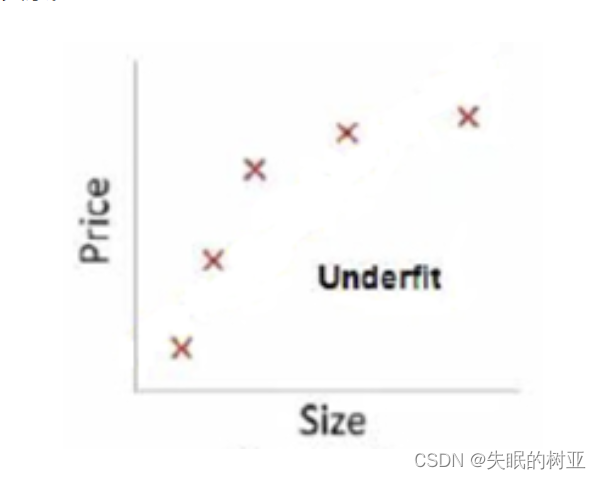
这张图中,横坐标size表示房屋的大小,纵坐标price表示房屋的价格,现在需要建立模型来表示两者之间的关系。
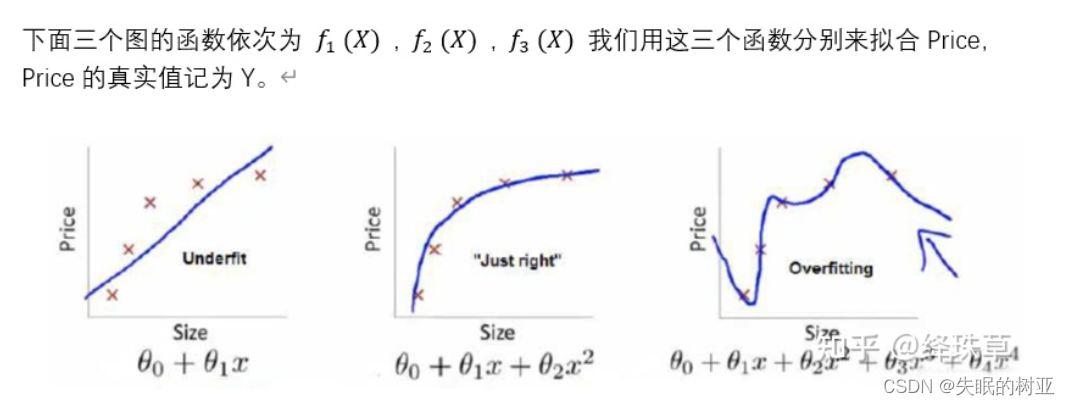
对于给定的输入x,模型会有一个输出f(x),用一个函数来度量拟合的程度,也就是真实值和预测值之间的差距,这个函数就称为损失函数。损失函数越小,就代表模型拟合的越好。
1.什么是损失函数
损失函数,用来估量模型的预测值f(x)和真实值y之间的差异。损失函数举例:
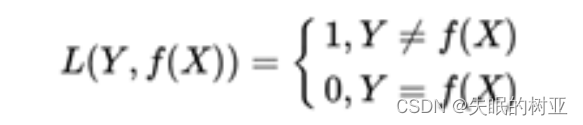
2. 什么是经验风险
风险函数,是损失函数的期望。f(x)关于训练集的平均损失称为经验风险,为:
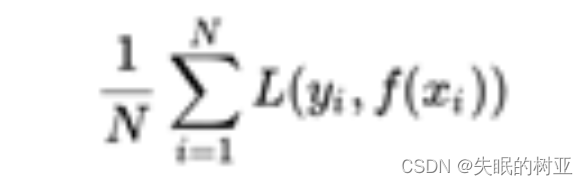
上面的图中,虽然第三个函数的图像对数据拟合的最好,损失函数最小,但是这并不是最好的。因为它出现过拟合习现象,过度学习历史数据。第一个函数的图像对历史数据拟合的很差,出现欠拟合现象。
目标是:不仅要让经验风险最小化,还要让结构风险最小化。
3.正则化
造成过拟合的主要原因是模型太复杂了,定义一个函数 J(f)专门用来度量模型的复杂度,在机器学习中叫做正则化(regularization)。常用的正则化函数有L1和L2范数。
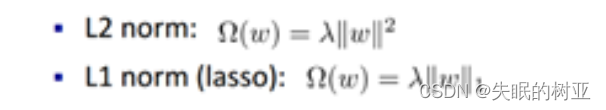
4.什么是目标函数
∴ 我们最终的优化函数是:损失函数+正则化函数
即优化经验风险和结构风险,这个函数被称为目标函数。优化训练误差可以让模型具有预测性,优化正则可以让模型更简单,预测更稳定。

bias偏差,variance方差。