1.namespace技术
namespace是Linux内核的一组特性,支持对内核资源进行分区隔离,让一组进程只能看到一组资源,而另一组进程只能看到另一组不同的资源。换句话说,namespace的关键特性是进程隔离。在运行许多不同服务的服务器上,将各个服务及其相关进程相互隔离能够减少系统环境变更带来的影响,以及避免系统安全性方面的问题。
namespace技术是实现容器的核心技术。容器提供了一个独立的环境,看起来就像一个完整的虚拟机,但它不是虚拟机,而是正在运行的一组进程。如果启动了两个容器,那么将有两组进程运行,但两者之间是相互隔离的,namespace技术实现了进程隔离。在同一个namespace下的一组进程之间可以感知彼此的变化,而对外界的进程一无所知。这样就可以让容器中的进程产生错觉,认为自己置身于一个独立的系统中,从而达到进程隔离的目的。
Linux namespace是对全局系统资源的一种封装隔离,使得处于不同namespace的进程拥有独立的全局系统资源,改变一个namespace中的系统资源只会影响当前namespace中的进程,对其他namespace中的进程没有影响。
namespace需要对不同类型的系统资源进行隔离,在介绍具体的每种namespace类型之前,先介绍以下3个与其相关的系统调用。
(1)clone系统调用可以为创建的子进程创建新的namespace,创建时传入的flags参数可以指明namespace类型。
(2)unshare系统调用为当前进程创建新的namespace,其flags参数可以指明namespace 类型。
(3)setns系统调用把某个进程放在已有的某个namespace中。
clone和unshare的功能都是创建并加入新的namespace。它们的区别是,unshare使当前进程加入新的namespace;clone创建一个新的子进程,然后让子进程加入新的namespace,而当前进程保持不变。
Linux namespace的整个创建过程如图11-3所示,clone和fork在内核中的处理过程都是调用_do_fork函数,图中用户态以常见的32位x86下的fork系统调用为例来说明系统调用的触发方式。
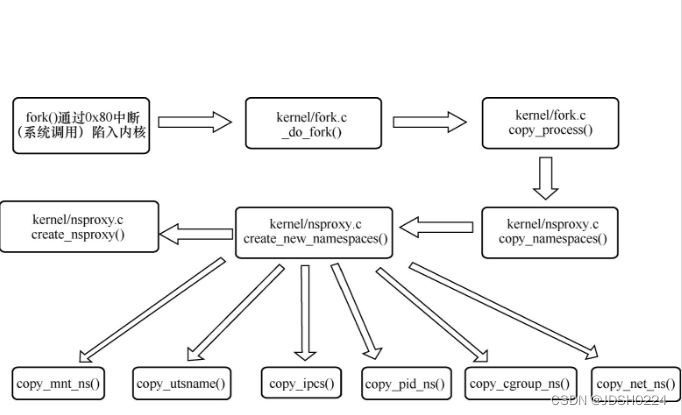
图11-3 Linux namespace的整个创建过程示意图
Linux 内核包含了不同类型的namespace。每个namespace 都有自己的独特属性。namespace 的类型如表11-1所示。
表11-1 namespace 的类型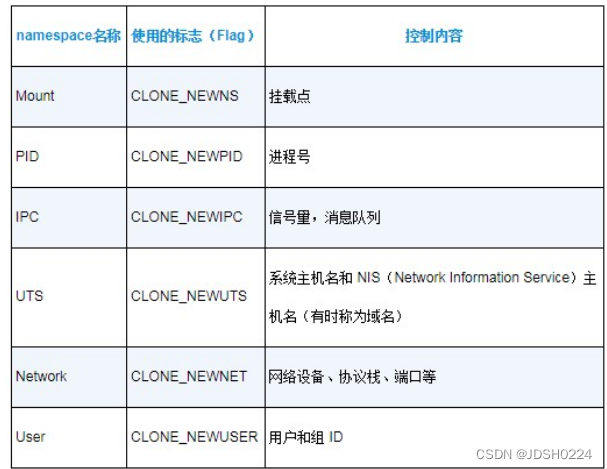
2. Mount namespace
Mount namespace与chroot技术相似,其隔离了进程的文件系统访问范围,不同Mount namespace下的进程会有不同的目录层次结构。在/proc/[pid]/mounts、/proc/[pid]/mountinfo 和 /proc/[pid]/mountstats中可以查看进程的挂载点信息。
使用clone或者unshare系统调用创建一个新的Mount namespace需要添加标志CLONE_NEWNS。如果Mount namespace用clone系统调用创建,子namespace的挂载列表是从父进程的Mount namespace复制而来。
下面用一个简单的实例演示Mount namespace。
$ sudo unshare --mount --fork /bin/bash
# mkdir temp
# mount -t tmpfs tmpfs-name ./temp
# df
Filesystem Size Used Avail Use% Mounted on
...
