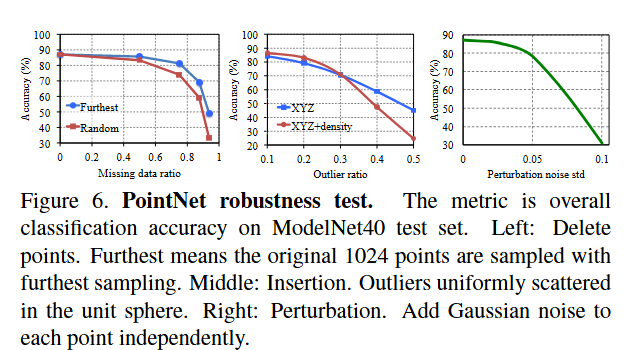
文章目录
- 版本及工具介绍
- Java 对象结构
- 对象头
- mark word 标记字
- mark word 标记字解析
- Lock Record
- class point 类元数据指针
- 实例数据
- 对齐填充
- 为什么需要对齐填充
- 常见 Java 数据类型对象分析
- ArrayList
- Long
- String
- Byte
- Boolean
- 其它
- 指针压缩
- 前置知识:32位操作系统为什么最多支持 4G 内存
- 从32位操作系统到64位操作系统
- 指针压缩:使用4字节指针的同时获得更大的内存
- 如何开启指针压缩
- 实现原理
- 思考
- mark word 数据字段为什么是不固定动态变化的
- mark word 是字段动态变化的,当获取锁时 hash code 等字段被存储在哪
- 个人简介
版本及工具介绍
- JDK版本:JDK 8
- Java 对象分析 Maven 插件
<dependency><groupId>org.openjdk.jol</groupId><artifactId>jol-core</artifactId><version>0.17</version></dependency>
Java 对象结构
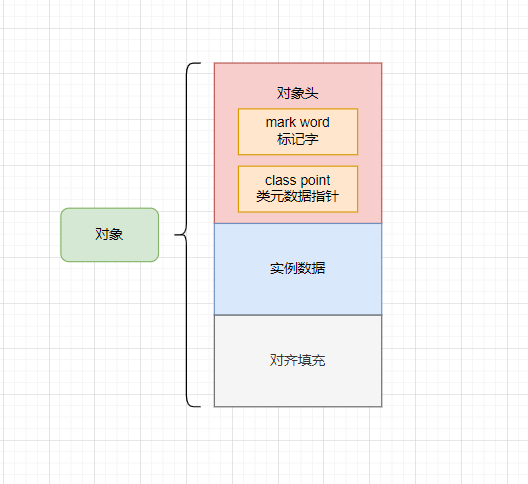
- 一个 Java 对象由三部分组成:对象头、实例数据、对齐数据,其中对象头分为 mark word 标记字和 class point 类元数据指针。
- jol-core 是 Java Object Layout(JOL)库的一部分,它是一个用于分析Java对象内存布局的工具。JOL 允许我们深入了解Java对象的内部结构,包括字段的偏移量、大小和布局,以及对象头的信息等。这对于性能优化和调试非常有用,特别是当我们需要了解对象在内存中的布局时。
- 如何使用 jol-core 打印Java对象信息
public class Test {static final A MUTEX = new A();public static void main(String[] args) {// 打印 JVM 信息System.out.println(VM.current().details());// hashCode 懒加载,调用 hashCode() 方法时生成存储在对象头System.out.println(MUTEX.hashCode());System.out.println(ClassLayout.parseInstance(MUTEX).toPrintable());synchronized (MUTEX) {System.out.println(ClassLayout.parseInstance(MUTEX).toPrintable());}System.out.println(ClassLayout.parseInstance(MUTEX).toPrintable());}
}class A {int a = 2;
}// 输出
# VM mode: 64 bits
# Compressed references (oops): 3-bit shift
# Compressed class pointers: 3-bit shift
# Object alignment: 8 bytes
# ref, bool, byte, char, shrt, int, flt, lng, dbl
# Field sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8
# Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8
# Array base offsets: 16, 16, 16, 16, 16, 16, 16, 16, 161407343478 // 对象 hashCodeconcurrency.A object internals:
OFF SZ TYPE DESCRIPTION VALUE0 8 (object header: mark) 0x00000053e25b7601 (hash: 0x53e25b76; age: 0)8 4 (object header: class) 0xf800c14312 4 int A.a 2
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total// 64位JVM mark word 占用8字节
// 64位JVM class point 元数据指针占用4字节(正常应该占用8字节,这里开启了指针压缩)
// 实例数据 int字段占用4字节
