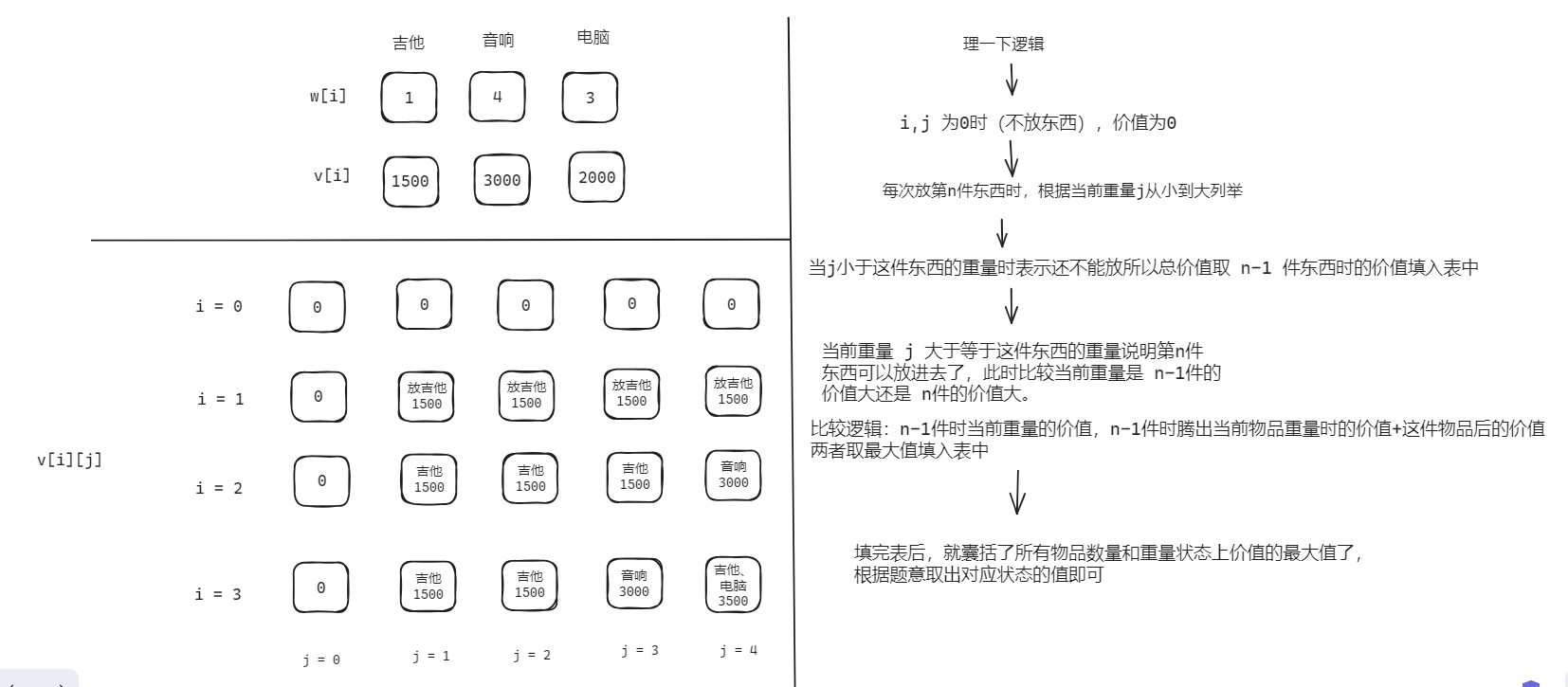
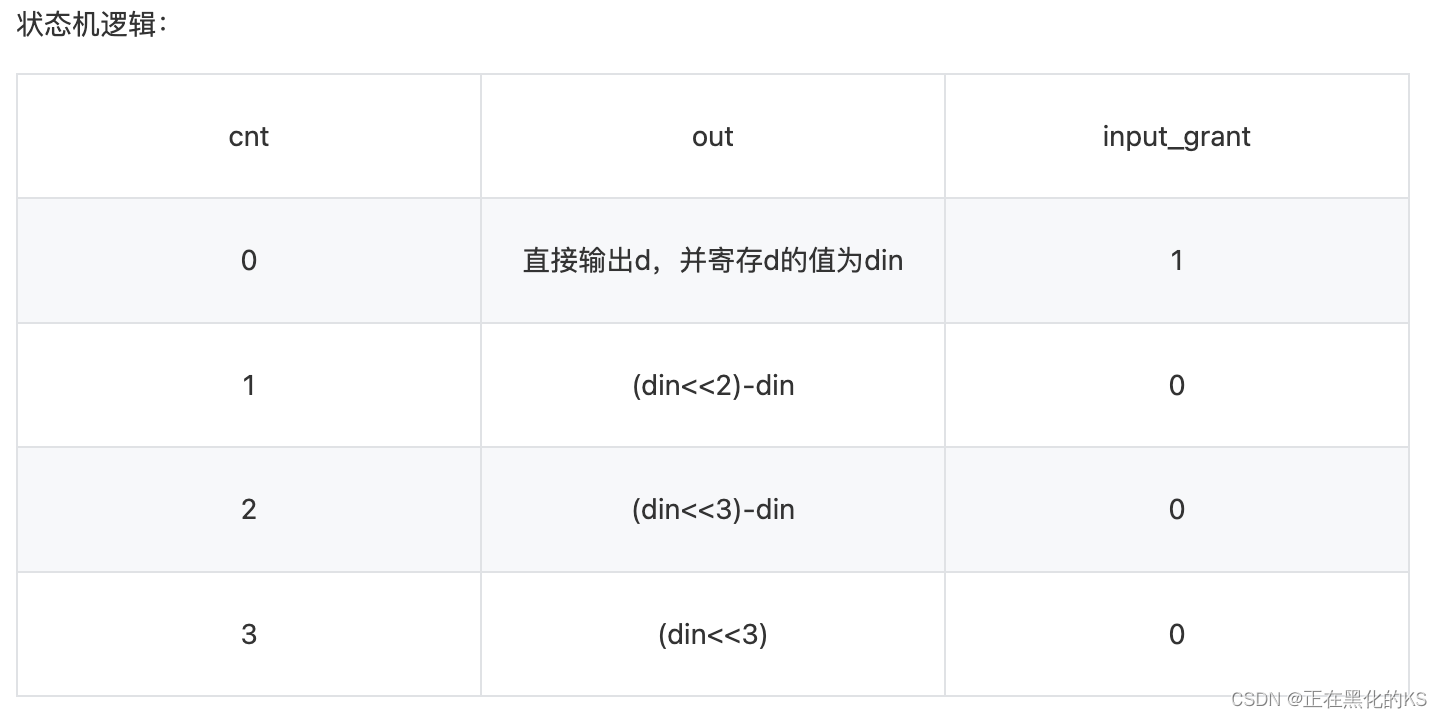
概述
spark 版本为
3.2.4,注意RDD转DataFrame的代码出现的问题及解决方案
本文目标如下:
RDD,Datasets,DataFrames之间的区别- 入门
- SparkSession
- 创建
DataFrames DataFrame操作- 编程方式运行
sql查询 - 创建
Datasets DataFrames与RDDs互相转换- 使用反射推断模式
- 编程指定
Schema
参考 Spark 官网
相关文章链接如下
| 文章 | 链接 |
|---|---|
| spark standalone环境安装 | 地址 |
| Spark的工作与架构原理 | 地址 |
| 使用spark开发第一个程序WordCount程序及多方式运行代码 | 地址 |
| RDD编程指南 | 地址 |
| RDD持久化 | 地址 |
RDD ,Datasets,DataFrames 之间的区别
Datasets , DataFrames和 RDD
Dataset 是一个分布式的数据集合,Dataset 是 Spark 1.6 中添加的一个新接口,它增益了 RDD (强类型,可以使用 lambda 函数的能力) 和 Spark sql 优化执行引擎的优势。Dataset 可以由JVM对象构建,然后使用函数转换(map、flatMap、filter等)进行操作。数据集API有Scala和Java版本。Python不支持数据集API。
DataFrame是组织成命名列的数据集。它在概念上等同于关系数据库中的表,DataFrame API在Scala、Java、Python和R中可用。在Scala API中,DataFrame只是Dataset[Row]的一个类型别名。而在Java API中,用户需要使用Dataset<Row>来表示DataFrame。
DataFrame=RDD+Schema,RDD可以认为是表中的数据,Schema是表结构信息。DataFrame可以通过很多来源进行构建,包括:结构化的数据文件,Hive中的表,外部的关系型数据库,以及RDD
入门
