读程序员的制胜技笔记04_有用的反模式(下)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/181410.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

手动制作Docker容器镜像
文章目录 手动制作Docker容器镜像说明前期准备制作镜像1.启动一个centos系统的容器2.在centos容器中源码安装httpd服务3.基于已经安装好httpd服务的centos容器制作一个httpd镜像4.验证制作出来的镜像的功能5.上传至自己的docker镜像仓库(可选) 手动制作D…
JVM字节码文件浅谈
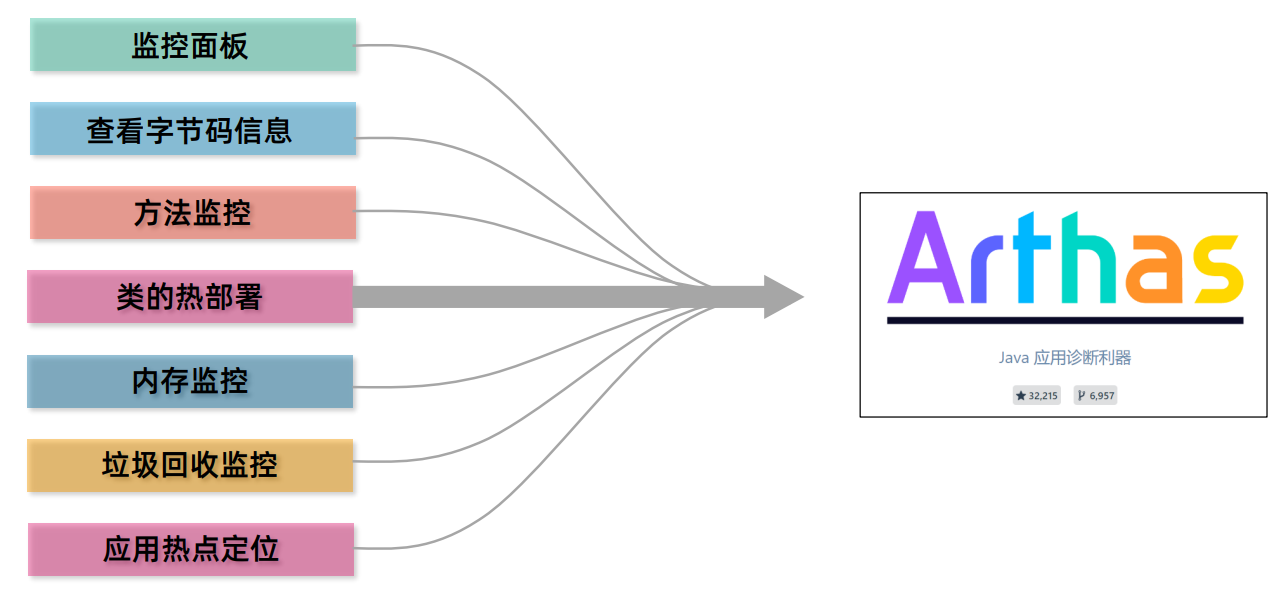
文章目录 版权声明java虚拟机的组成字节码文件打开字节码文件的姿势字节码文件的组成魔数(基本信息)主副版本号(基本信息)主版本号不兼容的错误解决方法基本信息常量池方法 字节码文件的常用工具javap -v命令jclasslib插件阿里art…

外卖系统的运转:背后的技术和管理细节
外卖系统的运作涉及许多技术和管理方面,其中包括前端应用程序、后端服务器、数据库管理、订单处理和配送等环节。
技术细节:
前端应用程序: 外卖平台的用户界面,包括顾客点餐界面和餐厅端的接单界面。通常使用HTML、CSS和JavaS…
C++: 类和对象(中)
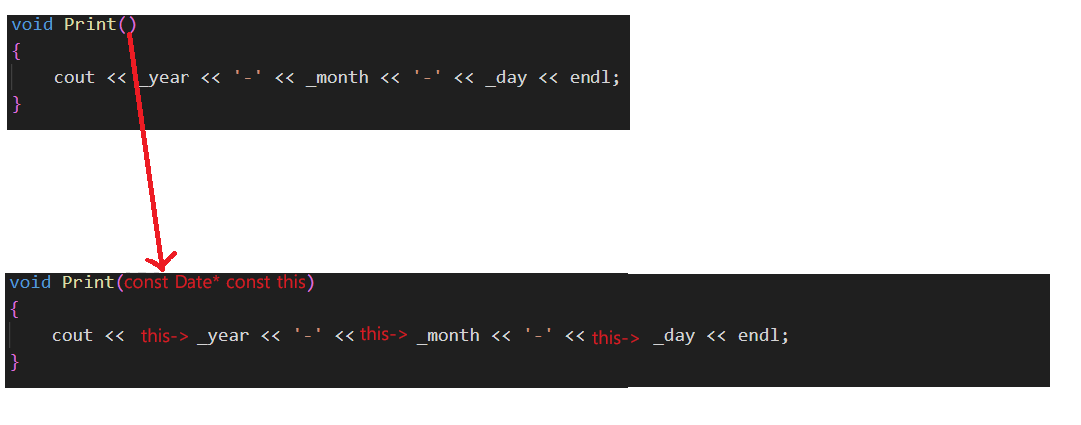
文章目录 1. 类的6个默认成员函数2. 构造函数构造函数概念构造函数特性特性1,2,3,4特性5特性6特性7 3. 析构函数析构函数概念析构函数特性特性1,2,3,4特性5特性6 4. 拷贝构造函数拷贝构造函数概念拷贝构造函数特性特性1,2特性3特性4特性5 5. 运算符重载一般运算符重载赋值运算符…

