论文:Diffusion models beat GAN on image Synthesis
代码:https://github.com/openai/guided-diffusion
出处:OPENAI | NIPS2021
时间:2021
贡献:
- 在本文章之前,扩散模型生成的图片已经非常逼真了,但是 inception score(IS FID等)不如GAN,如何提供一些人为指导来帮助模型采样和学习,提高分数和采样速度就是本文的出发点
- 作者引入了 classifier guidance 模式,将扩散模型变成了 class-conditional 任务,使用分类梯度来指导扩散模型的生成,平衡了多样性和保真性,降低了扩散模型的采样时间,同时能提高高分辨率情况下的采样效果
一、背景
在近几年来,生成式模型已经能生成类似人类的自然语音、声音、音乐,也能生成高质量的图像
GAN[19] 在当时来说是很多图像生成任务的 SOTA,其评判标准都是例如 FID、Inception Score、Precision 等简单标准
但这些标准很难完全捕捉到图像之间的差异,而且 GAN 也被证明捕捉到的差异性比很多 likelihood-based 方法能够捕捉到的更少一些,而且 GAN 比较难以训练,一旦没有仔细的设置参数和规则,就容易崩塌
扩散模型就是 likelihood-based 方法的一种,其通过逐步从图像信号中移除噪声来生成图片,其训练的目标函数可以被看做一个重参数化的变分下届,扩散模型在 CIFAR-10 上已经得到了 SOTA,但是在 LSUN 和 ImageNet 这些比较难的数据集上比 GAN 稍微落后一点。
作者认为,扩散模型和 GAN 之间的差距主要由于下面两个因素,也是基于这两个因素,作者对 diffusion model 进行了改进:
- GAN 的模型结构已经被探索和改进了很多了