// 共计 16 字节 默认8字节对齐,不需要补齐concurrency.A object internals:
OFF SZ TYPE DESCRIPTION VALUE0 8 (object header: mark) 0x00000096d75ff7e8 (thin lock: 0x00000096d75ff7e8)8 4 (object header: class) 0xf800c14312 4 int A.a 2
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes totalconcurrency.A object internals:
OFF SZ TYPE DESCRIPTION VALUE0 8 (object header: mark) 0x00000053e25b7601 (hash: 0x53e25b76; age: 0)8 4 (object header: class) 0xf800c14312 4 int A.a 2
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
对象头
- 对象头由 mark word 标记字和 class point 类元数据指针两部分组成。
mark word 标记字
- mark word 记录了 Java 对象运行时的数据信息,如持有的锁、是否是偏向锁、锁持有线程、hashcode、分代年龄等等,32位JVM中占用4个字节,64位JVM中占用8个字节,具体字段如下所示:

mark word 标记字解析
补充知识:
大端存储(Big-Endian):数据的高字节存储在低地址中,数据的低字节存储在高地址中
小端存储(Little-Endian):数据的高字节存储在高地址中,数据的低字节存储在低地址中// 上文示例 Mark word 分析 JVM 64位
0x00000053e25b7601 (hash: 0x53e25b76; age: 0)十六进制数: 0x00000053e25b7601
二进制数: 0000 0000 0000 0000 0000 0000 0101 00111110 0010 0101 1011 0111 0110 0000 0001锁标记: 01 无锁
分代年龄:0000 age:0
hashCode: 101 0011 1110 0010 0101 1011 0111 0110 = hash: 0x53e25b76 = 十进制:14073434780x00000096d75ff7e8 (thin lock: 0x00000096d75ff7e8)十六进制数: 0x00000096d75ff7e8
二进制数: 0000 0000 0000 0000 0000 0000 1001 01101101 0111 0101 1111 1111 0111 1110 1000锁标记: 00 轻量级锁
指向线程堆栈Lock Record指针:
0000 0000 0000 0000 0000 0000 1001 0110 1101 0111 0101 1111 1111 0111 1110 10
Lock Record
- lock record 保存对象 mark word 的原始值,还包含识别哪个对象被锁的所必需的元数据。
class point 类元数据指针
- class point 类元数据指针指向方法区的instanceKlass实例(虚拟机根据该指针确认对象是哪个类的实例),32位JVM中占用4个字节,64位JVM中占用8个字节或4个字节(指针压缩)。
实例数据
- 存储对象的字段信息。(包括继承的字段)
对齐填充
- Java 对象的大小默认8字节对齐,当大小不为8的倍数时,需要进行对齐填充,如:14字节需要填充为16字节。
为什么需要对齐填充
- 对齐填充是一种以空间换时间的方案,可以提高内存的访问效率,本质是为了更加高效的利用缓存行。
示例:
CPU缓存行(Cache Line)是计算机处理器缓存的最小存储单位,一般来说,32 位系统一般为 4字节、64位系统一般为 8字节。

- 指针压缩技术也依赖 Java 对象字节对齐。
常见 Java 数据类型对象分析
ArrayList
java.util.ArrayList object internals:
OFF SZ TYPE DESCRIPTION VALUE0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)8 4 (object header: class) 0xf8002f3912 4 int AbstractList.modCount 316 4 int ArrayList.size 320 4 java.lang.Object[] ArrayList.elementData [(object), (object), (object), null, null, null, null, null, null, null, null, null, null, null, null, null]