Instant-NGP论文笔记
文章目录 论文笔记 论文笔记 instant-ngp的nerf模型与vanilla nerf的模型架构相同。
instant-ngp的nerf模型包含两个MLP,第一个MLP就两个全连接,输入维度是32(16层分辨率x2),输出是16(用于预测密度&#x…

高防CDN:游戏应用抵御DDoS攻击的坚固堡垒
在当今的数字时代,游戏应用已经成为人们生活的一部分,而面临的网络威胁也日益复杂。其中,DDoS(分布式拒绝服务)攻击是游戏应用的一项严重威胁,可能导致游戏服务不可用,用户流失,以及…

Oracle安全基线检查
一、账户安全
1、禁止SYSDBA用户远程连接
用户具备数据库超级管理员(SYSDBA)权限的用户远程管理登录SYSDBA用户只能本地登录,不能远程。REMOTE_LOGIN_PASSWORDFILE函数的Value值为NONE。这意味着禁止共享口令文件,只能通过操作系统认证登录Oracle数据库。
1)检查REMOTE…
MASK-RCNN tensorflow环境搭建
此教程默认你已经安装了Anaconda,且tensorflow 为cpu版本。为什么不用gpu版本,原因下面解释。
此教程默认你已经安装了Anaconda。
因为tensorflow2.1后的gpu版,不支持windows。并且只有高版本的tensorflow才对应我的CUDA12.2; 而…
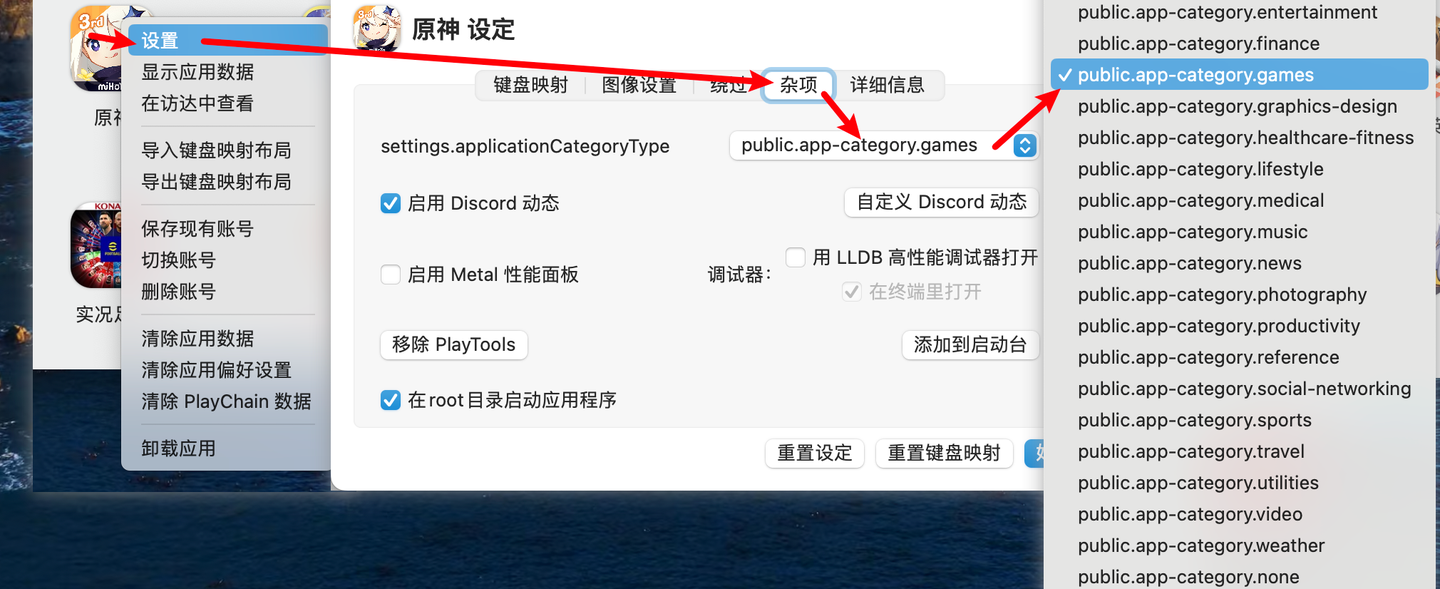
升级 MacOS 系统后,playCover 内游戏打不开了如何解决