Spark SQL是一个用于结构化数据处理的Spark模块。与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了更多关于正在执行的数据结构信息。在内部,Spark SQL使用这些额外的信息来执行额外的优化。有几种方法可以与SparkSQL进行交互,包括SQL和 Dataset API。计算结果时,使用相同的执行引擎,与用于表示计算的API/语言无关。方便用户切换不同的方式进行操作
people.json
people.json文件准备
SparkSession
Spark sql 中所有功能入口点是 SparkSession类。创建一个基本的 SparkSession,只需使用 SparkSession.builder()
import org.apache.spark.sql.SparkSessionval spark = SparkSession.builder().appName("Spark SQL basic example").config("spark.some.config.option", "some-value").getOrCreate()
创建 DataFrames
使用 SparkSession,通过存在的RDD,hive 表,或其它的Spark data sources 程序创建 DataFrames
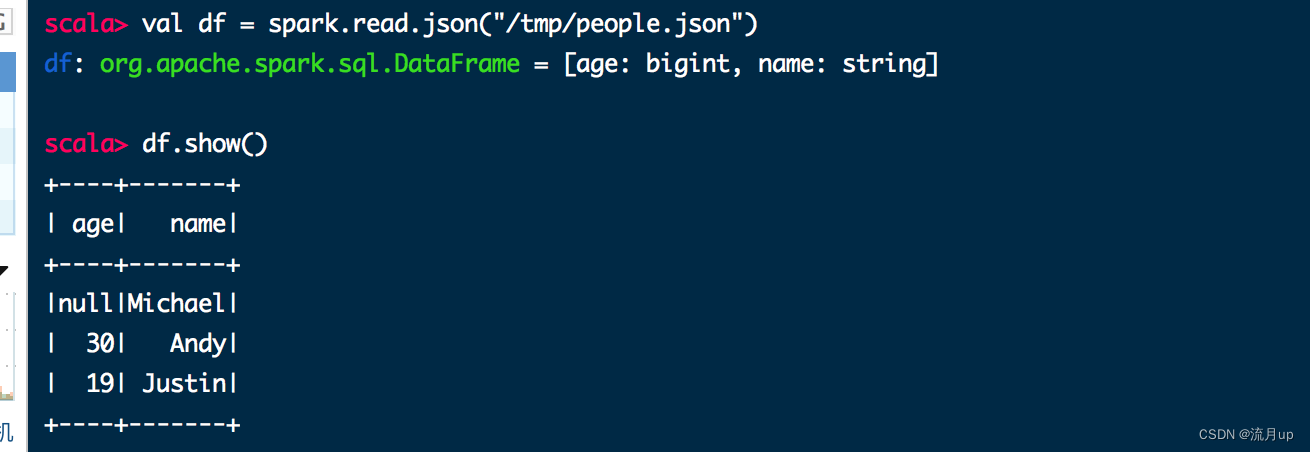
val df = spark.read.json("/tmp/people.json")
df.show()
执行如下图
DataFrame 操作
使用数据集进行结构化数据处理的基本示例如下
// 需要引入 spark.implicits._ 才可使用 $
// This import is needed to use the $-notation
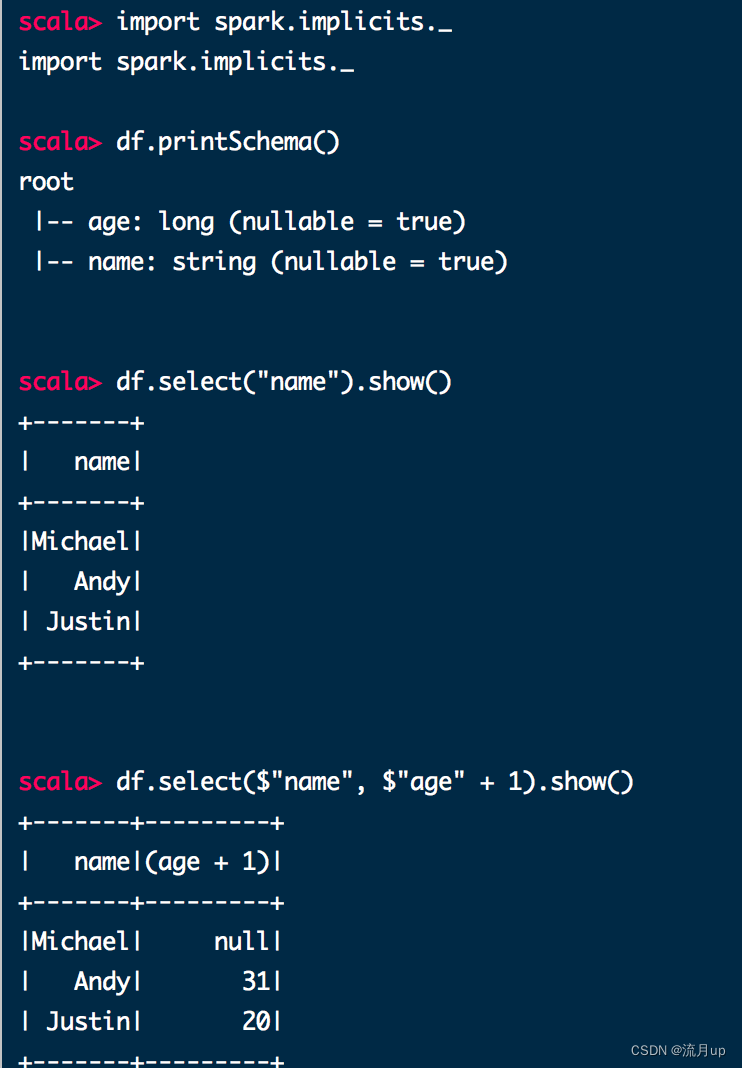
import spark.implicits._
// 打印schema 以树格式
// Print the schema in a tree format
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)// 仅显示 name 列
// Select only the "name" column
