我们在许多的编程语言中,大部分的数组下标都是从零开始的,那为什么不是从一开始的呢?
首先我们,先要了解数组相关的定义。
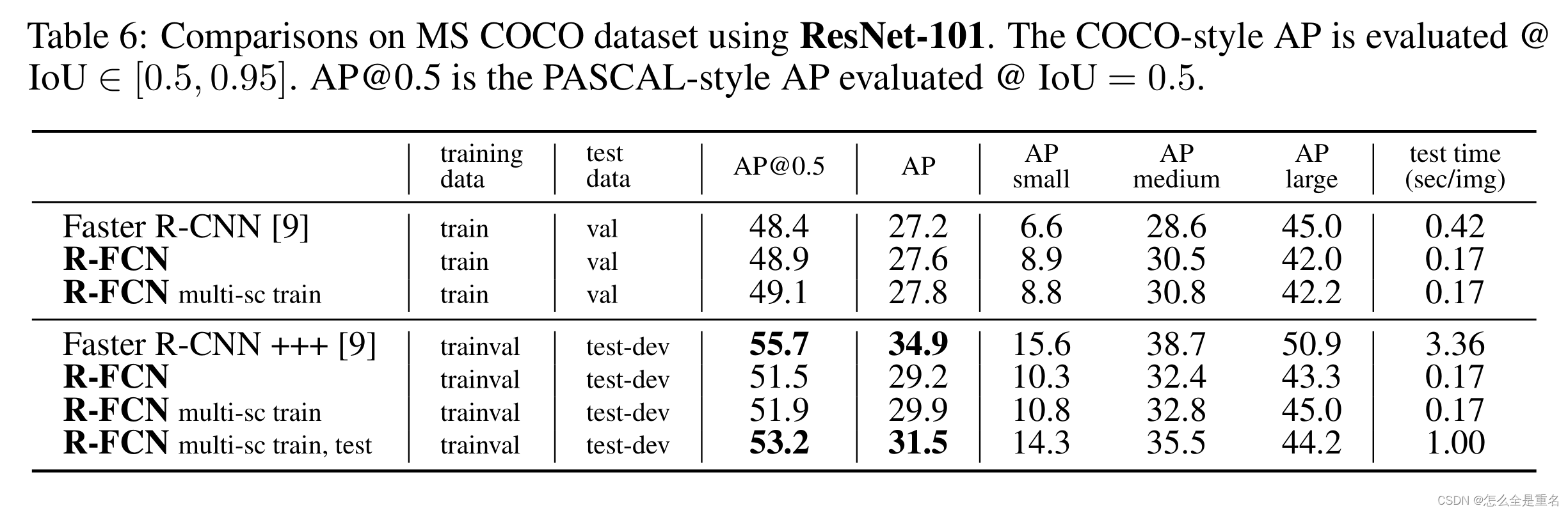
- 数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
- C语言中,下标的含意是:当前元素到第一个元素的偏移量。第一个元素的下标自然就是0,第二个元素的下标为1,第n个元素的下标为n-1。
下标从0开始的原因就是为了寻址方便。
计算机会给每个内存单元分配地址,并且通过地址来访问内存中的数据。当计算机想要随机访问数组中的某个元素时,他就会通过下面的寻址公式:
a[i]_address = base_address + i * data_type_size而如果下表从1开始,那么就会变成:
a[i]_address = base_address + ( i - 1 ) * data_type_size对比两个代码,会发现下标从1开始时,每次随机根据下标访问数组元素时,对于CPU来说,会多一个减法运算。 数组作为非常基础的数据结构,通过下标随机访问数组元素又是其非常基础的编程操作,效率的优化就要尽可能做到极致。所以为了减少一次减法操作,数组选择了从 0 开始编号,而不是从 1 开始。
还有另一种理解方式(偏移量):在内存就开辟了一块地址空间(内存中地址空间都是连续的,地址中的内容就是你存储在其中的值),然后变量a就指向了这片地址空间的“首”地址,如果想要访问这片地址的其他地址,那么就得用偏移量来计算。
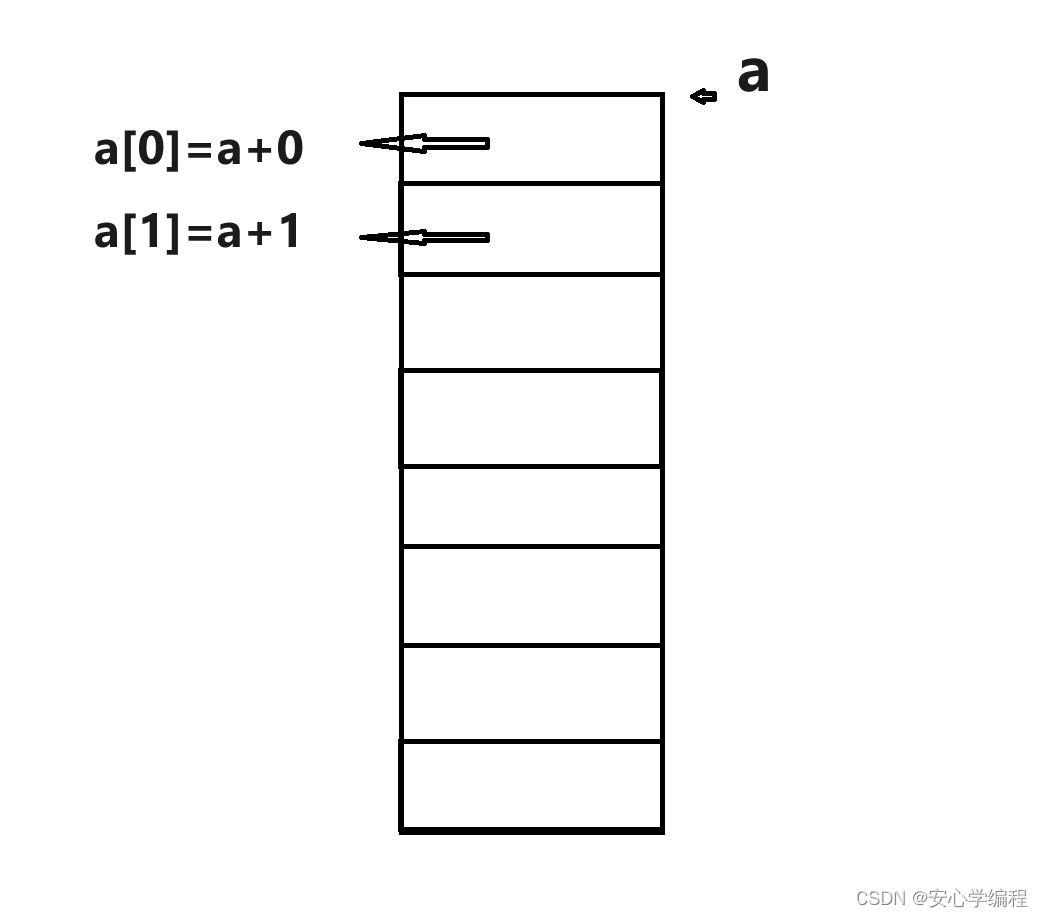
变量a已经指向首地址,a[0] = a + 0 ,0代表的就是偏移量,a偏移0个单位,就是其本身,所以a[0]代表的就是第一个地址。 a[1] = a + 1; a偏移一个单位,那么就可以访问到a[1],也就是第二个地址。所以只需要 变量名+[偏移量] ,(如 a[0]) 就可以访问到相应的内存地址。这是下标从0开始的情况。