我们有些小伙伴在升级了 macOS 系统后大概率会遇到之前能够正常使用的 playCover 突然游戏打不开了,最近 mac 刚刚正式推出了 MacOS 14.1 ,导致很多用户打开游戏会闪退,我们其实只需要更新一下 playCover 就可以解决
playCover 正式版更新会比较慢所以我…
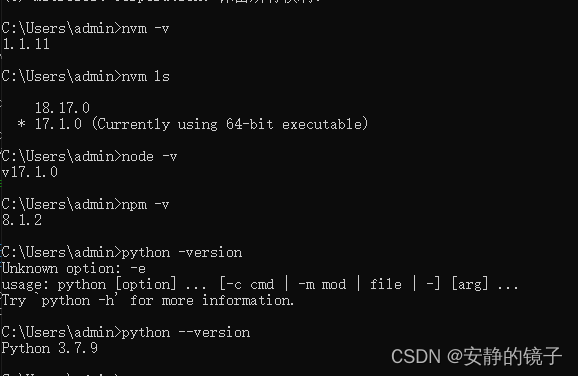
vue-admin-template 安装遇到的问题
vue-element-admin 是一个后台前端解决方案,它基于 vue 和 element-ui实现。 参考文档:
官网:
https://panjiachen.github.io/vue-element-admin-site/zh/guide/#%E5%8A%9F%E8%83%BD遇到的问题:
npm ERR! Error while executing…
最新Ai系统ChatGPT程序源码+以图生图+Dall-E2绘画+支持GPT4+Midjourney绘画
一、AI创作系统
SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如…

APP攻防--ADB基础
进入app包
先使用 adb devices查看链接状态 手机连接成功的 adb shell 获取到手机的一个shell 此时想进入app包时没有权限的,APP包一般在data/data/下。没有执行权限,如图 Permission denied 权限被拒绝 此时需要手机root,root后输入 su …

旅游业为什么要选择VR全景,VR全景在景区旅游上有哪些应用
引言:
VR全景技术的引入为旅游业带来了一场变革。这项先进技术不仅提供了前所未有的互动体验,还为景区旅游文化注入了新的生机。 一.VR全景技术:革新旅游体验
1.什么是VR全景技术?
