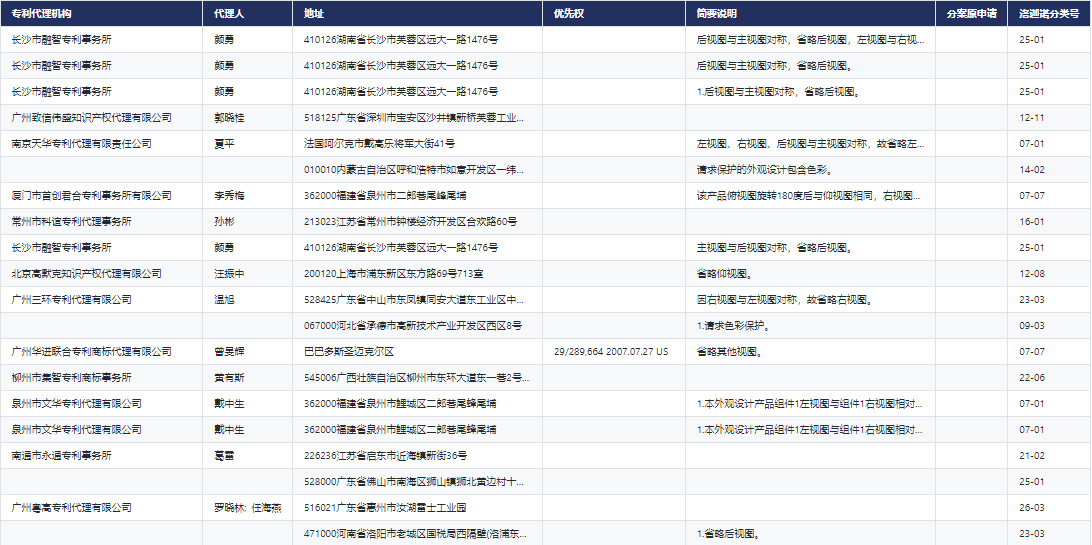
彩票原理系列文章
彩票与数学——彩票预测是玄学还是数学?![]() https://mp.csdn.net/mp_blog/creation/editor/122517043彩票与数学——常用彩票术语的统计学解释
https://mp.csdn.net/mp_blog/creation/editor/122517043彩票与数学——常用彩票术语的统计学解释![]() https://mp.csdn.net/mp_blog/creation/editor/122474853彩票与数学——彩票缩水的数学概念与原理
https://mp.csdn.net/mp_blog/creation/editor/122474853彩票与数学——彩票缩水的数学概念与原理![]() https://mp.csdn.net/mp_blog/creation/editor/123676954
https://mp.csdn.net/mp_blog/creation/editor/123676954
一、彩票预测科学吗?
因为彩票号码的随机性,一般人都觉得彩票预测是玄学,不切合实际,研究与预测彩票纯属浪费时间。
你或许也这么认为。质疑之前,需要确定你是否学习过《概率统计》这门课。
概率统计的基础数据是一定数量、有约束的随机数(集)。
概率统计的应用过程,常常有这样的情形:
(1)针对既有的数据集,计算相应的概率数据,建立非精确的模型;
(2)出现新的数据,则判断其是否符合原有模型的约束;比如:某人(脸)的校验点,与原有数据集中哪个脸的契合度最高,只要达到某个阈值,就可以大概确定是某人,这就是人脸识别。至于阈值多少合适呢?怎么定的?训练,然后差不多就行了。
(3)当然也可以用于预测下一个数据在哪个范围内出现,其概率是多少。
如果基础数据非常多的时候,就有了新名词:训练集。现在没有百亿,都不好意思叫训练集了。
《概率统计》稍微出现花样,就是深度学习了,还有了皇帝的新装“AI”。
哦!扯远了。回来说彩票。
二、彩票数据统计学
(现在所谓的“学说”越来越多,不妨将来设置一个这样的学问。)
彩票的随机数据集,就是已经开出的若干期彩票号码。比如双色球的1000多期。