tmpfs-name 97G 81G 17G 83% /home/mengning/temp
首先使用unshare命令创建一个bash进程并且新建一个Mount namespace,这里的unshare命令中,--mount参数指新建一个Mount namespace,--fork参数指fork一个子进程,/bin/bash参数指运行的可执行程序。这样就可以在新建的Mount namespace隔离环境中执行/bin/bash,此命令行已经是在隔离的环境下运行了。
然后在隔离的Mount namespace环境下创建temp目录,并将一个tmpfs类型的文件系统取名为tmpfs-name,挂载到/home/mengning/temp目录下。
通过df命令可以看到tmpfs-name文件系统已经被正确挂载。为了验证主机上并没有挂载此目录,新打开一个命令行窗口,同样执行df命令查看主机的挂载信息,可以看到主机上并没有挂载tmpfs-name文件系统,可见在独立的Mount namespace中执行mount操作并不会影响系统的mount树。
下面介绍Mount namespace的实现原理与相关数据结构,每个Mount namespace都由一个struct mnt_namespace结构体来管理,Linux-5.4.34内核的struct mnt_namespace结构体如下,具体参见fs/mount.h文件。
struct mnt_namespace {atomic_t count;struct ns_common ns;struct mount * root; // 根目录挂载点struct list_head list; // 所有的Mount namespace链表struct user_namespace *user_ns;struct ucounts *ucounts;u64 seq; /* Sequence number to prevent loops */wait_queue_head_t poll;u64 event;unsigned int mounts; /* # of mounts in the namespace */unsigned int pending_mounts;
} __randomize_layout;
每个struct mnt_namespace有自己独立的struct mount *root,即根挂载点是互相独立的。struct mount结构体如下,具体参见fs/mount.h。
struct mount {struct hlist_node mnt_hash;struct mount *mnt_parent;struct dentry *mnt_mountpoint;struct vfsmount mnt;union {struct rcu_head mnt_rcu;struct llist_node mnt_llist;};
#ifdef CONFIG_SMPstruct mnt_pcp __percpu *mnt_pcp;
#elseint mnt_count;int mnt_writers;
#endifstruct list_head mnt_mounts; /* list of children, anchored here */struct list_head mnt_child; /* and going through their mnt_child */struct list_head mnt_instance; /* mount instance on sb->s_mounts */const char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */struct list_head mnt_list;struct list_head mnt_expire; /* link in fs-specific expiry list */struct list_head mnt_share; /* circular list of shared mounts */struct list_head mnt_slave_list;/* list of slave mounts */struct list_head mnt_slave; /* slave list entry */struct mount *mnt_master; /* slave is on master->mnt_slave_list */struct mnt_namespace *mnt_ns; /* containing namespace */struct mountpoint *mnt_mp; /* where is it mounted */union {struct hlist_node mnt_mp_list;/* list mounts with the same mountpoint */struct hlist_node mnt_umount;};struct list_head mnt_umounting; /* list entry for umount propagation */
#ifdef CONFIG_FSNOTIFYstruct fsnotify_mark_connector __rcu *mnt_fsnotify_marks;__u32 mnt_fsnotify_mask;