VR全景技术是一种虚拟现实技术&am…

合肥中科深谷嵌入式项目实战——人工智能与机械臂(六)
订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000 python项目实战 Python编程基础教程系列(零基础小白搬砖逆袭) 说明:本专栏持续更新中,订阅本专栏前必读关于专栏〖Python网络爬虫实战〗转为付费专栏的订阅说明作者࿱…

【ES专题】ElasticSearch集群架构剖析
目录 前言阅读对象阅读导航前置知识笔记正文一、ES集群架构1.1 为什么要使用ES集群架构1.2 ES集群核心概念1.2.1 节点1.2.1.1 Master Node主节点的功能1.2.1.2 Data Node数据节点的功能1.2.1.3 Master Node主节点选举流程 1.2.2 分片1.3 搭建三节点ES集群1.3.1 ES集群搭建步骤1…
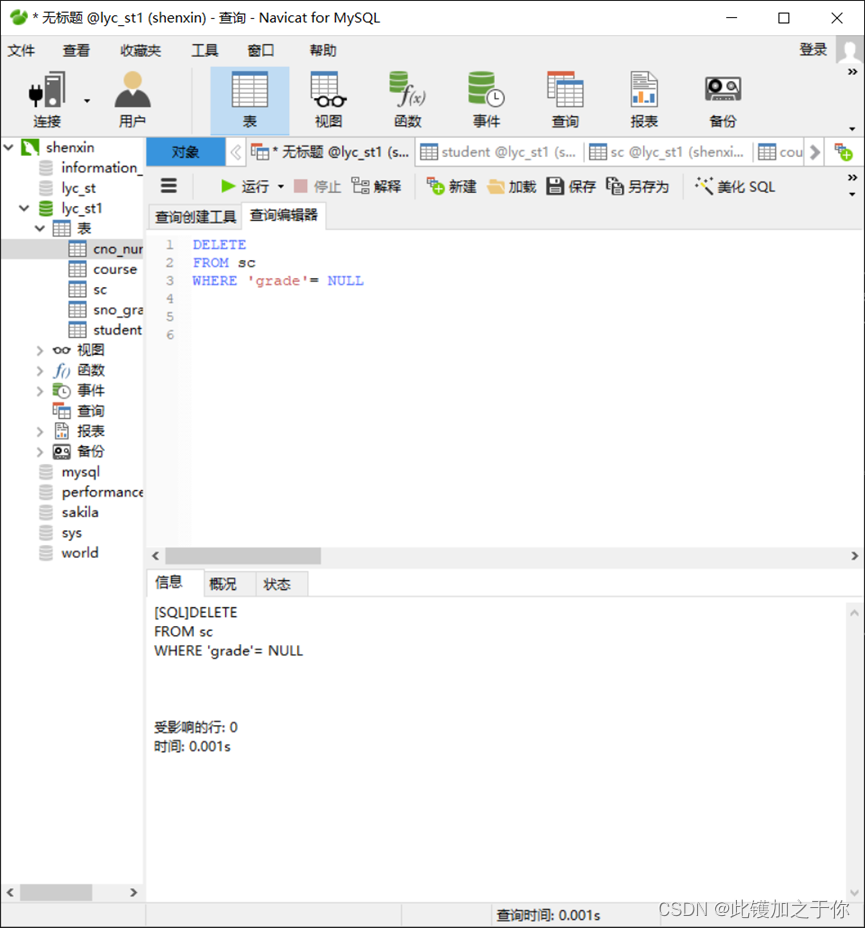
数据库实验:SQL的数据更新
目录 实验目的实验内容实验要求实验步骤实验过程总结 再次书接上文,sql基础的增删改查 实验目的
(1) 掌握DBMS的数据查询功能 (2) 掌握SQL语言的数据更新功能
实验内容
(1) update 语句用于对表进行更新 (2) delete 语句用于对表进行删除 (3) insert 语句用于对表…
