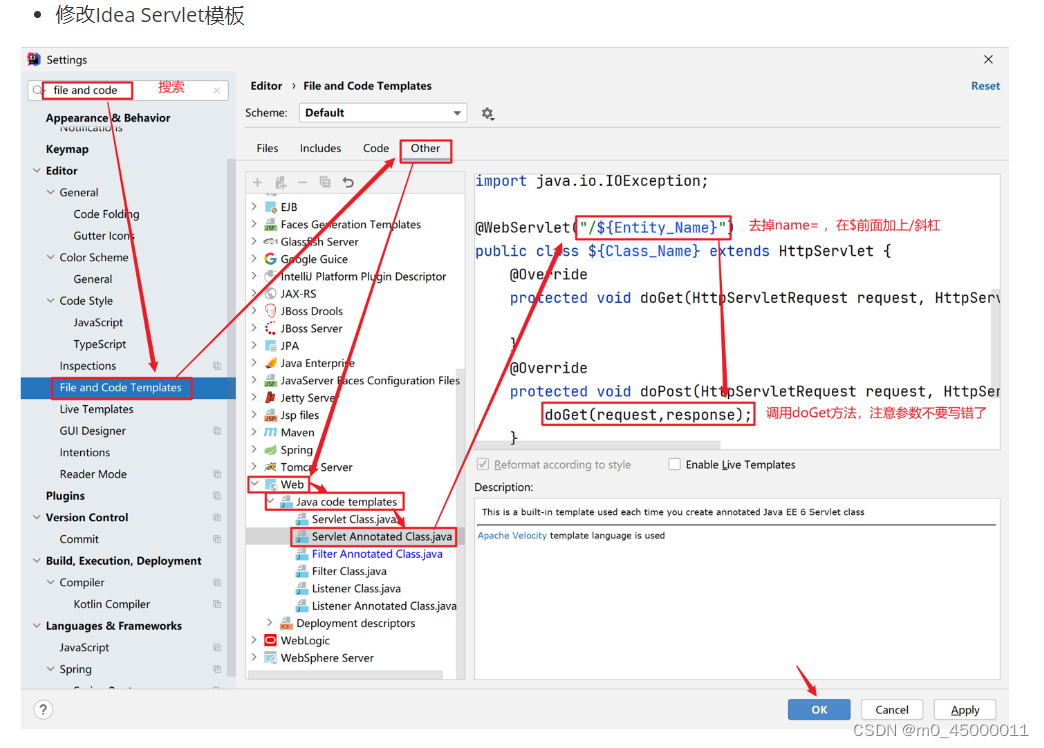
目录
前言
一、结构体
1. 基本定义与使用
2. 内存对齐
3. 自定义对齐数
4. 函数传参
二、位段
三、枚举
四、联合(共同体)
总结
前言
本篇博客将介绍C语言中的结构体(struct)、枚举(enum)和联合(union)这三种复合数据类型。结构体用于将多个不同类型的数据组合在一起,枚举定义一组相关常量,而联合允许不同的成员变量共用相同的内存空间。我们将详细讨论它们的基本定义与使用、内存对齐、自定义对齐数、函数传参、位段等概念和用法。
一、结构体
1. 基本定义与使用
结构体的定义有多种形式,但本质上是相似的,常见定义方式如下(以描述学生为例):
(1)基本定义
struct Stu
{char* name;char* stu_id;double score;
};(2)定义时顺便定义结构体变量
struct Stu
{char* name;char* stu_id;double score;
}s1,s2,s3;
// s1, s2, s3作为全局变量存在,其类型为(struct Stu)(3)匿名定义(无结构体类型名)
struct // 省略类型名
{char* name;char* stu_id;double score;
}s;当然上面这种匿名定义方法需要像方式(2) 那样初始化定义出结构体变量,以便后续使用,否则匿名结构体在脱离初始化状态后无法再生成与之对应的结构体变量。
(4)利用 typedef 起别名定义
typedef struct Stu
{char* name;char* stu_id;double score;
}Stu;
// 可以形象理解为 typedef (struct Stu) Stu
// 后面的Stu是对前面结构体类型名struct Stu起的别名可能这种定义方法和方式(1) 看起来相似,但在具体使用时可以帮助我们省去很多麻烦,尤其是在非定义结构体时初始化状态定义结构体变量时,类型名可以直接简写为起的别名。
定义结构体变量:
除了定义结构体时初始化状态定义外,后续同样可以对非匿名结构体定义对应的结构体变量:
// 无typedef时 --- 定义方法1
struct Stu s4;
// 利用typedef后 --- 定义方法4
Stu s5;基本使用方法:
typedef struct Stu
{char* name;char* stu_id;double score;
}Stu;int initStu(Stu* s)
{s->name = (char*)malloc(sizeof(char) * 10);s->stu_id = (char*)malloc(sizeof(char) * 15);s->score = 0;if (!s->name || !s->stu_id) { perror("malloc"); return 0; } // 分配堆区内存失败return 1;
}void test1()
