GPT-3.5[24]
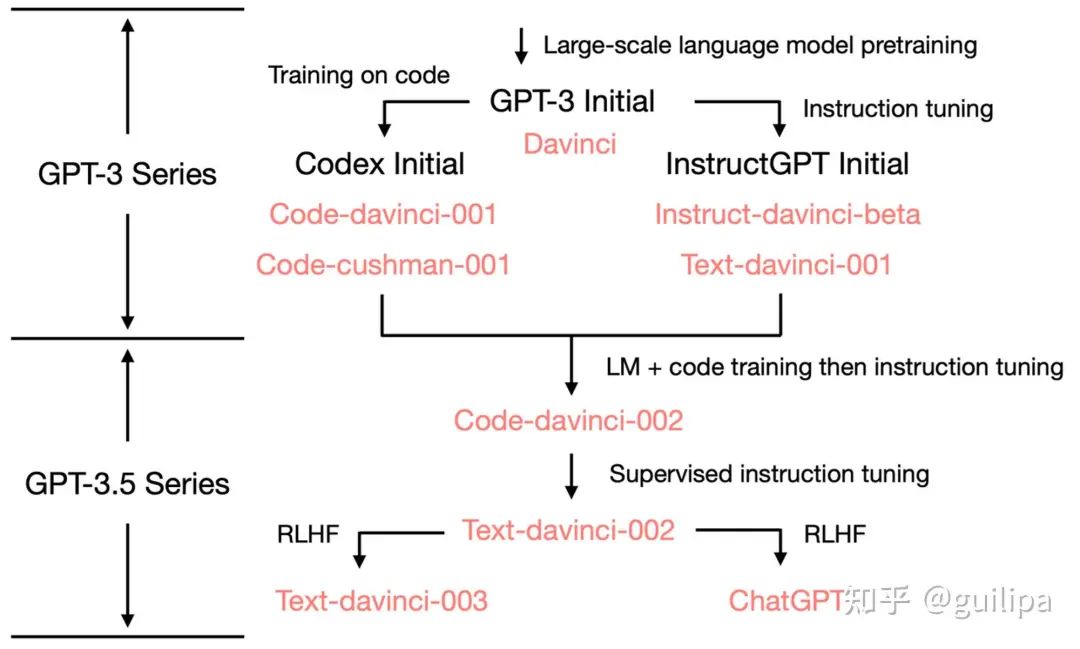
GPT-3.5 是从 GPT-3 演化来的一些列模型,如下图所示,从初始的 GPT-3 到 GPT-3.5 再到 ChatGPT 是经过了一些列的优化和演进。图片来源:ChatGPT进化的秘密 和 拆解追溯 GPT-3.5 各项能力的起源,参考文章整理了以下 GPT-3.5 的演化过程。
-
2020年7月,发布GPT-3,最原始的 GPT-3 基础模型主要有 davinci、curie、ada 和 babbage 四个不同版本,其中 davinci 是功能最强大的,后续也都是基于它来优化的;
-
2021年7月,发布Codex[25],在代码数据上对 GPT-3 微调得到,对应着 code-davinci-001 和 code-cushman-001 两个模型版本;
-
2021年3月,发布 InstructGPT[26] 论文,对 GPT-3 进行指令微调 (supervised fine-tuning on human demonstrations) 得到 davinci-instruct-beta1 模型;在指令数据和经过标注人员评分反馈的模型生成样例数据上进行微调得到 text-davinci-001,InstructGPT 论文中的原始模型对应着 davinci-instruct-beta;
-
2021年6月,发布 code-davinci-002,是功能最强大的 Codex 型号,在文本和代码数据上进行训练,特别擅长将自然语言翻译成代码和补全代码;
-
2021年6月,发布 text-davinci-002,它是在code-davinci-002 基础上进行有监督指令微调得到;
-
2021年11月,发布 text-davinci-003 和 ChatGPT[27], 它们都是在 text-davinci-002 基础上利用人类反馈强化学习 RLHF 进一步微调优化得到。
ChatGPT[28]
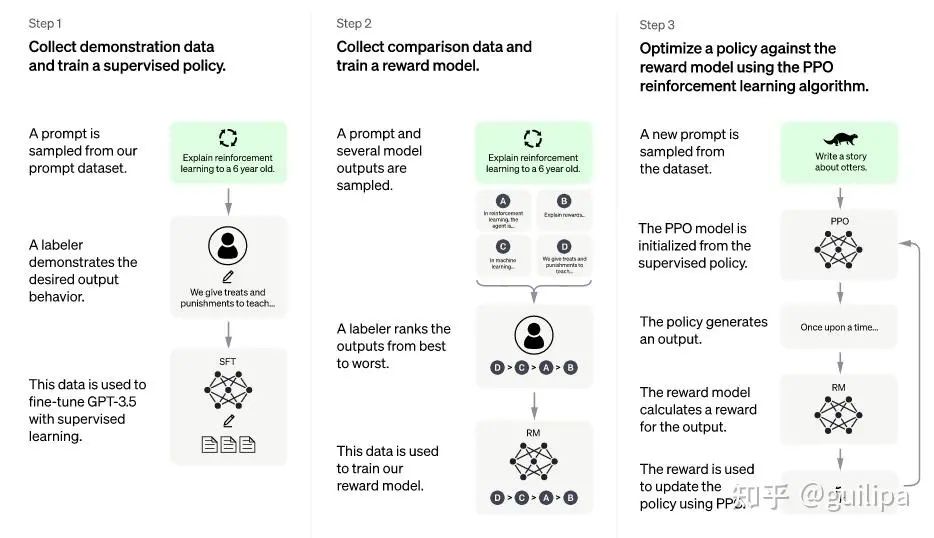
