部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink为各种场景提供了不同的部署模式,主要有以下三种:会话模式(Session Mode)、单作业模式(Per-Job Mode)、应用模式(Application Mode)。
区别主要在于:集群的生命周期以及资源的分配方式;以及应用的main方法到底在哪里执行——客户端(Client)还是 JobManager。
1.1 会话模式(Session Mode)
会话模式其实最符合常规思维。需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。
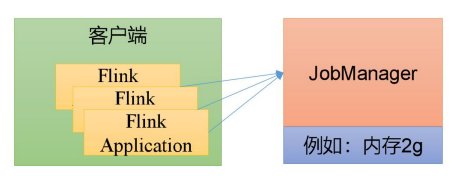
会话模式比较适合于单个规模小、执行时间短的大量作业。
1.2 单作业模式(Per-Job Mode)
会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,可以考虑为每个提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式。
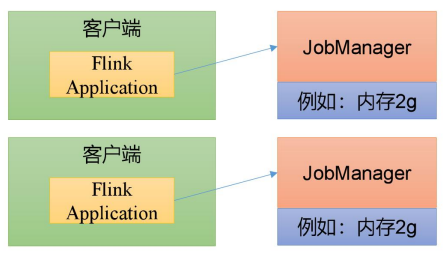
作业完成后,集群就会关闭,所有资源也会释放。
这些特性使得单作业模式在生产环境运行更加稳定,所以是 实际应用的首选模式。
需要注意的是,Flink本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如YARN、Kubernetes(K8S)。
1.3 应用模式(Application Mode)
