大语言模型的最早应用是Chatbot,其实我最早接触语义理解在2014年,2014年做智能音箱的时候,那时也是国内第一批做智能音箱的,在现在看起来当时的智能音箱比较傻,很多问题无法回答,长下文效果也不好,多轮对话效果就更差了,那时对话使用的主要技术是基于规则+知识图谱,所以主要还是停留在命令词识别基础上的交互,比如放音乐类、操控智能家电以及问天气等有限的几个范畴,更多的扮演的事assistent角色,开放式聊天做的并不好。
当时是设计阶段就决定了对话的上限,虽然我们当时模仿的Amazon Alexa如今“进化”出了数以万计的技能,但是相对于LLM,这些技能显得有些过时,如何将LLM接入Alex也是亚马逊不得不面临的事。
时至今日大型预训练的语言模型(如GPT、BERT等)使得对话机器人取得了显著的进展。这些模型通过在大规模文本数据上进行预训练,可以生成具有语法正确性、语义连贯性、具有记忆能力多轮对话的文本回复,除了生成自由对话回复的模型,还有一些任务导向的对话系统,如客服机器人、智能助理等。这时在运行时才会决定对话的上限,聊天机器人再次被认为是客户服务、营销和内部运营的潜在游戏规则改变者。
在训练模型的时候,常常提到模型的泛化能力,泛化能力使得模型可以高质量回复训练集中并不存在的内容,即可以将模型的训练过程看成是记忆+学习的过程,记忆是可以记住训练集中的内容,而学习就是根据训练集中的内容举一反三、触类旁通。在一个训练好的模型,如果触发高质量的记忆+学习能力以获得高质量的回复是信息获取类的核心竞争力之一。
就当前的大语言模型的产品形态而言,基于我所处的行业和工作性质认知,我认为集成大语言模型的工具类应用将是第一波享受大语言模型红利的应用场景。尽管微软基于大语言模型的代码补全github copilot还处在亏损的阶段,但是150万这一庞大的付费用户规模,已经验证了大量用户愿意为此买单,对于copilot生产代码的质量是至关重要的。
大语言模型的用户价值
总结来说,使用大语言模型的目的可以归为一下几类:
1.信息获取:提供及时、准确、可信的信息和答案,用户可以问问题、需求建议获取特定领域的知识,这好处在于可以快速获取信息而不需要再浏览搜索结果或者在工具间切换,突出优势是方便,这在信息爆炸的时代是非常突出的重点的,
2.娱乐和消遣:重点是消遣,这里必须突破的点是如何促进用户的多巴胺分泌,显示生活中黄赌毒都能促进大量的多巴胺分泌,同样一样东西,具有两面性,取决于人怎样使用,好比刷抖音/快手,有些人是获取知识,而有些人就是为了看不费脑子的爽图和短视频,如何在这一个过程中让用户不费脑子的消遣是产品设计的重点,但凡需要一些思考,就可能流失一部分用户,但是如果能够挖掘用户的兴趣点,比如有些小朋友喜欢脑筋急转弯,虽然费脑子,猜不中,但是小朋友却很喜欢玩,并且乐此不疲,虽然猜不中,但是总想征服下一个谜底,这个游戏的设计非常有挑战性。
