三、 0-1 矩阵的列集互斥问题。给定一个 m × n m \times n m×n 的 0-1 矩阵 A \mathrm{A} A 。定义列互斥为: 对于矩阵 A A A 中的任意两列 i i i 和 j j j, 如果在对应的每一行上, i i i 和 j j j 不存在同时为 1 的情况, 则称列 i \mathrm{i} i 和 j \mathrm{j} j 互斥。定义列集互斥为: 设 S 1 \mathrm{S} 1 S1 和 S 2 \mathrm{S} 2 S2 为矩阵 A \mathrm{A} A 中的列的集合, S 1 S1 S1 和 S 2 S2 S2 之间没有交集 (即, 不允许 A \mathrm{A} A 中的某列既属于 S 1 \mathrm{S} 1 S1 又属于 S 2 \mathrm{S} 2 S2 ), 如果在对应的每一行上, S 1 \mathrm{S} 1 S1 中的任意一列和 S 2 \mathrm{S} 2 S2 中的任意一列不存在同时为 1 的情况, 则称列集 S 1 \mathrm{S} 1 S1 和 S 2 S2 S2 互斥。设计一个算法, 求出 A \mathrm{A} A 上的一组 S 1 \mathrm{S} 1 S1 和 S 2 \mathrm{S} 2 S2 ,使得 S 1 \mathrm{S} 1 S1 和 S 2 \mathrm{S} 2 S2 包含的列的个数为最多
S 1 S1 S1和 S 2 S2 S2非空。
思路:

适当的利用剪枝函数和限界函数以减少搜索的空间:
- 剪枝函数:即题目要求,只有互斥才能进入下一层。
- 限界函数:目前A和B矩阵的列数加上剩余的列数已经小于当前最优解,放弃向下搜索。
使用Py编写这个算法的时候,可以使用numpy库的数据,加快我们运行的速度,同时可以减少很多循环遍历数组的冗余代码。
为了节省时间,我们在开始计算前,先把 n n n列向量的互斥关系都计算出来,保存在一个 n × n n \times n n×n的矩阵内。
import numpy as np
import matplotlib.pyplot as pltclass Matrix:def __init__(self, array):self.array = arrayrows, columns = array.shapeself.belong = np.zeros(columns, dtype=int) # 1属于A, 2属于Bself.solve = np.zeros(columns, dtype=int) # 最终解self.best = 0 # 最佳列数self.sumA = 0 # 记录当前A列数self.sumB = 0 # 记录当前B列数self.judge = np.ones((columns, columns), dtype=int) # 减少时间的关键,判断两列互斥self.diff = 9999# 先计算出列与列之间的互斥关系1代表不互斥,0代表互斥for i in range(columns):self.judge[i, i] = 0for j in range(i):for k in range(rows):if array[k, i] == 1 and array[k, j] == 1:self.judge[i, j] = 0self.judge[j, i] = 0break# j列能否归入Adef could_be_a(self, j):for i in range(j):if self.belong[i] == 2 and self.judge[i, j] == 