前面提到的两种模式下,应用代码都是在客户端上执行,然后由客户端提交给JobManager的。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给JobManager;加上很多情况下提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
所以解决办法就是,不要客户端了,直接把应用提交到JobManger上运行。而这也就代表着,需要为每一个提交的应用单独启动一个JobManager,也就是创建一个集群。这个JobManager只为执行这一个应用而存在,执行结束之后JobManager也就关闭了,这就是所谓的应用模式。
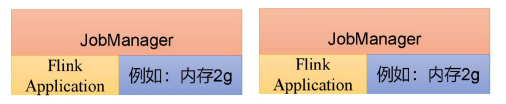
应用模式与单作业模式,都是提交作业之后才创建集群:单作业模式是通过客户端来提交的,客户端解析出的
每一个作业对应一个集群:而应用模式下,是直接由JobManager执行应用程序的。
实际应用时,一般需要和资源管理平台结合起来,选择特定的模式来分配资源、部署应用。
运行模式
2.1 Standalone 运行模式(了解)
独立模式是独立运行的,不依赖任何外部的资源管理平台;当然独立也是有代价的:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式一般只用在开发测试或作业非常少的场景下。
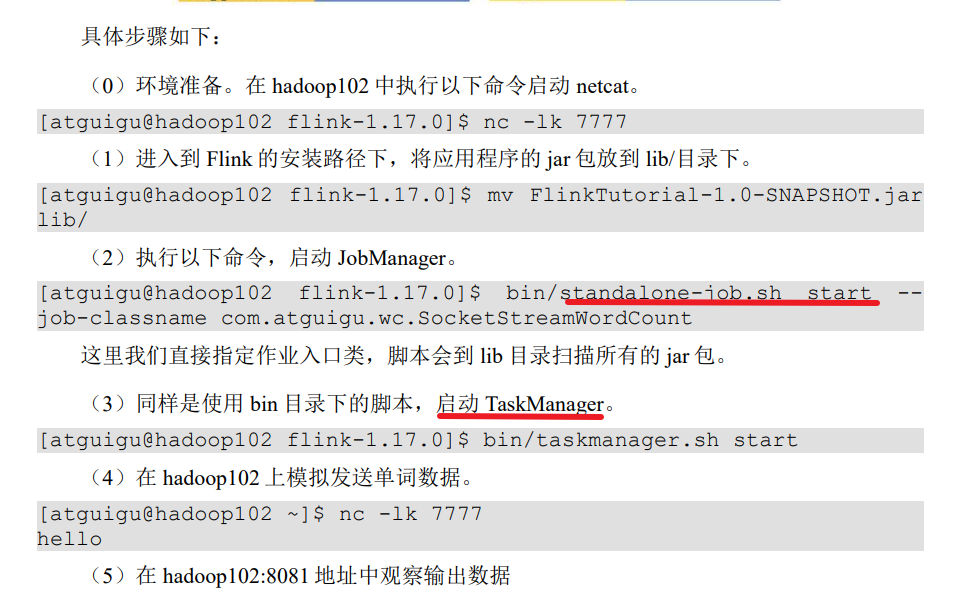
2.1.1 会话模式部署
提前启动集群,并通过 Web 页面客户端提交任务(可以多个任务,但是集群资源固定)。
2.1.2 单作业模式部署
Flink的Standalone集群并不支持单作业模式部署。因为单作业模式需要借助一些资源管理平台。
2.1.3 应用模式部署
应用模式下不会提前创建集群,所以不能调用 start-cluster.sh 脚本。可以使用同样在bin 目录下的 standalone-job.sh 来创建一个 JobManager。
