NLP实践——中文指代消解方案
- 1. 参考项目
- 2. 数据
- 2.1 生成conll格式
- 2.2 生成jsonline格式
- 3. 训练
- 3.1 实例化模型
- 3.2 读取数据
- 3.3 评估方法
- 3.4 训练方法
- 4. 推理
- 5. 总结
1. 参考项目
关于指代消解任务,有很多开源的项目和工具可以借鉴,比如spacy的基础模型,就包含了指代消解的功能,一般来讲,这些模型多是在Ontonotes 5.0的数据集上进行训练的。然而,尽管Ontonotes 5.0数据中也提供了中文数据,但相比英文指代消解模型,中文的可以直接使用的指代消解模型却不那么容易找到。
在这篇参考文档(https://chinesenlp.xyz/#/zh/docs/co-reference_resolution)中,介绍了现有的中文指代消解相关论文,下图是其中一些参考工作的得分指标。

关于指代消解任务的评测指标以及python版本的实现方法,在之前的博客 共指消解评测方法详解与python实现 中也有过介绍,感兴趣的同学可以阅读。
但是在上文提到的参考文献中,也没有找到很方便可以直接下载使用的模型,所以选择了利用之前的一个方案,在中文数据上重新训练一下。选择的方案是2021年的一篇论文《Coreference Resolution without Span Representations》,其项目又名s2e-coref,是指代消歧任务的一个经典工作。
- 论文地址:https://www.semanticscholar.org/reader/3029263ca51e6c2907f9f99277083cf6afb1adb7
- 项目地址:https://github.com/yuvalkirstain/s2e-coref
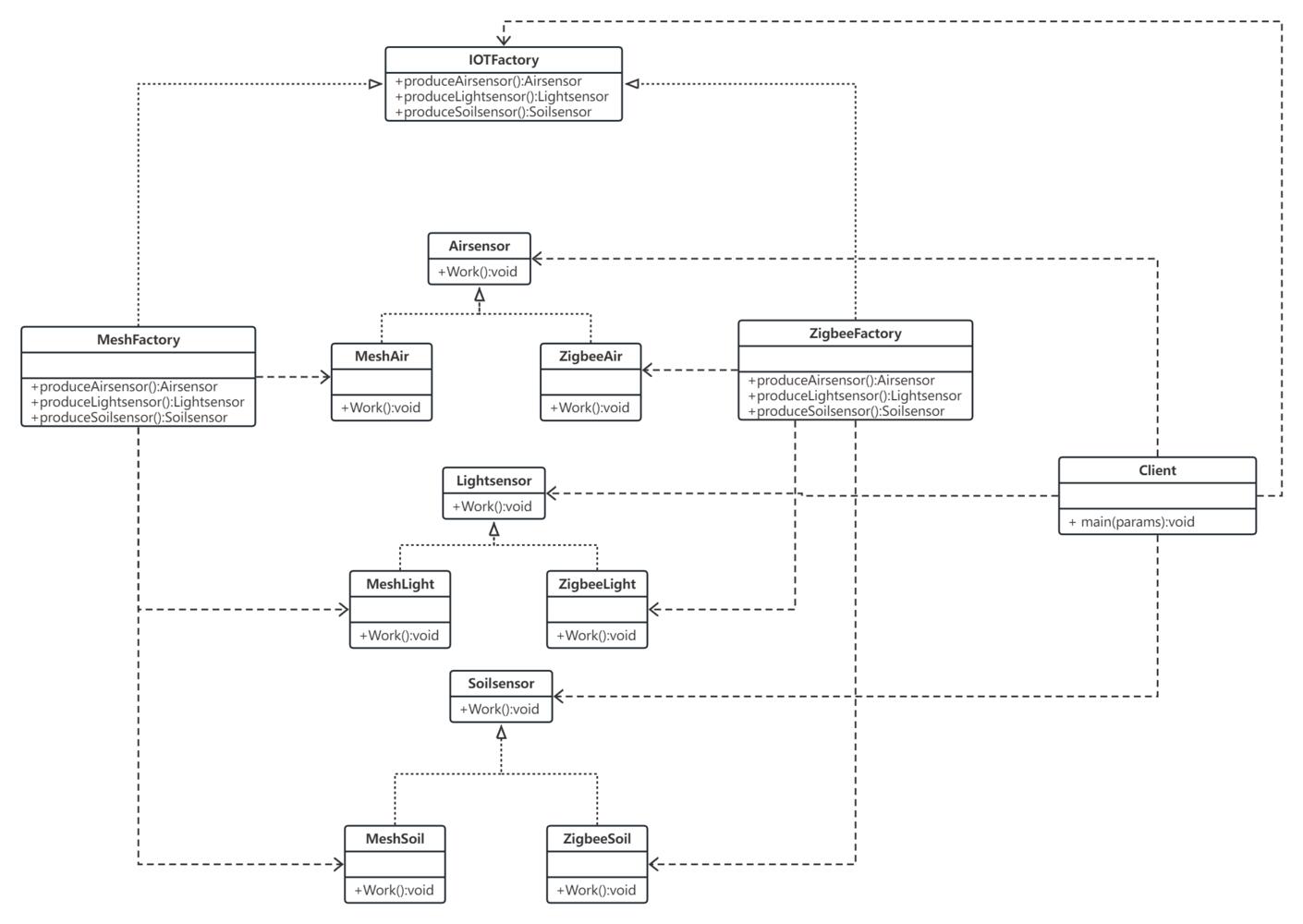
论文中没有给出模型结构的图,为了方便理解,这里我简单画一下:

此图只作为示意帮助理解,具体结构还要结合代码一起看。总的来说,就是在seq维度上,做了交互特征,然后选取topk,利用topk的索引去gather另一个linear的结果,最后拼接成一个final_logits,在解码阶段使用final_logits中,以此取max,回到topk_start_ids和topk_end_ids进行解码。
项目中给出了训练好的英文模型的直接下载地址,而对于中文模型,则需要自己去训练一下。接下来就详细介绍训练和推理的方法。
2. 数据
2.1 生成conll格式
数据采用的是Ontonotes,此数据虽然不需要付费,但是需要在LDC上申请,操作并不复杂。
参考知乎文章:https://zhuanlan.zhihu.com/p/121786025
按照文中的步骤操作即可。分别下载conll数据和ontonotes数据,然后进入conll-2012/v3/script,执行skeleton2conll.sh -D [path/to/conll-2012-train-v0/data/files/data] [path/to/conll-2012],注意这里的两个路径,分别是下载的ontonotes 5.0,解压之后的data目录,以及conll数据解压之后的v4/data目录。
执行完之后,会在各个小文件夹之下,如v4/data/train/data/chinese/annotations/bc/cctv/00,生成*_conll文件。需要注意的是脚本是python2写的,所以要把所有的print都注释掉,否则语法报错。
然后再在/conll-2012/v4/data/train [development| test]中分别创建merge.py,放入参考的知乎链接中的代码,将所有conll文件合并,最终生成了train [development| test].chinese.v4_gold_conll这3个文件,也就是用于s2e_coref项目的输入数据。
2.2 生成jsonline格式
在生成conll格式的数据之后,还需要根据s2e_coref项目的要求,进行预处理格式转换:
python minimize.py $DATA_DIR
其中minimize.py是s2e_coref项目中提供的脚本,DATA_DIR是转换好的conll格式的数据,经过这个转换之后,就把数据转换成了jsonline格式。(在这一步转换时我遇到了test数据的转换错误,由于不影响训练评估,所以就没有再花时间去解决报错的问题)
在minimize.py中,需要把english修改为chinese:
if __name__ == "__main__":data_dir = sys.argv[1]labels = collections.defaultdict(set)stats = collections.defaultdict(int)# minimize_language(data_dir, "english", labels, stats)minimize_language(data_dir, "chinese", labels, stats)# minimize_language("arabic", labels, stats)for k, v in labels.items():print("{} = [{}]".format(k, ", ".join("\"{}\"".format(label) for label in v)))for k, v in stats.items():print("{} = {}".format(k, v))
然后会在DATA_DIR中生成train.chinese.jsonlines和dev.chinese.jsonlines。
3. 训练
3.1 实例化模型
训练部分没有直接使用项目中给出的python run_coref.py,而是放在jupyter中方便调试。
首先,实例化模型。原项目中采用的longformer,所以这里就直接去HF上找一个中文版本的longformer:
https://huggingface.co/ValkyriaLenneth/longformer_zh
但是其中的Tokenizer没有做很详细的说明,经过了一番尝试之后,发现直接使用BertTokenizer实例化即可(后续会遇到一点问题但是可以解决):
from transformers import BertTokenizer, AutoConfig, LongformerConfig
