检索增强生成(RAG)已成为增强大型语言模型(LLM)能力的一种强大技术。通过从知识来源中检索相关信息并将其纳入提示,RAG为LLM提供了有用的上下文,以产生基于事实的输出。
但是现有的单代理RAG系统面临着检索效率低下、高延迟和次优提示的挑战。这些问题在限制了真实世界的RAG性能。多代理体系结构提供了一个理想的框架来克服这些挑战并释放RAG的全部潜力。通过划分职责,多代理系统允许专门的角色、并行执行和优化协作。
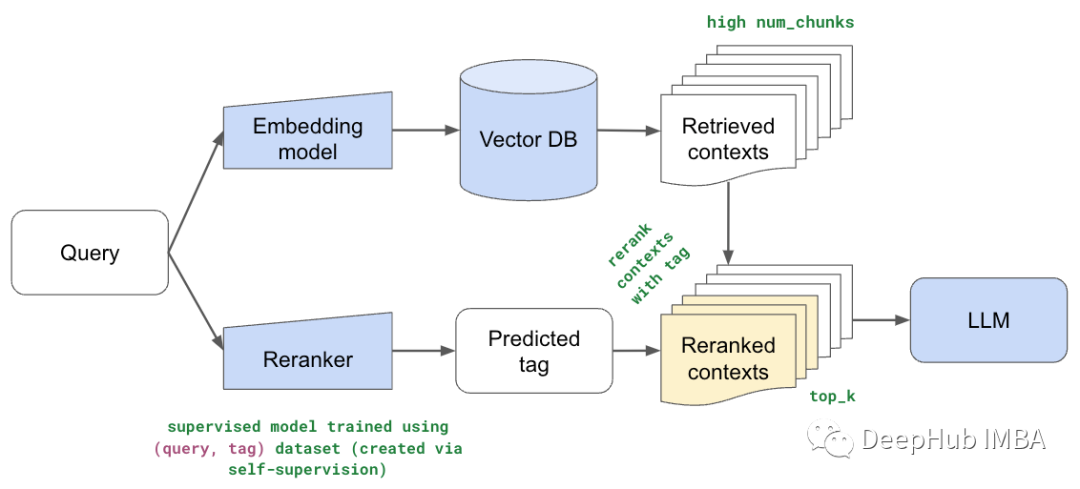
单代理RAG
当前的RAG系统使用单个代理来处理完整的工作流程——查询分析、段落检索、排序、摘要和提示增强。
这种单一的方法提供了一个简单的一体化解决方案。但是对每个任务依赖一个代理会导致瓶颈。代理会浪费时间从大量语料库中检索无关紧要的段落。长上下文的总结很糟糕,并且提示无法以最佳方式集成原始问题和检索到的信息。
这些低效率严重限制了实时应用程序的RAG的可伸缩性和速度。
多代理RAG
多代理体系结构可以克服单代理的限制。通过将RAG划分为并发执行的模块化角色可以实现:
检索:专用检索代理专注于使用优化的搜索技术进行有效的通道检索。这将最小化延迟。
搜索:通过排除检索因素,搜索可以在检索代理之间并行化,以减少等待时间。
排名:单独的排名代理评估检索的丰富度,特异性和其他相关信号的传代。这将过滤最大的相关性。
总结:将冗长的上下文总结成简洁的片段,只包含最重要的事实。
优化提示:动态调整原始提示和检索信息的集成。
灵活的体系:可以替换和添加代理来定制系统。可视化工具代理可以提供对工作流的洞察。
通过将RAG划分为专门的协作角色,多代理系统增强了相关性,减少了延迟,并优化了提示。这将解锁可伸缩的高性能RAG。
划分职责允许检索代理结合互补技术,如向量相似性、知识图谱和互联网抓取。这种多信号方法允许检索捕获相关性不同方面的不同内容。
通过在代理之间协作分解检索和排序,可以从不同的角度优化相关性。结合阅读和编排代理,它支持可伸缩的多角度RAG。
模块化架构允许工程师跨专门代理组合不同的检索技术。
Llama index的多代理 RAG
Llama index概述了使用多代理RAG的具体示例:
文档代理——在单个文档中执行QA和摘要。
向量索引——为每个文档代理启用语义搜索。
摘要索引——允许对每个文档代理进行摘要。
高阶(TOP-LEVEL)代理——编排文档代理以使用工具检索回答跨文档的问题。
对于多文档QA,比单代理RAG基线显示出真正的优势。由顶级代理协调的专门文档代理提供基于特定文档的更集中、更相关的响应。
下面我们看看Llama index是如何实现的:
我们将下载关于不同城市的Wikipedia文章。每篇文章都是单独存储的。我们只找了18个城市,虽然不是很大,但是这已经可以很好的演示高级文档检索的功能。
from llama_index import (VectorStoreIndex,SummaryIndex,SimpleKeywordTableIndex,SimpleDirectoryReader,ServiceContext,)from llama_index.schema import IndexNodefrom llama_index.tools import QueryEngineTool, ToolMetadatafrom llama_index.llms import OpenAI
下面是城市的列表:
wiki_titles = ["Toronto","Seattle","Chicago","Boston","Houston","Tokyo","Berlin","Lisbon","Paris","London","Atlanta","Munich","Shanghai","Beijing","Copenhagen","Moscow","Cairo","Karachi",]
下面是下载每个城市文档代码:
from pathlib import Pathimport requestsfor title in wiki_titles:response = requests.get("https://en.wikipedia.org/w/api.php",params={"action": "query","format": "json","titles": title,"prop": "extracts",# 'exintro': True,"explaintext": True,},).json()page = next(iter(response["query"]["pages"].values()))wiki_text = page["extract"]data_path = Path("data")if not data_path.exists():Path.mkdir(data_path)with open(data_path / f"{title}.txt", "w") as fp:fp.write(wiki_text)
加载下载的文档
# Load all wiki documentscity_docs = {}for wiki_title in wiki_titles:city_docs[wiki_title] = SimpleDirectoryReader(input_files=[f"data/{wiki_title}.txt"]).load_data()
定义LLM +上下文+回调管理器
llm = OpenAI(temperature=0, model="gpt-3.5-turbo")service_context = ServiceContext.from_defaults(llm=llm)
我们为每个文档定义“文档代理”:为每个文档定义向量索引(用于语义搜索)和摘要索引(用于摘要)。然后将这两个查询引擎转换为传递给OpenAI函数调用工具。
文档代理可以动态选择在给定文档中执行语义搜索或摘要。我们为每个城市创建一个单独的文档代理。
from llama_index.agent import OpenAIAgentfrom llama_index import load_index_from_storage, StorageContextfrom llama_index.node_parser import SimpleNodeParserimport osnode_parser = SimpleNodeParser.from_defaults()# Build agents dictionaryagents = {}query_engines = {}# this is for the baselineall_nodes = []for idx, wiki_title in enumerate(wiki_titles):nodes = node_parser.get_nodes_from_documents(city_docs[wiki_title])all_nodes.extend(nodes)if not os.path.exists(f"./data/{wiki_title}"):# build vector indexvector_index = VectorStoreIndex(nodes, service_context=service_context)vector_index.storage_context.persist(persist_dir=f"./data/{wiki_title}")else:vector_index = load_index_from_storage(StorageContext.from_defaults(persist_dir=f"./data/{wiki_title}"),service_context=service_context,)# build summary indexsummary_index = SummaryIndex(nodes, service_context=service_context)# define query enginesvector_query_engine = vector_index.as_query_engine()summary_query_engine = summary_index.as_query_engine()# define toolsquery_engine_tools = [QueryEngineTool(query_engine=vector_query_engine,metadata=ToolMetadata(name="vector_tool",description=("Useful for questions related to specific aspects of"f" {wiki_title} (e.g. the history, arts and culture,"" sports, demographics, or more)."),),),QueryEngineTool(query_engine=summary_query_engine,metadata=ToolMetadata(name="summary_tool",description=("Useful for any requests that require a holistic summary"f" of EVERYTHING about {wiki_title}. For questions about"" more specific sections, please use the vector_tool."),),),]# build agentfunction_llm = OpenAI(model="gpt-4")agent = OpenAIAgent.from_tools(query_engine_tools,llm=function_llm,verbose=True,system_prompt=f"""\You are a specialized agent designed to answer queries about {wiki_title}.You must ALWAYS use at least one of the tools provided when answering a question; do NOT rely on prior knowledge.\""",)agents[wiki_title] = agentquery_engines[wiki_title] = vector_index.as_query_engine(similarity_top_k=2)
下面就是高阶代理,它可以跨不同的文档代理进行编排,回答任何用户查询。
高阶代理可以将所有文档代理作为工具,执行检索。这里我们使用top-k检索器,但最好的方法是根据我们的需求进行自定义检索。
# define tool for each document agentall_tools = []for wiki_title in wiki_titles:wiki_summary = (f"This content contains Wikipedia articles about {wiki_title}. Use"f" this tool if you want to answer any questions about {wiki_title}.\n")doc_tool = QueryEngineTool(query_engine=agents[wiki_title],metadata=ToolMetadata(name=f"tool_{wiki_title}",description=wiki_summary,),)all_tools.append(doc_tool)# define an "object" index and retriever over these toolsfrom llama_index import VectorStoreIndexfrom llama_index.objects import ObjectIndex, SimpleToolNodeMappingtool_mapping = SimpleToolNodeMapping.from_objects(all_tools)obj_index = ObjectIndex.from_objects(all_tools,tool_mapping,VectorStoreIndex,)from llama_index.agent import FnRetrieverOpenAIAgenttop_agent = FnRetrieverOpenAIAgent.from_retriever(obj_index.as_retriever(similarity_top_k=3),system_prompt=""" \You are an agent designed to answer queries about a set of given cities.Please always use the tools provided to answer a question. Do not rely on prior knowledge.\""",verbose=True,)
作为比较,我们定义了一个“简单”的RAG管道,它将所有文档转储到单个矢量索引集合中。设置top_k = 4
base_index = VectorStoreIndex(all_nodes)base_query_engine = base_index.as_query_engine(similarity_top_k=4)
让我们运行一些示例查询,对比单个文档的QA /摘要到多个文档的QA /摘要。
response = top_agent.query("Tell me about the arts and culture in Boston")
结果如下:
=== Calling Function ===Calling function: tool_Boston with args: {"input": "arts and culture"}=== Calling Function ===Calling function: vector_tool with args: {"input": "arts and culture"}Got output: Boston is known for its vibrant arts and culture scene. The city is home to a number of performing arts organizations, including the Boston Ballet, Boston Lyric Opera Company, Opera Boston, Boston Baroque, and the Handel and Haydn Society. There are also several theaters in or near the Theater District, such as the Cutler Majestic Theatre, Citi Performing Arts Center, the Colonial Theater, and the Orpheum Theatre. Boston is a center for contemporary classical music, with groups like the Boston Modern Orchestra Project and Boston Musica Viva. The city also hosts major annual events, such as First Night, the Boston Early Music Festival, and the Boston Arts Festival. In addition, Boston has several art museums and galleries, including the Museum of Fine Arts, the Isabella Stewart Gardner Museum, and the Institute of Contemporary Art.========================Got output: Boston is renowned for its vibrant arts and culture scene. It is home to numerous performing arts organizations, including the Boston Ballet, Boston Lyric Opera Company, Opera Boston, Boston Baroque, and the Handel and Haydn Society. The city's Theater District houses several theaters, such as the Cutler Majestic Theatre, Citi Performing Arts Center, the Colonial Theater, and the Orpheum Theatre.Boston is also a hub for contemporary classical music, with groups like the Boston Modern Orchestra Project and Boston Musica Viva. The city hosts major annual events, such as First Night, the Boston Early Music Festival, and the Boston Arts Festival, which contribute to its cultural richness.In terms of visual arts, Boston boasts several art museums and galleries. The Museum of Fine Arts, the Isabella Stewart Gardner Museum, and the Institute of Contemporary Art are among the most notable. These institutions offer a wide range of art collections, from ancient to contemporary, attracting art enthusiasts from around the world.========================
下面我们看看上面的简单RAG管道的结果
# baselineresponse = base_query_engine.query("Tell me about the arts and culture in Boston")print(str(response))Boston has a rich arts and culture scene. The city is home to a variety of performing arts organizations, such as the Boston Ballet, Boston Lyric Opera Company, Opera Boston, Boston Baroque, and the Handel and Haydn Society. Additionally, there are numerous contemporary classical music groups associated with the city's conservatories and universities, like the Boston Modern Orchestra Project and Boston Musica Viva. The Theater District in Boston is a hub for theater, with notable venues including the Cutler Majestic Theatre, Citi Performing Arts Center, the Colonial Theater, and the Orpheum Theatre. Boston also hosts several significant annual events, including First Night, the Boston Early Music Festival, the Boston Arts Festival, and the Boston gay pride parade and festival. The city is renowned for its historic sites connected to the American Revolution, as well as its art museums and galleries, such as the Museum of Fine Arts, Isabella Stewart Gardner Museum, and the Institute of Contemporary Art.
可以看到我们构建的多代理系统的结果要好的多。
总结
RAG系统必须发展多代理体系结构以实现企业级性能。正如这个例子所说明的,划分职责可以在相关性、速度、摘要质量和及时优化方面获得收益。通过将RAG分解为专门的协作角色,多代理系统可以克服单代理的限制,并启用可扩展的高性能RAG。
https://avoid.overfit.cn/post/7f39d14f7e1a47188870b04c0c332641







![[GitLab] 安装Git 指定版本](https://img-blog.csdnimg.cn/d2b68a6bbedc4c92a0ce048954c7b793.png)