前言:大家好,我是小威,24届毕业生,在一家满意的公司实习。本篇文章参考网上的课程,介绍Elasticsearch集群的搭建,以及Elasticsearch集群相关知识点整理。
如果文章有什么需要改进的地方还请大佬不吝赐教👏👏。
小威在此先感谢各位大佬啦~~🤞🤞

🏠个人主页:小威要向诸佬学习呀
🧑个人简介:大家好,我是小威,一个想要与大家共同进步的男人😉😉
目前状况🎉:24届毕业生,在一家满意的公司实习👏👏💕欢迎大家:这里是CSDN,我总结知识的地方,欢迎来到我的博客,我亲爱的大佬😘

以下正文开始
文章目录
- Elasticsearch部署集群
- Elasticsearch集群职责
- Elasticsearch集群健康状态
- Elasticsearch集群分片
- Elasticsearch故障转移
- 书籍推荐
Elasticsearch部署集群

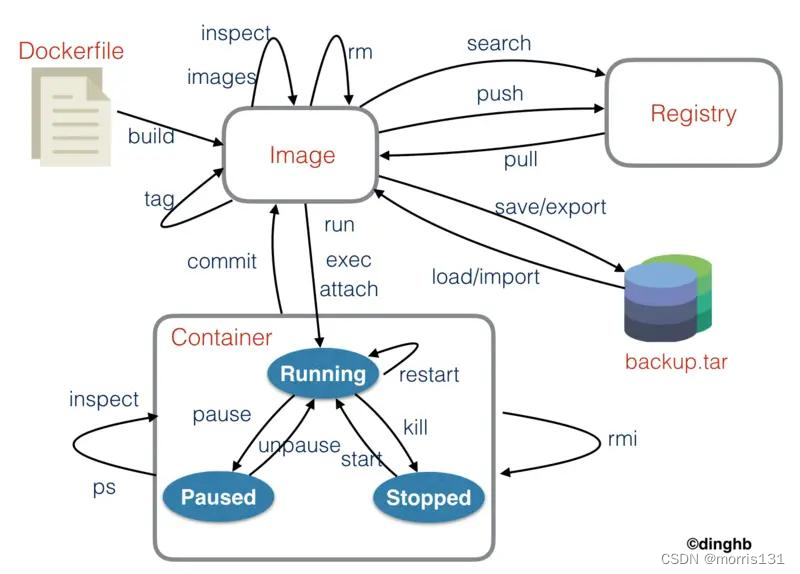
单机部署的Elasticsearch在做数据存储时会遇到存储数据上线和机器故障问题,因此对于Elasticsearch集群的部署是有必要的。搭建Elasticsearch集群,可以将创建的索引库拆分成多个分片(索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中),存储到不同的节点上,以此来解决海量数据存储问题;将分片上的数据分布在不同的节点上可以解决单点故障问题。
一个节点(node)就是一个Elasticsearch实例,一个Elasticsearch集群(cluster)由一个或多个节点组成,它们具有相同的集群名称(cluster.name),它们协同工作,分享数据和负载。
当加入新的节点或者删除一个节点时,集群就会感知到并平衡数据(同步)。
编写内容如下的docker-compose文件,将其上传到Linux的/root目录下:
version: '2.2'
services:es01:image: elasticsearch:7.12.1container_name: es01environment:- node.name=es01- cluster.name=es-docker-cluster # 集群名称相同- discovery.seed_hosts=es02,es03 # 可以发现的其他节点- cluster.initial_master_nodes=es01,es02,es03 # 可以选举为主节点- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data01:/usr/share/elasticsearch/data # 数据卷ports:- 9200:9200 # 容器内外端口映射networks:- elastices02:image: elasticsearch:7.12.1container_name: es02environment:- node.name=es02- cluster.name=es-docker-cluster- discovery.seed_hosts=es01,es03- cluster.initial_master_nodes=es01,es02,es03- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data02:/usr/share/elasticsearch/dataports:- 9201:9200networks:- elastices03:image: elasticsearch:7.12.1container_name: es03environment:- node.name=es03- cluster.name=es-docker-cluster- discovery.seed_hosts=es01,es02- cluster.initial_master_nodes=es01,es02,es03- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data03:/usr/share/elasticsearch/datanetworks:- elasticports:- 9202:9200
volumes:data01:driver: localdata02:driver: localdata03:driver: localnetworks:elastic:driver: bridge
es运行需要修改一些linux系统权限,进入并修改/etc/sysctl.conf文件
vi /etc/sysctl.conf
在文件中添加下面的内容:
vm.max_map_count=262144
然后执行命令,让配置生效:
sysctl -p
通过docker-compose启动集群:
docker-compose up -d
启动完成后,使用docker查看运行的容器,可以看到已启动Elasticsearch集群:

Elasticsearch集群职责
在Elasticsearch集群中,不同的节点可以承担不同的职责,例如:
-
Master节点:负责集群的管理和调度,包括分配和重新分配分片、节点的加入和退出、索引的创建和删除等。
-
Data节点:负责存储数据和执行搜索请求,包括分片的读写、搜索请求的处理等。
-
Ingest节点:负责对文档进行预处理,例如对文档进行解析、转换、过滤等操作。
-
Coordinating节点:负责协调搜索请求,将请求转发给适当的Data节点进行处理,并将结果汇总返回给客户端。
在实际的生产环境中,可以根据集群的规模和负载情况来决定节点的职责划分。例如,在小型集群中,可以将所有节点都设置为Master节点和Data节点;在大型集群中,可以将一部分节点设置为Master节点,一部分节点设置为Data节点,同时还可以设置一些Coordinating节点和Ingest节点来协调搜索请求和处理文档预处理。
Elasticsearch集群健康状态
Elasticsearch集群的健康状态可以通过以下命令或API来查看:
- 命令行方式:
可以使用curl命令或者httpie命令来访问Elasticsearch的API来获取集群健康状态,例如:
curl -X GET "localhost:9200/_cat/health?v"
或者
http GET localhost:9200/_cat/health?v
其中,localhost:9200是Elasticsearch的地址和端口号,_cat/health是API的路径,v表示显示详细信息。执行以上命令后,会返回如下信息:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1578318307 02:38:27 elasticsearch green 1 1 6 3 0 0 0 0 - 100.0%
其中,status字段表示集群的健康状态,有以下几种取值:
- green:所有主分片和副本分片都正常分配到节点上。
- yellow:所有主分片都正常分配到节点上,但是有一些副本分片还没有分配到节点上。
- red:有一些主分片没有分配到节点上,导致数据不可用。
- API方式:
可以使用Elasticsearch的API来获取集群健康状态,例如:
GET /_cluster/health
执行以上命令后,会返回如下信息:
{"cluster_name" : "my_cluster","status" : "green","timed_out" : false,"number_of_nodes" : 1,"number_of_data_nodes" : 1,"active_primary_shards" : 6,"active_shards" : 6,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}
其中,status字段表示集群的健康状态,其他字段的含义和命令行方式相同。

Elasticsearch集群分片
Elasticsearch集群中的数据被分成多个分片(shard),每个分片是一个独立的Lucene索引。分片可以在集群中的不同节点上分布,以提高搜索和写入性能。分片有两种类型:主分片(primary shard)和副本分片(replica shard)。
主分片是每个文档的主要存储位置,每个主分片都有一个唯一的标识符,并且只能在一个节点上存在。当一个文档被索引时,它被路由到一个主分片,然后被写入该分片的Lucene索引。
副本分片是主分片的拷贝,它们可以在不同的节点上存在。副本分片的数量可以在索引创建时指定,它们可以提高搜索性能和可用性。当一个主分片不可用时,副本分片可以被用来提供搜索结果。副本分片也可以用来平衡负载,因为它们可以被用来处理读取请求。
在Elasticsearch集群中,分片的数量和副本的数量可以通过索引的设置进行配置。通常,主分片的数量应该小于或等于集群中的节点数,以确保每个节点都有主分片。副本分片的数量应该根据集群的负载和可用性需求进行配置。
当索引创建完成的时候,主分片的数量就固定了,但是复制分片的数量可以随时调整。