df.select("name").show()
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
// 显示所有,age 加1
// Select everybody, but increment the age by 1
df.select($"name", $"age" + 1).show()
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+// 过滤 人的 age 大于 21
// Select people older than 21
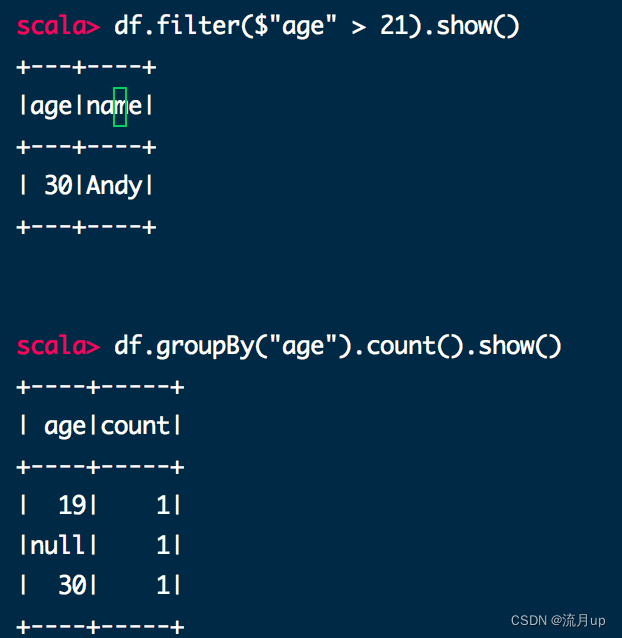
df.filter($"age" > 21).show()
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+// 按 age 分组统计
// Count people by age
df.groupBy("age").count().show()
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
spark-shell 执行如下图
编程方式运行 sql 查询
df.createOrReplaceTempView("people")val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
执行如下:
scala> df.createOrReplaceTempView("people")scala> val sqlDF = spark.sql("SELECT * FROM people")
sqlDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]scala> sqlDF.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
创建 Datasets
Datasets类似于RDD,不是使用Java序列化或Kryo,而是使用专门的编码器来序列化对象,以便通过网络进行处理或传输。使用的格式允许Spark执行许多操作,如过滤、排序和哈希,而无需将字节反序列化为对象。
