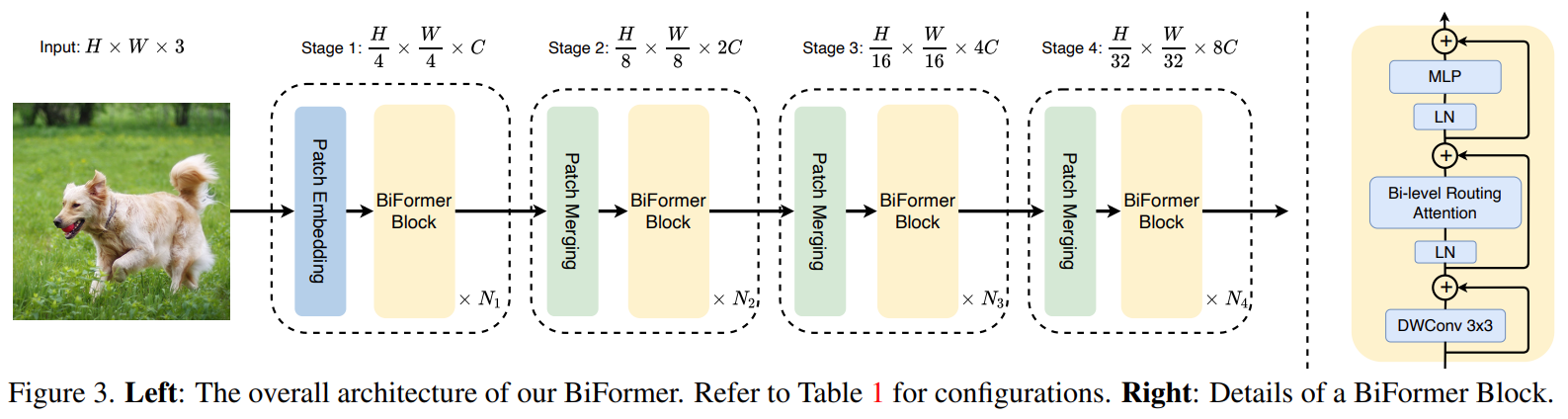
概述
短视频平台如TikTok已成为信息传播和电商推广的重要渠道。用户通过短视频分享生活、创作内容,吸引了数以亿计的观众,为企业和创作者提供了广阔的市场和宣传机会。然而,要深入了解TikTok上的视频内容以及用户互动情况,需要借助爬虫技术。本文将介绍如何使用Python和BeautifulSoup库解析TikTok视频页面,并通过统计分析视频信息,帮助您更好地利用这一重要渠道。
正文
TikTok的网页结构在不断变化,但我们可以使用BeautifulSoup库来解析页面内容。首先,我们需要安装BeautifulSoup库,可以使用以下命令:
pip install beautifulsoup4
接下来,我们需要导入所需的库:
import requests
from bs4 import BeautifulSoup
import threading
import random
然后,设置代理IP,这里以爬虫代理为例:
# 设置代理服务器 亿牛云爬虫代理标准版
proxy_host = "www.16yun.cn"
proxy_port = 31111
proxy_username = "16YUN"
proxy_password = "16IP"
定义一个函数,用于获取TikTok视频页面的内容:
def get_tiktok_video_page(video_id):url = f"https://www.tiktok.com/@tiktok/video/{video_id}"# 设置代理服务器proxies = {"http": f"http://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}","https": f"http://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}"}# 设置随机User Agentuser_agent = random.choice(user_agents)headers = {"User-Agent": user_agent}# 设置Cookiecookies = {"cookie_name": "cookie_value"}response = requests.get(url, proxies=proxies, headers=headers, cookies=cookies, timeout=10)if response.status_code == 200:return response.textelse:print(f"获取视频ID为{video_id}的页面失败")return None
接着,定义一个函数,用于解析TikTok视频页面的内容和进行统计分析:
def parse_tiktok_video_page(html):soup = BeautifulSoup(html, "html.parser")# 提取视频信息video_title = soup.find("h2", {"class": "title"}).textvideo_description = soup.find("p", {"class": "description"}).textvideo_play_count = soup.find("span", {"class": "play-count"}).textvideo_like_count = soup.find("span", {"class": "like-count"}).textvideo_comment_count = soup.find("span", {"class": "comment-count"}).textvideo_create_time = soup.find("p", {"class": "create-time"}).text# 输出解析结果print(f"视频标题:{video_title}")print(f"视频描述:{video_description}")print(f"视频播放数:{video_play_count}")print(f"视频喜欢数:{video_like_count}")print(f"视频评论数:{video_comment_count}")print(f"视频创建时间:{video_create_time}")# 统计分析视频信息,例如计算平均播放数、喜欢数和评论数,帮助决策制定和内容策略优化# 这里可以编写代码来进行统计分析
最后,我们可以使用多线程来提高采集效率:
# 示例用法
video_ids = ["6954826933932541953", "6954826933932541954", "6954826933932541955"]
user_agents = ["UserAgent1", "UserAgent2", "UserAgent3"]def crawl_video_data(video_id):html = get_tiktok_video_page(video_id)if html:parse_tiktok_video_page(html)threads = []
for video_id in video_ids:thread = threading.Thread(target=crawl_video_data, args=(video_id,))threads.append(thread)thread.start()for thread in threads:thread.join()
结语
通过本文的指导,您可以更好地理解如何构建一个功能强大的TikTok爬虫程序,解析视频页面内容,并进行统计分析,帮助您更好地利用这一重要的信息传播和电商推广渠道。





![[答疑]校长出轨主任流程的业务建模](https://img-blog.csdnimg.cn/d6dbd6e595594db3908d549c4ed817f3.png)