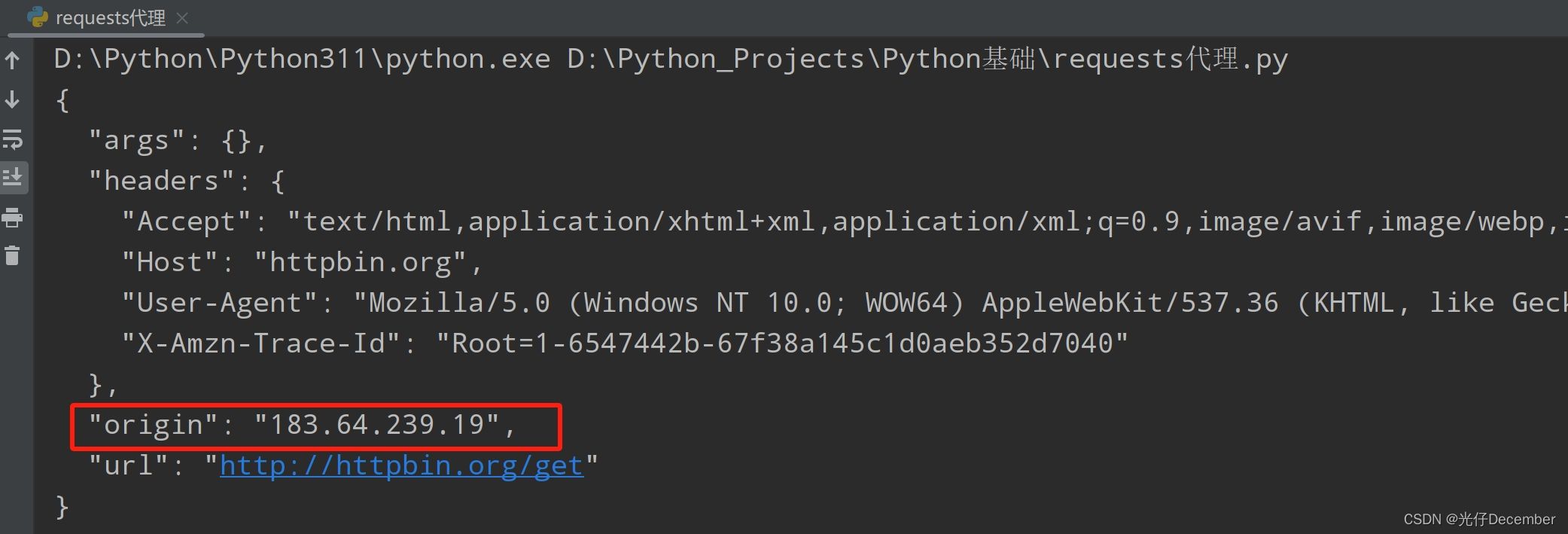
大家好,我是洋子,接触过接口自动化测试的同学都知道,我们一般要基于某种自动化测试框架,编写自动化case,编写自动化case的依据来源于接口文档,对照接口文档里面的请求参数进行人工添加接口自动化case
其实,对于日常新的服务端需求的迭代,人工一次性补充20个以下接口自动化case,还是可以接受。如果一次性要补充50个以上的接口case,光靠人工去填写就显得非常耗时了
还有一种比较常见的场景,一些老的服务模块需要进行迁移或者是重构,这些老模块本身可能也没有接口文档,业务逻辑也没有改变,如何确保原来业务在迁移后的正确运行非常重要,光靠QA进行接口测试也很难保障迁移后的新服务线上没有问题
为了最大程度的覆盖测试,我们可以通过复制线上流量拷贝到线下生成自动化case进行接口的功能测试以及diff测试,这种技术就叫流量回放
什么是流量回放
流量回放从字面意思理解,流量可以理解成互联网上发送和接收数据的量,由于我们网络通信协议一般都是HTTP请求,前后端交互方式一般通过后端API接口,所以流量的形式可以理解成线上的接口请求数量
而回放就是改变接口请求信息的位置,比如存放在到线下的数据库,Redis,或者分布式大数据集群中,也可以不经过存储进行实时回放,使得我们能够对线上流量进行利用
流量回放再通俗理解成两个字,就是引流
流量回放可以将流量进行拷贝后直接使用,也能把流量放大、流量缩小后使用
流量拷贝指的是将线上正式流量通过改写业务逻辑、tcpcopy、日志回放等方法在线下环境回放,从而达到测试的目的
流量拷贝可以完全模拟线上的流量,从而对复杂的业务场景进行仿真测试,并且不会对线上服务产生影响