#endifint mnt_id; /* mount identifier */int mnt_group_id; /* peer group identifier */int mnt_expiry_mark; /* true if marked for expiry */struct hlist_head mnt_pins;struct hlist_head mnt_stuck_children;
} __randomize_layout;
struct mount结构体中维护了子mnt链表,这样每个struct mnt_namespace实例都维护着彼此独立的mnt链表,产生的外在效果就是在某个Mount namespace中执行mount和umount命令不会对其他namespace产生影响,因为整个mount树是每个namespace各有一份,彼此间互不干扰。
从根目录的路径查找(path lookup)也在各自的mount树中进行。这里和chroot系统调用的做法是不一样的,此系统调用改变的只是进程描述符struct task_struct相关的struct fs_struct中的root,影响的是路径查找的起始点,而每个Mount namespace独立拥有整个mount树。
3.PID namespace
PID namespace,也可以称为Process namespace。
在Linux系统中,每个进程都有自己独立的PID,而PID namespace主要是用于隔离不同的进程。即在不同的PID namespace中可以有相同的进程号。每个PID namespace中进程号都是从1开始的,在同一PID namespace中通过调用fork、vfork和clone等系统调用创建的进程拥有独立的进程号。
要使用PID namespace需要Linux内核支持CONFIG_PID_NS选项。如下命令可查看当前系统的Linux内核是否支持PID namespace。
$ grep CONFIG_PID_NS /boot/config-$(uname -r)
CONFIG_PID_NS=y
在Linux系统中有一个进程比较特殊,就是init进程,也就是PID为1的进程。每个PID namespace中进程号都是从1开始的,而且PID namespace中的1号进程是同一namespace下所有其他进程的父进程或祖先进程。如果这个进程被终止,Linux内核将调用SIGKILL发出终止此namespace中所有进程的信号。
下面来简单验证一下PID namespace的隔离效果。如下unshare命令中--mount-proc表示创建PID namespace时重新挂载procfs。
$ sudo unshare --pid --fork --mount-proc /bin/bash
# psPID TTY TIME CMD1 tty1 00:00:00 bash
9 tty1 00:00:00 ps
通过ps命令查看当前PID namespace中的进程列表,发现PID为1的进程为当前bash命令行。
PID namespace支持嵌套,除了初始的PID namespace,其余的PID namespace都拥有其父节点的PID namespace。也就是说,PID namespace也是树形结构的,此结构内的所有PID namespace都可以追踪到祖先PID namespace。当然,这个深度也不是无限的,从Linux3.7内核版本开始,树的最大深度被限制成32。如果达到此最大深度,将会抛出No space left on device的错误。
在同一个PID namespace中,同级进程间彼此可见。但如果某个进程位于子PID namespace,那么该进程是看不到上一层(即父PID namespace)中的进程的。进程间是否可见,决定了进程间能否存在一定的关联和调用关系。
引入PID namespace后,要获取一个指定的进程,除了指明PID,还必须指明PID namespace,这主要通过pid_namespace结构体实现。
struct pid_namespace {struct kref kref; // 引用计数struct pidmap pidmap[PIDMAP_ENTRIES]; // pid分配的bitmap,为1表示已分配int last_pid; // 记录上次分配的pid,默认当前分配的pid=last_pid+1struct task_struct *child_reaper;// 父进程结束后,需要该child_reaper进程对其托管struct kmem_cache *pid_cachep; // 用于分配pid结构的slab缓存unsigned int level; // 记录该pidns的深度struct pid_namespace *parent; // 父pidns...kgid_t pid_gid;int hide_pid;int reboot; /* group exit code if this pidns was rebooted */
};
4. IPC namespace
Linux的IPC namespace主要针对消息队列(message queue)、信号量(semaphore)、共享内存(share memory),也被称为XSI IPC,源自UNIX System V IPC。
IPC namespace隔离了IPC资源,每个IPC namespace都有自己的一组System V IPC标识符,以及POSIX消息队列系统。在一个IPC namespace中创建的对象,对所有该namespace下的成员均可见,对其他namespace下的成员均不可见。