彩票的预测,主要是这样一些核心思想(数学的哈!):
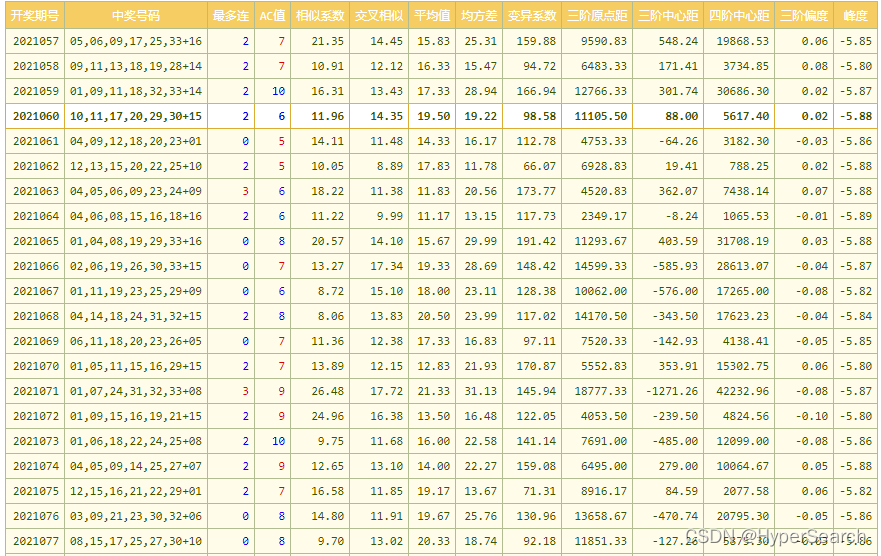
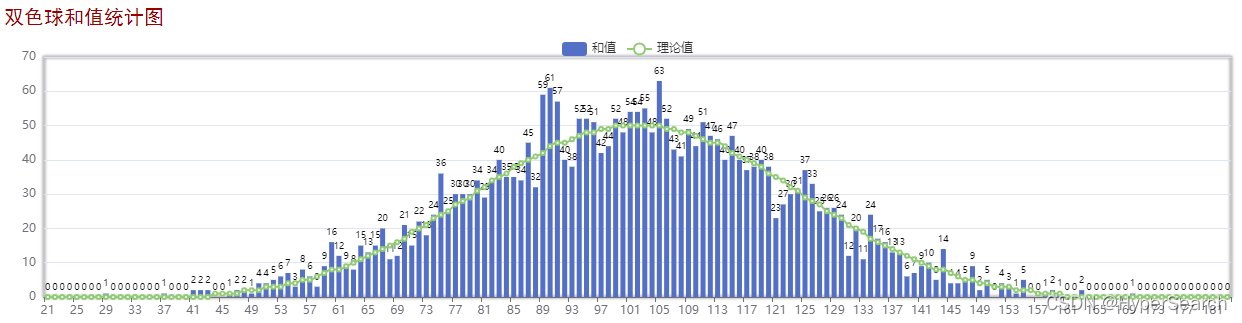
(1)统计:首先需要对数据集进行计算,包括和值、均值、标准差、均方差、跨度(最大号-最小号)、奇偶比(奇数个数比偶数个数,后面类似)、大小比、质合比(质数与合数的比。有个数学问题:1是质数?或是合数?)等等,一般的彩票网站都可以提供几十种统计数据。这个都是数学哈!
(2)价值:统计数据一般都以正态分布或近似正态分布(因为峰度、偏度可能不同)。
(3)算法:彩票预测的核心算法就是选定的一注彩票号码,是否符合一项或多项统计数据的置信区间约束。这里面有两个核心问题,一是用几个统计数据作为约束,二是设定怎样的置信区间。约束越多,置信区间越小,号码符合要求的可能性就越低。
(4)应用:以双色球(33选6+16选1)为例,全部号码的组合是17,721,088注。理论上,用很多的统计数据作为约束,尽量小的置信区间,可以将下期号码限制到较小的一个范围。哈哈!你是不是看到的发财的机会?
(5)冷水:当然,这存在巨大的问题。首先,号码不听话,不会完全按理论概率来出现。其次,如果限制太多,置信区间太小,可能恰恰把中奖号码给去掉了。比如,双色球可以有30-40个统计数据,完全符合这么多数据的一般置信区间(比如总量占62%的分布)也是很少的。
(6)希望:那是不是预测就没有价值呢?当然不是,否则就没有必要写本文了。
三、科学的彩票预测
科学的彩票预测应该这样:
(1)看看走势图,选择3-5个统计数据作为约束;
(2)看看统计数据,大致确定这些统计数据的置信区间(可以稍微大一点);
(3)选定一些特定的约束条件,这个全凭个人感受与运气。比如:特定号码(必出号码或者必定不会出现的号码)、特定和值,特定号码类型,特定的方差等等。注意了:特定约束的选择也要适量,不是越多越好。
(4)剩下的就是一个简单的程序而言。

彩票预测和人工智能有异曲同工之妙,无非就是统计+置信。
大家看到了,彩票预测必须有你(人)的参与。
而目前的所谓人工智能,离开了“人”的因素,真正的突破极为有限,越来越难(死路一条)。
目前,99%与AI相关的时间与资金都在白费。
当今世界真正懂人工智能的人还没有熊猫多。