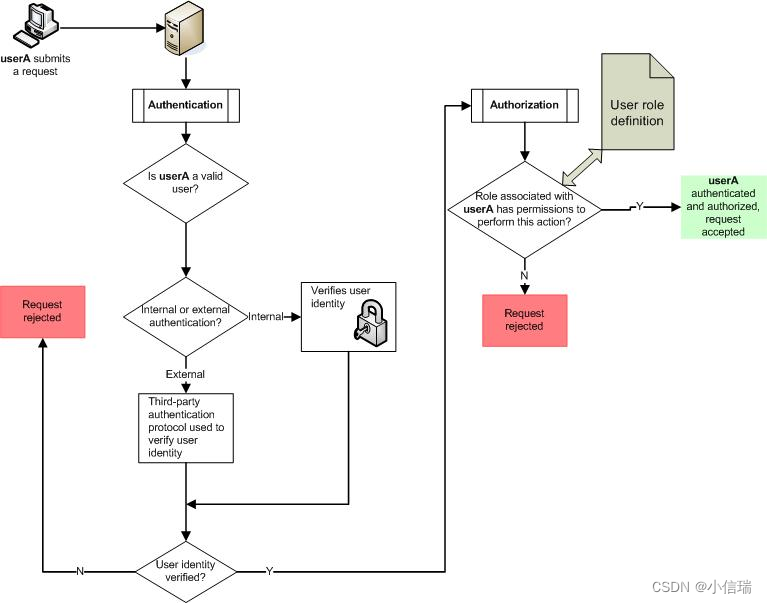
[toc]
前言
- AlexNet是是引领深度学习浪潮的开山之作,即使是我们现在进入了ChatGPT时代,这篇论文依然具有一定的借鉴意义。
- AlexNet的作者是多伦多大学的Alex Krizhevsky等人。Alex Krizhevsky是Hinton的学生。网上流行说 Hinton、LeCun和Bengio是神经网络领域三巨头,LeCun就是LeNet5的作者(Yann LeCun)。
资源
-
论文原文
-
https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
-
论文的代码实现
https://github.com/songhan/Deep-Compression-AlexNet
摘要
- 我们训练了一个很大很深的卷积神经网络,用来将2010年ImageNet 比赛中的120万的高分辨率图像分成1000类。在测试集上,我们的top-1和top-5分别为37.5%和17.0%,这比以前的所有SOTA算法的效果都要好。所提出的这个神经网络包含5个卷积层(卷积层后面可能会放置最大池化层)和3个全连接层,全连接层后面是一个softmax层,将类别分为1000类。整个网络拥有6000万个参数以及65万个神经元。为了使网络训练更快,我们使用了非饱和神经元,以及使用高效的GPU来进行卷积操作。同时,为了降低全连接阶层处过拟合的风险,我们使用了一种近期刚提出来的正则化方法“Dropout”,实验结果表明,这种方法在防止过拟合方面是非常有效的。我们同时也用这个模型的变体参加了2012年的比赛,取得了一个非常好的成绩。在测试集上,top-5的精度为15.3%,要远远高于第二名的26.2%。
1.引言
- 目前的目标识别任务主要是利用机器学习的方法。为了提高这些模型的性能,我们需要收集大量的数据集学习,学习更强大的模型,以及使用更好的技巧来防止过拟合。直到最近,带标签的数据集依然是相对比较小的-只有几千或者几万张图像(例如,NORB数据集,Caltech-101/256,以及CIFAR-10/100)。如果是简单的识别任务,那么使用这种级别的带标签数据集可以非常好的完成。例如,在minist数据集上的数字识别精度(<0.3%)已经可以接近于人类的表现了。但是,现实环境中的物体以及背景变化非常大,所以想要识别出来他们需要更大的训练数据集。事实上,小型数据集的缺点已经得到了广泛的承认,但直到最近,收集数以万计的图像进行标注才成为可能。包括LabelME在内的大型数据集中,拥有数十万张全分割图像。特别是ImageNet数据集包含了1500张标注好的高分辨率图像,其中类别超过了22000类。
- 为了从这种百万张图像级别的数据集中学习数以千计的目标特征,我们需要一个学习能力超强的网络模型。但是,这种目标检测任务巨大的复杂性,意味着就算是ImageNet这样的大数据集也不可能包括所有的先验知识。卷积神经网络就是这样的一类模型。它们的特征提取能力可以通过改变深度和宽度进行调整。他们可以在识别图像特性方面变得非常强大和准确(也就是说,统计数据的静态性和像素依赖关系的局部性)。因此,相较于同尺寸的标准前馈神经网络,CNN拥有更少的连接数和参数量,所以他们更容易去训练,尽管他们理论上性能可能稍差。
- 尽管cnn拥有这样诱人的特性,尽管他们的网络结构相对高效,但要将这些技术大规模地应用到高分辨率图像的分类上,训练成本依然很高。幸运的是,当前的经过高度优化的GPU再进行2D卷积的运行上表现的非常好,这给了我们训练大型CNN网络一个非常大的便利。此外,最近出现的ImageNet这样的大型数据集,包含了足够多的目标数量供我们训练,从而可以有效地避免过拟合。