使用IPC namespace需要内核支持CONFIG_IPC_NS选项。如下命令可查看当前系统的Linux内核是否支持IPC namespace。
$ grep CONFIG_IPC_NS /boot/config-$(uname -r)
CONFIG_IPC_NS=y
可以在IPC namespace中设置/proc/sys/fs/mqueue—— POSIX消息队列接口、/proc/sys/ kernel—— System V IPC接口(msgmax、msgmnb、msgmni、sem、shmall、shmmax、shmmni、shm_rmid_forced)和/proc/sysvipc—— System V IPC接口。
当IPC namespace 被销毁时(即namespace里的最后一个进程都被终止时),在IPC namespace中创建的IPC对象也会被销毁。
通过消息队列的实例来验证IPC namespace的作用,首先使用unshare命令来创建一个IPC namespace。
$ sudo unshare --fork --ipc /bin/bash
下面需要借助两个命令来实现对IPC namespace的验证。
● ipcs -q 命令:用来查看系统消息队列列表。
● ipcmk -Q 命令:用来创建系统消息队列。
下面先使用ipcs -q命令查看当前IPC namespace下的系统消息队列列表。
# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
由上述代码可以看到,当前无任何系统消息队列,然后使用ipcmk -Q命令创建一个系统消息队列。
# ipcmk -Q
Message queue id: 0
再次使用ipcs -q命令查看当前IPC namespace下的系统消息队列列表。
# ipcs -q
------ Message Queues --------
Key msqid owner perms used-bytes messages
0xc1ab30a8 0 root 644 0 0
可以看到已经成功创建了一个系统消息队列。然后新打开一个命令行窗口,使用ipcs -q 命令查看一下主机系统消息队列。
$ sudo ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
通过上面实验可以发现,在单独的IPC namespace内创建的系统消息队列在主机上无法看到,即IPC namespace实现了系统消息队列的隔离。
下面根据Linux内核的源代码对IPC namespace的原理进行分析。
在调用clone、unshare和setns等系统调用时,如果设置了CLONE_NEWIPC标志,则内核会调用copy_ipcs()创建一个新的IPC namespace。其中的核心是创建一个新的struct ipc_namespace结构体,相当于创建了一个新的XSI IPC域。
IPC namespace是一个扁平的结构,在Linux-5.4.34内核的include/linux/ipc_namespace.h文件中定义了ipc_namespace结构体如下。
struct ipc_namespace {
refcount_t count;
struct ipc_ids ids[3];
int sem_ctls[4];
int used_sems;
unsigned int msg_ctlmax;
unsigned int msg_ctlmnb;
unsigned int msg_ctlmni;
atomic_t msg_bytes;
atomic_t msg_hdrs;
size_t shm_ctlmax;
size_t shm_ctlall;
unsigned long shm_tot;
int shm_ctlmni;
/*
* Defines whether IPC_RMID is forced for _all_ shm segments regardless
* of shmctl()
*/
Int shm_rmid_forced;
struct notifier_block ipcns_nb;
/* The kern_mount of the mqueuefs sb. We take a ref on it */
struct vfsmount *mq_mnt;
/* # queues in this ns, protected by mq_lock */
unsigned int mq_queues_count;
/* next fields are set through sysctl */
unsigned int mq_queues_max; /* initialized to DFLT_QUEUESMAX */
unsigned int mq_msg_max; /* initialized to DFLT_MSGMAX */
unsigned int mq_msgsize_max; /* initialized to DFLT_MSGSIZEMAX */
unsigned int mq_msg_default;
unsigned int mq_msgsize_default;
/* user_ns which owns the ipc ns */
struct user_namespace *user_ns;
struct ucounts *ucounts;
