👉👉👉 哈喽!大家好,我是【大数据的奇妙冒险】的作者 ,具有 Java 以及大数据开发经验,目前是一位大数据领域项目经理。
擅长 Java、大数据开发、项目管理等。持有 PMP 和 系统架构设计师证书,可以说是持证上岗了😀
如果有对【大数据】感兴趣的朋友,欢迎关注 公 众 号【大数据的奇妙冒险】
目录
- 什么是水平分表
- 水平分表的路由策略
- 范围分表
- 中间表映射
- Hash 分表
- 一致性 hash 算法
- 小结
什么是水平分表
水平分表就是指以行为单位对数据进行拆分,将数据分别存储在多个相同表结构的表中。
一般是在数据量较大的情况使用,可以减轻数据库压力,提高效率。
水平分表的路由策略
范围分表
从字面的意思看很好理解,就是划定一个范围,比如第 0-1000 条数据放表一,1001-2000条放表二,以此类推;或者按照时间范围进行分表。
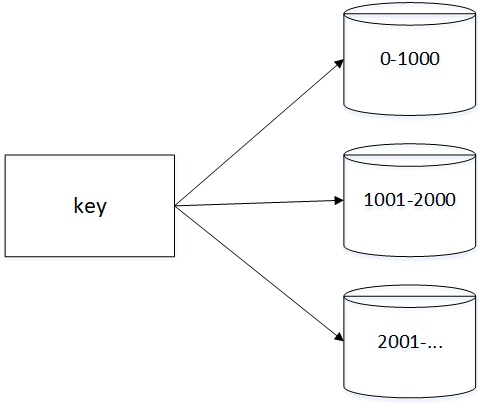
这样分表的好处是,扩容比较方便,一旦数据达到阈值需要进行扩容,只需要再加个表,往后的数据直接放新表。
但是缺点也比较明显,容易造成倾斜,存在读写偏移的情况,造成单表压力过大。
比如交易流水,每次发生交易都会往新表写,在查询习惯上,用户查最新的交易会比较多。
中间表映射
将分表 key 和表的映射关系存放在一张单独的表上,每次操作都先查询映射表,然后得到具体的表。比如设置一个中间表,其中一个字段是数据的 key,另一个字段是表的 id。
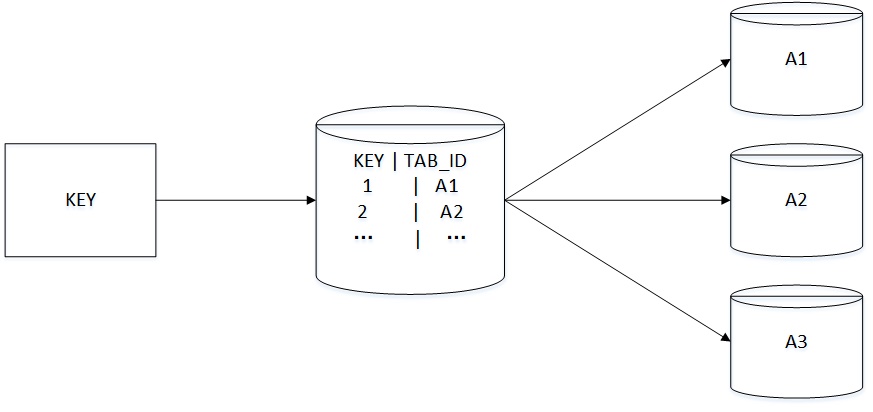
这样的优点就是比较灵活,可以自己定数据位置。
缺点呢,就是中间表的数据会不断扩张,就算可以对其进行水平分表,但这样也形成一个恶性循环。
而且使得查询流程增加,一旦有多个中间表就得每个都查一遍。
Hash 分表
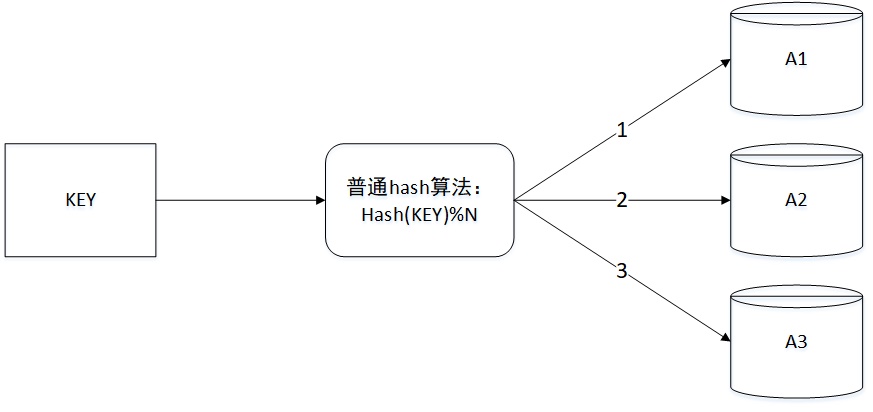
Hash 分表是将特定列或者特定的某几个列进行 hash 计算,然后路由到具体分表上。
比如说有三个分表,那可以进行哈希取模,结果为 1 的就放表一,为 2 就放表二,由此类推。
