DB-GPT介绍
- 引言
- DB-GPT项目简介
- DB-GPT架构
- 关键特性
- 私域问答&数据处理
- 多数据源&可视化
- 自动化微调
- Multi-Agents&Plugins
- 多模型支持与管理
- 隐私安全
- 支持数据源
- 子模块
- DB-GPT-Hub
- 微调
- 参考文献
引言
随着数据量的不断增长和数据分析的需求日益增多,将自然语言文本转化为结构化查询语言(SQL)的能力变得越来越重要。Text to SQL方案是一种将自然语言查询转化为SQL查询的技术,它可以帮助用户更轻松、更高效地从文本中提取所需的信息。
博主近期在研究text2sql的项目应用,从大模型和传统的深度学习模型两方面入手,未来会持续发布相关文章,本文将介绍Text to SQL的一种基于大模型的方案:DB-GPT。安装与部署可以参考博主这篇文章:部署DB-GPT
DB-GPT项目简介
DB-GPT项目(项目地址)是在github上发布的,为解决使用大模型和数据库交互的过程中,私密数据以及环境是否能掌握自己的手里,完全自主可控的问题。项目支持为所有以数据库为基础的场景,构建一套完整的私有大模型解决方案。 此方案因为支持本地部署,所以不仅仅可以应用于独立私有环境,而且还可以根据业务模块独立部署隔离,让大模型的能力绝对私有、安全、可控。
DB-GPT架构
DB-GPT基于 FastChat 构建大模型运行环境。此外,项目通过LangChain提供私域知识库问答能力。同时支持插件模式, 在设计上原生支持Auto-GPT插件。
整个DB-GPT的架构,如下图所示
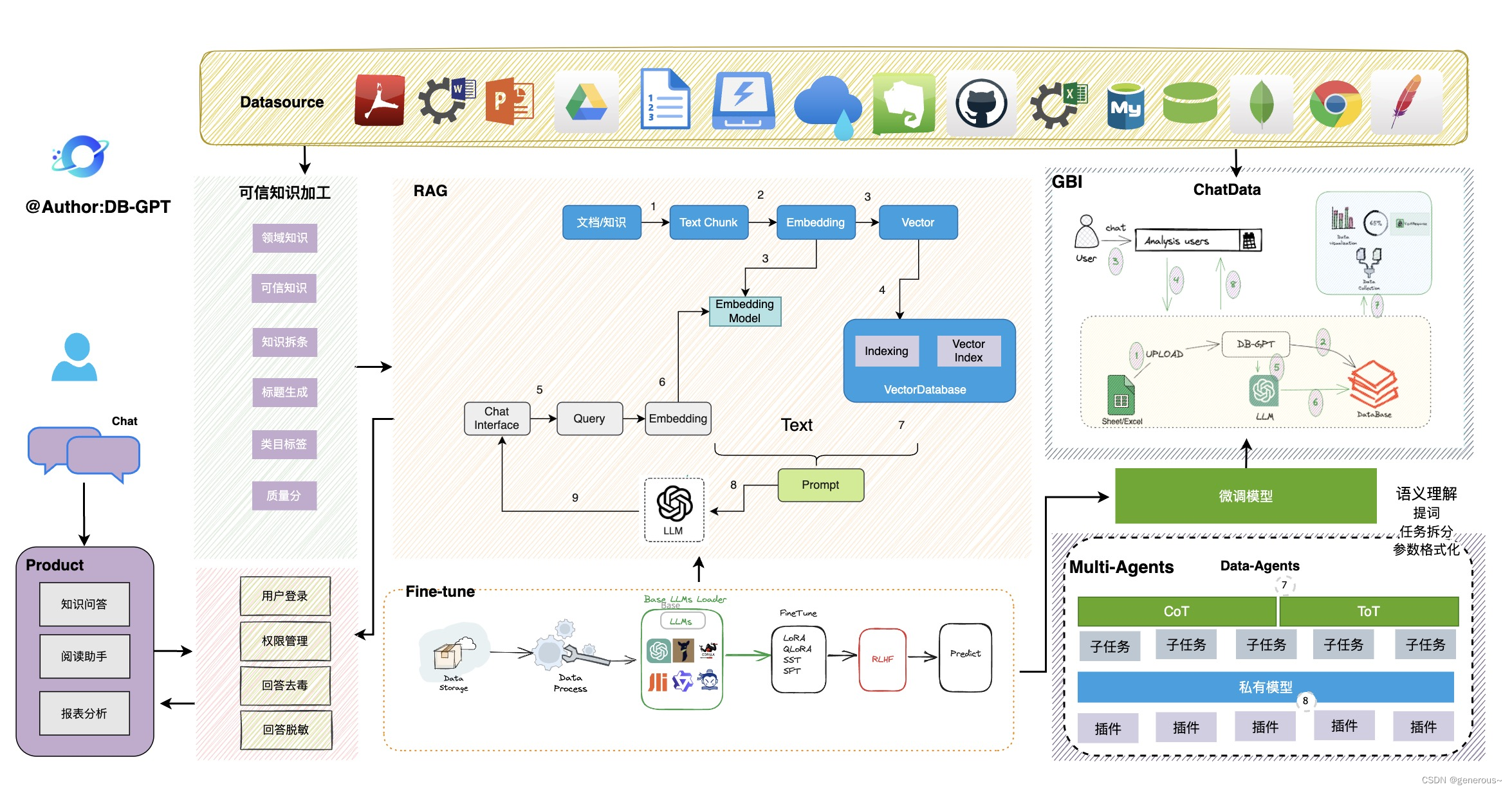
RAG:检索式增强生成方法(retrieval-augmented generation)
关键特性
私域问答&数据处理
支持内置、多文件格式上传、插件自抓取等方式自定义构建知识库,对海量结构化,非结构化数据做统一向量存储与检索
多数据源&可视化
支持自然语言与Excel、数据库、数仓等多种数据源交互,并支持分析报告。
自动化微调
围绕大语言模型、Text2SQL数据集、LoRA/QLoRA/Pturning等微调方法构建的自动化微调轻量框架, 让TextSQL微调像流水线一样方便。详见: DB-GPT-Hub
