pg_config
PGXS := $(shell $(PG_CONFIG) --pgxs)
include $(PGXS)
else
subdir = contrib/char_count
top_builddir = ../..
include $(top_builddir)/src/Makefile.global
include $(top_srcdir)/contrib/contrib-global.mk
endif
完成基本文件准备之后,一个插件就写完了,现在我们来安装这个简单的插件
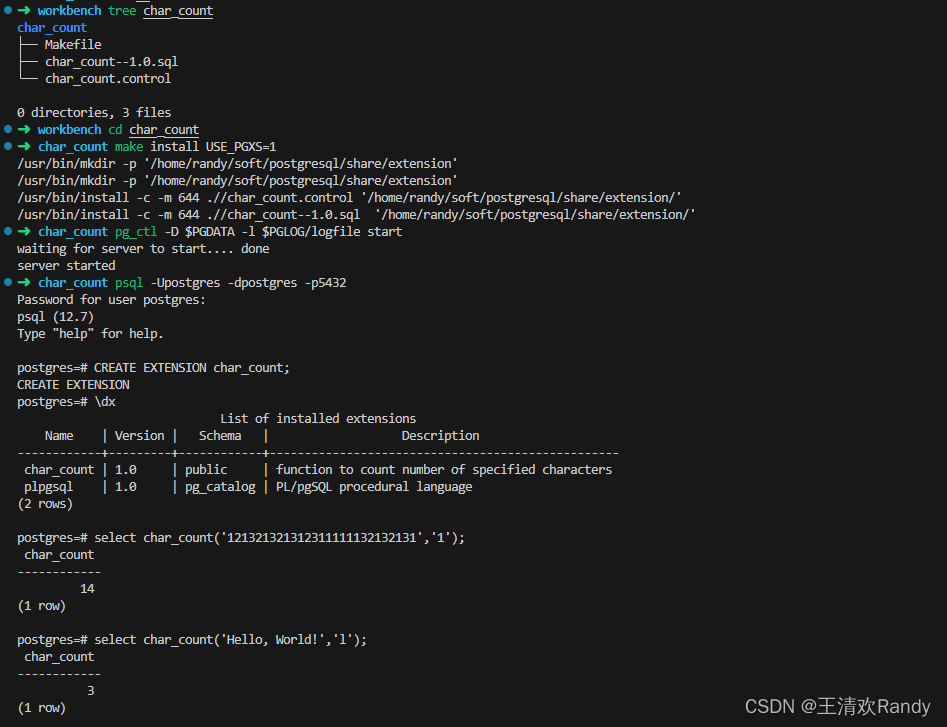
$ tree char_count
char_count
├── Makefile
├── char_count--1.0.sql
└── char_count.control0 directories, 3 files
$ cd char_count
$ make install USE_PGXS=1
/usr/bin/mkdir -p '/home/randy/soft/postgresql/share/extension'
/usr/bin/mkdir -p '/home/randy/soft/postgresql/share/extension'
/usr/bin/install -c -m 644 .//char_count.control '/home/randy/soft/postgresql/share/extension/'
/usr/bin/install -c -m 644 .//char_count--1.0.sql '/home/randy/soft/postgresql/share/extension/'
$ pg_ctl -D $PGDATA -l $PGLOG/logfile start
waiting for server to start.... done
server started
$ psql -Upostgres -dpostgres -p5432
Password for user postgres:
psql (12.7)
Type "help" for help.postgres=# CREATE EXTENSION char_count;
CREATE EXTENSION
postgres=# \dxList of installed extensionsName | Version | Schema | Description
------------+---------+------------+--------------------------------------------------char_count | 1.0 | public | function to count number of specified charactersplpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(2 rows)postgres=# select char_count('121321321312311111132132131','1');char_count
------------14
(1 row)postgres=# select char_count('Hello, World!','l');char_count
------------3
(1 row)
这个简单插件的安装使用过程如下,确保 pg_config 的路径被配置到系统环境变量中之后,我们使用 make install 命令安装该插件
然后使用 psql 登陆到 postgres 之后使用 CREATE EXTENSION 命令创建插件 char_count;之后就可以直接使用 SQL 语句调用 char_count(TEXT, CHAR) 函数了
2.2 使用 C 语言实现插件
上面我们使用 SQL 语句直接在 SQL 脚本中实现了 char_count(TEXT, CHAR) 函数,我们也可以使用 C 语言实现函数功能,然后在 SQL 脚本文件中声明该函数,这也是 PostgreSQL 实现插件更加常见的方式
使用 C 语言实现插件,我们需要对上面的实现过程做如下修改:
- 添加 C 语言源码文件
char_count.c - 修改
char_count.control控制文件,仅声明函数 - 修改 Makefile 文件添加 MODULES 指定源码文件
首先,我们添加 char_count.c 源码文件内容如下,实现字符计数功能
#include "postgres.h"
#include "fmgr.h"
#include "utils/builtins.h"PG_MODULE_MAGIC;PG_FUNCTION_INFO_V1(char_count);Datum
char_count(PG_FUNCTION_ARGS)
{int charCount = 0;int i = 0;text * inputText = PG_GETARG_TEXT_PP(0);text * targetChar = PG_GETARG_TEXT_PP(1);int inputText_sz = VARSIZE(inputText)-VARHDRSZ;int targetChar_sz = VARSIZE(targetChar)-VARHDRSZ;char * cp_inputText = NULL;char * cp_targetChar = NULL;if ( targetChar_sz > 1 ){elog(ERROR, "arg1 must be 1 char long");}cp_inputText = (char *) palloc ( inputText_sz + 1);cp_targetChar = (char *) palloc ( targetChar_sz + 1);memcpy(cp_inputText, VARDATA(inputText), inputText_sz);memcpy(cp_targetChar, VARDATA(targetChar), targetChar_sz);elog(INFO, "arg0 length is %d, value %s", (int)strlen(cp_inputText), cp_inputText );elog(INFO, "arg1 length is %d, value %s", (int)strlen(cp_targetChar), cp_targetChar );while ( i < strlen(cp_inputText) ){if( cp_inputText[i] == cp_targetChar[0] )charCount++;i++;}pfree(cp_inputText);pfree(cp_targetChar);PG_RETURN_INT32(charCount);
}
然后,修改 char_count.control 控制文件,仅声明 char_count 函数
\echo Use "CREATE EXTENSION char_count" to load this file. \quit
CREATE FUNCTION char_count_c(TEXT, CHAR) RETURNS INTEGER
AS '$libdir/char_count'
LANGUAGE C IMMUTABLE STRICT
最后,修改 Makefile 文件添加 MODULES 指定源码文件
EXTENSION = char_count
DATA = char_count--1.0.sql
PGFILEDESC = "char_count - count number of specified character"
REGRESS = char_count
MODULES = char_countifdef USE_PGXS
PG_CONFIG = pg_config
PGXS := $(shell $(PG_CONFIG) --pgxs)
include $(PGXS)
else
subdir = contrib/char_count
top_builddir = ../..
include $(top_builddir)/src/Makefile.global
include $(top_srcdir)/contrib/contrib-global.mk
endif
因为,增加了源码文件,所以在安装过程中,我们需要使用 make 命令将源码文件编译为动态库文件 char_count.so;然后再使用 make install 命令将控制文件 char_count.control 和脚本文件 char_count--1.0.sql 复制到 $PGHOME/share/postgresql/extension 目录,将 char_count.so 文件复制到 $PGHOME/lib 目录下
cd char_count
make && make install
03 PostgreSQL 创建插件实现原理
PostgreSQL 内核中使用 CREATE EXTENSION 创建插件时,首先,会解析插件的控制文件,取出需要执行的 sql 脚本版本号,同时根据控制文件的插件元数据信息创建 extension_oid 一起存入到系统表 pg_extension 中。
然后,通过解析并执行相对应的 sql 脚本文件,完成插件所需的视图和函数等内容的创建。如果使用的是源码文件创建的函数,在调用 CREATE FUNCTION 创建函数时,会通过加载插件动态库 so 文件来调用具体函数。
下面,通过控制文件处理过程,SQL 脚本文件路径查找过程和动态库函数调用过程三个部分详细介绍创建插件实现原理。
3.1 控制文件处理过程
PostgreSQL 中使用 CREATE EXTENSION 创建插件时控制文件的处理过程如下图所示:
ProcessUtilitySlow 函数解析到的 SQL 命令是 CREATE EXTENSION 时,就会调用 CreateExtension 函数执行具体插件创建过程;
该过程中使用 read_extension_control_file 和 parse_extension_control_file 两个函数读取并解析插件控制文件中的信息,通常包括扩展的名称、版本、依赖关系等;
然后,调用 InsertExtensionTuple 函数将控制文件中包含的插件元数据信息插入到系统表 pg_extension 中;
接着,调用 execute_extension_script 和 execute_sql_string 函数,根据获取到的 SQL 脚本路径,读取并执行 SQL 脚本;执行过程与 PostgreSQL 中一般的查询处理过程一致:
- 调用 pg_parse_query 将 sql 转换成 parsetree_list;
- 执行 pg_analyze_and_rewrite 对 SQL 脚本进行解析和重写;
- 调用 pg_plan_queries() 函数生成查询计划;
- 调用 ExecutorRun 对每一个 parse tree 进行执行。

上述过程中各函数作用的具体说明如下:
- ProcessUtilitySlow():处理 SQL 命令的函数,它会对传入的SQL命令进行解析和执行;如果 SQL 命令是创建插件的命令,就会调用CreateExtension() 函数执行相关逻辑。
- CreateExtension():解析 SQL 命令中的插件信息,然后调用 CreateExtensionInternal() 函数进行实际的创建操作。
- CreateExtensionInternal():读取插件控制文件中的信息,然后插入插件元组到 pg_extension 表中,最后执行插件脚本。