case class Person(name: String, age: Long)// 为 case classes 创建编码器
// Encoders are created for case classes
val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS.show()// 为能用类型创建编码器,并提供 spark.implicits._ 引入
// Encoders for most common types are automatically provided by importing spark.implicits._
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect() // Returns: Array(2, 3, 4)// 通过定义类,将按照名称映射,DataFrames 能被转成 Dataset
// DataFrames can be converted to a Dataset by providing a class. Mapping will be done by name
val path = "/tmp/people.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
执行如下:
scala> case class Person(name: String, age: Long)
defined class Personscala> val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]scala> caseClassDS.show()
+----+---+
|name|age|
+----+---+
|Andy| 32|
+----+---+scala> val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS: org.apache.spark.sql.Dataset[Int] = [value: int]scala> primitiveDS.map(_ + 1).collect()
res1: Array[Int] = Array(2, 3, 4)scala> val path = "/tmp/people.json"
path: String = /tmp/people.jsonscala> val peopleDS = spark.read.json(path).as[Person]
peopleDS: org.apache.spark.sql.Dataset[Person] = [age: bigint, name: string]scala> peopleDS.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
DataFrames 与 RDDs 互相转换
Spark SQL支持两种不同的方法将现有RDD转换为Datasets。
- 第一种方法使用反射来推断包含特定类型对象的
RDD的模式。这种基于反射的方法可以生成更简洁的代码,当知道schema结构的时间,会有更好的效果。 - 第二种方法是通过编程接口,构造
schema,然后将其应用于现有的RDD。虽然此方法更详细,直至运行时,才能知道他们的字段和类型,用于构造Datasets。
使用反射推断模式
代码如下:
object RddToDataFrameByReflect {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("RddToDataFrameByReflect").master("local").getOrCreate()// 用于从RDD到DataFrames的隐式转换// For implicit conversions from RDDs to DataFramesimport spark.implicits._// Create an RDD of Person objects from a text file, convert it to a Dataframeval peopleDF = spark.sparkContext.textFile("/Users/hyl/Desktop/fun/sts/spark-demo/people.txt").map(_.split(",")).map(attributes => Person(attributes(0), attributes(1).trim.toInt)).toDF()// Register the DataFrame as a temporary