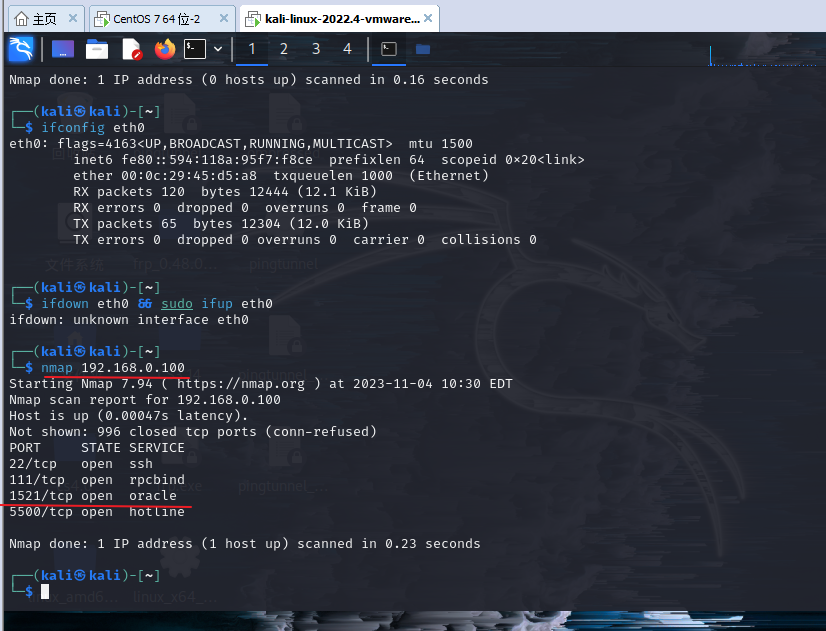
MSF暴力破解SID和检测Oracle漏洞
暴力破解SID 当我们发现 Oracle 数据库的 1521 端口时,我们可能考虑使用爆破 SID(System Identifier)来进行进一步的探测和认证。在 Oracle 中,SID 是一个数据库的唯一标识符。当用户希望远程连接 Oracle 数据库时,需要了解以下几个要素:SID、用户名、密码以及服务器的 I…
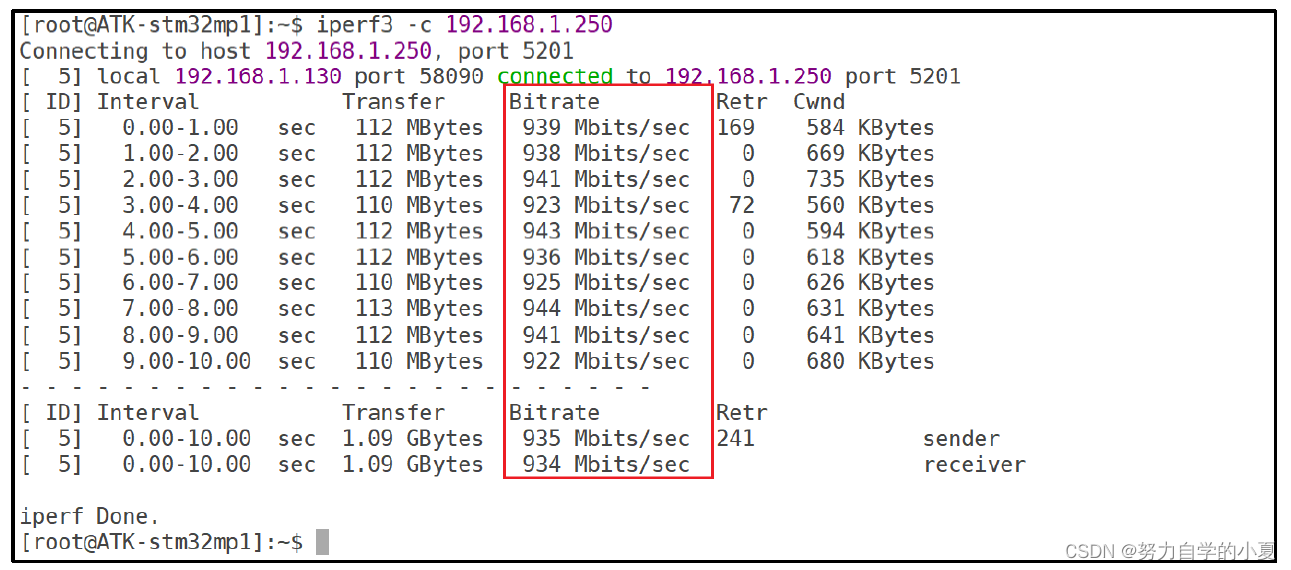
正点原子嵌入式linux驱动开发——Linux 网络设备驱动
网络驱动是linux里面驱动三巨头之一,linux下的网络功能非常强大,嵌入式linux中也常常用到网络功能。前面已经讲过了字符设备驱动和块设备驱动,本章就来学习一下linux里面的网络设备驱动。
嵌入式网络简介
嵌入式下的网络硬件接口
本次笔记…

分享一次无线话筒和接收机的配对经历BK9521/9522
最近老婆喜欢上了唱歌。我就需要为她准备歌曲和设备。装了台点歌机,买了软件,用4天的时间下了4T容量的歌曲,听过的没听过的都在里面,真的是太多了。
有了歌曲,就要有唱歌设备了。当我准备买无线话筒的时候,…
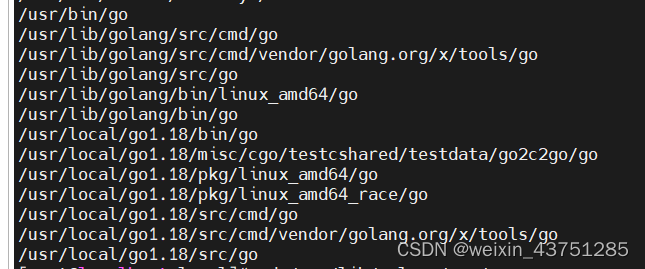
centos7中多版本go安装