from modeling import S2E # 从项目中的py引用# 先实例化一个config
config = AutoConfig.from_pretrained('YOUR_PATH_TO/longformer_zh') # 下载的longformer模型的地址
S2E.config_class = LongformerConfig
S2E.base_model_prefix = 'longformer'# 然后由于是jupyter执行,写一个辅助的参数类:
class Args:def __init__(self,model_name_or_path: str,model_type: str = 'longformer',tokenizer_name: str = 'allenai/longformer-large-4096',max_seq_length: int = 4096,dropout_prob: float = 0.3,top_lambda: float = 0.4,max_span_length: int = 30,max_total_seq_len: int = 5000,ffnn_size: int = 3072,normalise_loss: bool = True):self.model_type = model_typeself.model_name_or_path = model_name_or_pathself.tokenizer_name = tokenizer_nameself.max_seq_length = max_seq_lengthself.dropout_prob = dropout_probself.top_lambda = top_lambdaself.max_span_length = max_span_lengthself.ffnn_size = ffnn_sizeself.normalise_loss = normalise_lossself.max_total_seq_len = max_total_seq_len# 然后实例化参数类
args = Args('YOUR_PATH_TO/longformer_zh')# 实例化模型和tokenizer,会报一些warning,不用管它
tokenizer = BertTokenizer.from_pretrained('YOUR_PATH_TO/longformer_zh')
model = S2E.from_pretrained('YOUR_PATH_TO/longformer_zh',config=config,args=args)
model.to('cuda:0')
3.2 读取数据
实例化模型之后,读取数据集:
from data import CorefDataset # 从项目的data.py引用数据类train_file = 'train.chinese.jsonlines' # 之前转换的jsonline数据
dev_file = 'dev.chinese.jsonlines'train_dataset = CorefDataset(train_file, tokenizer, 4096)
dev_dataset = CorefDataset(dev_file, tokenizer, 4096)
3.3 评估方法
模型的评估方法直接从项目源码部分截取,然后删除不必要的部分:
import json
import os
import logging
import random
from collections import OrderedDict, defaultdict
import numpy as np
import torch
from coref_bucket_batch_sampler import BucketBatchSampler
from data import get_dataset
from metrics import CorefEvaluator, MentionEvaluator
from utils import extract_clusters, extract_mentions_to_predicted_clusters_from_clusters, extract_clusters_for_decode
from conll import evaluate_conll# logger = logging.getLogger(__name__)class Evaluator:def __init__(self, args, tokenizer):self.args = args# self.eval_output_dir = args.output_dirself.tokenizer = tokenizerdef evaluate(self, model, eval_dataset, prefix="", tb_writer=None, global_step=None, official=False):# eval_dataset = get_dataset(self.args, tokenizer=self.tokenizer, evaluate=True)# if self.eval_output_dir and not os.path.exists(self.eval_output_dir) and self.args.local_rank in [-1, 0]:# os.makedirs(self.eval_output_dir)# Note that DistributedSampler samples randomly# eval_sampler = SequentialSampler(eval_dataset) if args.local_rank == -1 else DistributedSampler(eval_dataset)eval_dataloader = BucketBatchSampler(eval_dataset, max_total_seq_len=self.args.max_total_seq_len, batch_size_1=True)# Eval!print("***** Running evaluation {} *****".format(prefix))print(" Examples number: %d", len(eval_dataset))model.eval()post_pruning_mention_evaluator = MentionEvaluator()mention_evaluator = MentionEvaluator()coref_evaluator = CorefEvaluator()losses = defaultdict(list)doc_to_prediction = {}doc_to_subtoken_map = {}for (doc_key, subtoken_maps), batch in eval_dataloader:batch = tuple(tensor.to(self.args.device) for tensor in batch)input_ids, attention_mask, gold_clusters = batchinput_ids = torch.where(input_ids == 22560, 100, input_ids)input_ids = torch.where(input_ids == 49518, 100, input_ids)with torch.no_grad():outputs = model(input_ids=input_ids,attention_mask=attention_mask,gold_clusters=gold_clusters,return_all_outputs=True)loss_dict = outputs[-1]if self.args.n_gpu > 1:loss_dict = {key: val.mean() for key, val in loss_dict.items()}for key, val in loss_dict.items():losses[key].append(val.item())outputs = outputs[1:-1]batch_np = tuple(tensor.cpu().numpy() for tensor in batch)outputs_np = tuple(tensor.cpu().numpy() for tensor in outputs)for output in zip(*(batch_np + outputs_np)):gold_clusters = output[2]gold_clusters = extract_clusters(gold_clusters)mention_to_gold_clusters = extract_mentions_to_predicted_clusters_from_clusters(gold_clusters)gold_mentions = list(mention_to_gold_clusters.keys())starts, end_offsets, coref_logits, mention_logits = output[-4:]max_antecedents = np.argmax(coref_logits, axis=1).tolist()mention_to_antecedent = {((int(start), int(end)),(int(starts[max_antecedent]), int(end_offsets[max_antecedent])))for start, end, max_antecedent inzip(starts, end_offsets, max_antecedents) if max_antecedent < len(starts)}predicted_clusters, _ = extract_clusters_for_decode(mention_to_antecedent)candidate_mentions = list(zip(starts, end_offsets))mention_to_predicted_clusters = extract_mentions_to_predicted_clusters_from_clusters(predicted_clusters)predicted_mentions = list(mention_to_predicted_clusters.keys())post_pruning_mention_evaluator.update(candidate_mentions, gold_mentions)mention_evaluator.update(predicted_mentions, gold_mentions)coref_evaluator.update(predicted_clusters, gold_clusters, mention_to_predicted_clusters,mention_to_gold_clusters)doc_to_prediction[doc_key] = predicted_clustersdoc_to_subtoken_map[doc_key] = subtoken_mapspost_pruning_mention_precision, post_pruning_mentions_recall, post_pruning_mention_f1 = post_pruning_mention_evaluator.get_prf()mention_precision, mentions_recall, mention_f1 = mention_evaluator.get_prf()prec, rec, f1 = coref_evaluator.get_prf()results = [(key, sum(val) / len(val)) for key, val in losses.items()]results += [("post pruning mention precision", post_pruning_mention_precision),("post pruning mention recall", post_pruning_mentions_recall),("post pruning mention f1", post_pruning_mention_f1),("mention precision", mention_precision),("mention recall", mentions_recall),("mention