{Stu s1;if (!initStu(&s1)) { printf("初始化失败\n"); }
}以上面代码为例,用途是对后续定义的结构体变量初始化(或为指针分配空间为变量赋零值),可以看到使用方法和内置类型基本相同,只是对结构体变量内部成员访问时,由于和结构体变量绑定需要利用结构体对象才能实现访问并进行相关操作。当然,结构体类型的变量作为函数参数进行传递时,最好以指针形式传递,避免拷贝该类型局部变量,可以提高效率,同时必要场景比如函数内部对该变量的成员变量作更改时,也离不开指针传递。
2. 内存对齐
为什么存在内存对齐:
1. 平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。2. 性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。
原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
内存对齐是什么?
结构体的对齐规则:
1. 第一个成员在与结构体变量偏移量为0的地址处。
2. 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值
3. 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
4. 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
来看下面一段代码帮助我们深刻理解内存对齐的概念:
typedef struct A1
{char a;double b;int c;
}A1;
typedef struct A2
{char a;int c;double b;
}A2;
void test2()
{A1 st1;A2 st2;printf("size of A1 and A2 = %zd\t%zd\n", sizeof(st1), sizeof(st2));
}我们注意到两个结构体内部变量类型和数量均相同,仅仅是声明顺序的不同,那对两者类型下的变量大小是多少字节呢?
运行结果:
![]()
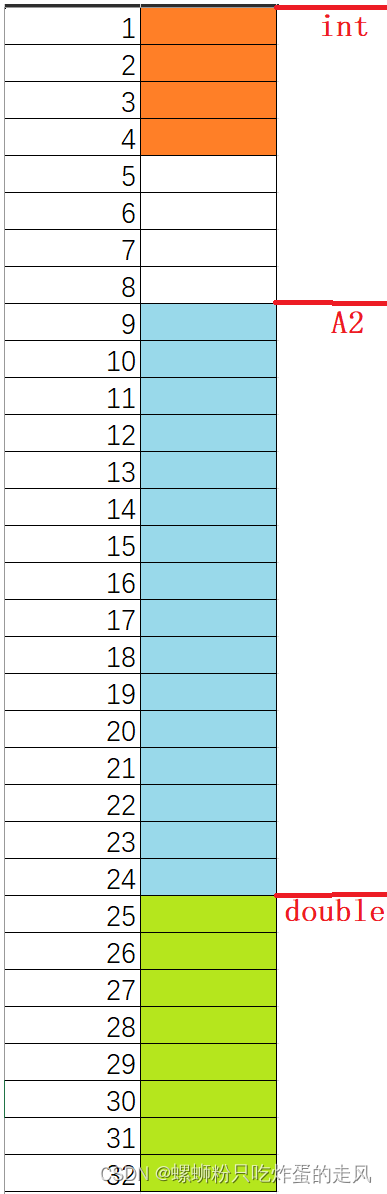
我们画出两者的内存存储形式:
A1: A2:
A2:
显然,由于结构体整体大小需要是最大对齐数的整数倍,A1还需要浪费(21、22、23、24)四个字节的空间,为什么A1中double元素声明为第二位,所以在一个对齐数即这里的(1-8)不足以同时容纳char和double类型时,就需要从下一个对齐位开始存放。
那要是嵌套结构体的大小又该如何计算呢?
typedef struct A2
{char a;int c;double b;
}A2;
typedef struct A3
{char a;A2 st_a2;double b;
};
void test2()
{A3 st3;printf("size of A3 = %zd\n", sizeof(st3));
}运行结果:
![]()
为什么是32不是48字节呢?