- 这篇论文的主要贡献包括如下:我们使用ILSVRC-2010 and ILSVRC-2012的子数据集训练了一个最大的卷积神经网络,取得了比以往算法都好的效果。我们编写了高度优化的二维卷积GPU实施方案以及其他所有训练卷积神经网络的固有操作,这些我们都进行了开源。同时我们的网络也包含了一系列不同于之前的特性,可以提升网络的性能,同时降低训练时间,这些都会被在第三部分详细说明。即使ImageNet有1200万张标注好的训练图像,但因为我们网络的尺寸比较大,所以依然存在过拟合的风险,所以我们在研究中采用了几种有效的技术来避免过拟合,这些方法会在第四部分详细说明。我们最终的网络结构包含五个卷积层和三个全连接层。在实验中,我们发现网络的深度是非常重要的:因为如果将卷积层的任何一层去掉(即使这一层包含的参数量不超过1%),也会使网络的性能大幅度的退化。
- 最后,网络的尺寸被当前的GPU内存所限制。我们的网络在两块3GB的 GTX 580GPU上训练了5到6天。我们的所有实验结果表明,如果将来可以使用更强大的GPU以及更大的数据集,我们的网络表现性能将会更好。
2.数据集
- ImageNet是一个超过1500万张标注好高分辨率图像的数据集。这个数据集是从互联网上搜集到的,然后由人工使用亚马逊的Mechanical Turk crowd-sourcing 工具标注。
- 这也是我们开展我们大多数实验的数据集。从2010年开始,作为Pascal Visual Object Challenge的一部分,ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) 一年举办一次。ILSVRC使用的是ImageNet的子数据集,包含有1000类目标,每一类目标大约有1000张图像。到目前为止,大约有1200万张训练集、5000张验证集以及15万测试集。
- ILSVRC-2010 是ILSVRC唯一一场提供测试集的比赛,所以我们在这个比赛的数据集上进行了我们绝大多数的实验。因为我们同时参加了2012年的比赛,所以我们在第六部分详细的说明了我们的比赛结果(测试集效果看不到)。在ImageNet数据集上,常见的做法是查看网络的两个分类错误比率:top-1和top-5。top-5错误top-前五名错误率是指正确标签不在模型认为最有可能的五个标签之列的测试图像的比例。
- 我们的网络要求图像输入是一个固定的分辨率,但是ImageNet包含了多种尺度的分辨率图像。因此,我们对这些多尺寸的图像进行了下采样,将其固定到一个256乘256的分辨率下。给定一个矩形的图像,我们首先对图像进行重新缩放,使较短的一边长度为256,之后从生成的图像中裁剪出中央为256x256的图像patch块。除了从每一个像素中减去训练集的平均值之之外,我们没有对数据集做其他的任何操作了。所以可以认为我们是在原始的RGB图像上训练我们的网络。
3.网络结构
- 我们的网络结构如图2所示,包含了八个可学习参数的层-五个卷积层和三个全连接层。下面我们开始介绍一些新颖的或者不同寻常的网络特性。3.1-3.4是按照我们对自己工作的重要性进行了排序,也就是越靠前的越重要。
3.1 ReLU 非饱和激活函数(最重要的技巧)
- 对于实际网来说来说,处理输入x和输出f的一种标准做法是这f (x) = tanh(x)或者 f ( x ) = ( 1 + e − x ) − 1 f(x)= (1+e^ {-x})^ {-1} f(x)=(1+e−x)−1 。考虑到梯度下降的训练时间,这种饱和非线性激活函数相比于非饱和线性激活函数训练起来是非常慢的,比如非饱和激活函数 f ( x ) = m a x ( 0 , x ) f(x)= \\max (0,x) f(x)=max(0,x) 。根据Nair 和Hinton的研究,我们更愿意把这种非线性的神经网络激活函数称之为Rectified Linear Units (ReLUs)。ReLU的训练速度非常快,在同等条件下,训练速度可以比tanh的训练速度快好几倍。具体的训练效果如图1所示,从中我们可以看到两者在相等的四层网络条件下,两者想要达到CIFAR-10数据集上的25%错误率所需要的迭代次数。这张图表明了我们如何使用传统的饱和激活函数,将无法在大型数据集上训练大型神经网络。