ChatGPT 是在 GPT-3.5 基础上进行微调得到的,微调时使用了从人类反馈中进行强化学习的方法(Reinforcement Learning from Human Feedback,RLHF),这里的人类反馈其实就是人工标注数据,来不断微调 LLM,主要目的是让LLM学会理解人类的命令指令的含义(比如文生成类问题、知识回答类问题、头脑风暴类问题等不同类型的命令),以及让LLM学会判断对于给定的prompt输入指令(用户的问题),什么样的答案输出是优质的(富含信息、内容丰富、对用户有帮助、无害、不包含歧视信息等多种标准)。
其实从 GPT-1到 GPT-3.5 可以发现更大的语言模型虽然有了更强的语言理解和生成的能力,但并不能从本质上使它们更好地遵循或理解用户的指令意图。例如,大型语言模型可能会生成不真实、有害或对用户没有帮助的输出,原因在于这些语言模型预测下一个单词的训练目标与用户目标意图是不一致的。为了对齐语言模型于人类意图,ChatGPT展示了一种途径,可以引入人工标注和反馈,通过强化学习算法对大规模语言模型进行微调,在各种任务上使语言模型与用户的意图保持一致,输出人类想要的内容。
GPT-4[29]
GPT-4 是 OpenAI 继 ChatGPT 之后发布的一个大规模的多模态模型,之前的 GPT 系列模型都是只支持纯文本输入输出的语言模型,而 GPT-4 可以接受图像和文本作为输入,并产生文本输出。GPT-4 仍然是基于 Transformer 的自回归结构的预训练模型。OpenAI 的博客中表示在随意的对话中,GPT-3.5 和 GPT-4 之间的区别可能很微妙,当任务的复杂性达到足够的阈值时,差异就会出现,即 GPT-4 比 GPT-3.5 更可靠、更有创意,并且能够处理更细微的指令。虽然在许多现实场景中的能力不如人类,但 GPT-4 在各种专业和学术基准测试中表现出人类水平的表现,包括通过模拟律师考试,得分在应试者的前 10% 左右。和 ChatGPT RLHF 的方法类似,alignment(对齐)训练过程可以提高模型事实性和对期望行为遵循度的表现,具有强大的意图理解能力,并且对 GPT-4 的安全性问题做了很大的优化和提升。