struct ns_common ns;
} __randomize_layout;
其中最关键的就是struct ipc_ids ids[3]数组中每一个struct ipc_ids结构体的成员,它们分别描述了一类IPC资源,分别代表信号量、消息队列和共享内存,Linux内核通过如下3个宏分别访问这3个IPC资源,意味着不同的IPC namespace只能访问自己的ipc_ids成员。
#define sem_ids(ns) ((ns)->ids[IPC_SEM_IDS])
#define shm_ids(ns) ((ns)->ids[IPC_SHM_IDS])
#define msg_ids(ns) ((ns)->ids[IPC_MSG_IDS])
以消息队列为例,宏msg_ids(ns)中ns是指struct ipc_namespace结构体的指针,(ns)->ids[IPC_MSG_IDS]是struct ipc_ids结构体数组的消息队列成员。如下代码所示,只能在当前IPC namespace中访问自己的ipc_ids成员及其消息队列,从而做到了隔离不同的IPC namespace之间的消息队列。
static inline struct msg_queue *msq_obtain_object(struct ipc_namespace *ns, int id)
{
struct kern_ipc_perm *ipcp = ipc_obtain_object_idr(&msg_ids(ns), id);
if (IS_ERR(ipcp))
return ERR_CAST(ipcp);
return container_of(ipcp, struct msg_queue, q_perm);
}
11.2.6 UTS namespace
UTS namespace用来隔离系统的主机名和网络域名。这两个资源可以通过sethostname和setdomainname系统调用库函数来设置,以及通过uname、 gethostname和getdomainname系统调用库函数来获取。
术语UTS来自调用函数uname时用到的结构体struct utsname,而这个结构体的名字源自“UNIX Time-sharing System”。
UTS namespace是namespace机制中实现最简单的一个,在unshare或setns命令中会调用sethostname和setdomainname,它们将会修改struct task_struct结构体的struct nsproxy结构体的struct uts_namespace结构体的struct new_utsname name成员,这样容器中访问到的主机名称等就与主机系统不同了。struct uts_namespace结构体和struct new_utsname结构体定义如下。
struct uts_namespace {struct kref kref;struct new_utsname name;struct user_namespace *user_ns;struct ucounts *ucounts;struct ns_common ns;
} __randomize_layout;struct new_utsname {char sysname[__NEW_UTS_LEN + 1];char nodename[__NEW_UTS_LEN + 1];char release[__NEW_UTS_LEN + 1];char version[__NEW_UTS_LEN + 1];char machine[__NEW_UTS_LEN + 1];char domainname[__NEW_UTS_LEN + 1];
};
5. Network namespace
Network namespace隔离了网络相关的系统资源,比如IP地址、网络接口、路由表、防火墙等。一个Network namespace提供了一份独立的网络环境,就跟独立的系统一样。一个物理设备只能存在于一个Network namespace 中,但可以从一个移动到另一个。可以使用来自iproute2安装包的ip netns命令来创建Network namespace,以及管理其下的网络资源。
使用Network namespace需要内核支持CONFIG_NET_NS 选项。使用如下命令查看当前系统是否支持该选项。
$ grep CONFIG_NET_NS /boot/config-$(uname -r)
CONFIG_NET_NS=y
当调用命令ip netns add ns1时,本质上就是带着CLONE_NEWNET标志调用unshare系统调用创建了一个新的Network namespace。
/** A structure to contain pointers to all per-process* namespaces - fs (mount), uts, network, sysvipc, etc.** The pid namespace is an exception -- it's accessed using* task_active_pid_ns. The pid namespace here is the* namespace that children will use.** 'count' is the number of tasks holding a reference.* The count for each namespace, then, will be the number* of nsproxies pointing to it, not the number of tasks.** The nsproxy is shared by tasks which share all namespaces.* As soon as a single namespace is cloned or unshared, the* nsproxy is copied.*/