- 我们并不是第一个考虑在CNN上替换传统的激活函数的研究团队。例如,Jarrett等人宣称,在Caltech-101数据集上进行实验时,将 f ( x ) = ∣ t a n h ( x ) ∣ f(x)=| \\tanh (x)| f(x)=∣tanh(x)∣放到局部平均池化层后面的分类效果和原始版本的网络效果一样好。但是,在这个数据集上首先关心的应该是防止过拟合,所以Jarrett做实验的目的以及得到的实验结果,都是关于过拟合的,而没有看到这种激活函数对于网络训练的加速效果,这一点可以在我们的报告中看到。更快的训练速度对于大模型在大数据集上进行训练具有非常深远的影响。
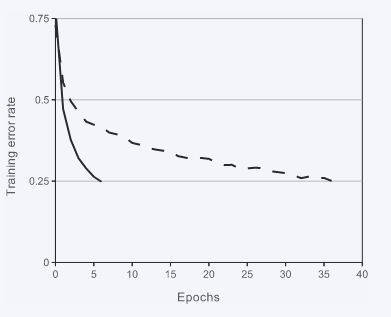
- 图1:一个使用ReLU激活函数的四层卷积神经网络(实线)在CIFAR-10数据集上达到25%的训练误差速度,要比同样的使用tanh激活函数的网络(虚线)快六倍。每一个网络的学习率都是经过人工微调过的,目的是让他们的训练速度尽可能快。两者都没有加任何类型的正则化。这里展现的效果因网络结构而异,但是使用ReLU激活函数的网络学习速度始终要比使用饱和神经元的网络快好几倍。
3.2 在多GPU上进行训练(次重要的技巧)
- 一个GTX580的GPU只有3GB的内存,这限制可以在它上面训练的网络的最大尺寸。这表明1200万的训练样本对于训练神经网络来说是足够的,但是对单GPU来说数据量却太大了。因此,我们把网络结构分散到2个GPU上来解决这个问题。当今的GPU已经可以很好的进行跨GPU进行数据同步了,因为他们可以直接在另一块GPU的内存上进行读和写,这个过程不需要通过宿主机的内存进行缓冲,因此可以大大加快数据的读写速度。在这个并行训练方案中,我们在每一个GPU上都放置一半的卷积核,不过有一个额外的技巧:GPU只在特定的层进行数据交互。举个例子来说,第3层接收全部来自于第2层卷积后的数据,但是,第4层的卷积核,只接受来自于本GPU上第3层的数据。选择这种连接模式,对于交叉验证来说是一个问题,但是这种方式却允许我们可以精确的调整双GPU之间的连接参数量,从而可以微调神经网络的尺寸。
- 这种组合的结果,有点类似于Cires¸an等人采用的柱状CNN结构,但需要注意的是,我们的两个GPU不是独立的,是有联系的(具体可以看图2)。这个方案可以降低我们的top-1和top-5的错误率,top-1降低了1.7%,top-5降低了1.2%,相比之下,在一个GPU上训练的每个卷积层的内核数量只有一个网络的一半。双GPU网络模型训练所花费的时间要比单个GPU训练所耗费时间稍微少一点。
- 注:这里所说的单GPU模型,实际上指的是在最终一层的卷积层中拥有和双GPU模型网络同样的参数,同样数量的卷积核。这是因为大多数的神经网络参数,都集中在了第一个全连接层中,而这些参数则主要来自于最后一个卷积层。所以为了保证两个网络拥有大致相同的参数,我们并没有将最后一层卷积层的卷积核数量减半(也没有将全连接层的数量减半)。因此,这种比较方式实际上是偏向于单GPU网络的,因为他比真的减半体积的双GPU模型来说更大。
3.3 局部响应标准化
- ReLU拥有令人非常满意的能力来保证不需要网络输入标准化来防止网络性能下降。如果有一些训练样本在ReLU上产生了正向输入,那么网络就会进行学习。但是我们仍然发现local normalization的方案有助于泛化性。用 a _ x , y i a\_ {x,y}^ {i} a_x,yi 来表示神经网络的活动,计算方法是在位置(x,y)上应用kernel i,之后在使用ReLU 非线性激活的函数,response-normalized activity 的表达式如下所示:

