情景:传统的爬虫只需要设置fetch_type=js即可,因为可以获取到整个页面。但是现在ajax应用越来越广泛,所以有的网页不能用此种爬虫类型来获取页面的数据,只能用slef.crawl()来发起http请求来抓取数据。
直接上例子:
可以看到,该网页的每一页的数据是通过ajax请求获取到的,方式为POST,所以不能用传统方法。
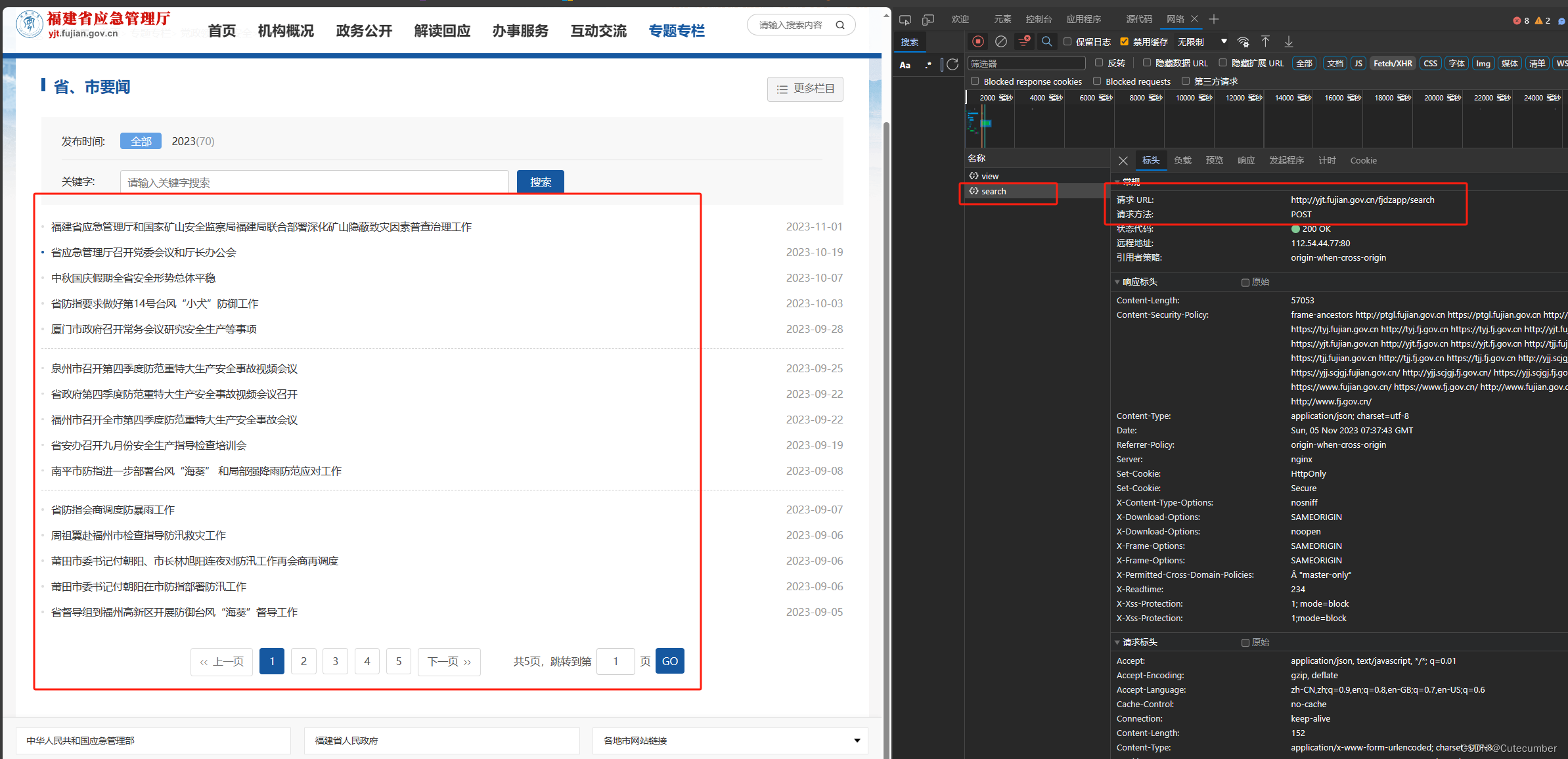
可以看到该请求的请求体,我们需要把请求体和请求方法写到crawl函数的参数里。
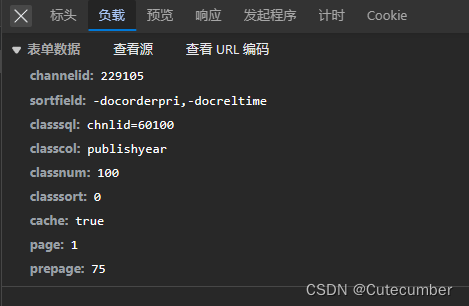
直接上代码:
# coding: utf-8
from pyspider.libs.base_handler import *class Handler(BaseHandler):@every(minutes=10)def on_start(self):data = {'channelid': 229105,'sortfield': '-docorderpri,-docreltime','classsql': 'chnlid=40078','classcol': 'publishyear','classnum': 100,'classsort': 0,'cache': 'true','page': 1,'prepage': 75,}save = {'req_body':data}# method指定POST,data指定请求体,save保存一些自定义字段。self.crawl('http://yjt.fujian.gov.cn/fjdzapp/search', callback=self.index_page, method="POST", data=data, save=save)# 抓取请求的响应数据后会调用此接口@config(age=10*60)def index_page(self, response):print(response.save['req_body']) # 查看请求体print(response.json) # 获取所抓到的数据return response.jsondef on_result(self, result):# 处理结果 ...
请求体和响应如下:

需要注意的地方
可以看到,字典的字段都是u'...',这表明是Unicode编码,所以想要获取字典中的字段,需要做下面的处理:
response字典中有个recordCount的key,我想获取他的值,需要将其先按照utf-8的编码方式解码为Unicode(python2默认Unicode编码,但是我们的脚本是utf-8的编码方式),这样就可以获取到字典的值啦
recordCount = response.json.get('recordCount'.decode('utf-8'))