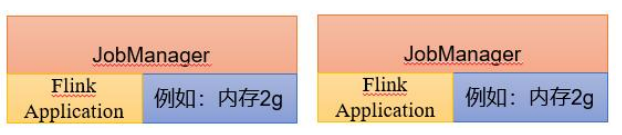
应用模式 jar包必须在lib目录下

2.2 YARN 运行模式(重点)
YARN (hadoop中组件,用于资源管理和作业调度)上部署的过程是:客户端把 Flink 应用提交给 Yarn 的ResourceManager,Yarn的ResourceManager 会向 Yarn 的 NodeManager 申请容器 。在这些容器上,Flink会部署JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在JobManger 上的作业所需要的 Slot 数量动态分配 TaskManager 资源。
2.2.1 前提准备
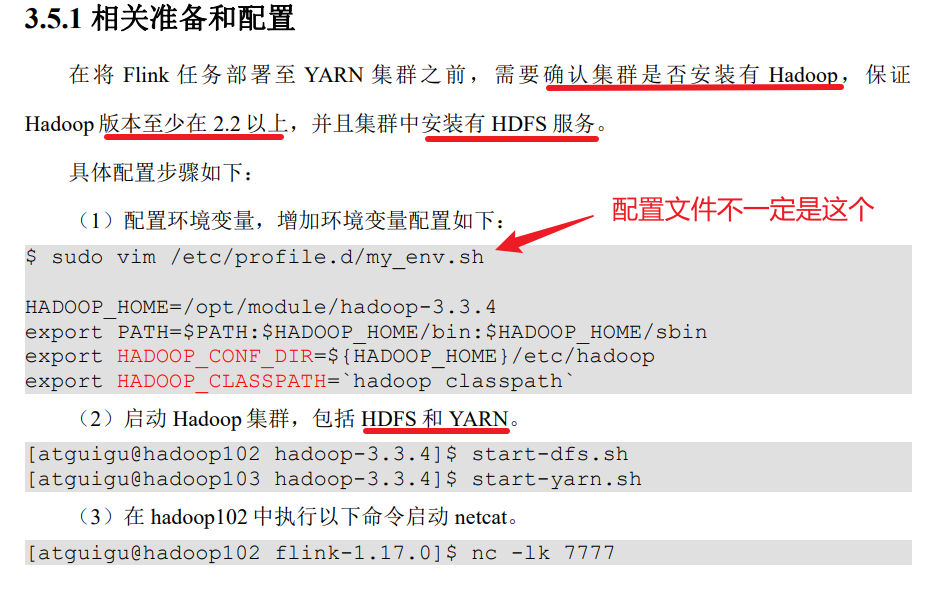
2.2.2 会话模式部署
YARN 的会话模式与独立集群略有不同,需要首先申请一个YARN 会话(YARNSession)来启动 Flink 集群。具体步骤如下:

可以Web UI界面提交

2.2.3 单作业模式部署
在 YARN 环境中,由于有了外部平台做资源调度,所以也可以直接向YARN提交一个单独的作业,从而启动一个 Flink 集群。
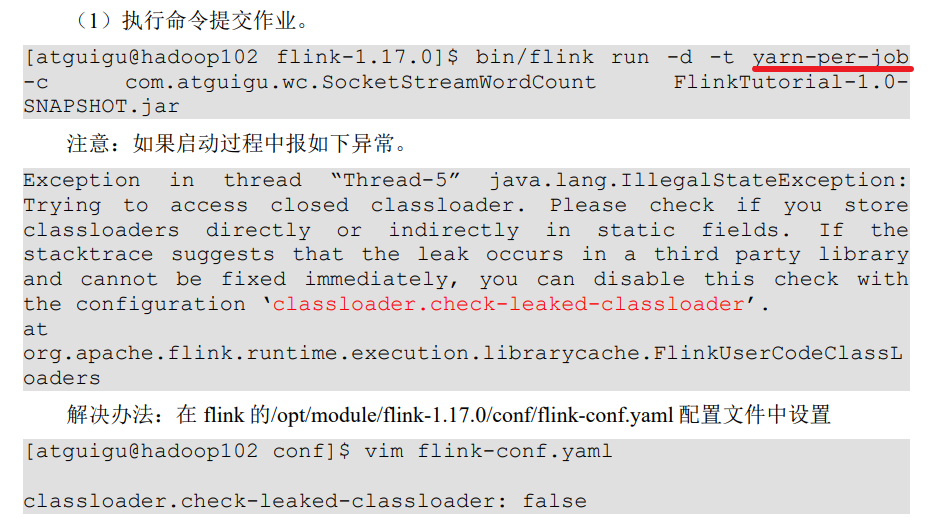
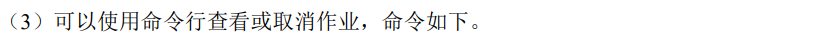
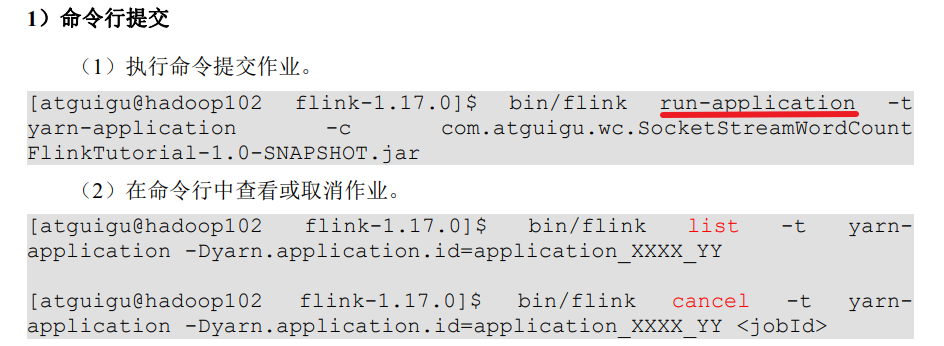
2.2.4 应用模式部署 √
应用模式同样非常简单,与单作业模式类似,直接执行 flink run-application 命令即可。
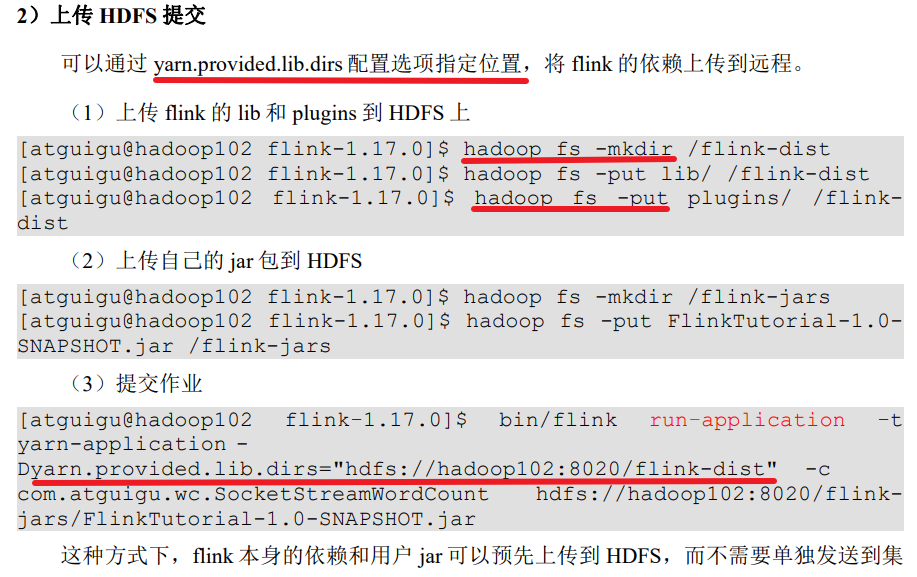
2.3 K8S 运行模式(了解)
