python在heidisql当中创建新表的注意事项
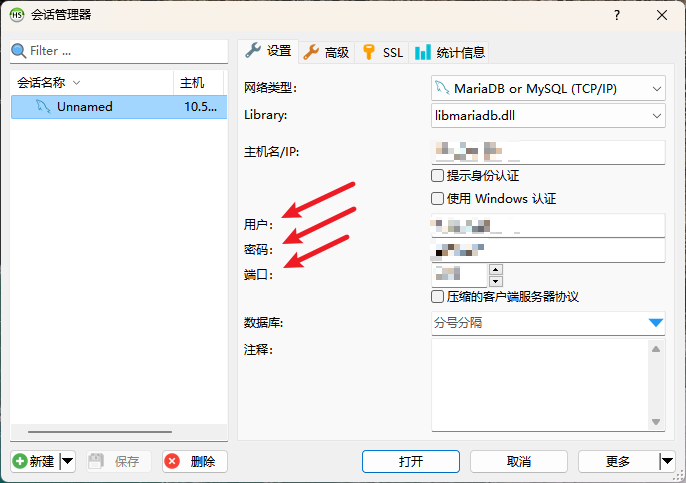
假设你已经在python当中弄好了所有的结果,并且保存在df_all这个dataframe当中,然后要将其导入数据库当中并创建一张新的表进行保存。
# 构建数据库连接,将merged_df写回数据库
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://abc:mima@IPdizhi:duankou/g12", encoding='utf-8', echo=True)
# mysql+pymysql://用户名:密码@主机名:端口号/数据库名
con = engine.connect() # 创建连接
df_all.to_sql(name='bug_info', con=con, if_exists='append', index=False)
- 上面这段代码当中df_all就是要创建的新的表的数据,df_all是你的pandas数据,但是一定要注意!!!!!!!,这个表名要在数据库中不存在,不然就会把别人的覆盖
- 第一次代码运行完先看看你代码生成的表有没有问题,没问题了再换回replace

- 如何查看数据库当中原本是否存在这个表名?(防止替换掉别人的数据)
- 首先,在上面这段代码当中,已经有了mysql+pymysql://abc:mima@IPdizhi:duankou/g12,说明是在g12数据库当中要创建一张新的表
- 因为如果在其他数据库当中出现了相同的表名是可以的,只要保证你自己的数据库没有出现相同的表名就可以了。
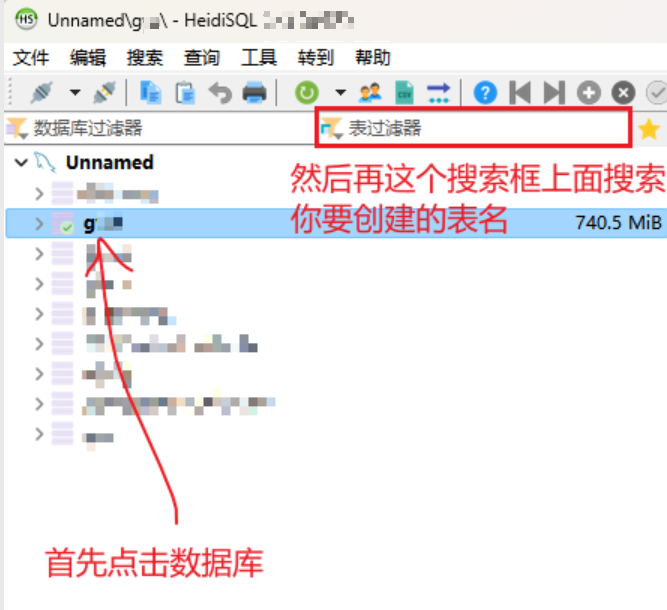
- hedisql有点问题,就是有时候replace了,但是要重新退出数据库之后重新进入,才能知道。