f1", mention_f1),("precision", prec),("recall", rec),("f1", f1)]print("***** Eval results {} *****".format(prefix))for key, values in results:if isinstance(values, float):print(f" {key} = {values:.3f}")else:print(f" {key} = {values}")if tb_writer is not None and global_step is not None:tb_writer.add_scalar(key, values, global_step)# if self.eval_output_dir:# output_eval_file = os.path.join(self.eval_output_dir, "eval_results.txt")# with open(output_eval_file, "a") as writer:# if prefix:# writer.write(f'\n{prefix}:\n')# for key, values in results:# if isinstance(values, float):# writer.write(f"{key} = {values:.3f}\n")# else:# writer.write(f"{key} = {values}\n")results = OrderedDict(results)# results["experiment_name"] = self.args.experiment_nameresults["data"] = prefixprint(results)# with open(os.path.join(self.args.output_dir, "results.jsonl"), "a+") as f:# f.write(json.dumps(results) + '\n')# if official:# with open(os.path.join(self.args.output_dir, "preds.jsonl"), "w") as f:# f.write(json.dumps(doc_to_prediction) + '\n')# f.write(json.dumps(doc_to_subtoken_map) + '\n')# if self.args.conll_path_for_eval is not None:# conll_results = evaluate_conll(self.args.conll_path_for_eval, doc_to_prediction, doc_to_subtoken_map)# official_f1 = sum(results["f"] for results in conll_results.values()) / len(conll_results)# logger.info('Official avg F1: %.4f' % official_f1)return results
需要注意的是,由于tokenizer创建的有问题,会造成embedding的时候OOV,具体表现为,报”list out of range“的错误(如果是在cuda上,则报cuda的错误),所以需要做一个简单的替换,也就是以下的两行:
input_ids = torch.where(input_ids == 22560, 100, input_ids)input_ids = torch.where(input_ids == 49518, 100, input_ids)
3.4 训练方法
训练也是直接从项目源码中截取。
首先需要配置一下训练参数:
args.batch_size_1 = False
args.gradient_accumulation_steps = 1
args.num_train_epochs = 100
args.head_learning_rate = 3e-4
args.learning_rate = 1e-5
args.weight_decay = 0.01
args.adam_beta1 = 0.9
args.adam_beta2 = 0.98
args.adam_epsilon = 1e-6
args.warmup_steps = 5600
args.dropout_prob = 0.3
args.top_lambda = 0.4
args.amp = False
args.n_gpu = 1
args.local_rank = -1
args.seed = 42
args.device = 'cuda:0'
args.do_eval = True
args.eval_steps = 1000
args.save_steps = 3000
args.save_if_best = True
训练过程中需要用到evaluator,实例化一个:
evaluator = Evaluator(args, tokenizer)
然后是训练方法:
def train(args, train_dataset, model, tokenizer, evaluator, dev_dataset):""" Train the model """# tb_path = os.path.join(args.tensorboard_dir, os.path.basename(args.output_dir))# tb_writer = SummaryWriter(tb_path, flush_secs=30)# logger.info('Tensorboard summary path: %s' % tb_path)train_dataloader = BucketBatchSampler(train_dataset, max_total_seq_len=args.max_total_seq_len, batch_size_1=args.batch_size_1)t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs# Prepare optimizer and schedule (linear warmup and decay)no_decay = ['bias', 'LayerNorm.weight']head_params = ['coref', 