机器人领域:控制,规划,感知等都可以用,可以把它作为一个优化过程,那么任何需要优化的问题都可以用它解决。
1.应用
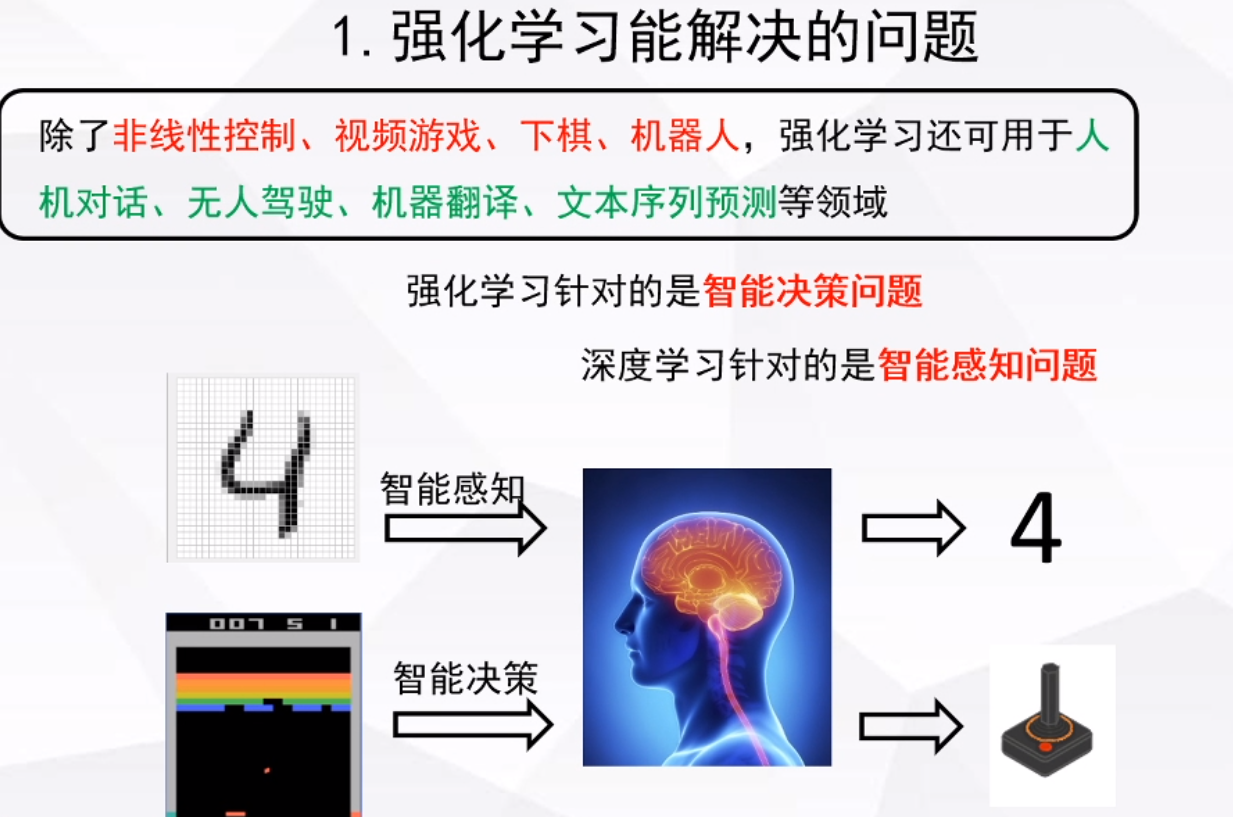
深度学习:智能感知,解决智能如何理解这个世界的问题。
强化学习:智能决策,解决智能体对这个世界做什么的问题。
相同点:都是从数据中学习,
不同点:深度学习需要静态的标签数据,强化学习需要动态(交互)的标签数据(宏观上),深度学习,主要识别和分类目标,强化学习解决最优决策问题。
2.单智能体强化学习
强化学习损失函数是回报,下图第一个式中,J是优化目标,是state分布,
是在状态s时选a的概率,R是在状态s时选a的回报。深度学习求解优化目标用梯度下降,但强化学习的损失函数无写出解析形式,所以成为一个对偶问题,也就是求最优值函数,用贝尔曼方程求解。
强化学习最开始是一种表格型方法,常用Q(s,a)表示,但很多任务中,s和a是无穷尽的,这就带来了维数灾难问题,导致计算机无法求解,后来就用CNN(卷积神经网络)拟合Q,出现了DQN,但DQN,有存在过优问题,后来用DDQN解决,在实际应用中,发现RNN(循环神经网络),在有些任务中效果更好,所以又出现了DRQN,在对数据进行学习时DQN一般是随机选择,但如果有策略性的选择数据,比方说用加权法,有时候效果更好,所以出现了Prioritized DQN,DQN中评估时只有值函数,后来又加入了优势值函数进行评估,得到了更好的效果,又出现了Dueling DQN,最后一个改变略显革命性,Distributioal DQN(分布式深度强化学习),DQN中我们学习(优化)的目标是R的期望值,但累计回报误差很大,而分布式,是想把值函数的概率分布学习出来。

进一步对模型已知问题的求解,就是对HJB方程(偏微分)方程求解,偏微分方程一般没有数值解,除非是二次可解析的用最优控制(LQR)求解,二维以上这种方法就不能搞了,同样会遇到维数灾难问题,所以用神经网络逼近,于是出现了自适应动态规划方法(ADP)。以及后面的群智能和基于模型的强化学习方法(都是解决数据高维问题)。
对于模型未知,提出了策略搜索方法,首先提出策略梯度的方法(似然率),但这个方法,方差很大,所以又出现了值梯度方法,这种方法方差小(PG,PPO,SAC)。以及后面出现的基于AC(DDPG,A3C),基于统计的方法(MPO),所有的方法都是为了解决方法问题。
注意一下值梯度方法的公式。

3.多智能体强化学习
单智能体强化学习是多智能体强化学习的特殊形式。一种动态的马尔可夫过程,一般用纳什均衡策略解决。常用方法MADDPG,CoMa,MAAC,AlphaStar,其中A代表attention,AlphaStar用了博弈理论,也是一个超级工程,集合了不同神经网络,像卷积,循环等。
4.困境和挑战

5.学习路线图

参考文献
1.深入浅出强化学习 编程实战 郭宪
2.博文视点学院










![nginx创建站点“nginx: [emerg] host not found in upstream”错误](https://img-blog.csdnimg.cn/571a75df9780478e8fff6c815e0580ab.png#pic_center)

![[黑马程序员SpringBoot2]——基础篇1](https://img-blog.csdnimg.cn/323fef01b1514cd2899fc57dab737a93.png)