这是因为结构体嵌套中,内部结构体以结构体变量并非结构体指针变量存储在外部结构体中时,所占字节数就是正常 sizeof(内部结构体实例化变量) 的值,所以此处 st_a2 的大小为 16 字节是毋庸置疑的,需要注意的是,该内部结构体变量的对齐数仍然是结构体自身内部变量中对齐数最大的值。这就导致对结构体A3来说,对齐数是8并非16,所以不会出现 16*3 = 48 的情况。
3. 自定义对齐数
通过上面内存对齐的示例,我们了解到对齐数的具体概念,以及VS平台下对齐数默认值为8,那么我们是否可以通过自定义对齐数的方式来节省内存占用呢?
用于分配内存的总对齐数 = 结构体内部变量中最大对齐数 和 设定对齐数的最小值
来看下面两段代码,我们自定义程序对齐数,看看实际使用时是否能够帮助我们节省空间:
#pragma pack(8) // 设置默认对齐数为8
typedef struct S1
{char c1;int i;char c2;
}S1;
#pragma pack() // 取消设置的默认对齐数,还原为默认#pragma pack(1) // 设置默认对齐数为1
typedef struct S2
{char c1;int i;char c2;
}S2;
#pragma pack() // 取消设置的默认对齐数,还原为默认void test3()
{printf("size of S1 and S2 = %zd\t%zd\n", sizeof(S1), sizeof(S2));
}运行结果:
![]()
首先我们分析两者各自实际用于内存对齐的对齐数是多少?
S1:内部变量最大对齐数 = 4 设定对齐数 = 8 两者最小值:4
S2:内部变量最大对齐数 = 4 设定对齐数 = 1 两者最小值:1
通过两者对齐数,我们可以简单的画出内存占用示意图:
S1: S2:
S2: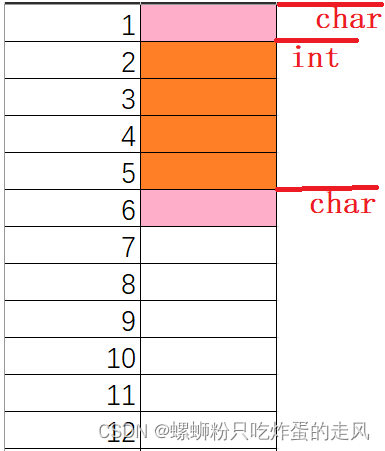
这样我们便不难理解内存对齐的实际含义,也了解到适当利用自定义最大对齐数可以起到节省内存的作用。当结构在对齐方式不合适的时候,我么可以自己更改默认对齐数。
4. 函数传参
不可避免地,自定义类型即这里提到的结构体也需要像内置类型一样在函数中实现特定操作,那就涉及到结构体作为函数参数进行函数传参的问题,来看以下代码:
typedef struct S
{int data[1000];int num;
}S;
S s = { {1,2,3,4}, 1000 };// 结构体传参 -- 传值
void print1(S s)
{printf("%d\n", s.num);
}
// 结构体地址传参 -- 传址
void print2(S* ps)
{printf("%d\n", ps->num);
}
void test4()
{print1(s);print2(&s);
}运行结果:
![]()
可以看到当结构体变量需要传入函数时,可以通过传值或传址实现,但是我们对于非内置类型即自定义类型最好使用传址方式传入函数,因为当传值传入函数时,函数内部会创建一个临时变量即形参来接受传入的实参,多了构造一个结构体变量的过程,从而产生内存和时间的损耗。函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。
详见:选择指针调用时机概述
当然,指针传递为了避免函数内误修改,可以在指针变量前加上const关键字修饰,如下:
void function_read(const S* s) // 举例实现一个只执行读取操作的函数
{int i = 0;while (s->data[i] != 0){printf("%d\t", s->data[i++]);}//s->data[i] = 1; // 编译报错
}
void test5()
{function_read(&s);
}这样我们既能减少内存占用,加快程序运行速度,又能兼顾安全性,防止不必要的修改外界变量。
二、位段
本来位段是属于结构体部分的内容,但是由于避免结构体部分内容太过冗杂,所以将其拆分叙述,首先我们需要知道什么是位段:
1.位段的成员必须是int、unsigned int 或signed int 。
2.位段的成员名后边有一个冒号和一个数字。
比如:
typedef struct SS
{int _a : 2;int _b : 5;int _c : 10;int _d : 30;
}SS;
void test6()
{printf("size of SS = %d\n", sizeof(SS));
}运行结果:
![]()
我们认识到位段在变量后设定的数字代表给其分配的字节数,结构体占的总字节数即后面数字相加所得。那如果在32位系统下,给 int 类型变量分配超过 4*8=32 字节呢,结构体到底将该变量的所占字节按照设定字节值计算还是按照正常的32字节处理?
