嗨喽~大家好呀,这里是魔王呐 ❤ ~!

python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取
一. 数据来源分析
-
明确需求
明确采集网站以及数据内容
数据: 职位信息网址:
https://we.51job.com/pc/search?keyword=python&searchType=3&sortType=0&metro= -
抓包分析
通过开发者工具进行抓包分析
I. 打开开发者工具: F12 / 右键点击检查选择network
暂时可能没有数据包或者数据包比较少 <数据不完整>II. 刷新网页: 让数据内容重新加载一遍
III. 通过关键字去搜索查询对应数据包
关键字: 我们需要的数据
https://we.51job.com/api/job/search-pc?api_key=51job×tamp=1690980373&keyword=python&searchType=3&function=&industry=&jobArea=000000&jobArea3=&landmark=&metro=&salary=&workYear=°ree=&companyType=&companySize=&jobType=&issueDate=&sortType=0&pageNum=1&requestId=&pageSize=30&source=1&accountId=&pageCode=sou%7Csou%7Csoulb
二. 代码实现步骤
-
发送请求, 模拟浏览器对于url地址发送请求
请求链接地址: 找到数据包链接
-
获取数据, 获取服务器返回响应数据
开发者工具: response <所有数据内容>
-
解析数据, 提取我们需要的数据内容
职位,公司,薪资,城市,经验,学历要求等
-
保存数据, 把数据保存本地文件 csv Excel 数据库 文本…
职位信息代码实现
请求数据
上面的抓包分析已经说的很清楚,所以不再赘述
这里请求我们需加上
-
Cookie:用户信息, 常用于检测是否登陆账号 <登陆与否都有cookie>
-
Referer:防盗链, 告诉服务器请求链接地址, 是从哪里跳转过来
-
User-Agent:用户代理, 表示浏览器基本身份信息
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
# 模拟浏览器
headers = {'Cookie': 'guid=54b7a6c4c43a33111912f2b5ac6699e2; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2254b7a6c4c43a33111912f2b5ac6699e2%22%2C%22first_id%22%3A%221892b08f9d11c8-09728ce3464dad8-26031d51-3686400-1892b08f9d211e7%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTg5MmIwOGY5ZDExYzgtMDk3MjhjZTM0NjRkYWQ4LTI2MDMxZDUxLTM2ODY0MDAtMTg5MmIwOGY5ZDIxMWU3IiwiJGlkZW50aXR5X2xvZ2luX2lkIjoiNTRiN2E2YzRjNDNhMzMxMTE5MTJmMmI1YWM2Njk5ZTIifQ%3D%3D%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%24identity_login_id%22%2C%22value%22%3A%2254b7a6c4c43a33111912f2b5ac6699e2%22%7D%2C%22%24device_id%22%3A%221892b08f9d11c8-09728ce3464dad8-26031d51-3686400-1892b08f9d211e7%22%7D; nsearch=jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D; privacy=1690977331; Hm_lvt_1370a11171bd6f2d9b1fe98951541941=1688644162,1690977332; Hm_lpvt_1370a11171bd6f2d9b1fe98951541941=1690979700; search=jobarea%7E%60%7C%21recentSearch0%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch1%7E%60010000%2C020000%2C030200%2C040000%2C090200%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21; acw_tc=ac11000116909815830311339e00e171910033f29edaf40a9eeee0368c9110; acw_sc__v2=64ca54d2e0effb7debcb282d322b72a10e69b3c3; JSESSIONID=C9461FAAB4EEE90D560B795EF5067188; ssxmod_itna2=Yui=DK0I4+xR2xl4iqdRbUwqGqLBxQqKaBxikvTChDlPIQDjbrx0=ntaoC6D60