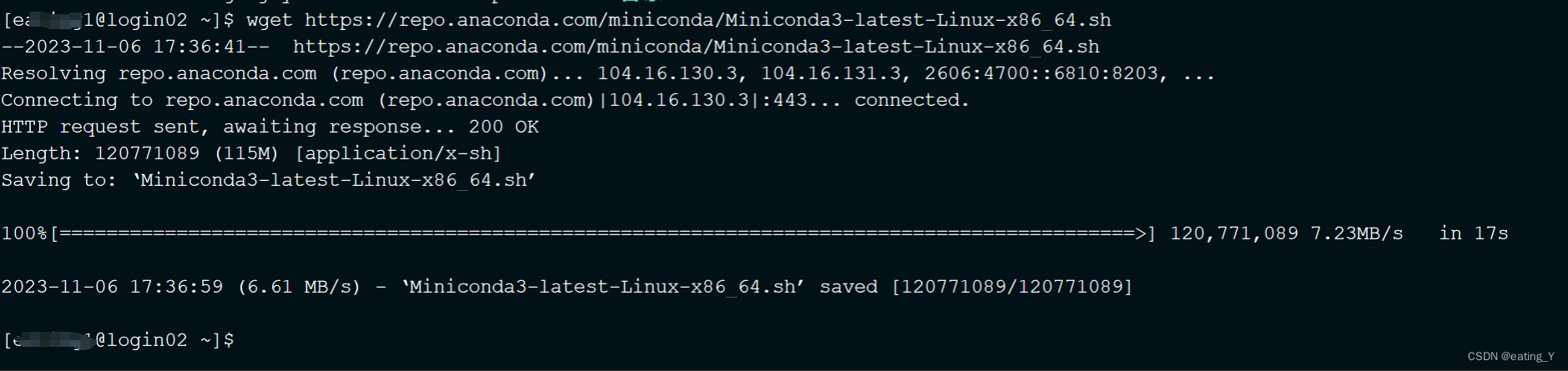
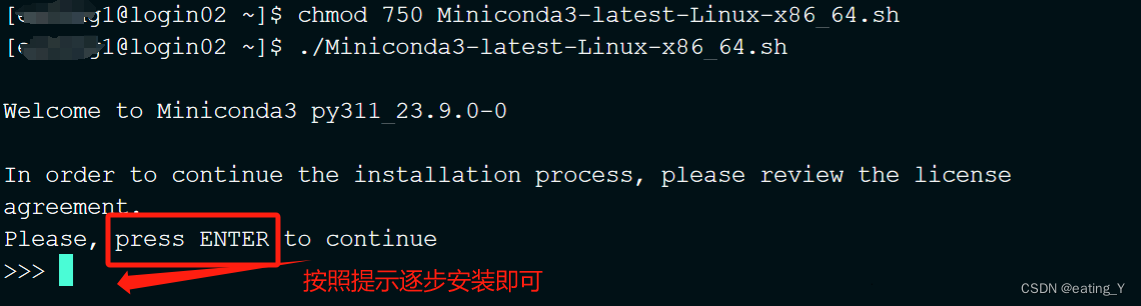
1.conda安装方法:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh #下载miniconda安装包chmod 750 Miniconda3-latest-Linux-x86_64.sh #添加执行权限bash ./Miniconda3-latest-Linux-x86_64.sh #安装下载的minnconda3

2.集群安装dcu版本的pytorch安装包
格式:
conda create -n 虚拟环境名 python=3.8
(1)集群一般会预置适配的安装包,路径为:/public/software/apps/DeepLearning/whl
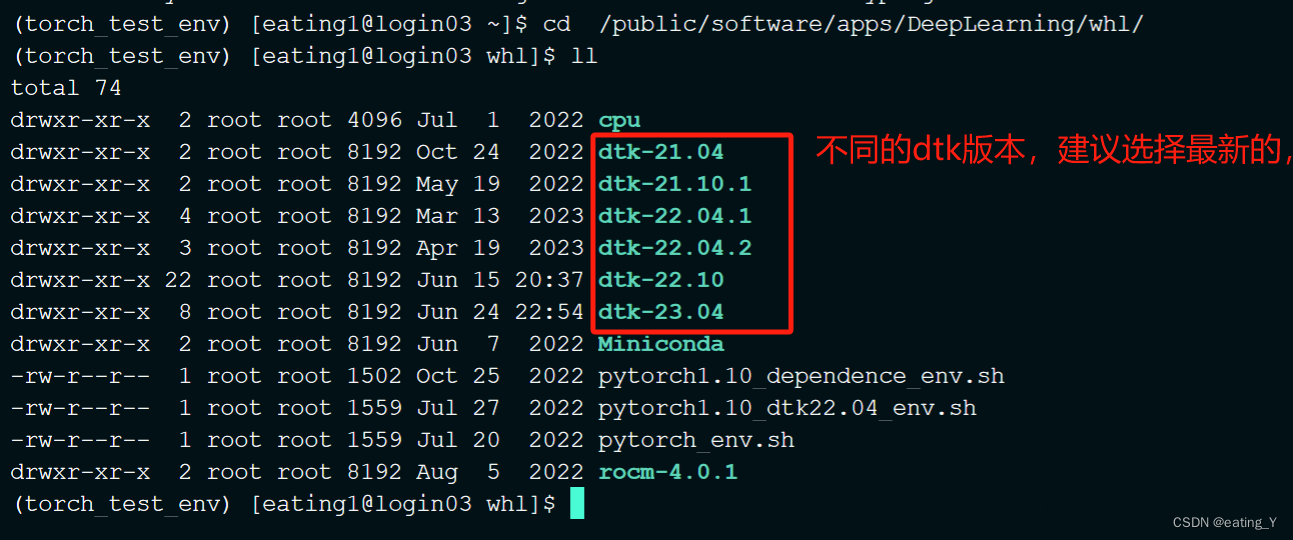
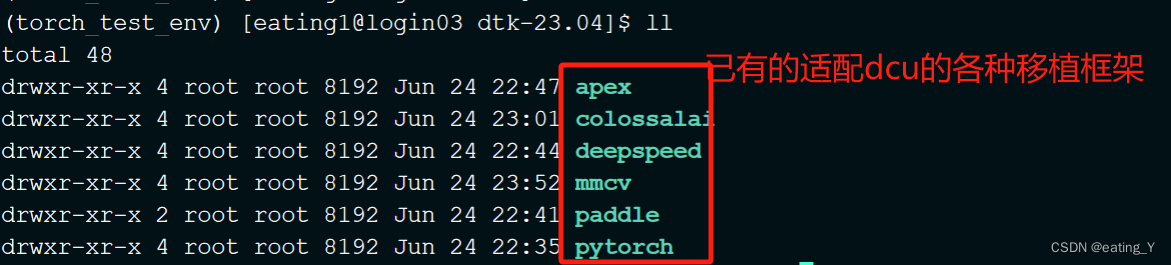
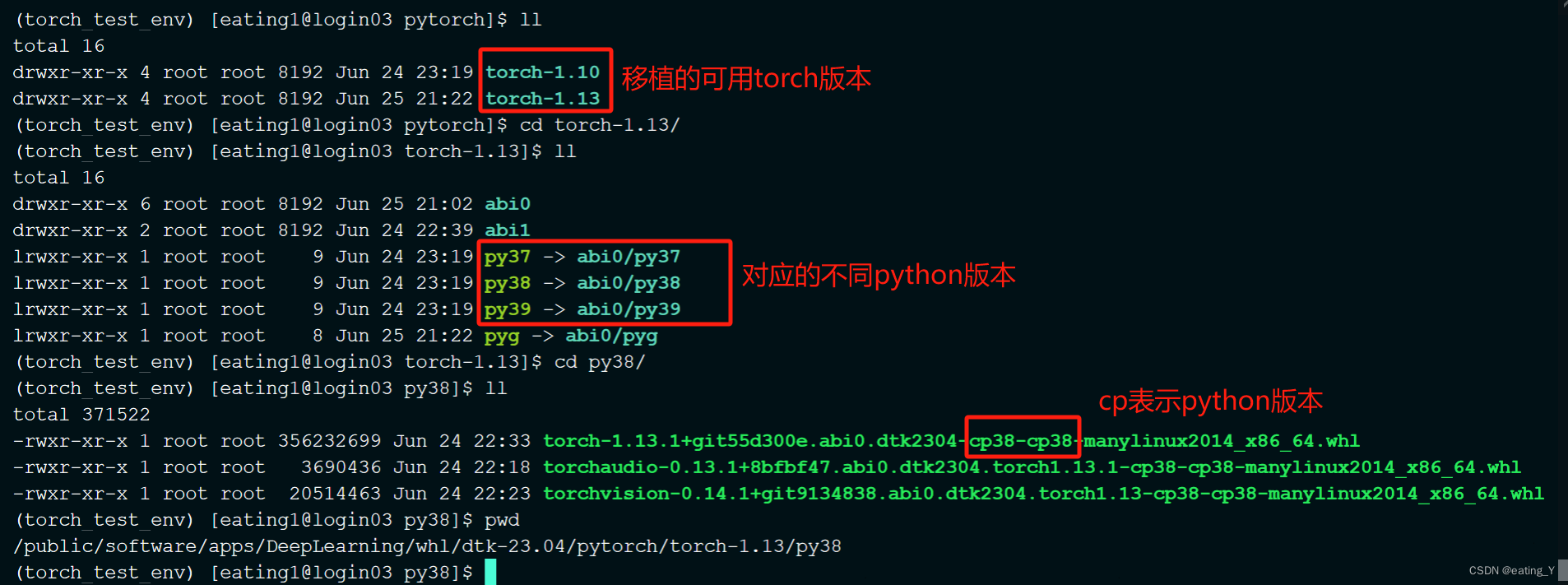
环境搭建方法(以安装dtk2304下面的torch1.13-py38为例):