一份流量复制多份,每份流量经过修改目的地址后发送到同一台实例上,比如拷贝5份流量到同一台实例,这台实例就能比线上环境同一时间多抗5倍压力,就能实现对线下环境进行压测,这就叫流量放大
那有小伙伴问,能放大,可以缩小吗?当然可以,流量缩小是通过复制部分流量并对其进行处理,以实现流量的缩小。这样做的原因可能是为了减少流量的规模或为了对流量进行进一步的分析和处理
在线下测试中难以覆盖的场景,都可以通过流量拷贝的方式来测试,测试的场景更广泛,覆盖面也更大
业界经验
目前业界也有一些常用的引流解决方案
阿里Doom
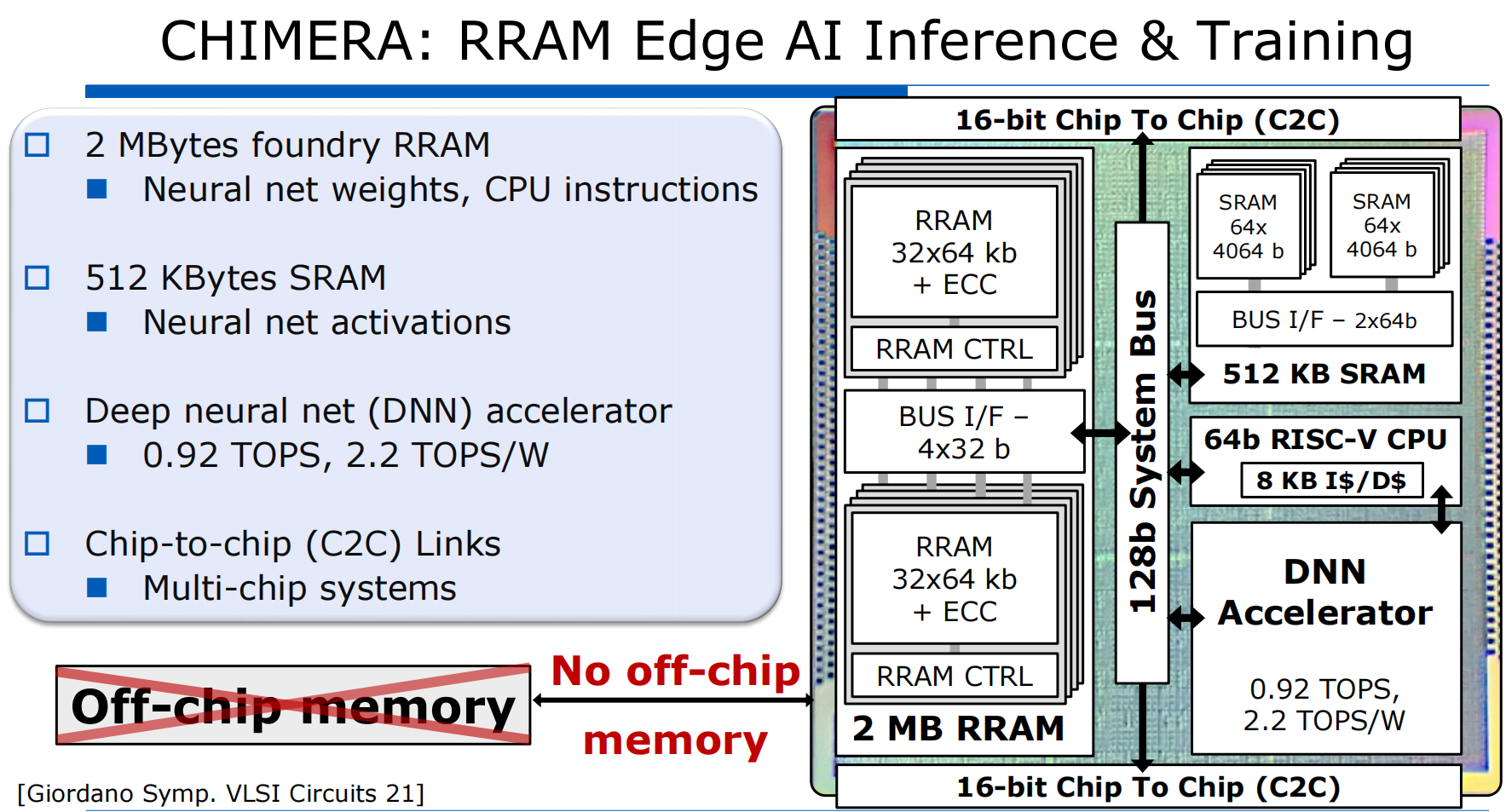
Doom是一个将一部分线上真实流量复制并用于自动回归测试的平台。其在应用内部通过aop切面编程方式实现的流量录制和回放功能,由于最底层借助了java的instrument实现aop,因此目前仅支持java应用的接入使用。其原理图如下:

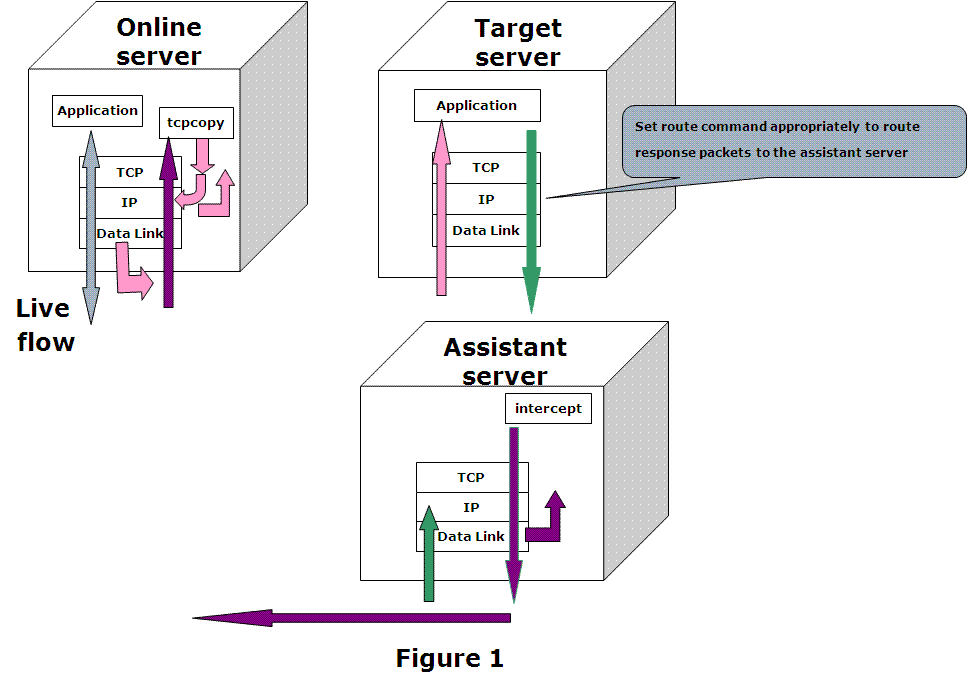
TCPCopy
TCPCopy是一种请求复制 (所有基于tcp的packets) 工具,由tcpcopy和intercept组成,其中tcpcopy在线上服务上运行并利用原始socket复制线上流量到测试服务上 (粉红色的线),intercept部署在辅助服务器上,负责接收响应(绿色的线)并回传给tcpcopy (紫色的线),具体见下图:
GoReplay
Goreplay是用 Golang开发的 HTTP 实时流量复制工具。支持流量的放大、缩小,频率限制,还支持把请求记录到文件,方便回放和分析,也支持和 ElasticSearch 集成,将流量存入 ES 进行实时分析GoReplay不是代理,而是监听网络接口上的流量,不需要更改生产基础架构,只需与服务相同的计算机上运行 。具体原理见下图
