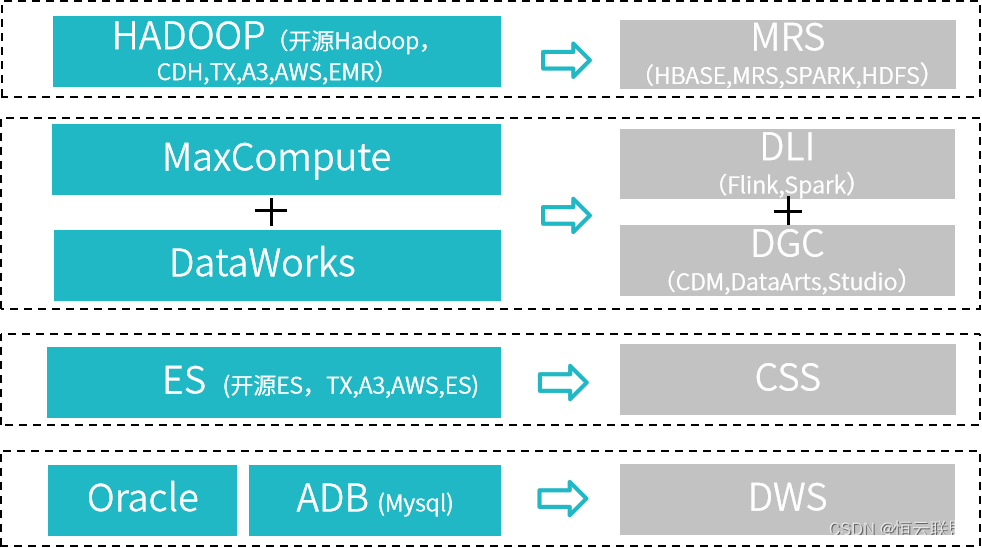
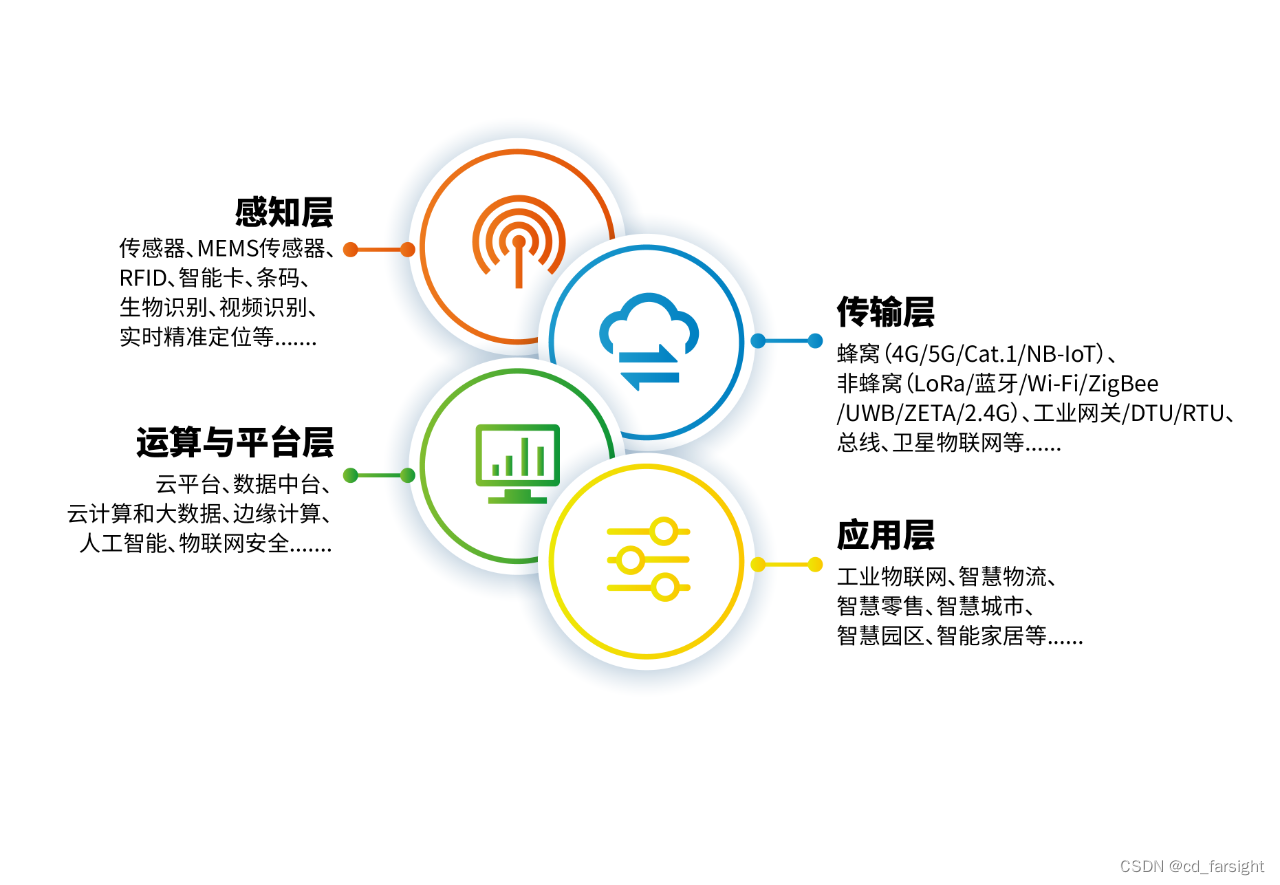
一、特征工程介绍
1.1 什么是特征
数值特征(连续特征)、文本特征(离散特征)
1.2 特征的种类


1.3 特征工程
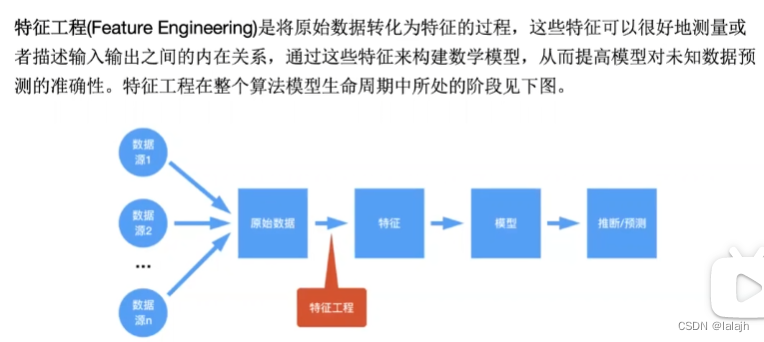
特征是机器学习可疑直接使用的,模型和特征之间是一个循环过程;
实际上特征工程就是将原始数据处理成机器学习可以直接使用数据的过程;
特征工程,降噪、将特征转化为数字,更好构建数学模型。
二、特征预处理
现实中数据集可能杂乱,如存在异常值、缺失值(非常大或小),这个时候是没法做特征工程的,需要数据预处理后,在做特征工程,这样效果更好!
特征预处理的⽅法
2.1 缺失值处理
⼀般缺失值可以⽤均值、中位数、众数等填充,或者直接将缺失值当做⼀个 特定的值来对待。还可以利⽤⼀些复杂的插值⽅法,如样条插值等来填充缺失值。如果缺 失值不多,还可以将包含缺失值的样本丢弃。
2.2 归⼀化
