线程池的工作原理和实现已经在之前的文章中介绍
本文主要总结面试中线程池常问题目。
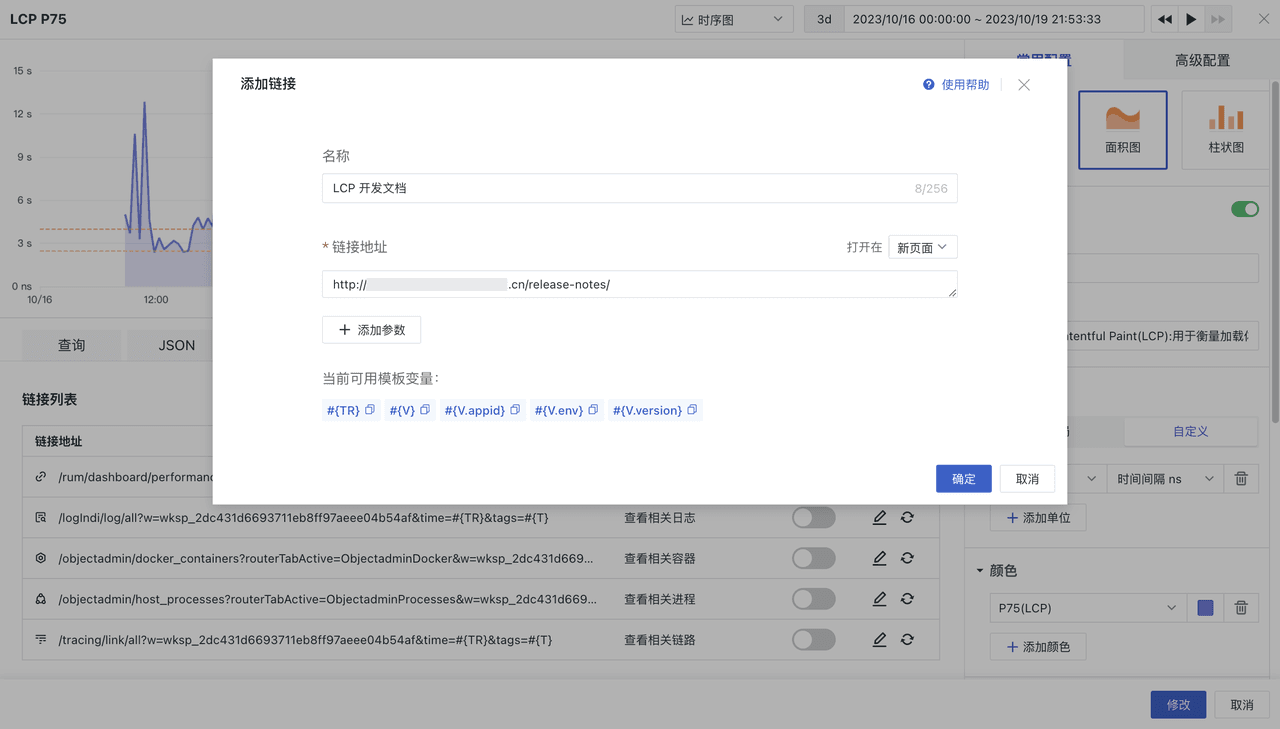
1、有几种常见的线程池(必知必会)?