- GAN 能更好的平衡多样性和保真度,产生高质量的样本,但不覆盖整个分布

二、方法
2.1 扩散模型回顾
扩散模型是通过从一个渐进加噪声的逆过程来采样的,也就是说,最开始的时候从噪声 x T x_T xT 中开始采样,然后逐步得到噪声更少的 x T − 1 x_{T-1} xT−1、 x T − 2 x_{T-2} xT−2 … ,直到得到最终的采样结果 x 0 x_0 x0
扩散模型就是在学习如何从 x t x_t xt 得到上一时刻的 x t − 1 x_{t-1} xt−1,扩散模型可以被建模为 ϵ θ ( x t , t ) \epsilon_{\theta}(x_t, t) ϵθ(xt,t),表示预测到的当前时刻的噪声,训练目标函数是 ∣ ∣ ϵ θ ( x t , t ) − ϵ ∣ ∣ 2 ||\epsilon_{\theta}(x_t, t) - \epsilon||^2 ∣∣ϵθ(xt,t)−ϵ∣∣2, ϵ \epsilon ϵ 是真实噪声
2.2 简单的质量测评标准
1、Inception Score(IS)
Inception Score (IS) 是用来衡量一个模型在生成单个类别的样本时能否很好地捕获整个 ImageNet 类别分布
然而,该指标有一个缺点,它并不奖励覆盖整个分布的行为,也不会奖励在一个类别中捕获很多多样性的行为,如果模型记住全数据集一小部分,仍然会有高 IS
2、FID
为了比 IS 更好地捕获多样性,Heusel等人[23] 提出了 Fréchet Inception Distance (FID),他们认为 FID 与人类判断更一致。FID 提供了一个对两个图像分布在 Inception-V3 [62] 潜空间中距离的对称度量
Nash 等人[42] 提出了 sFID 作为使用空间特征而非标准汇集特征的 FID 版本。他们发现这种指标更好地捕获了空间关系, 奖励具有连贯高级结构的图像分布