尝试超越设定:
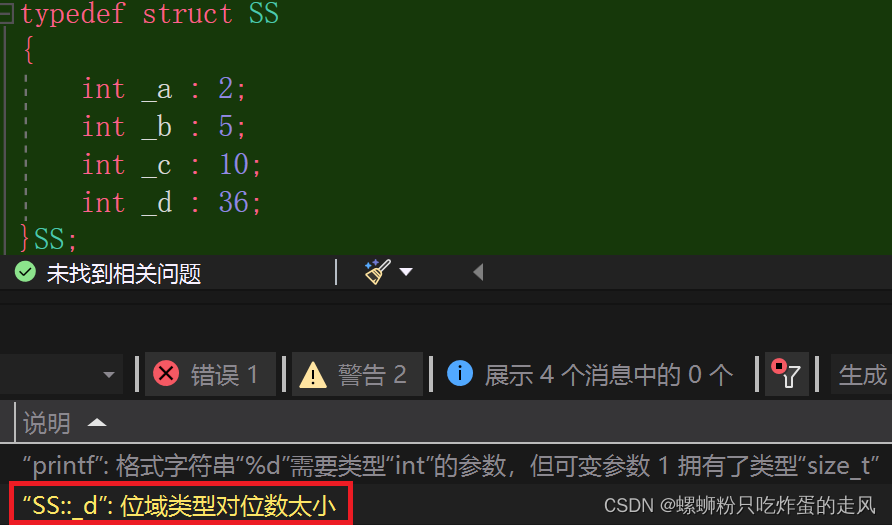
在编译时报错,说明编译器并没有放过此漏洞,印证了设定值不能超过常值。
注意点:
1. 位段的成员可以是int、unsigned int、signed int 或者是 char(属于整形家族)类型
2. 位段的空间上是按照需要以4个字节( int )或者1个字节( char )的方式来开辟的。
3. 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段。
来看下面一段代码:
typedef struct Sa
{char a : 3;char b : 4;char c : 5;char d : 4;
}Sa;
void test7()
{Sa s = { 0 };s.a = 10;s.b = 12;s.c = 3;s.d = 4;printf("%d %d %d %d", s.a, s.b, s.c, s.d); // 以整数形式打印利于观察
}运行结果:
![]()
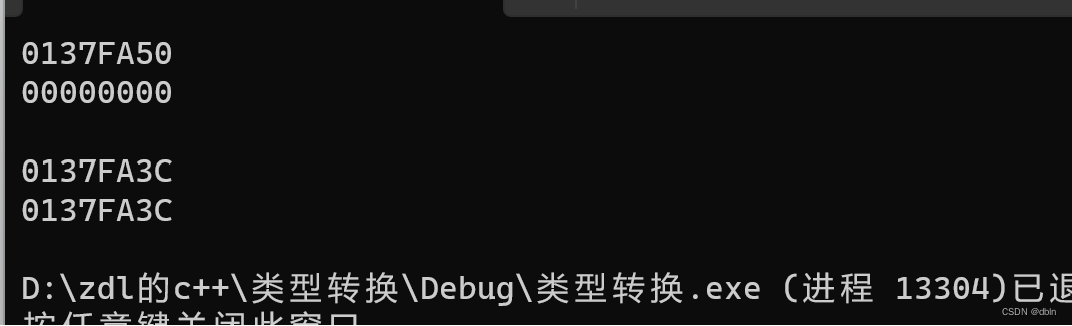
为什么会出现这样的情况呢?莫急,接着按照我们给每个字符型变量分配的字节入手,从二进制赋值方面观察:

得到实际内存中存储的二进制编码,我们打开内存窗口检验判断是否正确:
![]()
由此,可以知道我们判断是正确的,那为什么会出现运行窗口的数字,尤其是-4呢,我们只需要照猫画虎将二进制序列按位段分配的比特位读取即可,则有:

将各个变量内存储的二进制编码按照有符号类型读取,即为控制台输出的值。
三、枚举
枚举顾名思义就是一一列举。 把可能的取值一一列举。
enum Day // 星期
{Mon,Tues,Wed,Thur,Fri,Sat,Sun
};以上 Day 就是一个枚举类型,像这样的 {} 内的元素称为枚举常量。
这些可能取值都是有值的,默认从0开始,一次递增1,当然在定义的时候也可以赋初值。
比如:
enum Color // 颜色
{RED = 1,GREEN = 2,BLUE = 4
};需要注意的是,枚举常量之间需要用逗号隔开,而不是分号!