'mention', 'antecedent']model_decay = [p for n, p in model.named_parameters() ifnot any(hp in n for hp in head_params) and not any(nd in n for nd in no_decay)]model_no_decay = [p for n, p in model.named_parameters() ifnot any(hp in n for hp in head_params) and any(nd in n for nd in no_decay)]head_decay = [p for n, p in model.named_parameters() ifany(hp in n for hp in head_params) and not any(nd in n for nd in no_decay)]head_no_decay = [p for n, p in model.named_parameters() ifany(hp in n for hp in head_params) and any(nd in n for nd in no_decay)]head_learning_rate = args.head_learning_rate if args.head_learning_rate else args.learning_rateoptimizer_grouped_parameters = [{'params': model_decay, 'lr': args.learning_rate, 'weight_decay': args.weight_decay},{'params': model_no_decay, 'lr': args.learning_rate, 'weight_decay': 0.0},{'params': head_decay, 'lr': head_learning_rate, 'weight_decay': args.weight_decay},{'params': head_no_decay, 'lr': head_learning_rate, 'weight_decay': 0.0}]optimizer = AdamW(optimizer_grouped_parameters,lr=args.learning_rate,betas=(args.adam_beta1, args.adam_beta2),eps=args.adam_epsilon)scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup_steps,num_training_steps=t_total)loaded_saved_optimizer = False# Check if saved optimizer or scheduler states existif os.path.isfile(os.path.join(args.model_name_or_path, "optimizer.pt")) and os.path.isfile(os.path.join(args.model_name_or_path, "scheduler.pt")):# Load in optimizer and scheduler statesoptimizer.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "optimizer.pt")))scheduler.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "scheduler.pt")))loaded_saved_optimizer = Trueif args.amp:try:from apex import ampexcept ImportError:raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)# multi-gpu training (should be after apex fp16 initialization)if args.n_gpu > 1:model = torch.nn.DataParallel(model)# Distributed training (should be after apex fp16 initialization)if args.local_rank != -1:model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank],output_device=args.local_rank,find_unused_parameters=True)# Train!# logger.info("***** Running training *****")# logger.info(" Num examples = %d", len(train_dataset))# logger.info(" Num Epochs = %d", args.num_train_epochs)# logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)# logger.info(" Total optimization steps = %d", t_total)global_step = 0if os.path.exists(args.model_name_or_path) and 'checkpoint' in args.model_name_or_path:try:# set global_step to gobal_step of last saved checkpoint from model pathcheckpoint_suffix = args.model_name_or_path.split("-")[-1].split("/")[0]global_step = int(checkpoint_suffix)# logger.info(" Continuing training from checkpoint, will skip to saved global_step")# logger.info(" Continuing training from global step %d", global_step)# if not loaded_saved_optimizer:# logger.warning("Training is continued from checkpoint, but didn't load optimizer and scheduler")except ValueError:print('Starting fine-tuning.')