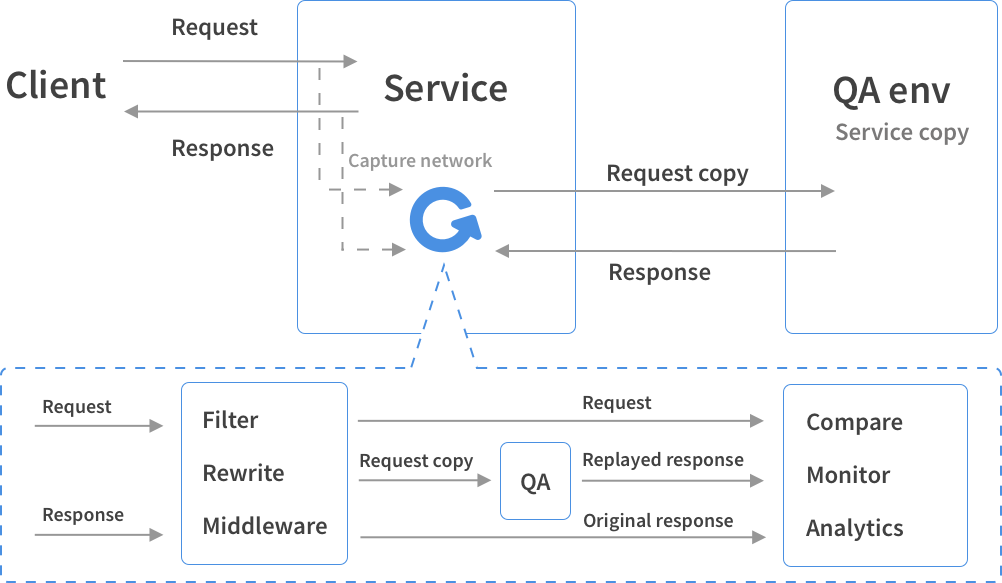
Nginx的ngx_http_mirror_module模块
Nginx 1.13.4 中引入ngx_http_miror_module模块来支持应用层的流量复制。该模块通过mirror配置指令来实现流量复制。如下图,可以通过下面配置来实现复制proxy.local流量到test.local
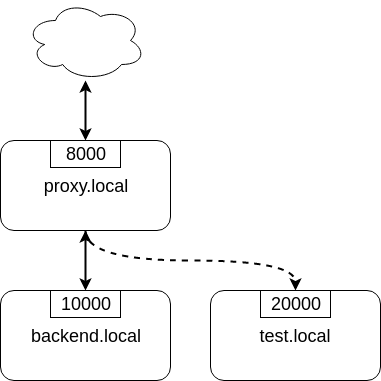
upstream backend {server backend.local:10000;
}upstream test_backend {server test.local:20000;
}server {server_name proxy.local;listen 8000;location / {mirror /mirror;proxy_pass http://backend;}location = /mirror {internal;proxy_pass http://test_backend$request_uri;}
}
其中每一条mirror配置项对应用户请求的一个副本,可以通过配置多次mirror指令来实现“流量放大”的效果。当然,你也可以将多个副本转发给不同的后端目标系统
流量回放的三种方式
从引流自身来看,主要有3种类型,分别是:主路复制、旁路复制、日志回放
主路复制:
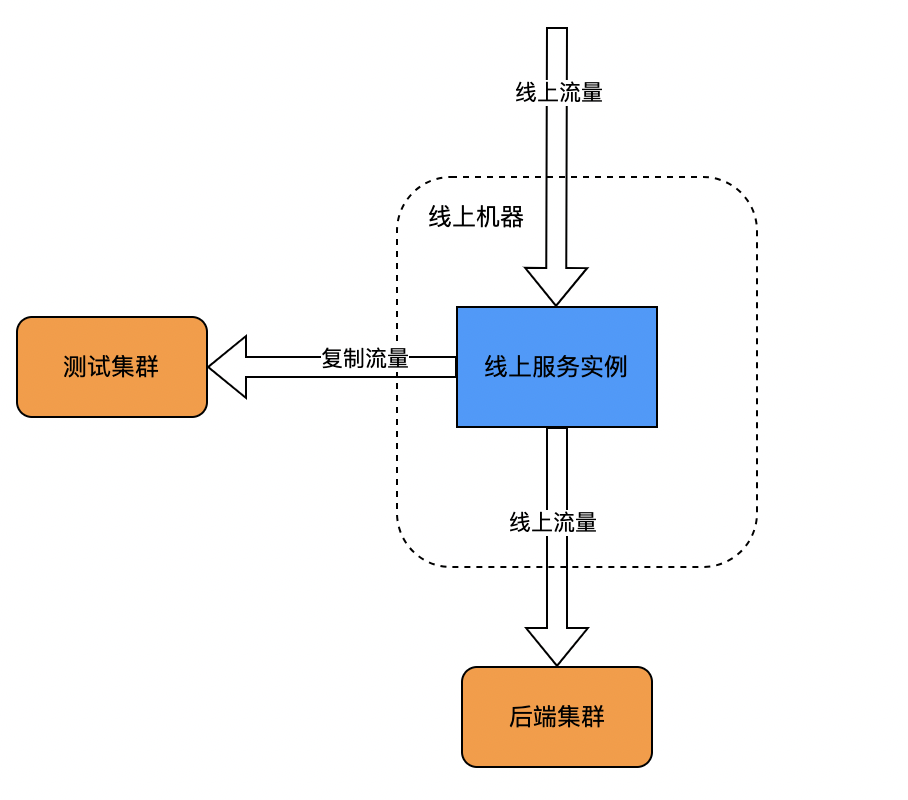