Elasticsearch故障转移
集群的master节点会监控集群中的所有节点的状态,一旦发现有节点宕机,就会立即将宕机的节点分片的数据迁移到其他节点上,以此来保证数据安全,这个流程叫故障转移。与此同时剩余节点中会重新选举主节点,当原来的主节点恢复正常时,原来迁移到其他节点上面的分片会被迁移到恢复的节点上,但此时原来的主节点不再是主节点(哥不再是当年的哥)。
总结:
Elasticsearch故障转移的实现主要依赖于以下两个机制:
-
分片复制机制:Elasticsearch将索引分为多个分片,每个分片都有多个副本,分布在不同的节点上。当一个节点发生故障时,其他节点上的副本可以接管该分片的工作,保证数据的可用性。
-
主从复制机制:Elasticsearch集群中的每个分片都有一个主节点和多个从节点。当主节点宕机时,从节点会自动选举一个新的主节点,以继续处理该分片的请求。
在实际应用中,为了进一步提高Elasticsearch集群的可用性和稳定性,可以采用以下措施:
-
配置多个节点:将Elasticsearch集群部署在多个节点上,以分散风险,避免单点故障。
-
监控节点状态:使用监控工具对Elasticsearch节点进行实时监控,及时发现并处理故障。
-
自动化运维:使用自动化运维工具对Elasticsearch集群进行管理和维护,减少人为操作的错误和风险。
-
定期备份数据:定期备份Elasticsearch集群中的数据,以防止数据丢失和损坏,保证数据的可恢复性。
书籍推荐
工欲善其事,必先利其器。今天推荐你入手这本React技术的神级武器库:《React Cookbook中文版》 ,(O’reily的经典系列书籍)

正如本书的英文原名一样,作为Cookbook(菜谱),本书将呈现React各个方面的“精美菜肴”。
具体说来,本书具有如下特点:
涉及React技术的方方面面
从目录就可以看出,本书覆盖了所有React技术使用者可能会涉及的方方面面。译者团队频频感慨,这本书真是太全了,如果能把书中内容都研究透,绝对可以成为React大拿。如果你是前端架构师,本书应该常伴你左右。
内容讲解循序渐进
相信每个爱钻研技术的开发者,看一般技术书籍的时候往往有这种感觉:内容流于泛泛,看完好像学了很多,却又很容易遗忘。而本书作为一本“菜谱”,每章的目标都是做出一道“菜肴”(即一个前端项目),每个小节又都以问题为牵引,让我们在不断跟随书中节奏解决问题的过程中,逐步对这个项目不断完善和迭代,在该章完结的时候,正好完成一个完整的可运行实例。其中要说明的是,这些问题来源于我们React技术开发者工作中真正遇到的最常见难题,因此本书又具备了另一个特点,即可以直接当成工具书,随用随查(这也是书名的本意)。
翔实的参考资料
每个小节除了“问题”和“解决方案”之外,还有“讨论”,很多时候还会给出重要资料的相关链接,便于读者进一步学习。相信每一个想在前端领域不断精进的小伙伴,在阅读的过程中,都会不断感知到自己的知识网络又拓展了。
以上只是大体介绍了本书的特色,本书还有很多亮点需要读者在阅读过程中去探索,比如在书中项目选取上的匠心独运,需要读者亲自去体会,相信你通读完全书后,也会跟我们得出同样的结论:本书是React技术的神级武器库。
读者收获
React可以帮助你便捷地创建和处理应用程序,但要掌握如何将各部分功能有机地整合在一起却并不容易。如何验证表单?如何在保持代码精简的情况下实现复杂的多步骤用户操作?如何测试代码?如何保证可维护性?如何连接后端?如何提高代码可读性?本书可以帮你快速解决这些问题。
许多书籍教你如何入门、理解框架,或者如何将组件库与React结合使用,但很少提供代码示例来帮助你解决具体的问题。本书简明易懂,包含开发人员使用React解决常见问题时的示例代码,这些解决方案按主题和问题类型分类,便于你索引和查找。
通过阅读本书,你将学会:
- 向使用React构建的单页面应用程序引入丰富多彩的UI。
- 创建可以离线安装和使用的渐进式Web应用程序。
- 与REST、GraphQL等后端服务集成。
- 自动测试应用程序的可访问性。
- 使用WebAuthn引入指纹验证和安全令牌,增强应用程序的安全性。
- 处理bug,并避免常见的功能和性能问题。

京东购买链接:点击了解
评论区任意留言可参与活动抽奖(评论最多五条,抽取四名欧皇)
好了,本篇文章就先分享到这里了,后续会继续分享其他方面的知识,感谢大佬认真读完支持咯~

文章到这里就结束了,如果有什么疑问的地方请指出,诸佬们一起讨论😁
希望能和诸佬们一起努力,今后我们顶峰相见🍻
再次感谢各位小伙伴儿们的支持🤞







![分发糖果[困难]](https://img-blog.csdnimg.cn/4f3a1023a59b4d558fda9ca2f0bdb3c7.png)