# logger.info(" Starting fine-tuning.")tr_loss, logging_loss = 0.0, 0.0model.zero_grad()set_seed(args) # Added here for reproducibility (even between python 2 and 3)# If nonfreeze_params is not empty, keep all params that are# not in nonfreeze_params fixed.# if args.nonfreeze_params:# names = []# for name, param in model.named_parameters():# freeze = True# for nonfreeze_p in args.nonfreeze_params.split(','):# if nonfreeze_p in name:# freeze = False# if freeze:# param.requires_grad = False# else:# names.append(name)# print('nonfreezing layers: {}'.format(names))train_iterator = trange(0, int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0])# Added here for reproducibilityset_seed(args)best_f1 = -1best_global_step = -1for _ in train_iterator:epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])for step, batch in enumerate(epoch_iterator):batch = tuple(tensor.to(args.device) for tensor in batch)input_ids, attention_mask, gold_clusters = batchinput_ids = torch.where(input_ids == 22560, 100, input_ids)input_ids = torch.where(input_ids == 49518, 100, input_ids)model.train()outputs = model(input_ids=input_ids,attention_mask=attention_mask,gold_clusters=gold_clusters,return_all_outputs=False)loss = outputs[0] # model outputs are always tuple in transformers (see doc)losses = outputs[-1]if args.n_gpu > 1:loss = loss.mean() # mean() to average on multi-gpu parallel traininglosses = {key: val.mean() for key, val in losses.items()}if args.gradient_accumulation_steps > 1:loss = loss / args.gradient_accumulation_stepsif args.amp:with amp.scale_loss(loss, optimizer) as scaled_loss:scaled_loss.backward()else:loss.backward()tr_loss += loss.item()if (step + 1) % args.gradient_accumulation_steps == 0:optimizer.step()scheduler.step() # Update learning rate schedulemodel.zero_grad()global_step += 1# Log metrics# if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:# logger.info(f"\nloss step {global_step}: {(tr_loss - logging_loss) / args.logging_steps}")# tb_writer.add_scalar('Training_Loss', (tr_loss - logging_loss) / args.logging_steps, global_step)# for key, value in losses.items():# logger.info(f"\n{key}: {value}")# logging_loss = tr_lossif args.local_rank in [-1, 0] and args.do_eval and args.eval_steps > 0 and global_step % args.eval_steps == 0:results = evaluator.evaluate(model, dev_dataset, prefix=f'step_{global_step}', tb_writer=None, global_step=global_step)f1 = results["f1"]if f1 > best_f1:best_f1 = f1best_global_step = global_steptorch.save(model.state_dict(), 'best_model_zh.pt')# Save model checkpoint# output_dir = os.path.join(args.output_dir, 'checkpoint-{}'.format(global_step))# if not os.path.exists(output_dir):# os.makedirs(output_dir)# model_to_save = model.module if hasattr(model, 'module') else model # Take care of distributed/parallel training# model_to_save.save_pretrained(output_dir)# tokenizer.save_pretrained(output_dir)# torch.save(args, os.path.join(output_dir, 'training_args.bin'))# print("Saving model checkpoint to %s", output_dir)# torch.save(optimizer.state_dict(), os.path.join(output_dir, "optimizer.pt"))# torch.save(scheduler.state_dict(), os.path.join(output_dir, "scheduler.pt"))# print("Saving optimizer and scheduler states to %s", output_dir)print(f"best f1 is {best_f1} on global step {best_global_step}")# if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0 and \# (not args.save_if_best or (best_global_step == global_step)):# # Save model checkpoint# output_dir = os.path.join(args.output_dir, 'checkpoint-{}'.format(global_step))# if not os.path.exists(output_dir):# os.makedirs(output_dir)# model_to_save = model.module if hasattr(model,# 'module') else model # Take care of distributed/parallel training# model_to_save.save_pretrained(output_dir)# tokenizer.save_pretrained(output_dir)# torch.save(args, os.path.join(output_dir, 'training_args.bin'))# print("Saving model checkpoint to %s", output_dir)# torch.save(optimizer.state_dict(), os.path.join(output_dir, "optimizer.pt"))# torch.save(scheduler.state_dict(), os.path.join(output_dir, "scheduler.pt"))# print("Saving optimizer and scheduler states to %s", output_dir)if 0 < t_total < global_step:train_iterator.close()break# with open(os.path.join(args.output_dir, f"best_f1.json"), "w") as f:# json.dump({"best_f1": best_f1, "best_global_step": best_global_step}, f)# tb_writer.close()return global_step, tr_loss / global_step
与评估类似地,训练方法中,也需要对OOV的情况进行相应的替换,替换内容已经体现在上述代码中。
最后训练即可:
global_step, tr_loss = train(args, train_dataset, model, tokenizer, evaluator, dev_dataset)
我没有进行特别仔细地调整超参数,直接跑了200轮,最终f1的最好结果是67.6。
4. 推理
最后写一下推理部分,一般来说,开源项目都不提供推理的代码,这部分需要自己实现。
def predict(model, tokenizer, text: str, device: str = 'cpu'):"""预测:param model: s2e模型:param tokenizer: 分词器:param text: 原文:param device: 运行的设备:return:---------------ver: 2022-09-05by: changhongyu---------------修改为适用于中文ver: 2023-09-19"""model.eval()example = process_input(text, tokenizer)example = tuple(tensor.to(device) for tensor in example if tensor is not None)input_ids, attention_mask = exampleinput_ids = torch.where(input_ids == 22560, 100, input_ids)input_ids = torch.where(input_ids == 49518, 100, input_ids)with torch.no_grad():outputs = model(input_ids=input_ids,attention_mask=attention_mask,gold_clusters=None,return_all_outputs=True)# outputs: (mention_start_ids, mention_end_ids, final_logits, mention_logits)batch_np = tuple(tensor.cpu().numpy() for