主路复制指的是在调用链中进行流量拷贝。一种是在业务逻辑中进行流量复制,比如在调用API的过程中,由业务方编写代码逻辑记录请求/响应信息内容;另一种是在框架(如阿里的Doom)处理逻辑中进行流量复制。
- 优点: 可以高度结合业务逻辑,实现细粒度定制化流量复制,比如可以只针对某些特征的流量进行复制
- 缺点: 业务逻辑与引流逻辑耦合度较高,功能上相互影响;每个请求都需要进行额外引流处理,对业务流程存在性能影响
旁路复制
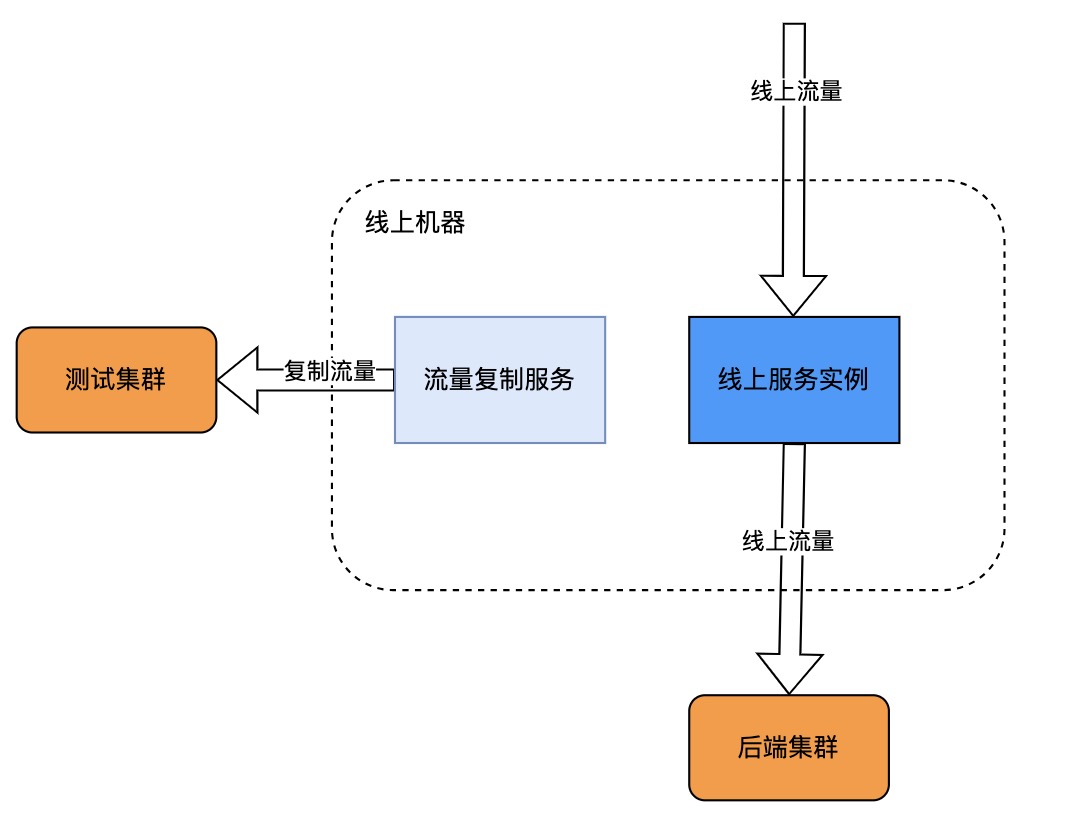
旁路复制一般是由第三方服务在网络协议栈中,监听复制流量,对业务无感。比如TCPCopy,相似的工具还有GoReplay等
- 优点: 与业务解耦,可以独立部署升级引流模块,业务方需关注引流功能实现
- 缺点: 4层网卡层面的网络包抓取后,仍需要进行数据包重组和解析,需要额外的消耗计算资源,往往需要全量抓包解析再进行筛选,无法结合业务逻辑进行定制化的采样
基于网关的业务特点:1) 流量大,无差别的抓包、解包筛选会消耗大量CPU,2) 承接所有产品线的流量,需要提供特定产品线的流量复制能力
特别注意:流量复制是在线上服务上进行的,因此会消耗线上机器的CPU资源,为了不对线上业务带来影响,需要在流量复制时监控线上机器的资源使用,一旦资源消耗太多时需要立即停止流量复制
日志回放
日志回放有点类似旁路复制,但是不再监听网络协议请求,而是在线上服务实例放一个log agent,通过它来将日志转存到大数据分布式集群当中
使用日志回放的前提是,业务代码逻辑当中需要打印的日志,需要包括接口的请求参数,URL,Body,请求方式等必要的接口信息,如果没有打印接口信息的日志,则无法进行日志回放
所以要采取这种回放方式,第一步就是需要开发去协助规范日志