struct nsproxy {atomic_t count;struct uts_namespace *uts_ns;struct ipc_namespace *ipc_ns;struct mnt_namespace *mnt_ns;struct pid_namespace *pid_ns_for_children;struct net *net_ns;struct cgroup_namespace *cgroup_ns;
};
对内核中Network namespace相关的源代码进行分析可以发现,Network namespace特性的添加,只是将一些原本全局唯一的网络资源变量(例如网络设备列表、路由表等),包裹到了struct net结构体中。因此创建多个struct net结构体,就相当于拥有了多个Network namespace。
6.User namespace
User namespace隔离了用户id和用户组id等。使用User namespace需要内核支持CONFIG_USER_NS选项,使用如下命令可以查看当前系统是否支持该选项。
$ grep CONFIG_USER_NS /boot/config-$(uname -r)
CONFIG_USER_NS=y
进程的用户id和用户组id在一个User namespace内和外有可能是不同的。比如一个进程在User namespace中的用户和用户组可以是特权用户(root),但在该User namespace之外,可能只是一个普通的非特权用户。这就涉及用户和用户组映射(uid_map、gid_map)等相关的内容,自Linux-3.5版本的内核开始,在/proc/[pid]/uid_map和/proc/[pid]/gid_map文件中,可以查看到映射用户和映射用户组。
User namespace也支持嵌套,使用unshare或者clone等系统调用时,使用CLONE_NEWUSER标志来创建User namespace,其最大的嵌套层级深度也是32。如果通过fork或者clone创建子进程时没有带CLONE_NEWUSER标志,那么默认子进程跟父进程在同一个User namespace中。
树形的关联关系可以通过ioctl系统调用接口维护。一个单线程进程可以通过setns系统调用来调整其所属的User namespace。
User namespace是最核心、最复杂的namespace,因为它是用来隔离和分割管理权限的,管理权限实质分为uid/gid和Capability两部分,涉及UGO(User、Group、Other)规则和Capability规则等进程执行时用户拥有的权限。这些将在第12章进一步展开讨论。
7.cgroups技术
cgroups的全称是Linux Control Groups,主要作用是在Linux内核中限制、记录和隔离进程组(process group)使用的物理资源,比如CPU、Memory、I/O等。
2006年,Google的工程师Paul Menage和Rohit Seth等人启动了一个项目,最初的名字叫process containers。因为container这个名字在内核中有歧义,所以后来改名为control groups,在Linux-2.6.24内核版本中发布。
最初cgroups的版本称为v1版,这个版本的cgroups设计得不够好,理解起来非常困难。后续的开发工作由Tejun Heo接管,重新设计并实现了cgroups,被称为v2版,在Linux-4.5内核版本中发布。
cgroups和namespace类似,也是将进程进行分组,但它的目的和namespace不一样,namespace是为了隔离进程组之间的资源,而cgroups是为了对一组进程进行统一的资源监控和限制,比如内存使用上限以及文件系统的缓存限制、CPU利用和磁盘I/O吞吐的优先级控制、为了计费的审计或统计功能,以及挂起/恢复执行进程等进程控制功能。
要想对进程资源进行管理和限制,需要考虑如何抽象进程和资源,同时要考虑如何组织它们。cgroups中以下4个非常重要的概念做到了这一点。
● task:任务,对应于系统中运行的一个实体,一般是指进程,线程在Linux中是特殊一点的进程。
● subsystem:子系统,具体的资源控制器,控制某个特定的资源,比如CPU子系统可以控制CPU的运行时间,内存子系统可以控制内存的使用量等。
● cgroup:控制组,一组任务和子系统的关联关系,表示对这些任务进行怎样的资源管理。
● hierarchy:层级树,一系列cgroup组成的树形结构。每个节点都是一个cgroup,它可以有多个子节点,子节点默认会继承父节点的属性。系统中可以有多个hierarchy层级树。
将CPU和内存子系统(或者任意多个子系统)附加到同一个层级树,如图11-4所示。
[插图]
图11-4 cgroups层级树示意图
Linux并没有为cgroups内核功能提供任何系统调用接口,那么它又是如何让用户态的进程使用到cgroups功能的呢?