viewpeopleDF.createOrReplaceTempView("people")// SQL statements can be run by using the sql methods provided by Sparkval teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19")// The columns of a row in the result can be accessed by field indexteenagersDF.map(teenager => "Name: " + teenager(0)).show()// or by field nameteenagersDF.map(teenager => "Name: " + teenager.getAs[String]("name")).show()}case class Person(name: String, age: Long)
}
执行如下图:
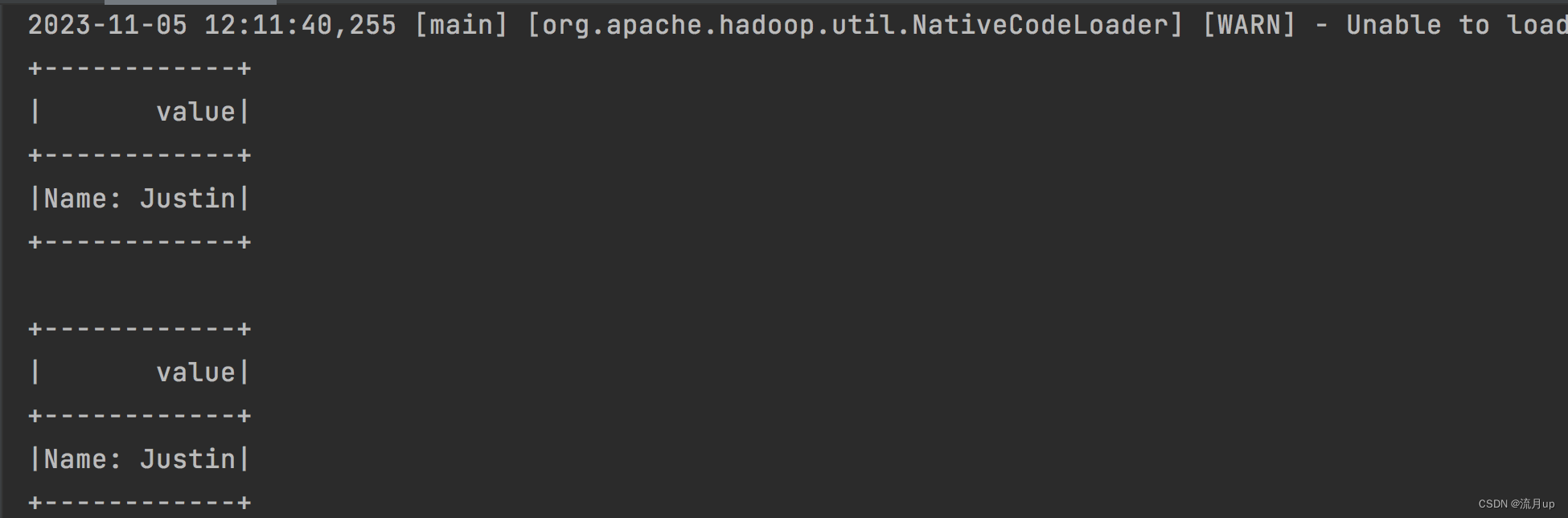
编码问题
关于 Spark 官网 上复杂类型编码问题,直接加下面一句代码
teenagersDF.map(teenager => teenager.getValuesMap[Any](List("name", "age"))).collect().foreach(println(_))
报以下图片错误
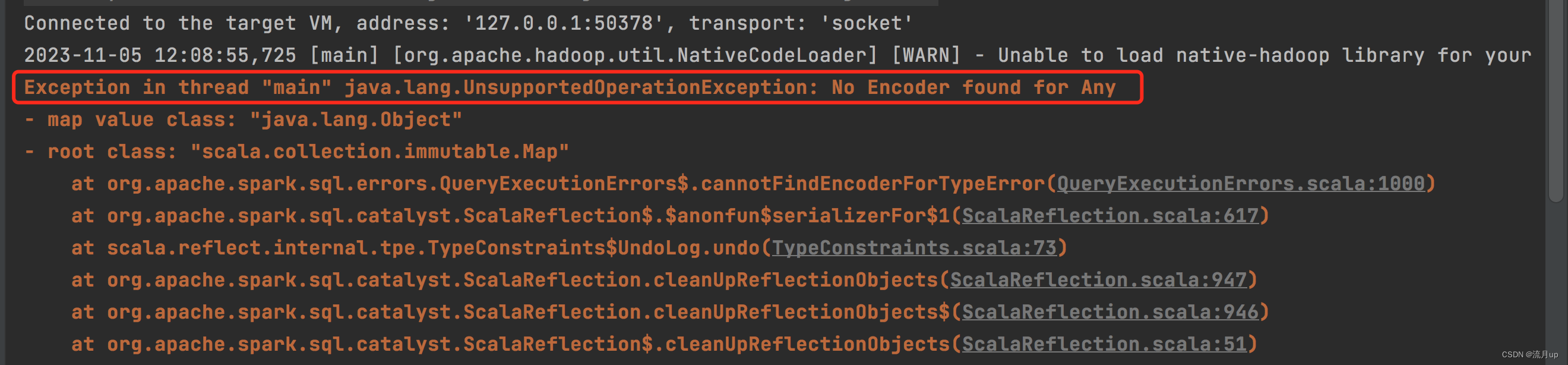
将原有代码改变如下:
// 没有为 Dataset[Map[K,V]] 预先定义编码器,需要自己定义// No pre-defined encoders for Dataset[Map[K,V]], define explicitlyimplicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]]// 也可以如下操作// Primitive types and case classes can be also defined as// implicit val stringIntMapEncoder: Encoder[Map[String, Any]] = ExpressionEncoder()// row.getValuesMap[T] retrieves