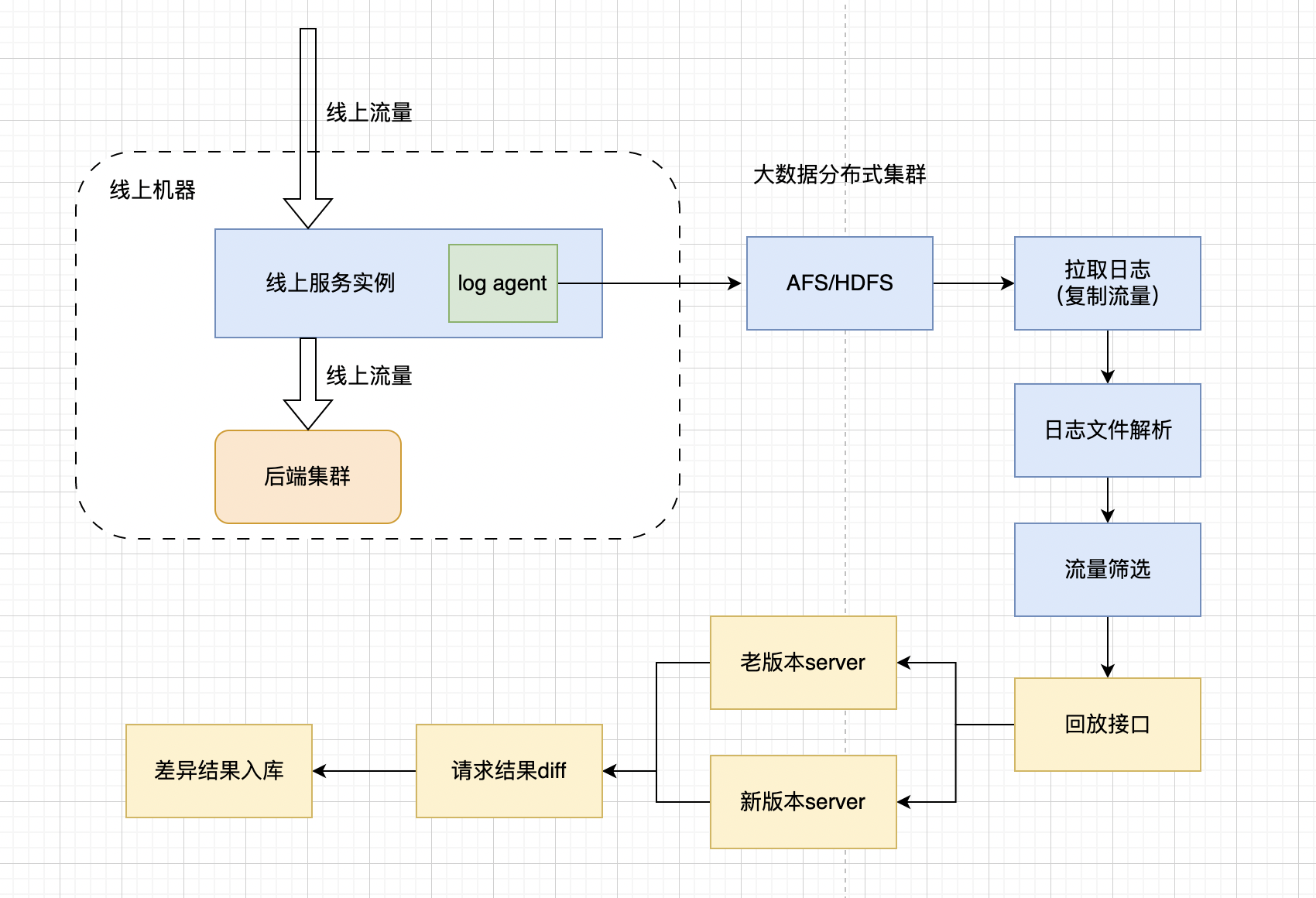
在HDFS/AFS集群当中存放日志以后,就能部署一个hadoop client 用来拉取集群上的日志,并对日志进行处理,解析出接口请求信息,有必要时需要对流量进行筛选后,再进行回放
下面分享一个使用Python多进程,解析日志获取流量的demo程序
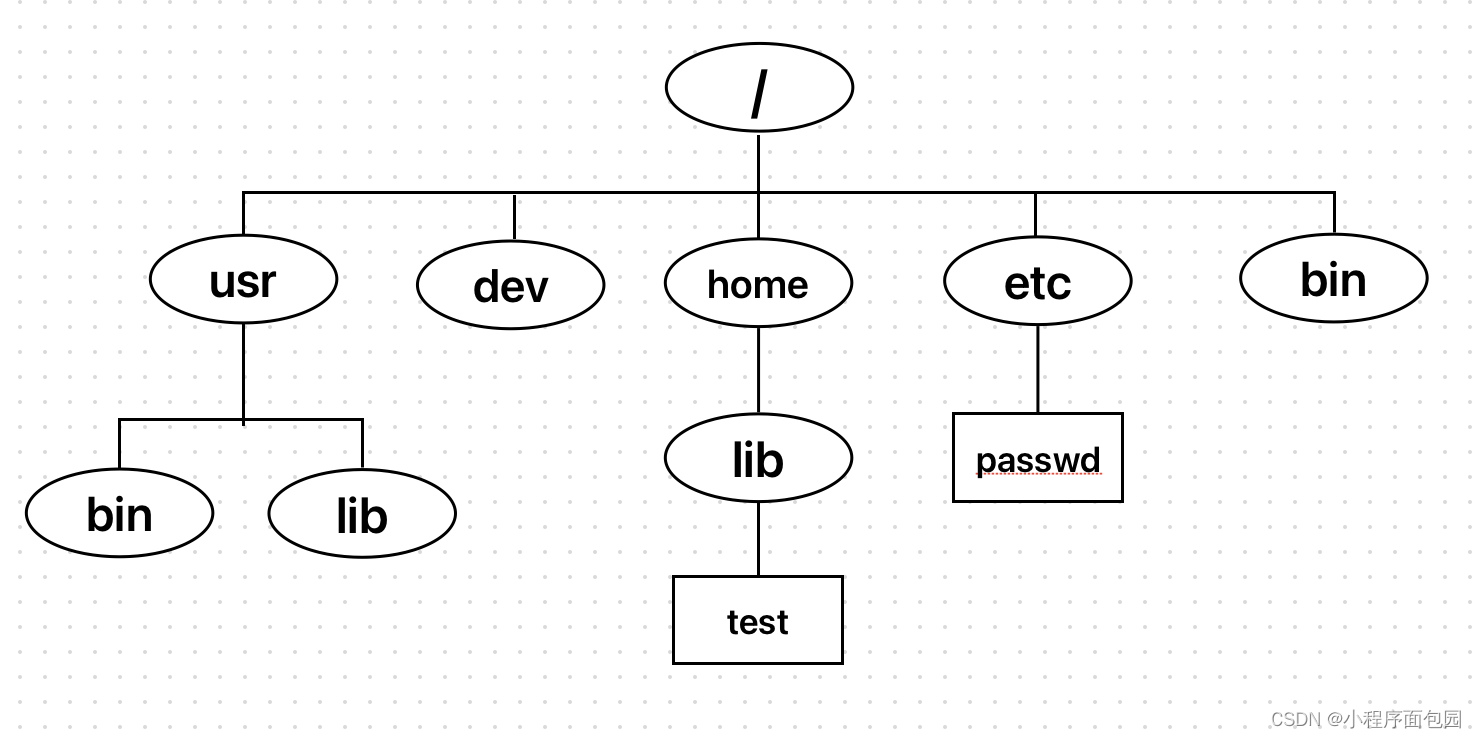
假设现在已经从集群上拉下了日志,日志目录结构如下:
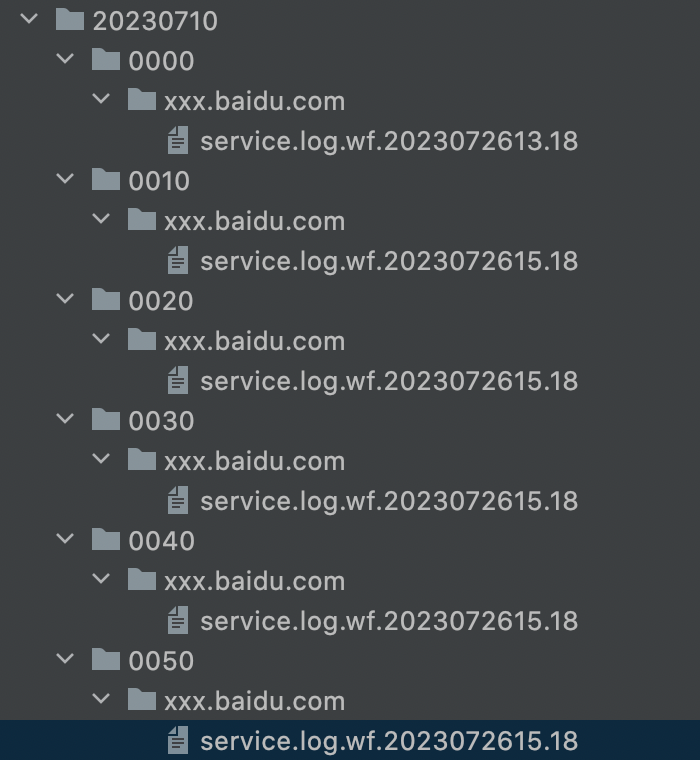
每一条日志文件service.log.wf.2023072615.18里面的内容为:一行接着一行的warning日志,部分warning日志带有接口信息
WARNING 24762924 20230726 13:00:24 Present.php:44 qa_traffic_playback: {"request_method":"POST","service_method":"getUserInfo","path":"\/service\/test?ngscfr=getUserInfo_10.221.110.27_fm_smallapp&method=getUserInfo&format=php&ie=utf-8","query":{"ngscfr":"getUserInfo_10.221.110.27_fm_smallapp","method":"getUserInfo","format":"php","ie":"utf-8"},"post":{"account_id":"59","account_type":"1","user_id":"123