生成式AI正在风靡全球,不少企业开始研究如何在其业务流程中采用人工智能技术,更有一些企业客户开始考虑在数据中心和私有云中部署自己的AIGC和 GPU 扩展网络。从网络角度来看,用于承载这类业务的数据中心与传统的数据中心有很大不同,它甚至与用于高性能计算 (HPC) 的数据中心也有所区别。
分析AI训练数据的一半时间消耗在网络上
尽管人们都在关注使用GPU服务器处理数据的用时,但实际上人工智能数据的一半处理过程都发生在网络中。所以,我们需要更加关注数据中心网络所能提供的速度和灵活性,以避免其成为整个数据中心的性能瓶颈。
构建高度可扩展的网络是AI数据中心的关键所在,考虑到未来的增长能力,网络交换架构必须包括横向和纵向扩展的硬件,网络操作系统需要带有应对数据包突增、负载平衡和智能流量重定向等数据中心高级功能,这样才可在AIGC网络内超负荷的 GPU 处理单元之间智能地重新路由流量。
工作负载数变少,但规模更大了
与致力于将网络延迟降至超低水平的高性能计算不同,人工智能数据中心的建设必须侧重于高吞吐能力。高性能计算网络旨在同时传输数千个工作负载,并要求将延迟降至最低,而人工智能工作负载的数量要少得多,但规模却大得多。
从速度的角度来看,对于AIGC网络来说,网络吞吐量比网络延迟更重要。如此,用于 HPC 的 InfiniBand 网络结构所具有的超低延迟优势已被削弱,而由于以太网标准具有更高的吞吐能力和更高的性价比,使用吞吐量更高的以太网网络可能很快就会成为常态。
网络部署需要更适应高密度连接
为生成式AI计算部署高密度 GPU 机架并非易事,首先网络布线的难度变大,此外还需要高达四倍的交换机端口密度。根据 Dell’Oro Group 的一份研究报告,到 2027 年,多达 20% 的数据中心交换机端口将分配给 AI 服务器。电源和冷却系统可能也都需要进行对应的调整才能适应更高的密度。
使用多站点或微型数据中心或许是适应这种密度的最佳选择。然而这也给连接这些站点的网络带来了压力,即要求网络尽可能具有更高的传输性能和扩展性。
网络的自动化编排和运维成为必备条件