BGQKRCldAQhTtK3g0q52oj02etMgwGTwD1YkKqKVKnCSBO42lue=O7gl1BbsBYS+/0+Vj3n97v/gTOReY8U1nFVQhTh6vQDruNzp9CTtm7DpIQux5r7huQyayh/7pvt9vwvF8zxFizxE3h3RYIKfKm4pid8t4+ehdr4=0Utj0w8Qe5TjLNdUBkR7PFNleEm=nQ7P47z2PkQGqFQdWFCnE=heRRaZYks/7cQQy+DOHdqWUHCBviqy44mhSW9djb/nuRe71K07ibT4b4UuefvBWnQl2L8mGj4LA+gCvzRbg84czpumImzm9/xCtoHQgQCp3qOZ+o6ee=xoFQgqdWlIPtubtP8Gfoi2xty9NygQgR+bpihmbPSyDOjefiKyQZommom0cT5+we8uGTFOgbrLihvWVxNoprgRPxKW3yfY4m9pV/4WGmiPTgIxqqlhYQ5txDKLDtYCIAPYOP0Oe5k2=K3hOTvTG7Ywq0xD7=DY9xeD==; ssxmod_itna=eq0xcDuiD=DQYiIK0Lc7tD9DRE6oiYoYdd77Dl=7QxA5D8D6DQeGTT2deWbiK=eDCqfsYIBdTqapWtY7whq8AmSoDHxY=DUPObIoD4fKGwD0eG+DD4DWDmmFDnxAQDjxGpnXvTs=DEDmb8DWPDYxDrE=KDRxi7DDyd7x07DQH8OGiqEOYF33vm0hGhqQi8D75pDlpxEfEwfR8qBOAAm/53wx0kg40OnoHz8ooDU0IzcZyrdG4eI0qxT7G3YW0KtGiKIQDehmrx7uq4Yj2TxgenHirS4D','Referer': 'https://we.51job.com/pc/search?keyword=python&searchType=3&sortType=0&metro=','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
# 请求链接
url = 'https://we.51job.com/api/job/search-pc'
# 请求参数
data = {'api_key': '51job','timestamp': '1690982356','keyword': 'python','searchType': '2','function': '','industry': '','jobArea': '000000','jobArea2': '','landmark': '','metro': '','salary': '','workYear': '','degree': '','companyType': '','companySize': '','jobType': '','issueDate': '','sortType': '0','pageNum': '1','requestId': '','pageSize': '20','source': '1','accountId': '','pageCode': 'sou|sou|soulb',
}response = requests.get(url=url, params=data, headers=headers)
print(response)
调用requests模块里面get请求方法, 对于url地址发送请求,
并且携带上headers请求头伪装, 最后用response自定义变量接受返回数据
解析数据
字典取值 --> 键值对取值:根据冒号左边的内容[键], 提取冒号右边的内容[值]
for 循环遍历提取 index 是自定义变量, 用于接受列表里面元素
list_data = response.json()['resultbody']['job']['items']
for index in list_data:# index 字典dit = {'职位': index['jobName'],'公司': index['fullCompanyName'],'薪资': index['provideSalaryString'],'城市': index['jobAreaString'],'经验': index['workYearString'],'学历': index['degreeString'],'公司性质': index['companyTypeString'],'公司规模': index['companySizeString'],'公司领域': index['industryType1Str'],'标签': ','.join(index['jobTags']),'职位详情页': index['jobHref'],'公司详情页': index['companyHref'],}print(dit)
保存到csv
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
f = open('python.csv', mode='w', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['职位','公司','薪资','城市','经验','学历','公司性质','公司规模','公司领域','标签','职位详情页','公司详情页',
])
csv_writer.writeheader()