- read_extension_control_file():读取扩展控制文件中的信息,包括扩展的名称、版本、依赖关系等。
- parse_extension_control_file():解析扩展控制文件中的信息,取出调用具体版本,文件名等信息。
- InsertExtensionTuple():这个函数会将插件元组插入到 pg_extension 表,把控制文件的信息保存到 Tuple 中。
- execute_extension_script():调用 execute_sql_string() 函数执行扩展脚本
- execute_sql_string(): 解析 sql 脚本文件并执行
3.2 SQL 脚本文件路径查找过程
PostgreSQL 中使用 CREATE EXTENSION 创建插件时处理完控制文件之后,会执行插件的 SQL 脚本,而这些脚本文件则需要根据控制文件中提供的插件版本等信息查找文件路径,该过程如下图所示:
在 CreateExtensionInternal 函数中处理插件控制文件的后,调用 get_ext_ver_list 和 get_ext_ver_info 函数获取插件的所有版本列表和具体版本信息;
然后,调用 find_install_path 和 find_update_path 函数查找某个需要执行脚本所在的路径,并通过 get_extension_script_filename 函数根据 SQL 脚本文件命名规则获取 sql 具体文件名称。

上述过程中各函数作用的具体说明如下:
- get_ext_ver_list() :获取指定插件的所有版本列表
- get_ext_ver_info() :获取指定插件的某个版本的信息;根据目标节点选择最短路径以及相对应的起始节点
- find_install_path() :根据插件名称和版本信息,在 PostgreSQL 的插件目录中查找对应的插件目录
- find_update_path() :当前插件版本和要升级到的版本,查找升级脚本所在的目录,使用最短路径算法 Dijkstra 实现
3.3 动态库函数创建过程
如果 PostgreSQL 插件中使用的是源码文件创建具体功能函数,那么在执行 SQL 脚本中使用 CREATE FUNCTION 创建函数时,会通过如下图所示过程加载插件动态库 so 文件来调用具体函数:
ProcessUtilitySlow 解析得到的 SQL 语句是创建函数的命令时,就会调用 CreateFunction 函数来执行具体过程,该函数中调 ProcedureCreate 创建一个新的函数,包括函数的名称、参数、返回值类型、语言、代码等内容;
ProcedureCreate 函数中使用 OidFunctionCall1 和 OidFunctionCall1Coll 调用指定函数的执行代码,该函数中使用 fmgr 提供的接口 fmgr_info 获取函数信息和函数指针;
然后,在 load_external_function 函数中调用 internal_load_library 函数根据函数指针在插件动态库中获取指定的函数实现逻辑

上述过程中各函数作用的具体说明如下:
- ProcessUtilitySlow():处理 SQL 命令的函数,它会对传入的 SQL 命令进行解析和执行;如果 SQL 命令是创建函数的命令,就会调用 CreateFunction() 函数继续处理相应逻辑。
- CreateFunction():解析 SQL 命令中的函数信息,并调用 ProcedureCreate() 函数创建函数。
- ProcedureCreate():创建一个新的函数,包括函数的名称、参数、返回值类型、语言、代码等。通过调用 fmgr_info() 函数获取函数的信息,并调用 OidFunctionCall1() 或 OidFunctionCall1Coll() 函数执行函数代码。
- OidFunctionCall1() 和 OidFunctionCall1Coll():这两个函数用于调用指定函数的执行代码,调用 fmgr 提供的接口。
- fmgr_info()、fmgr_info_cxt_security() 和 fmgr_info_C_lang():这些函数都是获取函数信息的函数;其中,fmgr_info() 函数获取函数的信息,包括输入输出参数、返回值类型、函数实现等;fmgr_info_cxt_security() 函数获取函数的安全上下文;fmgr_info_C_lang() 函数获取函数的实现语言和实现方式。
- load_external_function():加载指定的外部函数库,并返回函数指针。
- internal_load_library()、dlopen()、dlsym() 和 LoadLibrary():这些函数都是加载外部函数库的函数;其中,internal_load_library() 函数是 PostgreSQL 自己实现的加载函数库的函数,先判断是否 load,如果没有则通过调用 dlopen() 函数进行 load,然后使用 dlsym() 查找相关函数;
- LoadLibrary() 函数是 Windows 系统中的加载函数库的函数。
3.4 动态库函数调用过程
使用 CREATE EXTENSION 完成插件创建之后,就可以调用插件提供的函数了
PostgreSQL 中所有的函数调用都会调用 OidInputFunctionCall 函数进行处理,该函数实现如下,首先使用 fmgr_info 函数从插件动态库获取函数指针,然后调用 InputFunctionCall 函数调用指定函数。
Datum
OidInputFunctionCall(Oid functionId, char *str, Oid typioparam, int32 typmod)