承载AI的数据中心网络错综复杂,需要为此专门优化性能和提高可靠性,因此我们不应继续使用传统的命令行和第三方性能监控工具来管理 AIGC 网络。相反,企业应该部署一个网络编排平台,从一开始就在控制平面架构中提供一些有用的功能和性能洞察。
编排平台可提供多种优势,大大增强数据中心的管理能力:
- 自动创建数据中心Underlay网络,大大减少网络开局和网络安全策略所需的时间。
- 创建直观、自动化的Overlay网络和持续的 NetOps 管理。借助图形用户界面,管理平台可让网络管理员一站式地创建网络和网络安全策略,并自动将命令推送到需要的数据中心交换机而无需学习复杂的命令行。并且策略的创建基于系统内的标准模板,在很大程度上可以消除手动配置错误。
- 提高性能和网络可视化程度。网络自动化工具还可使用多种传统和现代方法从网络交换硬件中收集和分析交换机健康状况和性能数据。收集和分析网络遥测数据是目前最新的方案:在这种情况下,交换机被配置为使用 gNMI 和 NETCONF 等专用协议标准向协调器发送实时性能测量数据。
- 与传统的网络监控协议(如SNMP)相比,这些协议功能强大得多,有助于主动识别网络中存在的性能问题,在造成网络瘫痪或中断之前就开始补救。
附录:AIGC网络建设实践方案
方案详情请参阅:客户案例:高性能、大规模、高可靠的AIGC承载网络 (asterfusion.com)
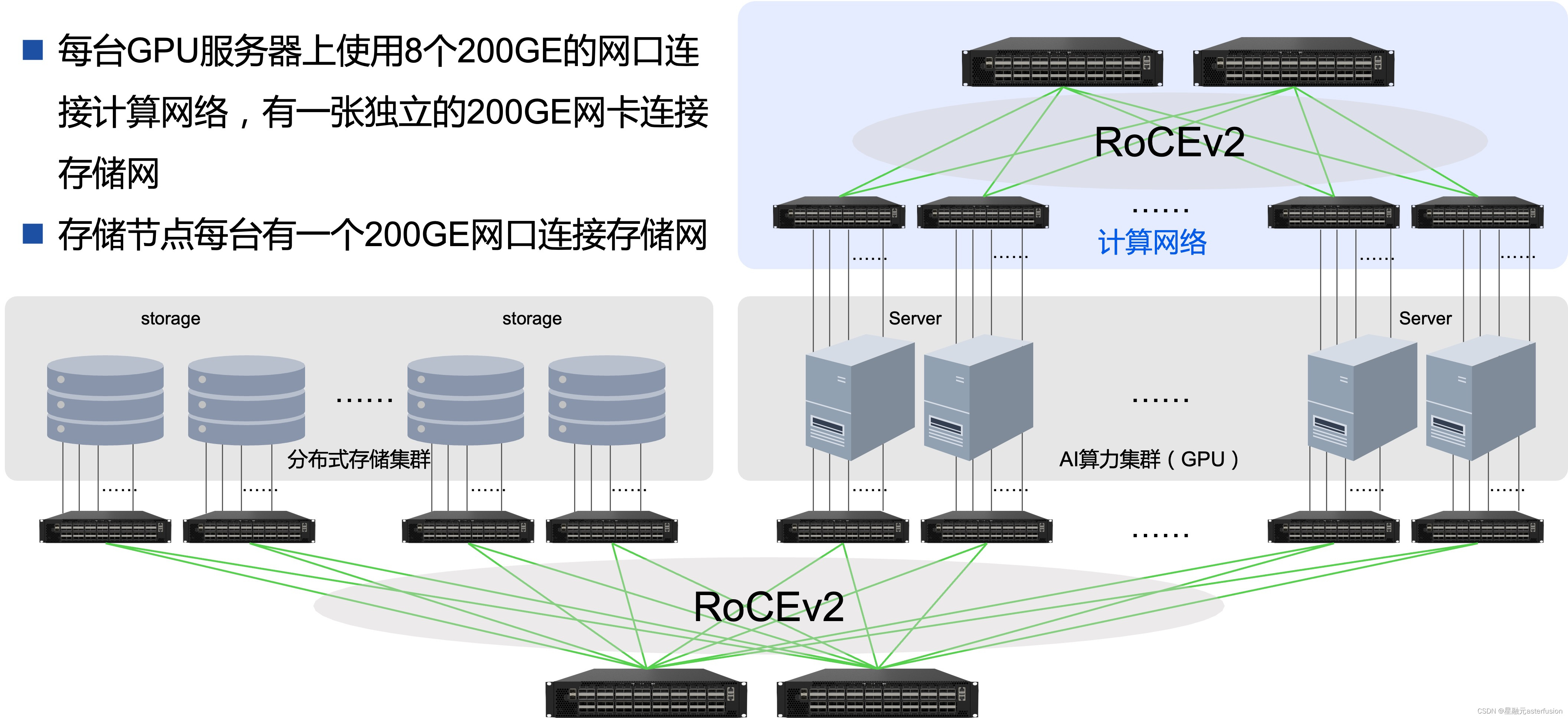
- 超低TCO、超高性价比:相较于IB网络方案,大幅度降低用户的网络TCO,同时确保超高性能
- 横向平滑扩容、1:1收敛无阻塞:无收敛的网络设计确保无阻塞的大容量网络,按需横向扩展
- 整网RoCEv2:基于CEE/DCB能力,提供可与IB媲美的性能和同样无损的网络服务
- 开放网络操作系统:星融元网络操作系统AsterNOS,SONiC企业级发行版,支持灵活的功能扩展、在线升级
- 无缝对接云管:AsterNOS 利用简单易用的REST API,可轻松让第三方的云平台/控制器快速纳管
- 专家级服务:专业、全面、可靠的研发、方案与服务团队,为客户提供小时级的快速响应服务
关注vx公号“星融元Asterfusion”,获取更多技术分享和最新产品动态。