conda create -n torch_test_env python=3.8 -y # torch_test_env为虚拟环境名,可以自定义 ,-y 表示yes,无需在安装过程中再手动输入conda activate torch_test_env #激活虚拟环境pip install /public/software/apps/DeepLearning/whl/dtk-23.04/pytorch/torch-1.13/py38/torch-1.13.1+git55d300e.abi0.dtk2304-cp38-cp38-manylinux2014_x86_64.whl -i https://pypi.mirrors.ustc.edu.cn/simple #安装集群的torch包,-i 后面表示镜像源,可以加速安装#其他不涉及加速的包可以正常pip install 安装注意:选择的torch版本对应的python需要和创建环境时的python相匹配

验证:
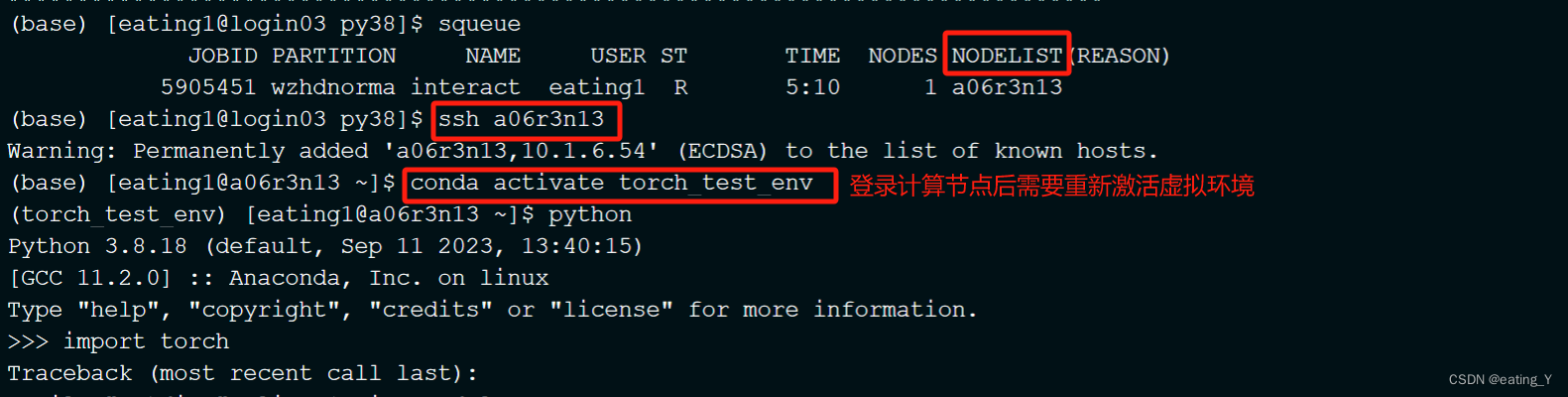
salloc -p wzhdnormal -N1 -n32 --gres=dcu:4 #申请资源。-p后面表示队列名,可以通过whichpartition查看到。