456","method":"getUserInfo","format":"php","ie":"utf-8","service_array_key":"a:0:{}","tb_sig":"7f2fcc8b398ca16979"}}
WARNING 24762924 20230726 13:00:24 Present.php:44 qa_traffic_playback: {"request_method":"POST","service_method":"getUserInfo","path":"\/service\/test?ngscfr=getUserInfo_10.221.110.27_fm_smallapp&method=getUserInfo&format=php&ie=utf-8","query":{"ngscfr":"getUserInfo_10.221.110.27_fm_smallapp","method":"getUserInfo","format":"php","ie":"utf-8"},"post":{"account_id":"59","account_type":"1","user_id":"56789","method":"getUserInfo","format":"php","ie":"utf-8","service_array_key":"a:0:{}","tb_sig":"7f2fcc8b398ca16979"}}
import os
import re
import json
import multiprocessingdef parse_log_file(log_file):log_entries = []with open(log_file, 'r') as file:for line in file:if '{"request_method"' in line:# 使用正则表达式匹配 JSON 字典pattern = re.compile(r'{.*?}}')match = pattern.search(line)if match:json_dict = match.group()print("json_dict",json_dict)# 解析 JSON 字典data = json.loads(json_dict)print("data",data)print("解析 JSON 字典",json_dict)return log_entriesdef process_directory(directory, results_dict):log_files = []for root, dirs, files in os.walk(directory):for file in files:if file.startswith('service_present.log.wf'):log_file = os.path.join(root, file)log_files.append(log_file)# 在这里处理每个匹配到的日志文件print("log_files B", log_file)parsed_entries=[]for log_file in log_files:parsed_entries += parse_log_file(log_file)results_dict[directory] = parsed_entriesif __name__ == '__main__':root_directory = '/home/work/' # 指定根目录results = multiprocessing.Manager().dict()processes = []for subdir in os.listdir(root_directory):directory = os.path.join(root_directory, subdir)if os.path.isdir(directory):process = multiprocessing.Process(target=process_directory, args=(directory, results))processes.append(process)process.start()for process in processes:process.join()for directory, entries in results.items():print(f'Directory: {directory}')for entry in entries:print(entry)解释一下这个程序,process_directory方法用来遍历日志目录,获取日志文件的绝对路径,parse_log_file方法用来解析日志文件,利用正则表达式提取出日志里面含接口信息的Json字符串,并转化为字典存放,这段代码片段还有可以优化的地方,因为存在在字典非常占用内容,如果接口信息过多,可能会出现内存占用过高的情况,这时候可以选择将接口信息存入数据库或者Redis
最后再提一嘴,在实际应用过程当中,我们可能还要利用算法进行流量筛选,经过初筛和精筛拿到指定的流量,另外还需要统计回放下来的流量覆盖率,这样才能比较准确的衡量流量的覆盖程度