multiple columns at once into a Map[String, T]teenagersDF.map(teenager => teenager.getValuesMap[Any](List("name", "age"))).collect().foreach(println(_))// Array(Map("name" -> "Justin", "age" -> 19))
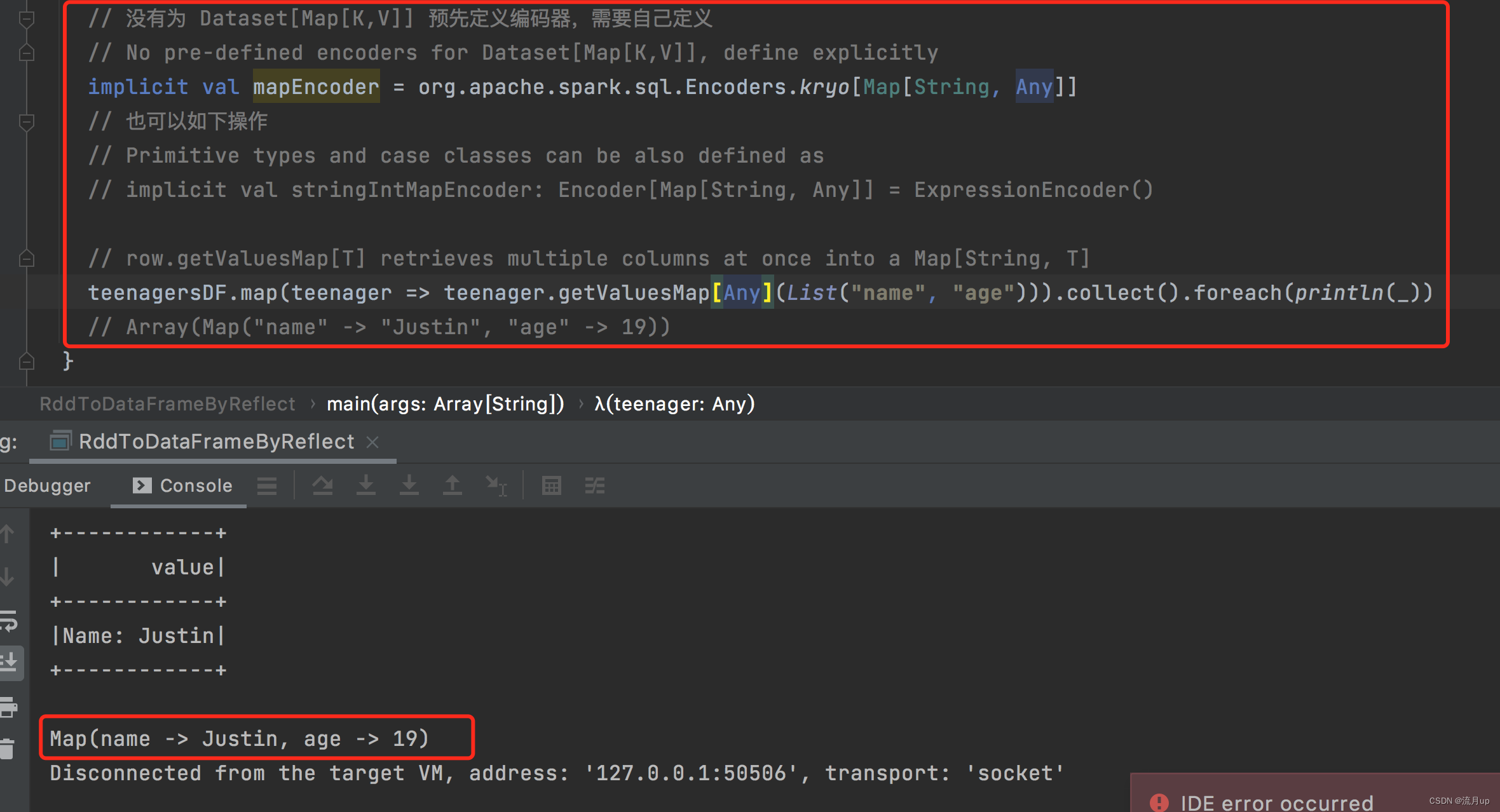
通过这一波操作,就可以理解什么情况下,需要编码器,以及编码器的作用
编程指定 Schema
代码如下:
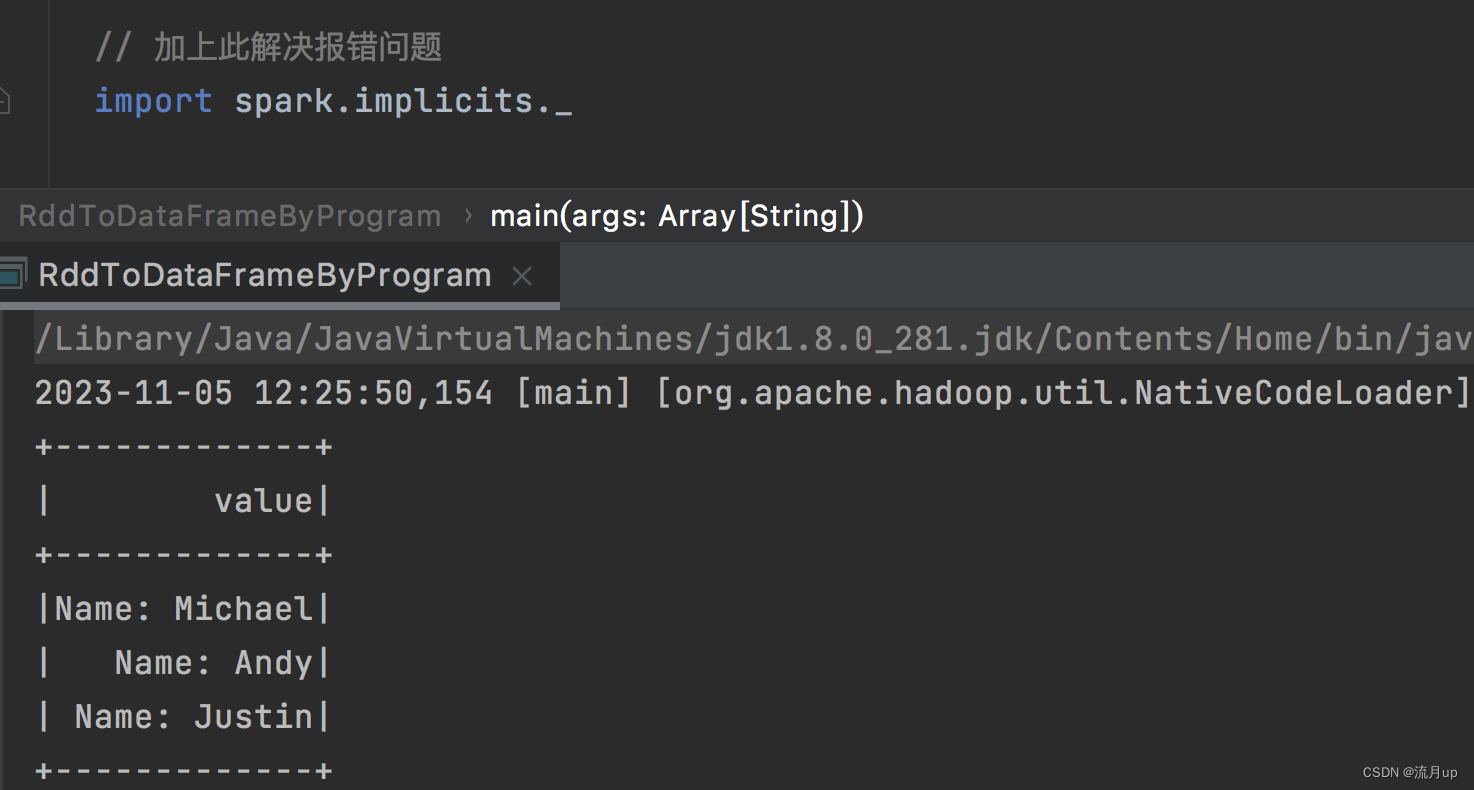
object RddToDataFrameByProgram {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local").getOrCreate()import org.apache.spark.sql.Rowimport org.apache.spark.sql.types._// 加上此解决报错问题import spark.implicits._// Create an RDDval peopleRDD = spark.sparkContext.textFile("/Users/hyl/Desktop/fun/sts/spark-demo/people.txt")// The schema is encoded in a stringval schemaString = "name age"// Generate the schema based on the string of schemaval fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true))val schema = StructType(fields)// Convert records of the RDD (people) to Rowsval rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim))// Apply