Linux内核有一个很强大的模块叫虚拟文件系统(Virtual File System,VFS),其能够把具体文件系统的细节隐藏起来,给用户态进程提供一个统一的文件系统API。Linux中使用多种数据结构在内核中关联了进程和cgroup节点,然后通过VFS把cgroups功能暴露给用户态,cgroups与VFS之间的衔接部分称为cgroups虚拟文件系统,因此可以在用户态用文件系统的方式进行操作。
在使用cgroups功能之前,可以通过查看/proc/cgroups,知道当前系统支持哪些子系统。
subsys_name hierarchy num_cgroup enabled
cpuset 11 1 1
cpu 3 64 1
cpuacct 3 64 1
blkio 8 64 1
memory 9 104 1
devices 5 64 1
freezer 10 4 1
net_cls 6 1 1
perf_event 7 1 1
net_prio 6 1 1
hugetlb 4 1 1
pids 2 68 1
从左到右,字段的含义如下。
● subsys_name:子系统的名字。
● hierarchy:子系统所关联的cgroup树的ID,如果多个子系统关联到同一棵cgroup树,那么它们的这个字段将一样,比如这里的cpu和cpuacct就一样,表示它们绑定到了同一棵树。
● num_cgroup:子系统所关联的cgroup树中进程组的个数,即树上节点的个数。
● enabled:使能状态,1表示开启,0表示没有开启。可以通过设置内核的启动参数“cgroup_disable”来控制子系统的使能状态。
从上到下的子系统依次是:
● cpuset:主要用于设置CPU的亲和性,可以限制cgroup中的进程只能在指定的CPU上运行,或者不能在指定的CPU上运行,同时cpuset还能设置内存的亲和性。
● cpu:主要用于限制cgroup的CPU使用上限及相对于其他cgroup的相对值。
● cpuacct:包含当前cgroup所使用的CPU的统计信息。
● blkio:为块设备设定输入/输出限制,比如物理设备磁盘、固态硬盘、USB等。
● memory:主要功能有限制cgroup中所有进程所能使用的物理内存总量;限制cgroup中所有进程所能使用的物理内存和交换空间总量(config_memcg_swap);限制cgroup中所有进程所能使用的内核内存总量及其他一些内核资源。因为内存子系统比较耗费资源,所以内核专门添加了一个参数cgroup_disable=memory来禁用整个内存子系统。
● devices:可允许或者拒绝cgroup中的任务访问设备。
● freezer:用于挂起或者恢复cgroup中的任务。
● net_cls:使用等级识别符(classid)标记网络数据包,可允许Linux流量控制程序(tc)识别从具体cgroup中生成的数据包。
● perf_event:允许使用perf工具来监控cgroup。
● net_prio:用来设计网络流量的优先级。
● hugetlb:主要对HugeTLB系统进行限制,这是一个大页内存文件系统。
● pids:功能是限制cgroup及其所有子孙cgroup里面能创建的总task数量。
cgroup的所有功能都是基于Linux内核中的cgroups虚拟文件系统来操作的,因而使用cgroup非常简单,挂载这个cgroup虚拟文件系统就可以了。一般情况下都是挂载到/sys/fs/cgroup目录下,当然挂载到其他任何目录都是可以的。可以通过mount命令查看cgroup的挂载信息。
$ mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
以/sys/fs/cgroup目录为例,假设该目录已经存在,下面用到的xxx为任意字符串,应该为cgroup取一个更有意义的名字。挂载一棵和所有子系统关联的cgroup树到/sys/fs/cgroup的命令如下。
$ sudo mount -t cgroup xxx /sys/fs/cgroup
挂载一棵和cpuset子系统关联的cgroup树到/sys/fs/cgroup/cpuset的命令如下。
$ sudo mkdir /sys/fs/cgroup/cpuset
$ sudo mount -t cgroup -o cpuset xxx /sys/fs/cgroup/cpuset
挂载一棵与cpu和cpuacct子系统关联的cgroup树到/sys/fs/cgroup/cpu,cpuacct的命令如下。
$ sudo mkdir /sys/fs/cgroup/cpu,cpuacct