Multi-Agents&Plugins
支持自定义插件执行任务,原生支持Auto-GPT插件模型,Agents协议采用Agent Protocol标准
多模型支持与管理
海量模型支持,包括开源、API代理等几十种大语言模型。如LLaMA/LLaMA2、Baichuan、ChatGLM、文心、通义、智谱等。
支持多种大语言模型, 当前已支持如下模型(列举几个常用):
Vicuna
vicuna-13b-v1.5
LLama2
baichuan2-13b
baichuan-7B
chatglm-6b
chatglm2-6b
隐私安全
通过私有化大模型、代理脱敏等多种技术保障数据的隐私安全。
支持数据源
MySQL
PostgresSQL
Spark
DuckDB
Sqlite
MSSQL
ClickHouse
子模块
DB-GPT-Hub 通过微调来持续提升Text2SQL效果
DB-GPT-Plugins DB-GPT 插件仓库, 兼容Auto-GPT
DB-GPT-Web 多端交互前端界面
DB-GPT-Hub
DB-GPT-Hub是一个利用LLMs实现Text-to-SQL解析的实验项目,主要包含数据集收集、数据预处理、模型选择与构建和微调权重等步骤,通过这一系列的处理可以在提高Text-to-SQL能力的同时降低模型训练成本,让更多的开发者参与到Text-to-SQL的准确度提升工作当中,最终实现基于数据库的自动问答能力,让用户可以通过自然语言描述完成复杂数据库的查询操作等工作。
目前项目已经基于多个大模型打通从数据处理、模型SFT训练、预测输出和评估的整个流程,代码在本项目中均可以直接复用。
参考链接:https://zhuanlan.zhihu.com/p/642719916
博主计划下一篇文章进行微调操作的讲解。
微调
本项目微调不仅能支持QLoRA和LoRA法,还支持deepseed(多卡训练)
QLoRA方法: https://zhuanlan.zhihu.com/p/634516004
参考文献
[1]DB-GPT: 用私有化LLM技术定义数据库下一代交互方式:https://zhuanlan.zhihu.com/p/654452504