3.社交互动:这是人的情感需求,需要提供的事情绪价值,高质量的共情是这个点必须突破的核心所在。这是满足人的社交需求,在一些情况下,如孤独感、需要倾诉和陪伴是,对话机器人可以提供一种无压力和包容性的交流环境。
不同用户在不同场景对于时间的看法是不一样的,对于互联网等科技工作者,在工作的时间,需要高质量的信息获取以便提升工作的产出和结果,而在下班之后的时间有些人人用来社交、有些人用来娱乐,有些人用来进修,不同的选择对于时间的价值期许是不一样的。
以高铁候车大厅为例,坐在凳子上等车的人中,约85%都盯着手机,其中以30岁左右的人比例最高,在干的事情,主要为聊天(人面对面聊天),和手机交互,和电脑pad交互(极少),吃喝、带娃以及发呆(盯着大屏或者其他场景看),手机占了90%的时间,主要使用的APP主要为微信、抖音、微博、游戏、电话、购物等这几大类,如果想要占据这些人的时间,那么娱乐类是重点。
如果是办公室的白领场景,那么这些人沟通外界的方式更多的是电脑,且在家也多有个人电脑,办公场景更多的需要高做出高质量选择,高质量的信息获取就至关重要,对于程序员、财务、律师、金融、医疗等不同的类型的白领又需要特定领域的知识。
所以在设计一个ChatBot的时候,需要想清楚服务于什么用户(核心用户),刚性需求是什么(痛点),典型的场景(什么时候用,就是你想吞噬用户什么场景的时间,是高铁候车大厅还是程序员办公室工作场景?)以及竞品优势是什么。
大语言模型现状
像GPT-4这样的LLM的出现彻底改变了聊天机器人的设计格局,这些高级模型利用人工智能来理解上下文并生成类似人类的响应。这种转变对聊天机器人设计具有重大影响。
当前各家的模型还处在初始阶段,基本上是模型即服务的状态,通过测试在模型层面上回复质量就是层次不齐的,而对于相同的模型,采用不同retrieve方法引导生成的回复,质量也是不一样的。这种retrieve方法是交互范式的改变。
很多产品将对话机器人以web主打的形式接入公司的官网或者是浏览器插件的形式提供AI功能,web仍然是构建对话机器人的最简单、最干净的方式,并提供设计对话机器人的最大自由度。围绕着的也会有各类平台的app,以增加对话机器人的触及度。
不同的场景中,用户对对自身时间价值的看法是不一样的,期望产生的价值也是不一样的,当前大一统的对话机器人并不能很好的覆盖通用的日常场景,就目前而言并不认为大语言模型会一统所有场景,比如现在吃饭会打开一个APP,购物会打开一个app,比如饿了么,现在的交互范式是我主动搜索,然后下拉一个个看评分看详细介绍,个性化并不智能,大模型可以做到更了解一个人
商业盈利当前仍不是重点,圈地是重点,但是商业化已经在流量以及会员制付费的模式上尝试,并取得了一些进展。
设计师现在可以更专注于完善聊天机器人的对话能力,在特定领域训练它,并确保它为最终用户提供价值,从而产生更具吸引力和更有效的用户体验。