0:return Falsereturn True# j列能否归入Bdef could_be_b(self, j):for i in range(j):if self.belong[i] == 1 and self.judge[i, j] == 0:return Falsereturn Truedef biggest_divide(self, i):columns = self.array.shape[1]if i >= columns:if self.sumA + self.sumB > self.best and self.sumA and self.sumB and np.abs(self.sumA-self.sumB) < self.diff:self.best = self.sumA + self.sumBself.solve = self.belong.copy()self.diff = np.abs(self.sumA-self.sumB)returnif self.could_be_a(i):self.belong[i] = 1self.sumA += 1self.biggest_divide(i + 1)self.belong[i] = 0self.sumA -= 1if self.could_be_b(i):self.belong[i] = 2self.sumB += 1self.biggest_divide(i + 1)self.belong[i] = 0self.sumB -= 1if self.sumA + self.sumB + columns - i >= self.best:self.biggest_divide(i + 1)def show(self):a_indices = np.where(self.solve == 1)[0]b_indices = np.where(self.solve == 2)[0]print("A:", a_indices)print("B:", b_indices)color_array = self.array.copy()color_array[:, a_indices] *= 10color_array[:, b_indices] *= 7plt.matshow(color_array, cmap=plt.cm.Reds)plt.show()row = 50
colume = 20
array = np.random.choice([0, 1], size=(row, colume), p=[0.8, 0.2])
test = Matrix(array)
test.biggest_divide(0)
test.show()
使用show来可视化最终结果,如果这里只取列数合最大,一般A列都比较多,如果要好看的结果可以限制A列和B列之间距离越小越好,多设置一个diff参数,当列数合相同时,保存A列与B列相差较小的结果。
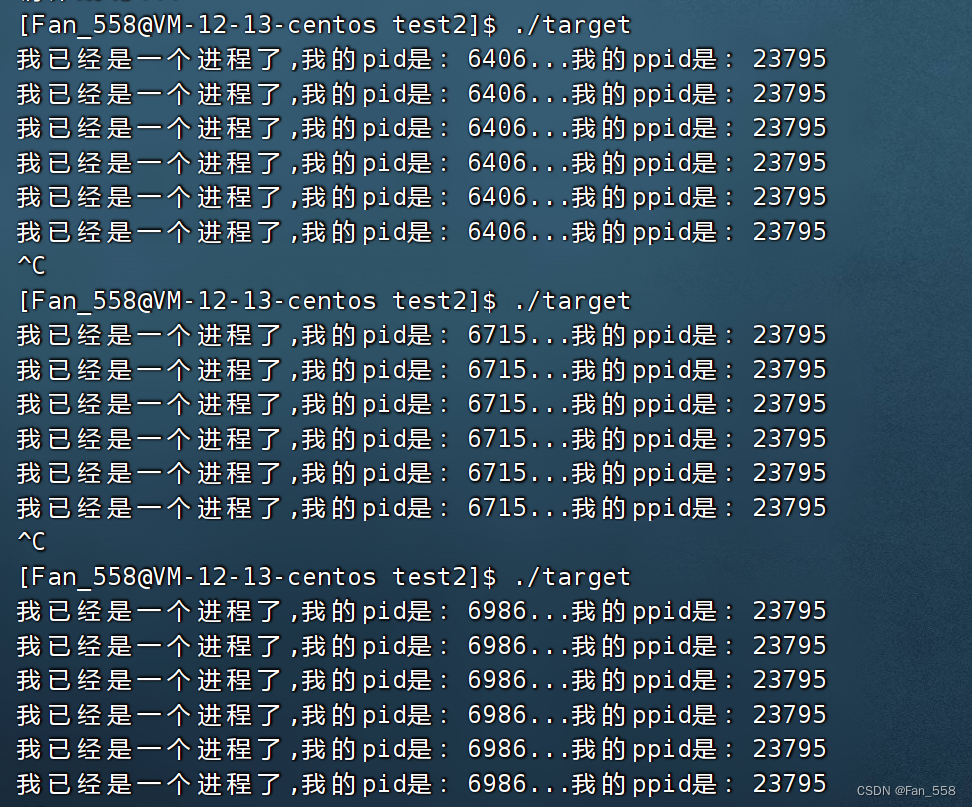
在 m m m=50, n n n=20下,1填充率为20%,随机填充下的互斥结果,深红色为A集合,鲜红色为B集合。
A: [ 0 5 16 17 19]
B: [ 2 7]

时间复杂度分析:
- 对于每一列,回溯算法会考虑三种可能性:将其归入 A 部分或归入 B 部分或者不归入。
- 对于每一列的三种可能性,又会递归考虑下一列的三种可能性,以此类推。
- 这样的递归结构导致了指数级的搜索树。
- 在最坏情况下,需要考虑的列数等于矩阵的列数,因此有 3 n 3^n 3n种可能性,其中 n n n 是列数。