数据可视化展示
Python学历要求
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
c = (Pie().add("",[list(z)for z in zip(edu_type,edu_num)],center=["40%", "50%"],).set_global_opts(title_opts=opts.TitleOpts(title="Python学历要求"),legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.load_javascript()

Python招聘城市分布
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
c = (Pie().add("",[list(z)for z in zip(city_type,city_num)],center=["40%", "50%"],).set_global_opts(title_opts=opts.TitleOpts(title="Python招聘城市分布"),legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()

Python工作薪资\n\n最低薪资区间
pie1 = (Pie(init_opts=opts.InitOpts(theme='dark',width='1000px',height='600px')).add('', datas_pair_1, radius=['35%', '60%']).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%")).set_global_opts(title_opts=opts.TitleOpts(title="Python工作薪资\n\n最低薪资区间", pos_left='center', pos_top='center',title_textstyle_opts=opts.TextStyleOpts(color='#F0F8FF', font_size=20, font_weight='bold'),)).set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8', '#00BFFF', '#7FFFAA'])
)
pie1.render_notebook()

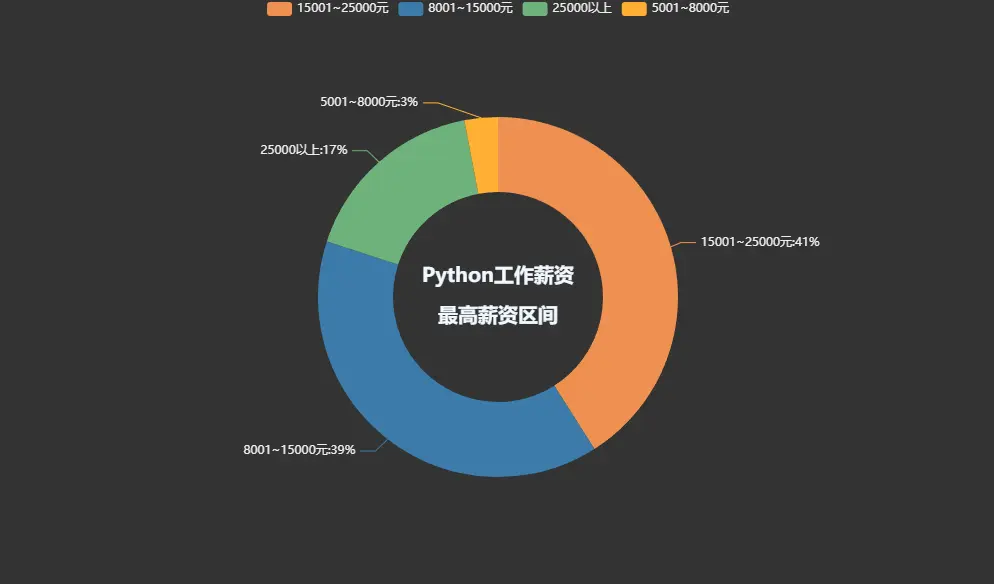
Python工作薪资\n\n最高薪资区间
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
pie1 = (Pie(init_opts=opts.InitOpts(theme='dark',width='1000px',height='600px')).add('', datas_pair_2, radius=['35%', '60%']).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%")).set_global_opts(title_opts=opts.TitleOpts(title="Python工作薪资\n\n最高薪资区间", pos_left='center', pos_top='center',title_textstyle_opts=opts.TextStyleOpts(color='#F0F8FF', font_size=20, font_weight='bold'),)).set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8', '#00BFFF', '#7FFFAA'])
)
pie1.render_notebook()
Python招聘经验要求
exp_type = df['经验'].value_counts().index.to_list()
exp_num = df['经验'].value_counts().to_list()
c = (Pie().add("",[list(z)for z in zip(exp_type,exp_num)],center=["40%", "50%"],).set_global_opts(title_opts=opts.TitleOpts(title="Python招聘经验要求"),legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()

各大城市Python低平均薪资
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
from pyecharts.charts import Bar
# 创建柱状图实例
c = (Bar().add_xaxis(CityType).add_yaxis("", CityNum).set_global_opts(title_opts=opts.TitleOpts(title="各大城市Python低平均薪资"),visualmap_opts=opts.VisualMapOpts(dimension=1,pos_right="5%",max_=30,is_inverse=True,),xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)) # 设置X轴标签旋转角度为45度).set_series_opts(label_opts=opts.LabelOpts(is_show=False),markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="min", name="最小值"),opts.MarkLineItem(type_="max", name="最大值"),opts.MarkLineItem(type_="average", name="平均值"),]),)
)c.render_notebook()

各大城市Python高平均薪资
# 创建柱状图实例
c = (Bar().add_xaxis(CityType_1).add_yaxis("", CityNum_1).set_global_opts(title_opts=opts.TitleOpts(title="各大城市Python高平均薪资"),visualmap_opts=opts.VisualMapOpts(dimension=1,pos_right="5%",max_=30,is_inverse=True,),xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)) # 设置X轴标签旋转角度为45度).set_series_opts(label_opts=opts.LabelOpts(is_show=False),markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="min", name="最小值"),opts.MarkLineItem(type_="max", name="最大值"),opts.MarkLineItem(type_="average", name="平均值"),]),)
)c.render_notebook()

Python招聘企业公司性质分布
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:926207505
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
from pyecharts.charts import Bar # 导入pyecharts里面柱状图
from pyecharts.faker import Faker # 导入随机生成数据
from pyecharts.globals import ThemeType # 主题设置c = (Bar({"theme": ThemeType.MACARONS}) # 主题设置.add_xaxis(c_type) # x轴数据.add_yaxis("", c_num) # Y轴数据.set_global_opts(# 标题显示title_opts={"text": "Python招聘企业公司性质分布", "subtext": "民营', '已上市', '外资(非欧美)', '合资', '国企', '外资(欧美)', '事业单位'"})# 保存html文件
# .render("bar_base_dict_config.html")
)
# print(Faker.choose()) # ['小米', '三星', '华为', '苹果', '魅族', 'VIVO', 'OPPO'] 数据类目
# print(Faker.values()) # [38, 54, 20, 85, 71, 22, 38] 数据个数
c.render_notebook() # 直接显示在jupyter上面

尾语
最后感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。





![[python 刷题] 974 Subarray Sums Divisible by K](https://img-blog.csdnimg.cn/e95817a874eb47069ad80b9dda2c3fbe.jpeg#pic_center)