容器化部署是如今业界流行的一项技术,基于 Docker 镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是 Kubernetes(k8s),而Flink也在最近的版本中支持了 k8s 部署模式。基本原理与 YARN 是类似的,具体配置可以参见官网说明。
历史服务器
运行 Flink job 的集群一旦停止,只能去 yarn 或本地磁盘上查看日志,不再可以查看作业挂掉之前的运行的 Web UI,很难清楚知道作业在挂的那一刻到底发生了什么。如果还没有 Metrics 监控的话,那么完全就只能通过日志去分析和定位问题了,所以如果能还原之前的 Web UI,可以通过 UI 发现和定位一些问题。
Flink 提供了历史服务器,用来在相应的 Flink 集群关闭后查询已完成作业的统计信息。都知道只有当作业处于运行中的状态,才能够查看到相关的WebUI 统计信息。通过History Server 才能查询这些已完成作业的统计信息,无论是正常退出还是异常退出。
此外,它对外提供了 REST API,它接受 HTTP 请求并使用JSON 数据进行响应。Flink任务停止后,JobManager 会将已经完成任务的统计信息进行存档,History Server 进程则在任务停止后可以对任务统计信息进行查询。比如:最后一次的Checkpoint、任务运行时的相关配置。
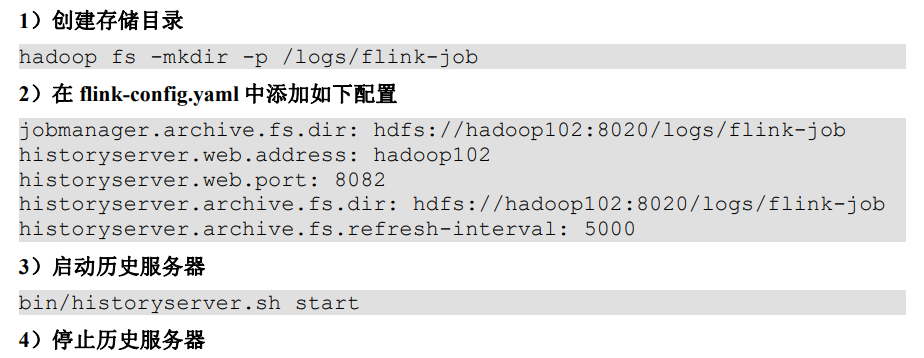
bin/historyserver.sh stop
5)在浏览器地址栏输入:http://hadoop102:8082 查看已经停止的job的统计信息。







![Python库学习(十二):数据分析Pandas[下篇]](https://img-blog.csdnimg.cn/img_convert/2a4695c9d8059976876ae0f8fb347752.png)