the schema to the RDDval peopleDF = spark.createDataFrame(rowRDD, schema)// Creates a temporary view using the DataFramepeopleDF.createOrReplaceTempView("people")// SQL can be run over a temporary view created using DataFramesval results = spark.sql("SELECT name FROM people")// The results of SQL queries are DataFrames and support all the normal RDD operations// The columns of a row in the result can be accessed by field index or by field nameresults.map(attributes => "Name: " + attributes(0)).show()}
}
执行如下图
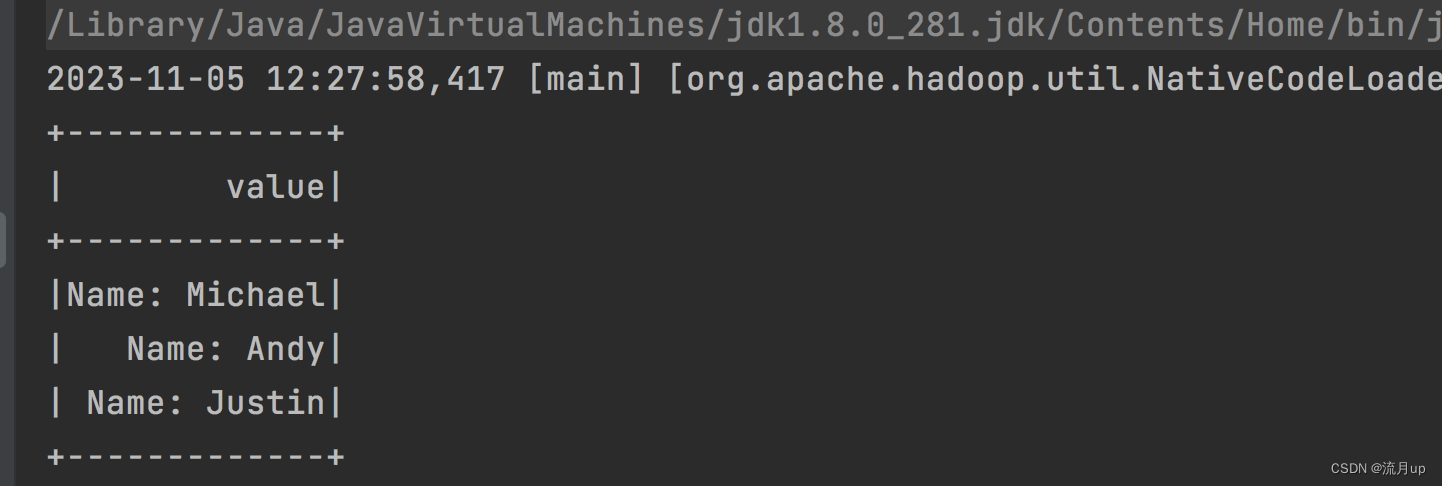
官方文档的代码不全问题
Unable to find encoder for type String. An implicit Encoder[String] is needed to store String instances in a Dataset. Primitive types (Int, String, etc) and Product types (case classes) are supported by importing spark.implicits._ Support for serializing other types will be added in future releases.
results.map(attributes => "Name: " + attributes(0)).show()

加下以下代码
// 加上此解决报错问题
import spark.implicits._
如下图解决
结束
spark sql 至此结束,如有问题,欢迎评论区留言。