- 其中,总和遍及同一空间位置的 n 个 "相邻 "特征图,N是这一层上的卷积核数量总和。当然了,kernel maps的顺序在训练之前是随意设置的。这种类型的response normalization可以实现实现一种横向抑制,这是受真实神经元的工作原理启发。在使用不同内核计算出来的神经元输出中,形成对大内核的竞争。k,n,α,β是超参数,对于同一个验证集来说,数值是确定的。在这里我们设置k=2,n=5,α=0.0001以及β=0.75。 我们在一些层的ReLU后面使用这种normalization。(这部分工作的具体介绍看3.5)
- 我们的这个方案和Jarrett的local contrast normalization有点类似,但因为我们不仅仅减去了平均值,所以我们的做法应该更符合“brightness normalization”。Response normalization可以让我们的模型的top1和top5的错误率分别降低1.4%和1.2%。我们也在CIFAR-10数据集上验证了我们方案的效果:
3.4 重叠池化
- 神经网络中的池化层可以汇总相邻神经元组特征中的主要信息。一般情况下,相邻神经元的池化区域不会重叠。更精确的说,你可以认为池化层是由相隔s像素的网格状的区域组成的,每一个区域都可以提取出zxz的特征图。如果我们设置s=z,我们就可以得到CNN通常采用的传统局部池化方法。如果我们设置s<z,我们将会取得一个过度采样的池化特征图。我们在这个网络中实际设置的是s=2,z=3。相比于没有进行重叠池化的s=z,z=2,,这种方法可以分别让网络top-1和top降低0.4%和0.3%。在训练过程中,我们通常会发现采用重叠池化的模型,可以更好地解决锅拧合的问题。
3.5 总的模型
- 现在我们开始介绍我们所设计的这个CNN网络的总体模型。正如图2所示,这个网络包含了八个有权重的网络层;前面的五个是卷积层,后面的三个是全连接层。最后的全连接层输出到一个1000-way的Softmax层,将网络的输出映射为1000类的标签。我们的网络最大化了我们逻辑回归目标,相当于最大化了预测分布下正确标签的对数概率在整个训练案例中的平均值。
- 如图2所示,2、4、5的卷积层只连接同一块GPU的上层网络的输出。第三层的卷积核分别连接的是两块GPU上的所有第二层的输出。全连接层处的神经元连接了所有上一层网络的神经元。Response-normalization层放在了第一和第二卷积层的后面。就像3.4所描述的那样,最大池化层和第五层卷积层一样,放在了两个Response-normalization层后面。在每一个卷积层和全连接层后面都放置了一个RELU非线性激活函数层。
- 第一卷积层的输入为224 x 224 x 3的图像,使用96个11x11x3的卷积核来进行卷积,步长设置为4像素。(这是kernel map中相邻神经元的感受野中心之间的距离)第二卷积层使用第一个卷积层的输出作为输入,拥有256个5x5x48的卷积核。第3、4、5卷积层,直接连接前者,中间没有任何的池化层或者激活函数层。第三层卷积层有384个3x3x256的卷积核,连接的是第二层的输出(经过normalized和池化后的输出)。第4个卷积层有384个3x3x192的卷积核,第5卷积层有256个3x3x192的卷积核。全连接层每层有4096个神经元。

- 图2 我们cnn网络的一个结构展示,清晰地表明了我们两块GPU的相互关系。一块GPU处理一些卷积层运算,另一款GPU处理另一些卷积层的运算。这两块GPU只在特定的层进行信息交互。网络的输入是150528维数据(224_224_3=150528)。各层网络的参数量分别为253440-186624-64896-43264-4096-4096-1000。
4.减少过拟合