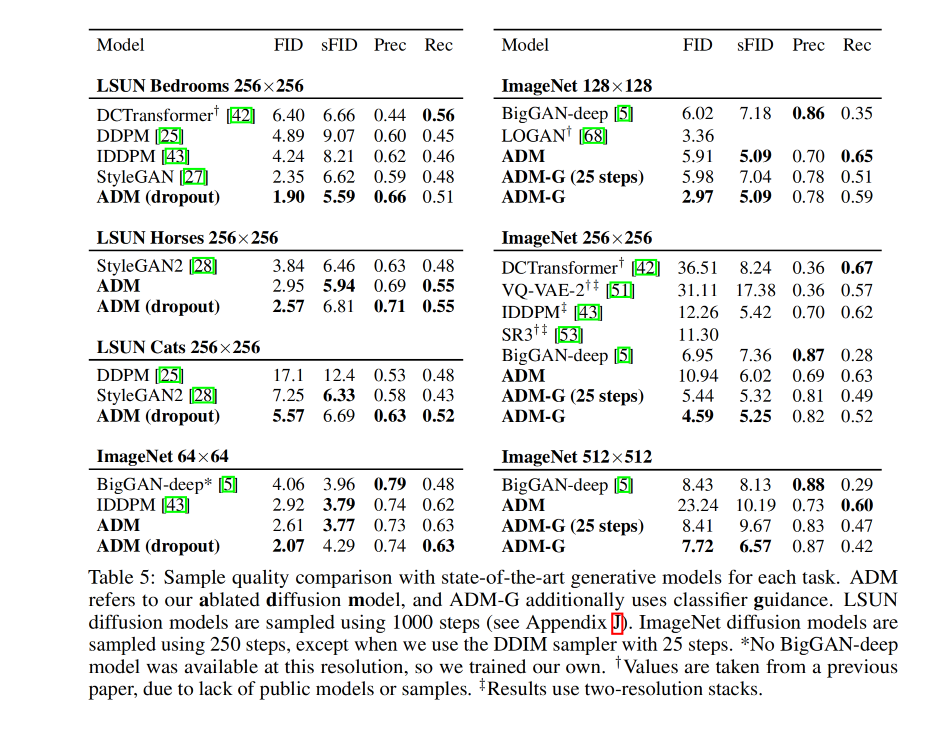
作者使用 FID 作为评判指标,因为其能同时捕捉样本的多样性和保真性
作者还使用了 Precision 或 IS 来衡量保真性,使用 Recall 来衡量多样性或分布范围
2.3 模型架构改进
作者为了获得简单有效的模型架构,进行了多种不同的架构消融实验
因为扩散模型使用的是 U-Net,所以作者主要对 U-Net 的结构进行了改进

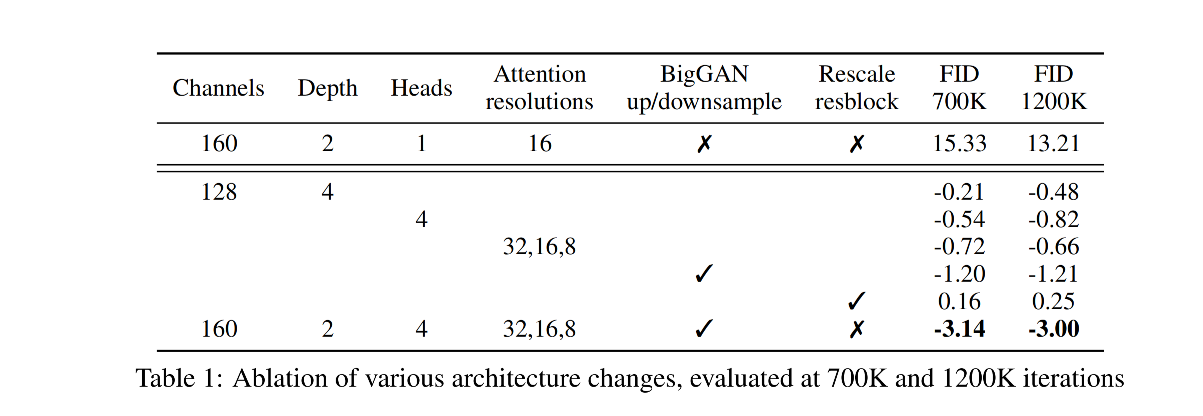
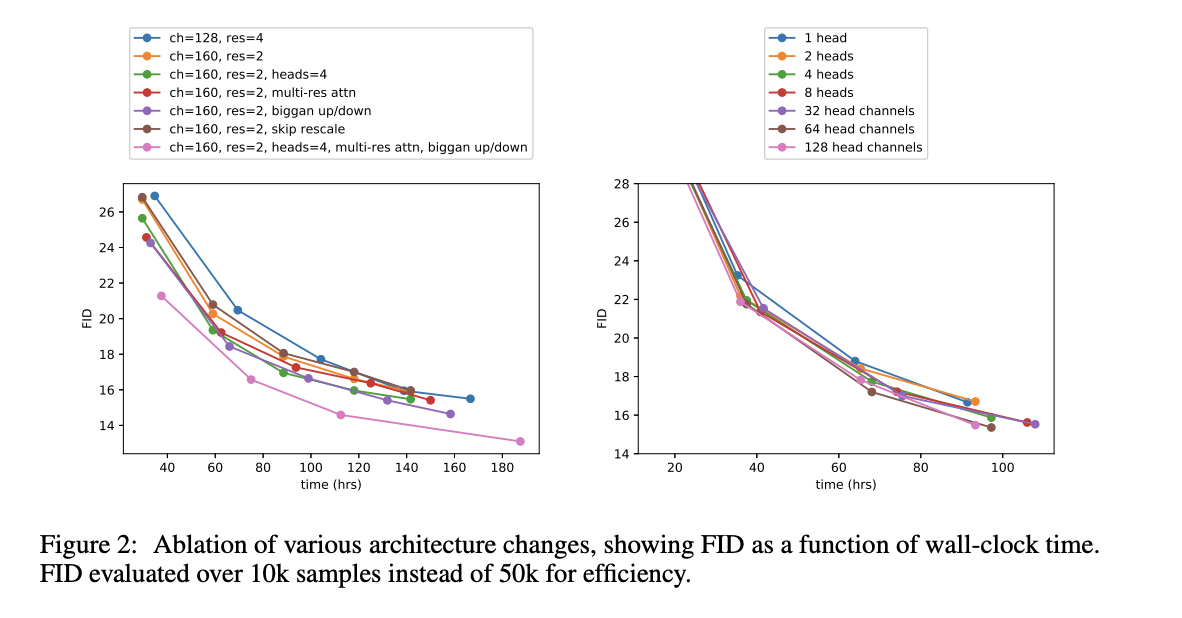
虽然增加模型深度能提高效果,但训练时长增加了,所以不做模型深度的改变
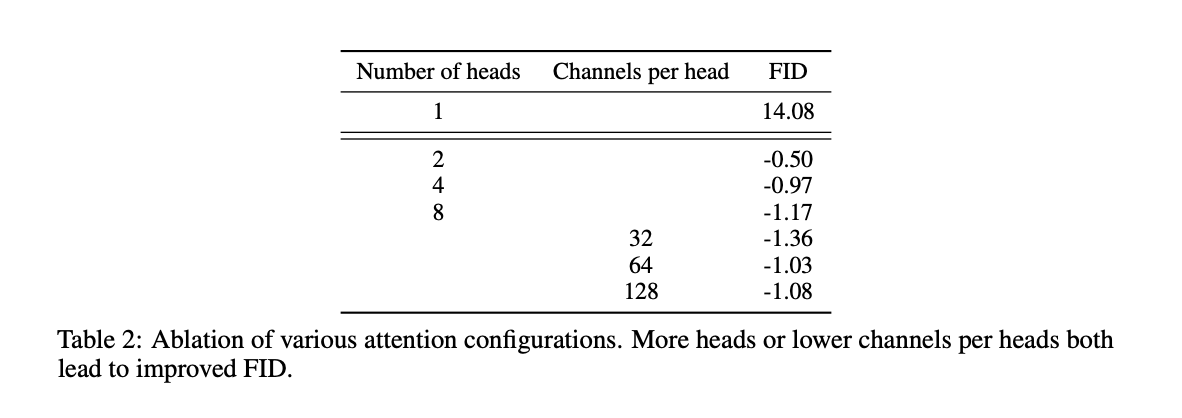
作者还对比了使用不同 head 的效果,最终使用了 64
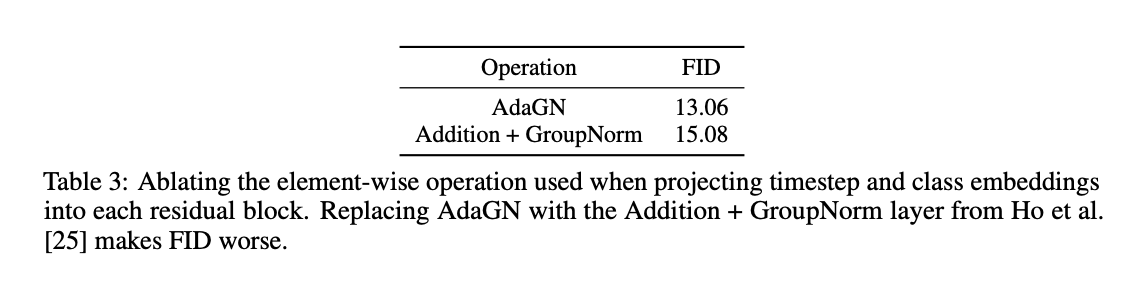
2.4 Classifier Guidance
GAN 用于条件合成时,除了精心设计结构外,还会使用很多 class labels,所以作者也想使用分类器来提升扩散模型的效果
方法:作者会在带噪声的图像 x t x_t xt 上训练一个分类器,然后使用梯度来指导扩散模型的采样过程来朝着对应类别进行采样,作者这里使用的 ImageNet
本文方法不用额外训练扩散模型,直接在原有训练好的扩散模型上,通过外部的分类器来引导生成期望的图像。唯一需要改动的地方其实只有 sampling 过程中的高斯采样的均值,也即采样过程中,期望噪声图像的采样中心越靠近判别器引导的条件越好。
使用分类模型对生成的图片进行分类,得到预测分数与目标类别的交叉熵,将其对带噪图像求梯度用梯度引导下一步的生成采样。

三、效果