$ sudo mount -t cgroup -o cpu,cpuacct xxx /sys/fs/cgroup/cpu,cpuacct
创建cgroup,可以直接用mkdir在对应的子资源中创建一个目录。
$ sudo mkdir /sys/fs/cgroup/cpu/mycgroup
$ ls -l /sys/fs/cgroup/cpu/mycgroup
total 0
-rw-r--r-- 1 root root 0 Dec 13 08:02 cgroup.clone_children
-rw-r--r-- 1 root root 0 Dec 13 08:02 cgroup.procs
-r--r--r-- 1 root root 0 Dec 13 08:02 cpuacct.stat
-rw-r--r-- 1 root root 0 Dec 13 08:02 cpuacct.usage
-r--r--r-- 1 root root 0 Dec 13 08:02 cpuacct.usage_all
-r--r--r-- 1 root root 0 Dec 13 08:02 cpuacct.usage_percpu
-r--r--r-- 1 root root 0 Dec 13 08:02 cpuacct.usage_percpu_sys
-r--r--r-- 1 root root 0 Dec 13 08:02 cpuacct.usage_percpu_user
-r--r--r-- 1 root root 0 Dec 13 08:02 cpuacct.usage_sys
-r--r--r-- 1 root root 0 Dec 13 08:02 cpuacct.usage_user
-rw-r--r-- 1 root root 0 Dec 13 08:02 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 Dec 13 08:02 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 Dec 13 08:02 cpu.shares
-r--r--r-- 1 root root 0 Dec 13 08:02 cpu.stat
-rw-r--r-- 1 root root 0 Dec 13 08:02 notify_on_release
-rw-r--r-- 1 root root 0 Dec 13 08:02 tasks删除子资源,就是删除对应的目录。
$ sudo rmdir /sys/fs/cgroup/cpu/mycgroup/
删除对应的目录之后,如果tasks文件中有进程,它们会自动迁移到父cgroup中。
设置group的参数就是直接向特定的文件中写入特定格式的内容,比如要限制cgroup能够使用的CPU核数。
$ sudo echo 0-1 > /sys/fs/cgroup/cpuset/mycgroup/cpuset.cpus
要把某个已经运行的进程加入cgroup,可以直接向需要的cgroup tasks文件中写入进程的PID。
$ sudo echo 2358 > /sys/fs/cgroup/memory/mycgroup/tasks
如果想直接把进程运行在某个cgroup,但是运行前还不知道进程的PID应该怎么办呢?可以利用cgroup的继承方式来实现,子进程会继承父进程的cgroup,因此可以把当前Shell加入要想的cgroup。
$ sudo echo $$ > /sys/fs/cgroup/cpu/mycgroup/tasks
这个方案有个缺陷,运行之后原来的Shell还在cgroup中。如果希望进程运行完不影响当前使用的Shell,可以另起一个临时的Shell。
$ sudo sh -c "echo \$$ > /sys/fs/cgroup/memory/mycgroup/tasks && stress -m 1"如果想要把进程移动到另外一个cgroup,只要使用echo把进程PID写入cgroup tasks文件中即可,原来cgroup tasks文件会自动删除该进程。
除了使用cgroup虚拟文件系统操作cgroup,还有一些软件包提供了一系列命令可以操作和管理cgroup,比如在Ubuntu系统中可以通过下面的命令安装cgroup-tools来操作和管理cgroup。
$ sudo apt-get install -y cgroup-tools
cgroups提供了强大的功能,能够控制容器资源的使用情况,是容器的关键技术之一。篇幅所限,没有介绍每一个类型的子系统是如何管理和控制容器资源的,仅对cgroups技术做了概览性的介绍。