Instance size: 24 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
Long
java.lang.Long object internals:
OFF SZ TYPE DESCRIPTION VALUE0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)8 4 (object header: class) 0xf80022c012 4 (alignment/padding gap) 16 8 long Long.value 1
Instance size: 24 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
String
java.lang.String object internals:
OFF SZ TYPE DESCRIPTION VALUE0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)8 4 (object header: class) 0xf80002da12 4 char[] String.value [S, t, r, i, n, g]16 4 int String.hash 020 4 (object alignment gap)
Instance size: 24 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
Byte
java.lang.Byte object internals:
OFF SZ TYPE DESCRIPTION VALUE0 8 (object header: mark) 0x0000000000000005 (biasable; age: 0)8 4 (object header: class) 0xf80021eb12 1 byte Byte.value 113 3 (object alignment gap)
Instance size: 16 bytes
Space losses: 0 bytes internal + 3 bytes external = 3 bytes total
Boolean
java.lang.Boolean object internals:
OFF SZ TYPE DESCRIPTION VALUE0 8 (object header: mark) 0x0000000000000005 (biasable; age: 0)8 4 (object header: class) 0xf800209712 1 boolean Boolean.value true13 3 (object alignment gap)
Instance size: 16 bytes
Space losses: 0 bytes internal + 3 bytes external = 3 bytes total
其它
指针压缩
前置知识:32位操作系统为什么最多支持 4G 内存
- 先看一张8字节的内存:
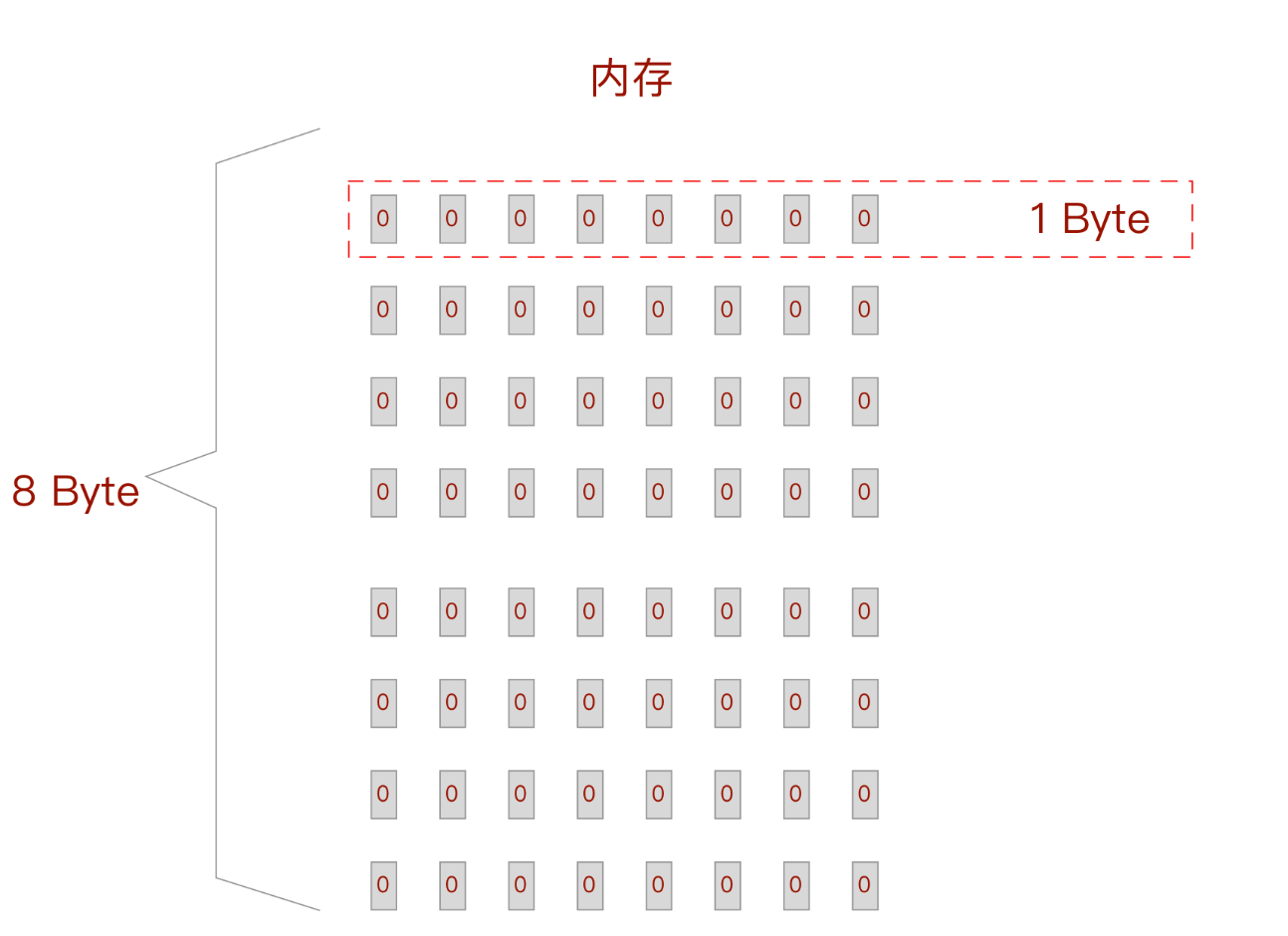
如果需要寻址上面的所有格子:那么我们需要 2^6 次方个地址,即 6位操作系统。相同的算法我们计算32位的操作系统:
2^32 bit = 2^29 byte = 2^19 KB = 2^9 MB = 2^-1 GB = 0.5 GB实际值为0.5G,但是为什么说32位 CPU 最多支持 4G 内存呢?实际上CPU会把 8 bit(1Byte)当作一组,即最小的读取单元为 1 Byte, 因此 2^32 * 1 Byte = 4G// 实际上,能够使用的内存大小由两方面决定硬件和操作系统,操作系统指的是虚拟地址层面,而硬件指的是地址总线。
// 其它参考:https://www.zhihu.com/question/22594254/answer/42967413
从32位操作系统到64位操作系统
- 从上面我们知道32操作系统最多使用的内存为4G,随着我们开发的程序越来越复杂,32位操作系统已经不能满足我们的内存需求,我们进入了64操作系统的时代,我们可以使用的内存达到 4G * 2^32 ,但指针长度也达到了8个字节,过长的指针带来了新的问题:
1、增加了GC开销:64位对象引用需要占用更多的堆空间,留给其他数据的空间将会减少,从而加快了GC的发生,更频繁的进行GC。
2、降低缓存命中率:64位对象引用增大了,内存能缓存的oop将会更少,从而降低了缓存的效率。
指针压缩:使用4字节指针的同时获得更大的内存
如何开启指针压缩