- 我们的神经网络结构有6000万个参数。尽管使用一共有1000个类别的ILSVRC的数据集进行训练,这给一个训练样本添加了10 bits的约束。但事实证明,如果网络没有过拟合的话,这些数据集是无法分担这么多的网络参数的。下面我们将介绍应对过拟合的两种方法。
4.1 数据增强
- 最简单和最常用的少网络,在数据集上过拟的方法是,在保证数据集标签不改变的前提下人为地扩大数据集的数量。我们使用了两种非常明确的方法来进行数据增强,这两种方法所带来的计算资源的消耗非常小,因此我们可以直接进行训练时的在线数据转换,而非不得不把这些增强后的图像保存在本地磁盘上。在我们的方案中,我们使用Python代码在CPU上对图像进行转换,GPU则只负责使用转换好的图像进行训练。所以这种数据增强的方法是free的(相对于GPU来说,译者注)
- 第一种形式的数据增强是,通过平移和水平翻转来进行增强。我们从原始的256x256的图像(包括他们的水平翻转中)中随机提取224x224的图像patch块,用来训练我们的网络模型。这可以让我们的训练数据集增加2048倍。当然了,由此产生的训练样本是高度相似的。如果不采用这个做法的话,我们的网络将有可能会过拟合,从而迫使我们不得不采用更小的模型。在测试集上,网络也是对原始图像以及他们的水平翻转图像的224x224的patch进行的预测(四个角的patch和一个中心的patch),一张图像总共产生十个patch,最后在Softmax层对10个patch的得分进行平均后预测。
- 第二个数据增强的方法是改变训练集上RGB通道图像的强度。特别是,我们是使用PCA方法在ImageNet数据集上来改变RGB像素值的强度的。对于每一个训练图像来说,我们将找到的主成分的倍数相加,其幅度与相应的本征值乘以从平均值为零且标准差为0.1的高斯分布中提取的随机变量成比例。因此对于每一个RGB图像像素KaTeX parse error: Undefined control sequence: \[ at position 12: I\_ {xy} = \̲[̲I\_ {xy}^ {R},I… ,我们增加下面的数值
- KaTeX parse error: Undefined control sequence: \[ at position 1: \̲[̲ p\_ {1} , p\_ …
- 其中, P _ i P\_i P_i和 λ _ i λ\_i λ_i 分别是 RGB 像素值 3 × 3 协方差矩阵的第 i 个特征向量和特征值,αi 是上述随机变量。每个 αi 只对特定训练图像的所有像素绘制一次,直到该图像再次用于训练时才重新绘制。这一方案近似地捕捉到了自然图像的一个重要特性,即物体特征不受光照强度和颜色变化的影响。该方案可将 TOP-1 错误率降低 1%以上。(这一段不好翻译,所以用的机翻)
4.2 Dropout
- 融合多个不同模型的预测结果,是减少测试误差的一种非常成功的策略,但是这种方法对于动不动需要训练好几天的大型神经网络来说,太昂贵了。在训练的时候,有一种非常有效的方法来融合两个模型,时间上只需要花两倍的成本。这便是最近刚被提出来称之为dropout的技术,可以以50%的概率随机的将硬含层中的神经元输出设置为零。被丢弃的神经元在这条通路中不传递对应的输出到下一层,也不参与反向传播。所以每一次当输入被给出后,神经网络都采用了一个不同的结构,但是所有的结构都共享了一套权重参数。这种技术降低了神经网络的共适应复杂性,因为一个省域经济不可以依赖于其他特定存在的神经元来进行判断。因此,这强迫网络去学习一些更强大、更通用的特征。这些特征在于其他神经元的不同,随机自己组合使用是非常有用。在测试的时候,我们使用所有的神经元,但是对他们的输出做一个乘0.5的操作,与训练的时候大致相对应。相当于取指数级多剔除网络产生的预测分布的几何平均数。。