{FmgrInfo flinfo;fmgr_info(functionId, &flinfo);return InputFunctionCall(&flinfo, str, typioparam, typmod);
}
fmgr_info 中获取函数指针的过程和以及其他相关信息,对于系统函数则从 Tuple 中获取;对于动态库中函数,则调用 fmgr_info_C_lang 来获取函数指针
fmgr_info_C_lang 的实现如下所示,和动态库创建过程中的动态库加载过程一样,都是通过调用 load_external_function 函数加载动态库并获取函数指针
static void
fmgr_info_C_lang(Oid functionId, FmgrInfo *finfo, HeapTuple procedureTuple)
{CFuncHashTabEntry *hashentry;PGFunction user_fn;const Pg_finfo_record *inforec;bool isnull;/** See if we have the function address cached already*/hashentry = lookup_C_func(procedureTuple);if (hashentry){user_fn = hashentry->user_fn;inforec = hashentry->inforec;}else{Datum prosrcattr,probinattr;char *prosrcstring,*probinstring;void *libraryhandle;prosrcattr = SysCacheGetAttr(PROCOID, procedureTuple,Anum_pg_proc_prosrc, &isnull);if (isnull)elog(ERROR, "null prosrc for C function %u", functionId);prosrcstring = TextDatumGetCString(prosrcattr);probinattr = SysCacheGetAttr(PROCOID, procedureTuple,Anum_pg_proc_probin, &isnull);if (isnull)elog(ERROR, "null probin for C function %u", functionId);probinstring = TextDatumGetCString(probinattr);/* Look up the function itself */user_fn = load_external_function(probinstring, prosrcstring, true,&libraryhandle);/* Get the function information record (real or default) */inforec = fetch_finfo_record(libraryhandle, prosrcstring);/* Cache the addresses for later calls */record_C_func(procedureTuple, user_fn, inforec);pfree(prosrcstring);pfree(probinstring);}switch (inforec->api_version){case 1:/* New style: call directly */finfo->fn_addr = user_fn;break;default:/* Shouldn't get here if fetch_finfo_record did its job */elog(ERROR, "unrecognized function API version: %d",inforec->api_version);break;}
}
动态库加载过程中使用的 dlopen, dlsym 函数是 dlfcn 库提供一组函数接口:dlopen 可以在运行时动态加载共享库 、 dlsym 可以查找动态链接库中的符号即函数或变量、而 dlclose 用于关闭已加载的动态库。
这几个函数在 PostgreSQL 后台进程运行过程中的作用如下图所示,使用 dlopen 在运行时将插件动态库加载到后台进程的内存映射区域,然后使用 dlsym 在动态库中查找函数并返回函数指针,这样进程在调用该函数时就根据函数指针执行动态库中的函数实现。

如果文章对你有帮助,欢迎一键三连 👍 ⭐️ 💬 。如果还能够点击关注,那真的是对我最大的鼓励 🔥 🔥 🔥 。
参考资料
PostgreSQL: Documentation: 12: 37.17. Packaging Related Objects into an Extension
PostgreSQL数据库扩展包——原理CreateExtension扩展控制文件解析_mb62de8abf75c00的技术博客_51CTO博客
Postgres源码分析——CREATE EXTENSION - 墨天轮 (modb.pro)
Postgres中新增扩展包的方法和原理-CSDN博客
编写Postgres扩展之一:基础 - Tacey Wong - 博客园 (cnblogs.com)
A Guide to Create User-Defined Extension Modules to Postgres - Highgo Software Inc.
如何为PostgreSQL创建一个内置函数? · 小wing的驿站 (xiaowing.github.io)




![[SQL开发笔记]WHERE子句 : 用于提取满足指定条件的记录](https://img-blog.csdnimg.cn/112a932af7774594b42ad28bf2a85e78.png)