安装go的方式
官网下载tar.gz包安装
# 1.下载tar包
wget https://go.dev/dl/go1.18.1.linux-amd64.tar.gz
# 2.解压tar包到指定路径
tar -xvf go1.18.1.linux-amd64.tar.gz -C /usr/local/go1.18
# 3.配置环境变量,打开 /etc/profile 文件添加以下文件每次开机时…
推荐文章
- 旅行季《乡村振兴战略下传统村落文化旅游设计》许少辉八一著作想象和世界一样宽广
- 央视新闻曝光TR外汇平台诈骗案,涉案金额高达5亿元
- 银发经济:老龄化社会中的机遇与挑战
- # 从浅入深 学习 SpringCloud 微服务架构(四)Ribbon
- (10)(10.8) 固件下载
- (13)香橙派+apache2与php+天猫精灵=自建平台语音支持--duerOS对接
- (15)衰落信道模型作用于信号是相乘还是卷积
- (9月10日)最新植物大战僵尸杂交版【v2.4.0版本已更新】
- (Git)git clone报错——SSL certificate problem: self signed certificate
- (UDP)其他信息: 通常每个套接字地址(协议/网络地址/端口)只允许使用一次。
- (超经典)老妈如此验证儿子是否跟女友上过床
- (超全)Kubernetes 的核心组件解析