1)定长线程池(FixedThreadPool)
2)定时线程池(ScheduledThreadPool)
3)可缓存线程池(CachedThreadPool)
4)单线程化线程池(SingleThreadExecutor)
核心概念:这四个线程池的本质都是ThreadPoolExecutor对象(自己看源码)
不同点在于:
1)FixedThreadPool:只有核心线程,线程数量固定,执行完立即回收,任务队列为链表结构的有界队列。
2)ScheduledThreadPool:核心线程数量固定,非核心线程数量无限,执行完闲置 10ms 后回收,任务队列为延时阻塞队列。
3)CachedThreadPool:无核心线程,非核心线程数量无限,执行完闲置 60s 后回收,任务队列为不存储元素的阻塞队列。
4)SingleThreadExecutor:只有 1 个核心线程,无非核心线程,执行完立即回收,任务队列为链表结构的有界队列
2.线程池的主要参数有哪些
1)corePoolSize(必需):核心线程数。默认情况下,核心线程会一直存活,但是当将 allowCoreThreadTimeout 设置为 true 时,核心线程也会超时回收。
2)maximumPoolSize(必需):线程池所能容纳的最大线程数。当活跃线程数达到该数值后,后续的新任务将会阻塞。
3)keepAliveTime(必需):线程闲置超时时长。如果超过该时长,非核心线程就会被回收。如果将 allowCoreThreadTimeout 设置为 true 时,核心线程也会超时回收。
4)unit(必需):指定 keepAliveTime 参数的时间单位。常用的有:TimeUnit.MILLISECONDS(毫秒)、TimeUnit.SECONDS(秒)、TimeUnit.MINUTES(分)。
5)workQueue(必需):任务队列。通过线程池的 execute() 方法提交的 Runnable 对象将存储在该参数中。其采用阻塞队列实现。
6)threadFactory(可选):线程工厂。用于指定为线程池创建新线程的方式。
7)handler(可选):拒绝策略。当达到最大线程数时需要执行的饱和策略。
3.线程池的工作流程
这个问题回答的时候,最好用讲故事的方式进行。
假如核心线程数是5,最大线程数是10,阻塞队列也是10
1)有新任务来的时候,将先使用核心线程执行;
2)当任务数达到5个的时候,第6个任务开始排队;
3)当任务数达到15个的时候,第16个任务将开启新的线程执行,也就是第6个线程
4)当任务数达到20个的时候,线程池满了,如果有第21个任务,将执行拒绝策略(见下一个问题)
流程图:
4、线程池的拒绝策略有哪些
1)AbortPolicy(默认):丢弃任务并抛出 RejectedExecutionException 异常。
2)CallerRunsPolicy:由调用线程处理该任务。
3)DiscardPolicy:丢弃任务,但是不抛出异常。可以配合这种模式进行自定义的处理方式。
4)DiscardOldestPolicy:丢弃队列最早的未处理任务,然后重新尝试执行任务。
5、如何合理设置线程池的核心线程数
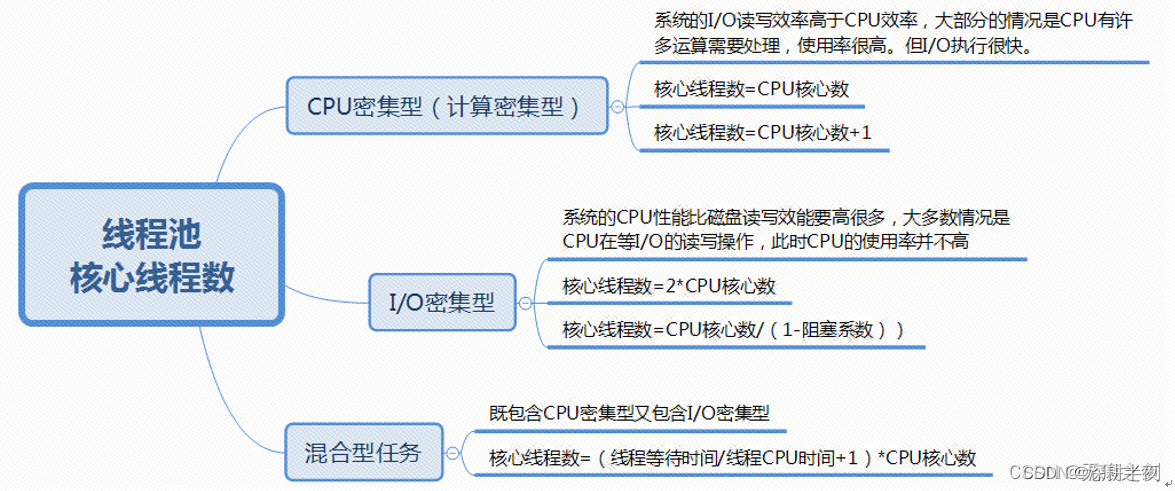
线程数量的计算公式一般都是 线程数=Ncpu(1+w/e).其中W代表的是阻塞耗时,e代表的是计算耗时。
1)IO密集型:如果存在IO,那么W/e肯定大于1,但是需要考虑系统内存上限(没开启一个线程都需要内存空间),这个需要服务器测试到底多少个线程比较合适(CPU占比,线程数、总耗时、内存耗时)。保守取值为1,及线程数=2Ncpu+1,
2)计算密集型:假设没有等待时间,则W=0,W/C=0,线程数= Ncpu+1. 其中多出来的一个是为了防止线程偶发的缺页中断。
服务性能I0优化有一个估算公式:
最佳线程数目=((线程等待时间+线程CPU时间)/线程CPU时间)X CPU数量
比如平均每个线程CPU运行时间为0.5s,而线程等待时间为1.5s(比如IO),CPU个数为8.则根据以上公式可以估算((1.5+0.5)/0.5)X 8=32
公式进一步转化:
最佳线程数目 = (线程等待时间/线程CPU时间+1)X 线程数
原文链接:https://blog.csdn.net/m0_37824308/article/details/123825244