音频处理发现的比较简单的代码,原作者代码在github:GitHub - silencesmile/python_wav: 对音频文件的处理:音频信息,读取内容,获取时长,切割音频,pcm与wav互转
可以按给定的开始和结束时间调用代码批处理,示例:
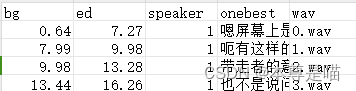
这是原音频文件的信息存储在csv文件,目标是按照给定的开始结束时间切割成多个小的音频片段
bg列为开始时间单位为秒,ed列为结束时间单位为秒,wav列为想要的音频片段命名
批处理代码,调用了get_second_part_wav函数:
from pydub import AudioSegment
def get_second_part_wav(main_wav_path, start_time, end_time,part_wav_path):# 原音频文件路径,开始时间,结束时间,切分音频的存储路径start_time = int(start_time) * 1000end_time = int(end_time) * 1000sound = AudioSegment.from_file(main_wav_path)word = sound[start_time:end_time]word.export(part_wav_path, format="wav")audio_teacher = pd.read_csv('try1.csv', encoding='utf-8')
start_list = audio_teacher['bg'].tolist()
end_list = audio_teacher['ed'].tolist()
wav_list = audio_teacher['wav'].tolist()for i in range(len(start_list)):start_time = start_list[i]end_time = end_list[i]get_second_part_wav('audio/try1.mp4', start_time, end_time, 'audio_sep/' + str(wav_list[i]))原作者的可以根据需要调用的代码 :
# -*- coding:utf8 -*-
'''
auth: Young
公众号:Python疯子 (Hold2Crazy)
'''
import wave
import contextlib
import numpy as np
import matplotlib.pyplot as pltfrom scipy.io import wavfile
from pydub import AudioSegmentdef wav_infos(wav_path):'''获取音频信息:param wav_path: 音频路径:return: [1, 2, 8000, 51158, 'NONE', 'not compressed']对应关系:声道,采样宽度,帧速率,帧数,唯一标识,无损'''with wave.open(wav_path, "rb") as f:f = wave.open(wav_path)return list(f.getparams())def read_wav(wav_path):'''读取音频文件内容:只能读取单声道的音频文件, 这个比较耗时:param wav_path: 音频路径:return: 音频内容'''with wave.open(wav_path, "rb") as f:# 读取格式信息# 一次性返回所有的WAV文件的格式信息,它返回的是一个组元(tuple):声道数, 量化位数(byte单位), 采# 样频率, 采样点数, 压缩类型, 压缩类型的描述。wave模块只支持非压缩的数据,因此可以忽略最后两个信息params = f.getparams()nchannels, sampwidth, framerate, nframes = params[:4]# 读取声音数据,传递一个参数指定需要读取的长度(以取样点为单位)str_data = f.readframes(nframes)return str_datadef get_wav_time(wav_path):'''获取音频文件是时长:param wav_path: 音频路径:return: 音频时长 (单位秒)'''with contextlib.closing(wave.open(wav_path, 'r')) as f:frames = f.getnframes()rate = f.getframerate()duration = frames / float(rate)return durationdef get_ms_part_wav(main_wav_path, start_time, end_time, part_wav_path):'''音频切片,获取部分音频 单位是毫秒级别:param main_wav_path: 原音频文件路径:param start_time: 截取的开始时间:param end_time: 截取的结束时间:param part_wav_path: 截取后的音频路径:return:'''start_time = int(start_time)end_time = int(end_time)sound = AudioSegment.from_file(main_wav_path)word = sound[start_time:end_time]word.export(part_wav_path, format="wav")def get_second_part_wav(main_wav_path, start_time, end_time, part_wav_path):'''音频切片,获取部分音频 单位是秒级别:param main_wav_path: 原音频文件路径:param start_time: 截取的开始时间:param end_time: 截取的结束时间:param part_wav_path: 截取后的音频路径:return:'''start_time = int(start_time) * 1000end_time = int(end_time) * 1000sound = AudioSegment.from_file(main_wav_path)word = sound[start_time:end_time]word.export(part_wav_path, format="wav")def get_minute_part_wav(main_wav_path, start_time, end_time, part_wav_path):'''音频切片,获取部分音频 分钟:秒数 时间样式:"12:35":param main_wav_path: 原音频文件路径:param start_time: 截取的开始时间:param end_time: 截取的结束时间:param part_wav_path: 截取后的音频路径:return:'''start_time = (int(start_time.split(':')[0])*60+int(start_time.split(':')[1]))*1000end_time = (int(end_time.split(':')[0])*60+int(end_time.split(':')[1]))*1000sound = AudioSegment.from_file(main_wav_path)word = sound[start_time:end_time]word.export(part_wav_path, format="wav")def wav_to_pcm(wav_path, pcm_path):'''wav文件转为pcm文件:param wav_path:wav文件路径:param pcm_path:要存储的pcm文件路径:return: 返回结果'''f = open(wav_path, "rb")f.seek(0)f.read(44)data = np.fromfile(f, dtype=np.int16)data.tofile(pcm_path)def pcm_to_wav(pcm_path, wav_path):'''pcm文件转为wav文件:param pcm_path: pcm文件路径:param wav_path: wav文件路径:return:'''f = open(pcm_path,'rb')str_data = f.read()wave_out=wave.open(wav_path,'wb')wave_out.setnchannels(1)wave_out.setsampwidth(2)wave_out.setframerate(8000)wave_out.writeframes(str_data)# 音频对应的波形图
def wav_waveform(wave_path):'''音频对应的波形图:param wave_path: 音频路径:return:'''file = wave.open(wave_path)# print('---------声音信息------------')# for item in enumerate(WAVE.getparams()):# print(item)a = file.getparams().nframes # 帧总数f = file.getparams().framerate # 采样频率sample_time = 1 / f # 采样点的时间间隔time = a / f # 声音信号的长度sample_frequency, audio_sequence = wavfile.read(wave_path)# print(audio_sequence) # 声音信号每一帧的“大小”x_seq = np.arange(0, time, sample_time)plt.plot(x_seq, audio_sequence, 'blue')plt.xlabel("time (s)")plt.show()