hash 分表的优点是可以使数据比较均衡的分布到每张分表中,但可扩展性比较差。
举个栗子,假如原先 3 个分表,现在再加一张,存量数据的 hash 值则需要重新计算以确定分发到哪张表,然后将数据进行迁移,一旦发生迁移,可用性就会降低。
在实际应用中,hash 分表其实是用的比较多的,但是由于普通哈希存在上述问题,所以一般是用一致性 hash 算法。
一致性 hash 算法
它是一种分布式哈希算法,用于在分布式系统中解决节点动态变化带来的数据迁移问题。
假定有 2^32 个点组成一个环,有 3 个分表,然后我们用表的编号进行哈希计算后除以 2^32 取模后放到环上;
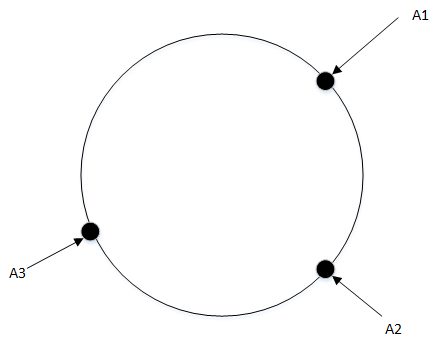
然后将数据也进行哈希计算后除以 2^32 取模后放到环上;

之后数据按照顺时针方向查找表,遇到的第一个表就存进去。
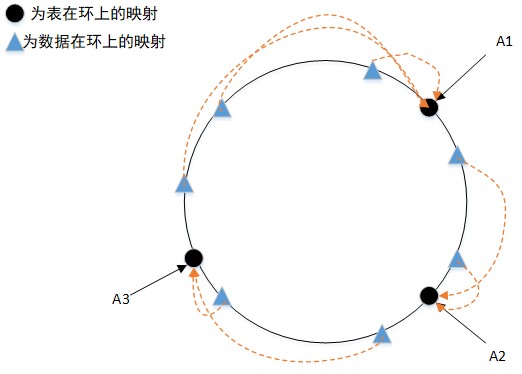
通过这样的方式,可以减少当修改节点时需要迁移的数据量。假设我们在 A3 和 A1 之间加一个表,那么需要迁移的数据就只有原本属于 A1 的部分数据。
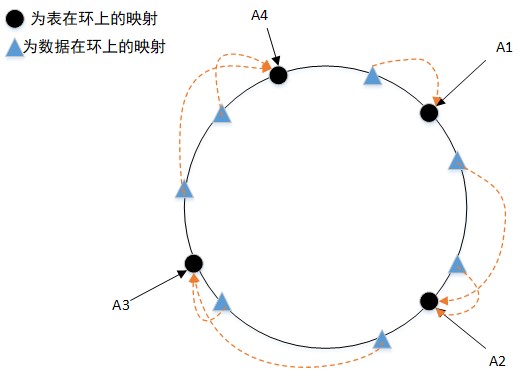
但是一次性 hash 算法也存在问题,那就是当节点比较集中的情况下,就会导致数据倾斜,即大量的数据会存储在某些节点。
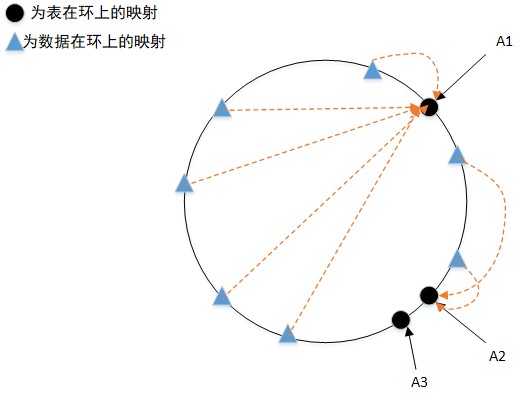
那么,这有什么解决办法吗?
当然是有的,一般是增加虚拟节点,即每张物理表映射出一个或多个虚拟节点,分布在环上,使得数据的存储更均匀(为了方便,每个节点只画了一个虚拟节点,真实场景一般需要多一些)。
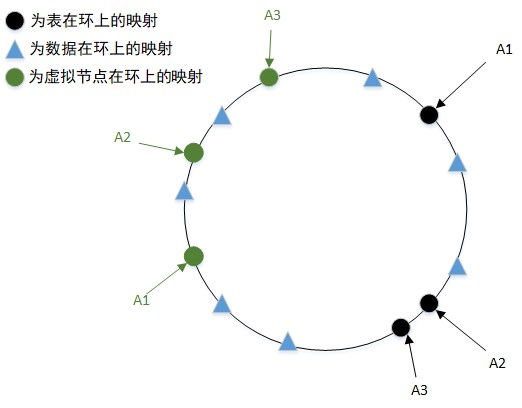
当需要对数据进行读写的情况,只需要找到虚拟节点,然后再找到对应的真实节点,读取其数据即可。
小结
本文讲了水平分表以及几种常见的数据路由策略,介绍了每种策略的优缺点;之后引申了一致性 hash 算法以及其缺陷和解决方法。对于本文的内容,实际上也可以套用到各种分布式应用中。如果觉得这篇文章对你有帮助,不妨点个小赞支持一下。欢迎关注:✨大数据的奇妙冒险