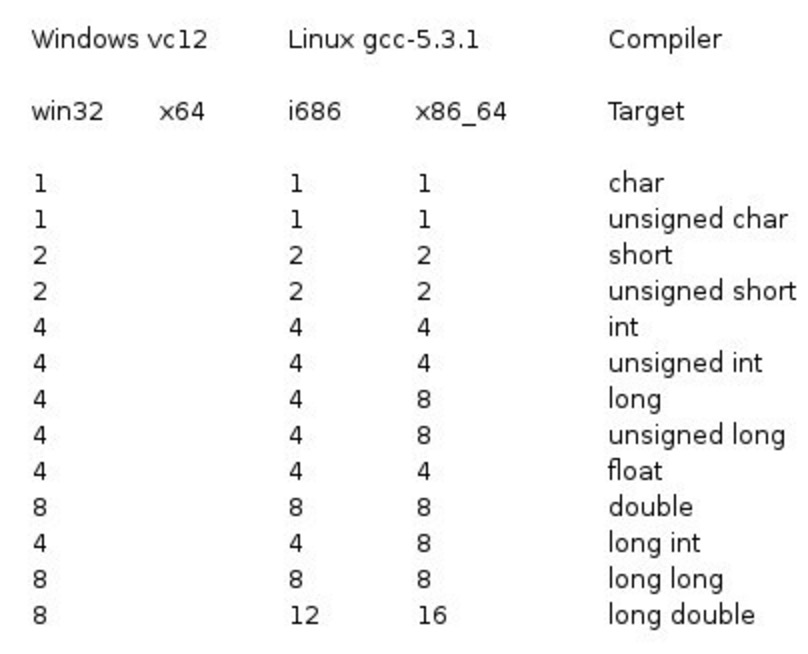
大家好,我是你们的群主王知无呀。
Flink 1.18已经于近期发布了。在这个新版本中新增了很多新的功能和特性。在这些特性中,有一些是生产环境非常重要的能力,大家在使用过程中可以重点参考和了解其中的原理。
算子级别状态保留时间TTL设置
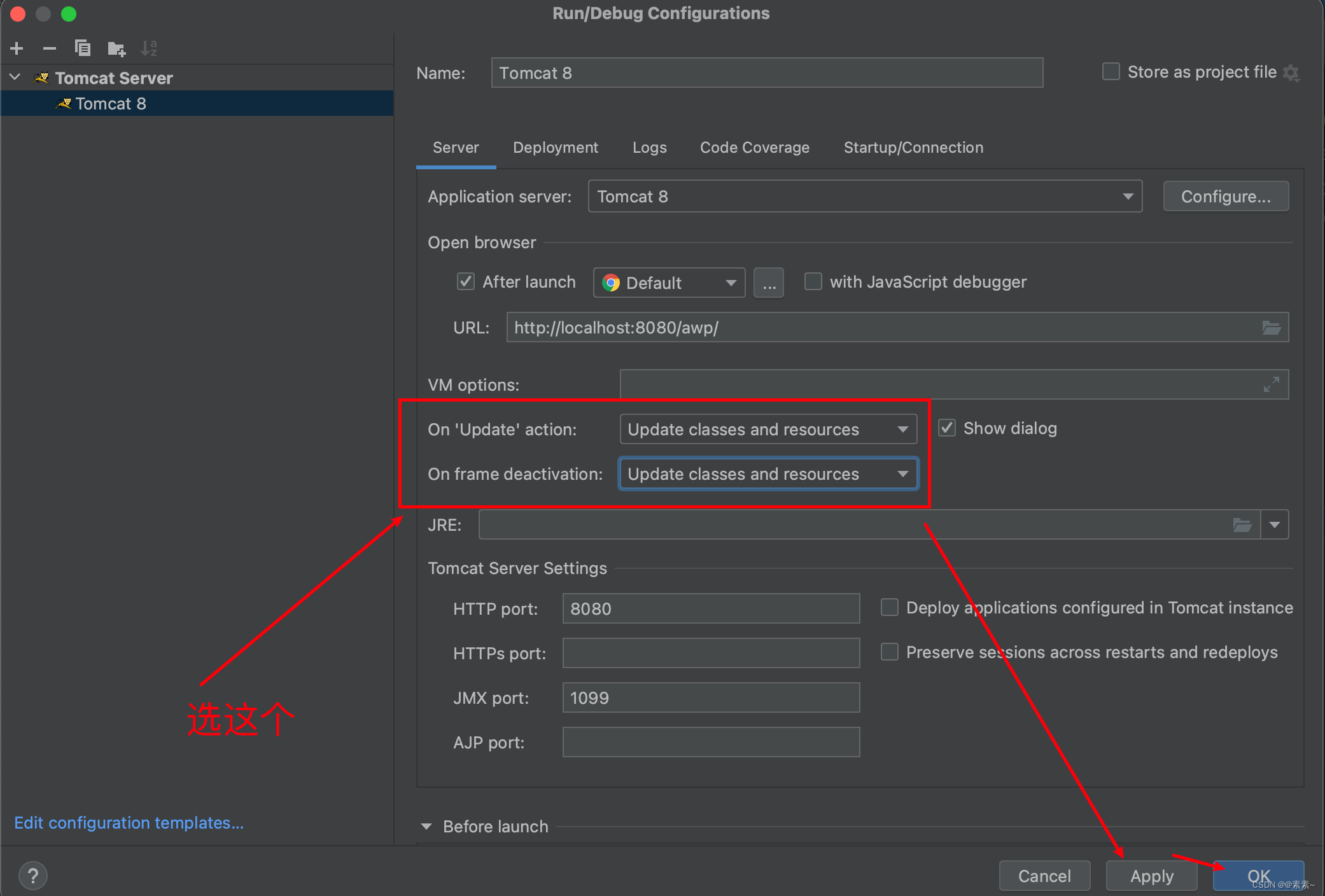
首先,在流处理的提升上,从 Flink 1.18 版本开始,Table API 和 SQL 用户可以为有状态的算子单独设置状态保留时间 (TTL)。
这个功能是一个非常实用和重要的功能,在以前的版本中,状态保留时间只能在 pipeline 级别使用配置项通过table.exec.state.ttl进行控制。引入算子级别的状态保留后,用户现在可以根据其具体需求优化资源使用。
现在可以为左侧和右侧流设置不同的 TTL,这有助于大数据量的状态大小控制,可以有效减少状态大小,在失败恢复,重启上线等场景中,任务可以更快恢复。
但是在公开的Flink1.18版本给出的官方用法中,采用了修改JSON File这种不太易用的方式:
-- left source table
CREATE TABLE Orders (`order_id` INT,`line_order_id` INT
) WITH ('connector'='...'
);-- right source table
CREATE TABLE LineOrders (`line_order_id` INT,`ship_mode` STRING
) WITH ('connector'='...'
);-- sink table
CREATE TABLE OrdersShipInfo (`order_id` INT,`line_order_id` INT,`ship_mode` STRING
) WITH ('connector' = '...'
);COMPILE PLAN '/path/to/plan.json' FOR
INSERT INTO OrdersShipInfo
SELECT a.order_id, a.line_order_id, b.ship_mode
FROM Orders a JOIN LineOrders b ON a.line_order_id = b.line_order_id;然后通过修改这个PLAN中的json数据达到分别设置TTL的目的:

上图中的PLAN中有针对算子的state状态设置,可以根据需要修改左右流的状态:

在FLIP-292中,社区也给出了这么做的理由:

水印对齐和空闲检测
在此之前,这两个功能只能在DatStream API中使用:
-- configure in table options
CREATE TABLE user_actions (...user_action_time TIMESTAMP(3),WATERMARK FOR user_action_time AS user_action_time - INTERVAL '5' SECOND
) WITH ('scan.watermark.idle-timeout'='1min',...
);-- use 'OPTIONS' hint
select ... from source_table
/**OPTIONS('scan.watermark.idle-timeout'='1min')
*/-- configure in table options
CREATE TABLE user_actions (
...
user_action_time TIMESTAMP(3),WATERMARK FOR user_action_time AS user_action_time - INTERVAL '5' SECOND
) WITH (
'scan.watermark.alignment.group'='alignment-group-1',
'scan.watermark.alignment.max-drift'='1min',
'scan.watermark.alignment.update-interval'='1s',
...
);-- use 'OPTIONS' hint
select ... from source_table
/** OPTIONS(
'scan.watermark.alignment.group'='alignment-group-1',
'scan.watermark.alignment.max-drift'='1min',
'scan.watermark.alignment.update-interval'='1s')
*/其中水印对齐在在多并行度下,Watermark 会在每个并行度的 source 处或者其他算子内部添加,并且需要在进行对齐。
空闲检测就更有用了,我们在很多业务场景中经常会有Source端数据迟迟不来,导致下游某些酸子不能触发计算,在之前我们可以通过设置table.exec.source.idle-timeout全局生效,现在我们可以在不同的源上设置不同的超时时间了。
动态细粒度扩缩容
Flink 1.18 起,在作业运行时,我们可以通过 Flink Web UI 和 REST API 更改作业的任何 task 的并行度。
之前可能受限于平台能力,这个情况困扰过很多同学,不能修改作业的并行度。现在这个能力有了,可以方便我们轻松的进行任务的扩缩容,并且这个能力和反压监控相结合,更容易调整任务的资源,确保集群任务的健康稳定运行,另外可以方便的进行线上任务治理。
Flink的能力还在不断更新中,例如对Paimon的支持上也有了不小的提升。还有一些其他的改动,大家可以根据实际情况查看官方的文档。
300万字!全网最全大数据学习面试社区等你来!
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!

2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)
互联网最坏的时代可能真的来了
我在B站读大学,大数据专业
我们在学习Flink的时候,到底在学习什么?
193篇文章暴揍Flink,这个合集你需要关注一下
Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
我们在学习Spark的时候,到底在学习什么?
在所有Spark模块中,我愿称SparkSQL为最强!
硬刚Hive | 4万字基础调优面试小总结
数据治理方法论和实践小百科全书
标签体系下的用户画像建设小指南
4万字长文 | ClickHouse基础&实践&调优全视角解析
【面试&个人成长】2021年过半,社招和校招的经验之谈
大数据方向另一个十年开启 |《硬刚系列》第一版完结
我写过的关于成长/面试/职场进阶的文章
当我们在学习Hive的时候在学习什么?「硬刚Hive续集」