信息获取类都是如此,信息的质量将是大语言模型之间竞争的核心,为了提升大语言模型的回复质量,由此引出了扩充高质量数据集、Fine-tune、RAG、联网信息获取都是在提升回复质量。
大模型进化的方向
用户将从聊天中获取怎样的价值,或者说聊天机器人给用户在什么场景提供怎样的潜在价值是是出发点,换句话说满足了了人性中哪点或哪几点,相对于本我、自我、超我的马斯洛分层模型,我更喜欢用人性劣根性的七宗罪来提炼价值。
设计对话机器人是艺术和科学的融合,结合了用户界面设计UI、用户体验UX、交互设计ID和大模型训练。是用户针对其痛点场景的第一解决方案,产品自始至终的设计都应该牢记对用户提供价值。最核心的是理解用户需求,用户是不懂技术的,让用户学习如何写好prompt的产品体验是不合理的,如果在用户不感知的情况下帮助用户生成高质量的prompt,表面上式我想要,深挖到最后,都可以归结到人性层面,所以有时候用户的问,并不是用户真正想的问题,所以挖掘背后的问并为用户写出正确的Prompt是产品设计中必须考虑的点。
从表面的形式上看,未来大模型发展的趋势如下:
1.各种插件引入,给大模型补充数据、技能,搜索、地图、财经、天气数据等;增加在数据专业性和时效性;
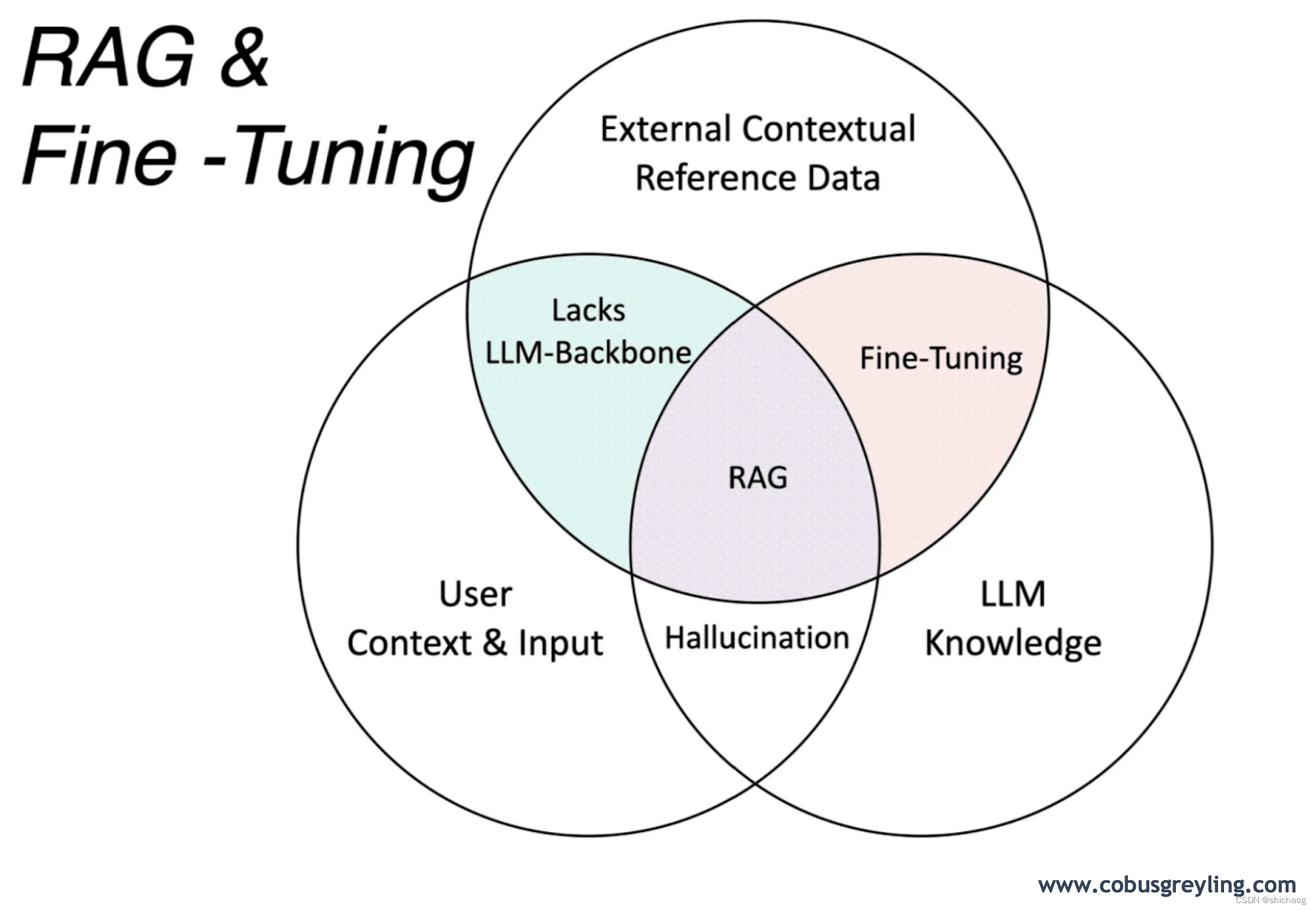
2.应对隐私和幻觉,隐私包括个人电话、地址相关账号登信息的泄露,也包括公司的一些文档、信息、资料等泄露,幻觉是生成可靠的回复,当前的大语言模型是可能生成实事性的错误或者捏造相关事实。
对于幻觉,当前采用如下两种方法居多。
-
Fine-Tuning -
Retrieval Augmented Generation (RAG).
3.由于部分大语言模型对话已经退出,因而当前已经收集到了海量的真实对话数据,理解机器人失败的原因仍然至关重要。分析见解不仅增强了用户体验,还揭示了聊天机器人设计中的潜在陷阱。通过研究机器人在用户旅程或对话流程中的不足之处,我们可以相应地完善和改进设计。
4.头部互联网公司继续领跑,并且在已有业务和通用对话机器人继续尝试,具有行业数据(金融、医疗、法律、软件等)将会构建行业大语言模型并司内尝试使用;
5.预计24年底到25年上半年,头部互联网通公司根据已有对话机器人收集的数据分析后,大概率会反应过来其以前的通用大模型全品类聊天注定是失败的产品,构建个人助理(类似企业高管的个人助理,只不过这里是大语言模型)大模型才是出路,并且即可可能成长为一下阿里、腾讯、字节,如果是上面三家中的一家,那么市值翻个好几倍也不在话下,个所以如何构建好个人场景的衣食住行等相关服务至关重要,这对于大公司是有优势的,比如字节跳动,旗下的抖音有电商、本地生活、休闲娱乐以及住房等多个维度的产品矩阵,当然在一两个领域里能成功已经是非常大的成功了,比如食这个领域里干掉美团,其实美团的体量很大,但是美团的壁垒并不高。
6.大模型门槛越来越低,生态会越来越好,更多的中小公司会依靠大模型带来的能力,将企业提升一个等级,这在民营企业中最有可能出现。