-XX:+UseCompressedOops // 对象指针压缩
-XX:+UseCompressedClassPointers // 类元数据指针压缩// 如上示例中已开启
# Compressed references (oops): 3-bit shift
# Compressed class pointers: 3-bit shift// 64 JVM class point 占用4个字节
concurrency.A object internals:
OFF SZ TYPE DESCRIPTION VALUE0 8 (object header: mark) 0x00000053e25b7601 (hash: 0x53e25b76; age: 0)8 4 (object header: class) 0xf800c14312 4 int A.a 2
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
实现原理
// JVM 中 java对象默认8字节对齐 最大堆内存 32 GB(4G * 2^3),超过 32 GB 指针压缩将失效
-XX:ObjectAlignmentInBytes8字节对齐的情况下,地址的后三位总是为0:8 = 100016 = 1000024 = 1100032 = 10000040 = 10100048 = 11000056 = 11100064 = 100000072 = 1001000因此,在Java对象中存储时通过右移三位将3个0抹去,从内存中获取值时再通过将Java对象中的地址左移3位补0,从而实现使用4个字节获得 2^32 * 2^3 个内存地址,一个内存地址指向 1Byte 则总计32G内存(这也是为什么我们经常看到一些文章中说Java堆内存不要超过32G的原因,因为4字节指针,8字节对齐无法表示超过32内存,会关闭指针压缩,除非调整对齐字节数来扩大可访问的内存空间)。设置为16字节对齐:最大堆内存 64 GB(4G * 2^4),超过 64 GB 指针压缩将失效16 = 1000032 = 10000048 = 11000064 = 1000000
思考
mark word 数据字段为什么是不固定动态变化的
- 实现不增加对象的内存占用的情况下,支持对象锁并发和锁优化。
mark word 是字段动态变化的,当获取锁时 hash code 等字段被存储在哪
- HotSpot VM 若为偏向锁则未获取 hash code,若已获取 hash code 则不会获取偏向锁而是直接获取轻量级锁(若为偏向级锁,此时获取 hash code 则会膨胀为重量级锁),轻量级锁时 hash code 存放在 Lock Record 中,重量级锁时 hash code 存放在 ObjectMonitor 对象上。
- 注意:这里讨论的hash code都只针对identity hash code。用户自定义的hashCode()方法生成的 hash code 不会放在对象头。(Identity hash code是未被覆写的 java.lang.Object.hashCode() 或者 java.lang.System.identityHashCode(Object) 所返回的值。)
- 参考大R回答:https://www.zhihu.com/question/52116998/answer/133400077
个人简介
👋 你好,我是 Lorin 洛林,一位 Java 后端技术开发者!座右铭:Technology has the power to make the world a better place.
🚀 我对技术的热情是我不断学习和分享的动力。我的博客是一个关于Java生态系统、后端开发和最新技术趋势的地方。
🧠 作为一个 Java 后端技术爱好者,我不仅热衷于探索语言的新特性和技术的深度,还热衷于分享我的见解和最佳实践。我相信知识的分享和社区合作可以帮助我们共同成长。
💡 在我的博客上,你将找到关于Java核心概念、JVM 底层技术、常用框架如Spring和Mybatis 、MySQL等数据库管理、RabbitMQ、Rocketmq等消息中间件、性能优化等内容的深入文章。我也将分享一些编程技巧和解决问题的方法,以帮助你更好地掌握Java编程。
🌐 我鼓励互动和建立社区,因此请留下你的问题、建议或主题请求,让我知道你感兴趣的内容。此外,我将分享最新的互联网和技术资讯,以确保你与技术世界的最新发展保持联系。我期待与你一起在技术之路上前进,一起探讨技术世界的无限可能性。
📖 保持关注我的博客,让我们共同追求技术卓越。

![[动态规划] (六) 路径问题 LeetCode 63.不同路径II](https://img-blog.csdnimg.cn/img_convert/801646ea2895286da122a7c396fdd7fd.png)