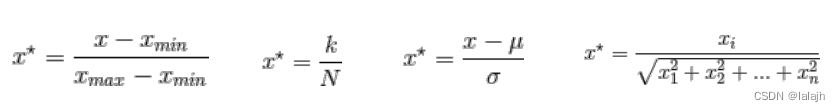一、研究背景
以往工作专注于提取伪造特征的共同特性和真假域鉴别性信息,以提升特征泛化性。
但在训练过程中,这些方法只区分真假域,并将不同的伪造域看作一类而不加以区分。
这会导致伪造样本进一步以伪造不相关特征(如,身份、外观、背景)聚类,虽然在训练数据上呈现更紧凑的聚类,但并没有真正提取到伪造相关特征。
二、研究目标
1.实现伪造域之间的适当分离。
2.实现真实域和伪造域之间的距离拉远。
三、研究动机
在训练数据上,模型在监督信息的指导下会学习一个更相关的特征模式,并表现出良好的性能。
而在未知域中,由于特征分布存在偏差,按照原始模式提取的特征将包含很大比例的不相关信息。
模型基于这些不相关信息做出决策会降低判断准确率,呈现泛化性能差的现象。
四、技术路线
提出 controllable guide-space(GS)方法学习不同伪造域之间的差异性、相同伪造域内的一致性,以此增强对伪造线索的关注,提高特征的伪造相关性。由于习得的特征域伪造痕迹更为相关,从而可以提升泛化性能 。
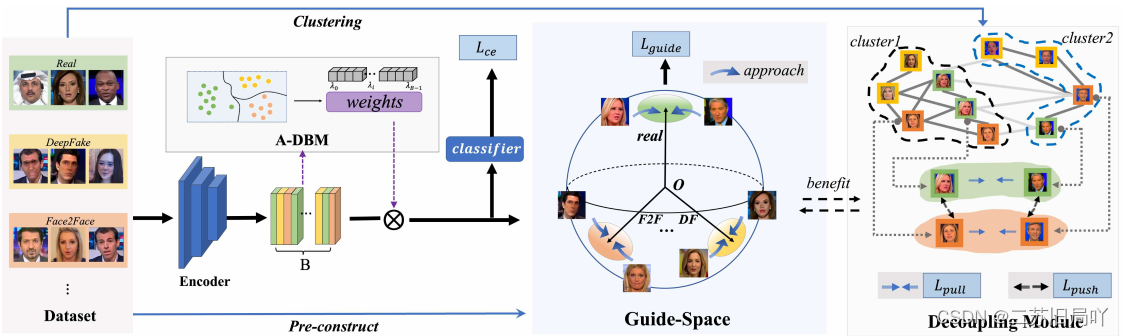
1.预先构造理想的引导空间,并使特征向各自域的引导特征靠拢,实现真实域的紧凑性和伪造域间的可控分离(超参数可控)。
- 使不同伪造域的引导特征尽可能分离。
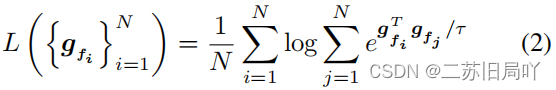
- 定义超参数 θ 0 \theta_0 θ0作为真假域的距离约束。但 θ 0 \theta_0 θ0不是越大越好,因为不同伪造域之间仍要保持一定区分性。
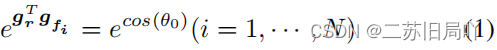
2.优化引导空间
- 令所有特征向各自的引导特征靠拢。
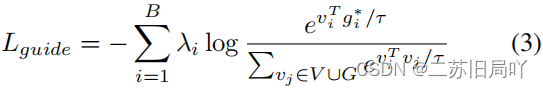
- 交叉熵损失约束分类
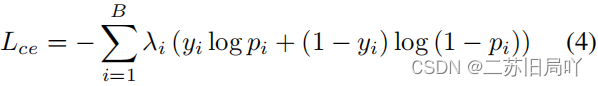
3.设计基于特征聚合度的决策边界调整模块(A-DBM),通过为样本设置权重来调整决策边界,使特征更好地在域内聚集并趋向导向空间的特征分布。
- 在某一域内,根据邻域内的特征聚合程度计算模型决策可靠性。
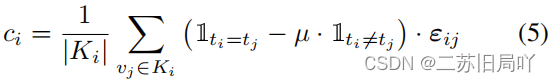
邻域内样本类别一致:可靠
邻域内样本类别不一致:不可靠
在决策边界附近:中等 - 根据可靠性计算样本权重。
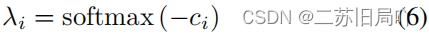
4.根据自监督特征的聚类结果,挖掘并解耦不同域之间的伪造无关联系,并通过减轻伪造无关联系的干扰来提升泛化性能。
- 不同伪造域的特征彼此聚集,证明它们包含较强的伪造无关联系,需要通过训练进行分离。
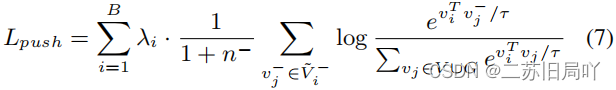
- 同一域的特征属于不同簇,需要将它们拉近,增强伪造相关性。
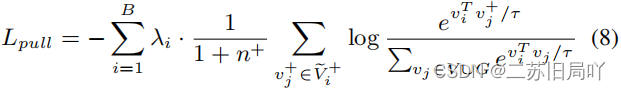
5.总损失
![]()
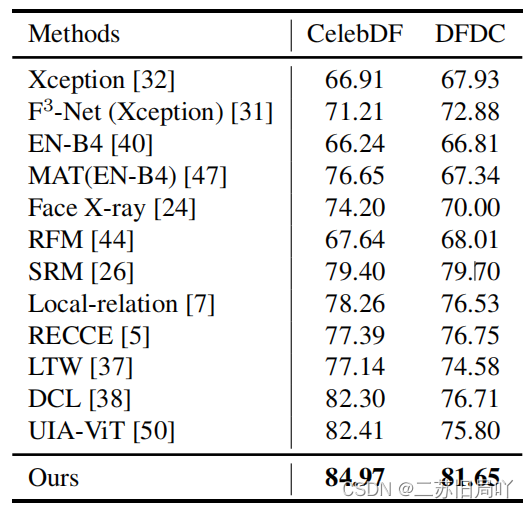
五、实验结果