枚举的优点:
1. 增加代码的可读性和可维护性
2. 和#define定义的标识符比较枚举有类型检查,更加严谨。
3. 防止了命名污染(封装)
4. 便于调试
5. 使用方便,一次可以定义多个常量
枚举使用注意点:
enum Color // 颜色
{RED = 1,GREEN = 2,BLUE = 4
};
void test8()
{RED = 100; // 类似于 define 不可重赋值
}四、联合(共同体)
这种类型定义的变量也包含一系列的成员,特征是这些成员公用同一块空间(所以联合也叫共用体)。
比如:
//联合类型的声明
typedef union Un
{char c;int i;
}Un;
//联合变量的定义
Un un;
void test9()
{//计算连个变量的大小printf("%d\n", sizeof(un));
}运行结果:
![]()
我们换一种方式测试两变量的地址是否相同,即可更好印证两者公用一块内存空间:
void test9()
{//计算连个变量的大小printf("%d\n", sizeof(un));//打印地址printf("address of 'c' and 'i' = %p and %p\n", &un.c, &un.i);
}运行结果:
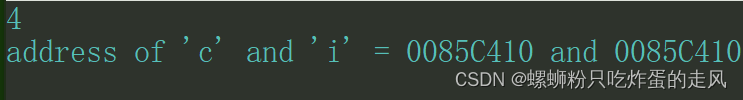
可以看到两者的首地址相同。
联合的成员是共用同一块内存空间的,这样一个联合变量的大小,至少是最大成员的大小(因为联
合至少得有能力保存最大的那个成员)
来看下面一段代码:
void test9()
{//下面输出的结果是什么?un.i = 0x11223344;un.c = 0x55;printf("%x\n", un.i);
}运行结果:
![]()
由于本机器为小端机器,所以 i 在内存中的存储实际上是:
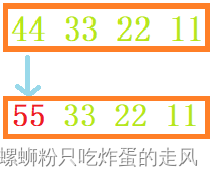
相当于我们改变字符 c 的值即改变整形变量 i 的首个字节的值。
面试题:
利用联合判断机器是大端还是小端。
// 判断机器大小端
int check_sys()
{union U{char c;int i;};union U un;un.i = 0x00000001;un.c = 0;return un.i;
}
void test10()
{if (check_sys()) { printf("大端\n"); }else{printf("小端\n");}
}如果返回值为0x00000001,则表示机器是大端序;如果返回值为0,则表示机器是小端序。
联合大小计算:
void test11()
{union Un1{char c[5];int i;};union Un2{short c[7];int i;};//下面输出的结果是什么?printf("size of Un1 = %d\n", sizeof(union Un1));printf("size of Un2 = %d\n", sizeof(union Un2));
}运行结果:
![]()
我们得知,联合大小有以下规则:
- 联合的大小至少是最大成员的大小。
- 当最大成员大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍。
总结
通过本篇文章我们详细介绍了C语言中的结构体、枚举和联合这三种复合数据类型。结构体可以将多个不同类型的数据组合在一起,方便地管理和访问这些数据;枚举用于定义一组相关常量,简化代码中对离散值的表示;联合允许不同的成员变量共用相同的内存空间,节省内存开销。我们还讨论了内存对齐、自定义对齐数、函数传参、位段等相关概念和用法。通过理解和掌握这些知识,我们可以更好地利用C语言的复合数据类型,提高程序的效率和可读性。