不同特征之间由于量纲不⼀样,数值可能相差很⼤,直接将这些差别极⼤的特征 灌⼊模型,会导致数值⼩的特征根本不起作⽤,⼀般我们要对数值特征进⾏归⼀化处理, 常⽤的归⼀化⽅法有min-max归⼀化、分位数归⼀化、正态分布归⼀化、⾏归⼀化等。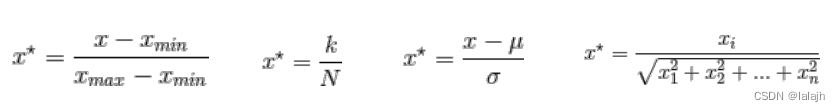
2.3异常值与数值截断
对于数值型特征,可能会存在异常值,包括异常⼤和异常⼩的值。在统计数据处理中有所谓3σ准则,即对于服从正态分布的随机变量,该变量的数值分布在 (μ-3σ,μ+3σ)中的概率为0.9974,这时可以将超出该范围的值看成异常值,采⽤向上截断 (⽤μ-3σ)和向下截断(⽤μ+3σ)的⽅法来为异常值赋予新的值。对于真实业务场景,可能还要 根据特征变量的实际意义来进⾏处理。
2.4⾮线性变换
有时某个属性不同值之间差别较⼤(⽐如年收⼊),有时为了让模型具备更多的⾮线性能⼒(特别是对于线性模型),这两种情况下都需要对特征进⾏⾮线性变换,⽐如值取 对数(值都是正的情况下)作为最终的特征,也可以采⽤多项式、⾼斯变换、logistic变换等转化为⾮线性特征。