- 如图2所示,我们在前两个全连接层中使用dropoutt的策略。如果没有rapt我们的网络表现出轻微的过拟合。加入dropout之后,网络收敛的速度变慢,大约需要之前两倍的迭代次数。
5 学习的细节
- 我们训练网络时使用随机梯度下降SGD的策略,Batch Size设置为128,momentum动量为0.9,权重衰减为0.0005。我们发现这种非常小的weight decay对于网络模型学习特征来说是非常重要的。换句话说,这里的weight decay不仅仅是一个正则项:它还可以降低网络模型的训练误差。weight w的更新规则是:
- KaTeX parse error: Expected 'EOF', got '&' at position 33: …v \_ { i + 1 } &̲ : = 0.9 \\cdot…
- i是迭代次数,v是momentum变量,ε是网络的学习率, l e f t l a n g l e l e f t . f r a c p a r t i a l L p a r t i a l w r i g h t ∣ _ w _ i r i g h t r a n g l e _ D _ i \\left\\langle \\left. \\frac { \\partial L } { \\partial w } \\right| \_ { w \_ { i } } \\right\\rangle \_ { D \_ { i } } leftlangleleft.fracpartialLpartialwright∣_w_irightrangle_D_i 是第i个batch D _ i D \_ { i } D_i 在 w _ i w \_ { i } w_i处求得的目标关于w的梯度的平均值,
- 我们使用标准的方差为0.01的零均值高斯分布来对每一层网络的权值进行初始化。我们对第2、4、5的卷积层和全连接层中的隐含层的偏置项进行全1处理。这种初始化方法通过给ReLU提供正向输入加速了训练早期阶段的收敛。我们在剩下的网络层的神经元偏置中设置为全0。
- 我们对所有的网络层使用同一个学习率,这个学习率是我们在整个训练过程中手动调节的。我们调整学习率的原则是:如果验证集上的误差在一段时间内没有继续减小的话,我们就把当前的学习率除以10。学习率初始为0.01,当训练结束时,学习率减少了三次,也就是调整为了0.00001。我们在3GB的英伟达GTX580上面训练1200万张图像的数据集90个epoch,这花费了我们5到6天的时间。
6.Results
- 我们在ILSVRC-2010的训练和测试结果展示在了表格1中。我们网络的top-1和top-5测试误差分别为37.5%和17.0%。ILSVRC- 2010上面取得的最好结果是47.1%和28.2%。当时使用的方法是,对基于不同特征训练的六个稀疏编码模型的预测结果求平均值的方法。此后,通过对根据两种密集采样特征计算的费雪向量 (FV) 训练的两个分类器的预测结果进行平均计算而获得的最佳成绩是 45.7% 和 25.7%[24]。
- 我们同时使用我们的模型参加了ILSVRC-2012比赛,表2是我们的比赛结果。因为ILSVRC-2012的测试集标签没有给出,所以我们无法评估我们的模型在测试集上的误差。根据我们的实验发现、验证集和测试集的精度相差非常小,不超过0.1%。因此在本段的其他部分,我们交替使用验证和测试误差比率。
- 本研究所提出的CNN模型取得了18.2%的top-5误差率。对五个相似的CNN模型进行误差平均,top-5的误差率是16.4%。在ImageNet Fall 2011数据集上(1500万张图像,22000个类别)训练一个在卷积层的后面外加一个池化层的CNN模型,之后微调它在ILSVRC-2012上面进行训练,所取得的top-5误差率是16.6%。对两个使用entire Fall 2011预训练权重的CNN模型分类结果进行平均,top-5的误差率是15.3%。第二名的测试结果误差率为 26.2%,采用的方法是将多个分类器的预测结果平均化,这些分类器是根据不同类型的密集采样特征计算出的 FV 进行训练的。