wzhdnormal其中hd表示dcu队列 ,-N 表示节点数,-n 表示核心数,dcu:4表示卡数,一般核:卡=8:1,即若申请两张卡,对应核数为16,salloc -p wzhdnormal -N1 -n16 --gres=dcu:2ssh 计算节点 #登录计算节点,squeue查看作业运行状态,nodelist下面对应的为计算节点
conda activate torch_test_env #重新进入虚拟环境
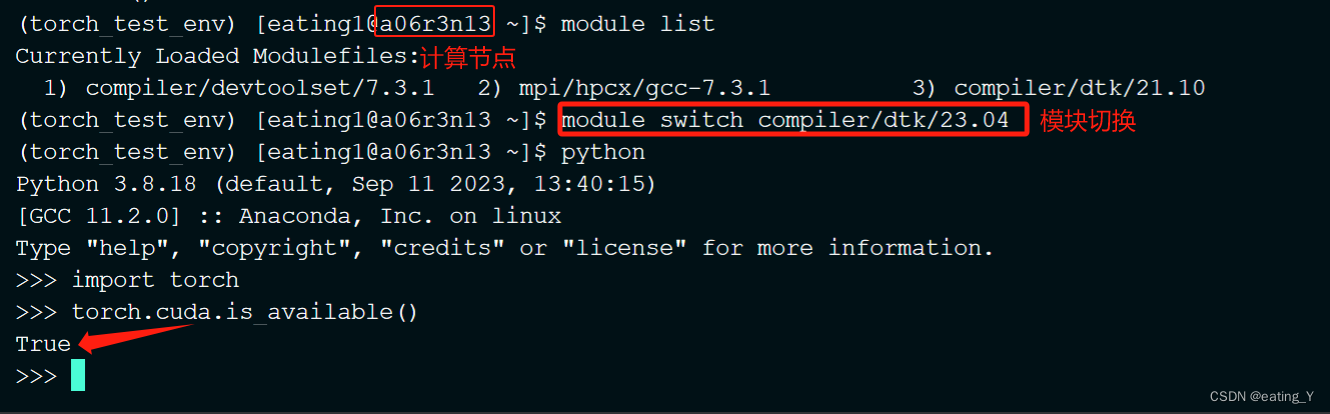
module switch compiler/dtk/23.04 #切换为对应的dtk版本
python
import torch
torch.cuda.is_available() #显示true表示安装成功注意:验证完请务必取消作业,scancel JOBID

作业提交参考脚本:
test.slurm #自定义脚本名
#!/bin/bash
#BATCH -J test # 作业名
#SBATCH -p wzhdnormal # 队列名 使用whichpartition 查看
#SBATCH -N 1 # 节点数量
#SBATCH --ntasks-per-node=1 # 每节点运行进程数
#SBATCH -c 8 # 每个进程所用cpu核数
#SBATCH --gres=dcu:1 # 每个节点申请的dcu数量
#SBATCH -o %j.out # 作业标准输出
#SBATCH -e %j.out # 作业错误输出,这里两种输出放在了一个文件中显示#加载conda环境
source ~/miniconda3/etc/profile.d/conda.sh
conda activate torch_test_env
#加载module
module purge
module load compiler/devtoolset/7.3.1
module load mpi/hpcx/gcc-7.3.1
module load compiler/dtk/23.04#运行程序
python -u main.py
提交作业:sbatch 脚本名
查看作业:squeue
取消作业:scancel 作业号 (作业号:执行squeue,jobid下面的数字)
实时查看输出:tail -f 输出文件名




![[动态规划] (十) 路径问题 LeetCode 174.地下城游戏](https://img-blog.csdnimg.cn/img_convert/564dbdb8c3471240feac7343a8771b57.png)