tensor in example if tensor is not None)outputs_np = tuple(tensor.cpu().numpy() for tensor in outputs)predicted_clusters = Nonefor output in zip(*(batch_np + outputs_np)):# gold_clusters = output[2]# gold_clusters = extract_clusters(gold_clusters)# mention_to_gold_clusters = extract_mentions_to_predicted_clusters_from_clusters(gold_clusters)# gold_mentions = list(mention_to_gold_clusters.keys())starts, end_offsets, coref_logits, mention_logits = output[-4:]max_antecedents = np.argmax(coref_logits, axis=1).tolist()mention_to_antecedent = {((int(start), int(end)), (int(starts[max_antecedent]), int(end_offsets[max_antecedent]))) forstart, end, max_antecedent in zip(starts, end_offsets, max_antecedents)if max_antecedent < len(starts)}predicted_clusters, _ = extract_clusters_for_decode(mention_to_antecedent)if not predicted_clusters:return# 格式转换formatted_clusters = []# token idx转token listtokens = convert_token_idx_to_tokens(input_ids[0].cpu().numpy().tolist(), tokenizer)tokens = [tok if tok not in ["''", "``"] else '"' for tok in tokens]for cluster_idx, cluster in enumerate(predicted_clusters):formatted_cluster = []for ent_idx, (token_start, token_end) in enumerate(cluster):# 对簇里的每一个实体# 转为char_spanchar_span = convert_token_span_to_char_span(text=text,token_span=[token_start - 4, token_end - 4],tokens=tokens[4: -1])formatted_info = {"cluster_id": str(cluster_idx),"id": f"{cluster_idx}-{ent_idx}","text": text[char_span[0]: char_span[1]+1],"start_pos": char_span[0],"end_pos": char_span[1],}formatted_cluster.append(formatted_info)formatted_clusters.append(formatted_cluster)return formatted_clusters
其中convert_token_span_to_char_span和convert_token_idx_to_tokens的作用,分别是将实体表述的token span转换为字符span,以及将token_id的列表转换为token的列表,这里不展示这两个方法。如果读者写不出来的话,可以找chatGPT帮忙,或者私信我。
最后,测试一下效果:
# test case 1
text = '据美联社报道,上周利比亚的洪灾已经造成当地超过4000人死亡,10000人失踪'
predict(model, tokenizer, text, 'cpu')
'''
[[{'cluster_id': '0','id': '0-0','text': '利比亚','start_pos': 9,'end_pos': 11},{'cluster_id': '0','id': '0-1','text': '当地','start_pos': 19,'end_pos': 20}]]
'''# test case 2
text = '拜登在2020年的大选中击败了特朗普,成功当选美国总统。他说,特朗普不会让美国再次伟大。'
predict(model, tokenizer, text, 'cpu')
'''
[[{'cluster_id': '0', 'id': '0-0', 'text': '拜登', 'start_pos': 0, 'end_pos': 1},{'cluster_id': '0','id': '0-1','text': '他','start_pos': 28,'end_pos': 28}],[{'cluster_id': '1','id': '1-0','text': '特朗普','start_pos': 15,'end_pos': 17},{'cluster_id': '1','id': '1-1','text': '特朗普','start_pos': 31,'end_pos': 33}],[{'cluster_id': '2','id': '2-0','text': '美国','start_pos': 23,'end_pos': 24},{'cluster_id': '2','id': '2-1','text': '美国','start_pos': 37,'end_pos': 38}]]
'''
5. 总结
本文介绍如何使用Ontonotes 5.0数据集训练一个中文实体共指模型,主要介绍训练和推理方法,模型原理和细节没有进行详细的说明,如果感兴趣的话,建议看一下原项目的源码,不要直接读论文,代码写的比较清晰,论文反而没有那么好理解。
如果本文对你有所帮助,记得点一个免费的赞,我们下期再见。