6.1 定性评价
- 图3展示了网络的两个数据连接层学习到的卷积核。网络学到了各种频率和方向选择性的卷积核,以及各种彩色斑点。这里需要注意的是,我们专门展示了两块GPU上卷积核学习到特征的差别。GPU1在很大程度上与颜色无关,而GPU2学到的特征则与颜色有关。这种非常特殊的区别,在每次运行时都会发现,与任何特定的随机权重初始化方式都无关(GPU重新编号为)

- 图3 96个11x11x3的卷积核在224x224x3的输入图像中渠道的特征。上面的48个核是在GPU上训练调整的,下面的48个核是在GPU2上训练调整的。这部分的细节可以看论文的6.1部分。

- 图4:(左侧)8张ILSVRC-2010测试集图像以及5个我们模型预测出来的最可能标签。真正的标签被写在了每张图片的下方,正确标签的识别概率也被用红色条展示出来(如果正确标签刚好是在前5个最高概率中的话)(右侧)5个ILSVRC-2010测试集图像放在了第一列,剩下的列显示了6个网络认为最相关的训练集图像,这些图像在最后一个隐藏层中产生的特征向量与测试图像特征向量的欧氏距离最小。
- 在图4的左侧,我们通过计算网络的top-5对测试集图像进行预测,定性对网络模型的效果进行评价。需要注意的是,即使目标远离中心,比如左上角的虫子,也同样可以被网络识别到。大多数的top-5标签似乎都是合理的。例如,只有其他类型的猫科动物才被认为是豹的可信标签。在某些情况下(格栅、樱桃),照片的预期焦点确实模糊不清。
- 另一种证明网络效果的可视化方法是考虑网络的最后一层卷积层输出的4096维向量。如果两张图片所产生的特征图激活向量欧式距离比较小,我们就认为这两张图像在神经网络的高维空间中是相似的。图4显示出了从测试集中挑选出的5张图片,和他们分别对应的6张从训练集中挑选出的最相似的图像。注意看在像素层面上,检索到的训练集图像,在L2范数计算规则下并不是与第一列的测试集图像距离最近的。例如检索到的狗和大象,会以各种姿势出现。我们在论文的补充材料中展现了更多类似的检索结果。
- 使用欧式距离计算2个4096维向量的相似性是不高效的,但可以使用一个训练到的自动编码器,将这些向量压缩为简短的二进制代码来高效检索。对于图像检索来说,相较于直接使用自动编码器,对原始的像素图像进行编码,这种对向量的编码方式效果更好。因为直接对原始图像进行编码,并没有使用图像标签,因此倾向于检索具有相似边缘模式的图像,无论它们在语义上是否相似。
7 讨论
- 我们的实验结果表明了一个大的深的卷积神经网络是可以在一个较高难度挑战的数据集上使用纯监督学习取得突破的。如果我们的神经网络被拿掉了任何一层,网络的性能会下降很多。例如,如果拿掉中间的任何一层,top-1的准确性将会下降2%。所以深度对于卷积神经网络取得好的效果来说是非常重要的。
- 为了简化我们的实验,尤其是当我们获得足够的计算能力,可以在不相应增加标注数据量的情况下显著扩大网络规模时,我们没有使用任何的无监督预训练方法(即使我们认为这些方法是有帮助的)。到目前为止,
- 但我们将网络模型变得更大,然后训练时间更长后,我们的网络已经提升了很多。但是如果想要和人类的视觉系统相提并论的话,我们还有许多数量的工作要做。最后,我们将会使用非常大和非常深的卷击神鹰网逻辑去处理视频任务,在视频上时间结构提供了非常有用的信息,而这些信息在静态图像中是缺失的或者不那么明显的。
博主最后说明
- 翻译这篇文章主要是用来帮助自己进行自我对照,以及锻炼自己的英文阅读能力的。自己不是英语专业的,中间肯定有很多翻译的不够准确,读起来不够通顺的地方,还请大家不啬指出,我会在这篇文章以及下一篇系列的翻译文章中进行改正。(但不接受那些不说明具体问题所在就无脑褒贬的不负责说法)